Parallelism vs Concurrency: choosing the right tools
Hello, dear habrovchane! We decided to resume publication even before the end of the big holidays, but in today's article the topic of fair distribution of gifts is still revealed. The very same article, as the name implies, is devoted to a comparative analysis of parallelism and competitiveness.
Explanatory dictionary
')
Wikipedia
In this article, I will argue with Joe Armstrong and Rob Pike, showing for clarity how vending machines and gift boxes differ. Illustrations made by me, neatly drawn in the program Microsoft Paint.
Both parallelism and competition are very fashionable phenomena of our time. Many languages and tools are positioned as optimized for concurrency and competition, and often for that and for another at once.
I believe that fundamentally different tools are required for concurrency and competition, and any tool can be really well suited for either the first or the second. On fingers:
Tools of the first and second kind can coexist in the same language or system. For example, Haskell is obviously well equipped for both contention and concurrency. But, nevertheless, we are still talking about two different sets of tools, and the Haskell wiki explains that when implementing parallelism, you should not use the tools for competition:
The iron rule is: if you can, use Pure Parallelism, otherwise use Competition.
Haskell specialists realize that these two tasks cannot be solved with one tool. A similar situation arises in the new language ParaSail - there are both types of tools, and the documentation recommends not using competitive features in parallel, non-competitive programs.
This does not fit sharply with the beliefs of some people who are primarily interested in competition and who believe that their tools are great for concurrency. So, Rob Pike writes that it is easy to implement parallelism in Go, since it is a competitive language.
Similarly, Joe Armstrong declares that Erlang is very convenient for parallelism, because of its competitive nature. Armstrong even argues that attempts to parallelize inherited code written in a non-competitive language are “the solution to the wrong task . ”
Where do such different opinions come from? Why do supporters of Haskell and ParaSail think that for competition and concurrency, while Go and Erlang experts believe that competitive languages are good for concurrency?
I think people come to such different conclusions, because they solve dissimilar tasks, and they develop different ideas about the main differences between competition and parallelism. Joe Armstrong even drew a picture , depicting how he sees these differences. I’ll draw another one - but first I’ll show you the Armstrong image:
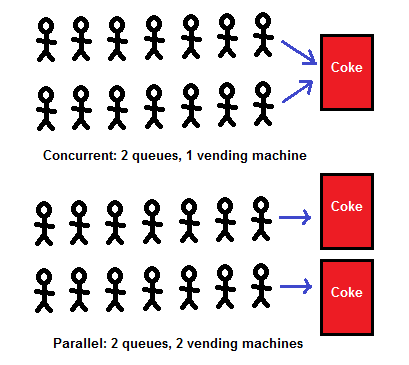
In principle, many aspects of the competition appear in one line, but I drew two, as in the original Armstrong. What is drawn here?
Actually, that's all you can say about the vending machine. What about the distribution of gifts to the horde of children? Is there a difference between jars of cola and gifts?
Yes there is. A vending machine is an event processing system : a person can approach the machine at any time, and each time will find a different number of jars in it. Gift giving is a computing system : you know the children, you know what you bought, you decide which child will receive which gift and how.
In the gift scenario, the opposition between competition and concurrency looks quite different:
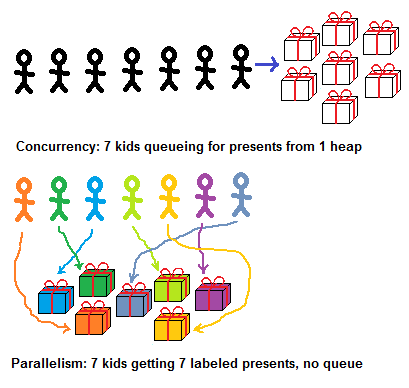
How is “competitive” different from “parallel” in this example?
The line in front of a bunch of gifts is “competitive” in the most direct sense: you want to get to the heap first, so that this Lego designer will go to you.
If gifts are marked, then there is no competition. Labels logically associate each child with his gift, and these are parallel, non-intersecting, non-conflicting lines. (Why did I draw arrows so that they intersect? Good question, we will discuss it further. Considering it, keep in mind that the paths of children / processes intersect when they pave the way for the present, but such intersections do not lead to conflicts).
Calculations vs event handling
In the case of event processing systems, such as vending machines, PBXs, web servers and banks, competition is inherent in the task by definition - you must resolve the inevitable conflicts between spontaneous requests. Parallelism is part of the solution; it speeds up work, but the real problem in this case is competition.
When working with computing systems (gift boxes, graphics, computer vision, scientific computing), competition is not part of the problem — you calculate the output based on previously known input, without the participation of any external events. Parallelism in this case provokes a problem - yes, the processing is accelerated, but bugs may occur.
Let's discuss other differences between event processing systems and computing systems. Let's start with the obvious things, such as determinism, but here more subtle consequences will come to light.
Determinism: preferably vs impossible
In computing systems, determinism is desirable because it greatly simplifies life. For example, it is convenient to test optimization and refactoring, making sure that the results do not change - this is possible only in deterministic programs.
Often, determinism is not a requirement - you may not care at all what kind of 100 pictures you will get, if they still have kittens, or to what decimal point Pi will be calculated if you are satisfied with any value in the range from 3 to 4. Determinism is simply very convenient - and possible.
However, determinism is impossible in event processing systems, in the sense that different order of events will inevitably produce different results. If I beat you, then I should get the last jar of cola, the last dollar in our joint bank account, etc. If you overtake me even for a millisecond, then all this will go to you.
Of course, with the simplest debugging, you can always run the system strictly sequentially, processing one event per unit of time. But if you imagine a slightly more realistic situation and begin to handle events even before you can handle all the tasks, then you cannot count on a specific result.
Even if you scroll through the event log in the debugging environment, which reflects how two users race to withdraw money from their bank account, then when you re-run you can get a different final alignment. The number of possible final states with an increase in the number of conflicts grows exponentially.
Oh.
Sign of reliable parallelism: determinism vs correctness
How to find out that when various events follow, you have bugs?
If you always get the same result on a computer system, then you probably don’t have concurrency bugs, even if the result is incorrect. So, if the system gives you pictures with dogs instead of pictures with cats, there is a bug, but it does not concern parallelism, if with each run they are the same dogs.
In event processing systems, the only true sign of the absence of bugs in parallelism is if you always get the correct result.
When two users race trying to withdraw money from an account, you cannot expect to always receive identical results. What to expect if we proceed from the health of the banking program? A lot of things. You will (probably) never have a negative balance on the account, you (probably) will not be able to empty your bank account twice, actually creating extra money, etc.
If none of these errors ever happens, then you have implemented a properly functioning bank, otherwise there is a bug. In the case of PBXs, everything is about the same, with the exception that a different set of conditions will correspond to the “correct result”.
There is no universal way to catch bugs related to timing, if you do not understand those aspects of the system that are not related to timing.
Oh!
Bugs with concurrency: easy to catch vs impossible to describe
In the case of marked gift boxes, it is easy to track bugs with concurrency - even if the signatures are in Chinese and you don’t know Chinese:
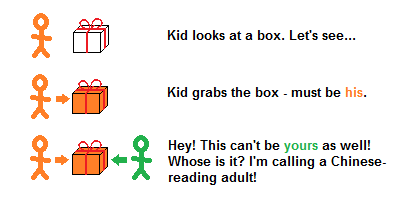
Even if you cannot read the signatures, it is enough to know that they are available. If two kids start arguing over a box, then something is wrong, and you need to call an adult who can read them.
If you are an automatic debugging tool, and do not know which task should process which data, it is enough to know that the task should not access data modified by another task . If this happens, tell the programmer to correctly assign the data to the tasks in order to avoid conflicts.
Such tools are not purely hypothetical, they exist. For example, such a tool is in Cilk. Checkedthreads has a Valgrind based tool for this.
In Parallel Haskell, this is not required - if only because there are no side effects, which means there will be no conflicts with the parallel computation of different entities. But even if you apply a dynamic test instead of a static one, then you practically guarantee that your parallelism bugs will disappear.
The bottom line is that in computing systems, you don't need to know a lot to isolate bugs and identify the problem they are causing. "This is the box that caused the fight." In error-handling systems, the supervising adult must be much more aware of the system in order to maintain discipline.
Just in case, there is a weaker, but no less universal rule: do not touch that with which someone is already working . You must wait for your turn. An adult can enforce this rule, which is better than nothing. But this is not enough to prevent many common ills:

When someone steals up for gifts out of turn, this is a clear violation. Bug found, order restored.
But a different situation is possible: someone unpacked a gift, left the queue, came back and found that someone else had taken his gift. This situation may be incorrect - or normal. In the end, the other child waited for his turn, that is, the only universal rule of event processing systems was observed - but this mischievous person still violated the rule that we give out gifts to.
Here is how the problem looks in code. The following erroneous money transfer implementation was flagged as incorrect with an automatic debugging tool:
Here we have no synchronization - the value of src.balance can be changed by two processes, and one does not have to wait until the other is finished. So, you may lose some reduction operations by one or something else. A data race detector, for example, Helgrind, will notice this bug by tracking memory accesses and detecting out of sync - this is no more difficult than checking in Cilk or checkedthreads.
True, the code below still contains bugs, but the data race detectors do not react to it:
Here “atomic” means that before changing balances everyone will have to wait in a kind of queue - we will consider it just a queue, albeit a very unusual one; more about this below. When the queue is built correctly, the data race detectors are calm - but is the bug still there?
The flow can be suspended after decreasing src.balance by one, but even before increasing dst.balance by one; there is an intermediate state in which money is "temporarily lost." This is problem? Maybe. Do you understand banking? I - no, and Helgrind just does not understand.
Here is a program with a more obvious error:
Here the flow can check whether there is a sufficient amount of money on src.balance so that it can be withdrawn, after which it will go for a smoke. In the meantime, another thread will come up, make a similar check and begin to withdraw money. The first thread returns, gets in line, waits in the wings and withdraws its amount - and this operation can no longer go through if the first thread has time to withdraw a lot of money.
The situation resembles the following: while you were away, someone came and took your iPhone. These are race conditions, not data race - that is, the situation arises regardless of how accurately the queue was built.
What is the "race conditions" ? Depends on the application. I have no doubt that the last fragment contains bugs, but I’m not so sure about the last but one; it all depends on how the bank works. If we cannot even give the definition of a “race of conditions” without knowing what the program is doing, it is impossible to hope that we can automatically track it.
Of course, race conditions may not be. For this, it would be necessary to simply implement the entire withdrawal procedure as atomic, which, of course, makes it possible to make any competition option. However, the situation with race conditions, as compared to, for example, issuing exceptions to the null pointer, is different in that you can send input to the program again and again, which provokes bugs, and the situation will repeat, albeit very rarely. This is where automatic deterministic debugging would be very useful, in which a bug is flagged whenever the system receives such input. Unfortunately, in event processing systems this is not possible.
Queues: implementation detail or part of an interface
When gifts are signed, the queue is not needed. Everyone can come and pick up their own.
Or not, definitely not. When thousands of children need to receive thousands of signed gifts, they will line up in a queue or several lines; otherwise they will simply fly over each other. The principle of operation of these lines is not important in the sense that everyone will receive their gifts one way or another. But the chosen method of the queue depends on how long you have to wait for your gift.
That is why I drew "logical parallel" lines connecting children with gifts, precisely so that they intersect - although in fact there are no conflicts for specific gifts.
The 4 processors accessing unrelated data elements across the entire memory bus create a situation in which the “logical parallel lines actually intersect”, and in fact the processors will have to wait in a kind of hardware queue to do their work. 1000 logically independent tasks distributed to these 4 processors by the load balancer scheduler can only be performed using queues.
Even in a fully parallel and conflict-free system, there are usually many queues — but these are implementation details that should not affect the result. You will get the same thing, no matter what place you occupy in any of the queues:
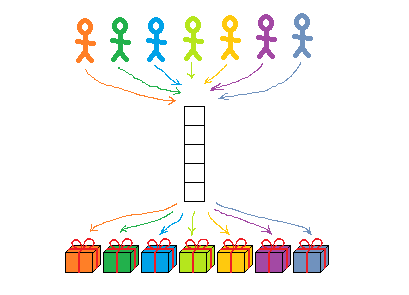
In contrast, in a competitive system, the queue is directly in the interface:
In event systems there can be both simple and intricate queues, but these are queues in the sense that order often influences the result, and this is normal - or there may be a race of conditions, such things.
In computational parallel conflict-free systems, the execution order should not affect the result — and you will need tools to ensure that the system is truly conflict-free.
Rob Pike on his slides shows how easy it is to write a load balancer on Go. Yes, just. Go is created for competition, and competition is associated with queues, as is load balancing. I would not say that load balancers are difficult to write in any language, but in a competitive language it is really simple.
But this is only part of the parallelism story. Next, you will need either static guarantees for the absence of conflicts, or dynamic checking. I’m not saying that you can’t do this on Go — you can definitely do it — just without it, you will not be able to use computing systems effectively. Having these mechanisms, you get a different set of interfaces and tools that differ from channels and Gorutin - even if it is implemented at the basic level with the help of channels and Gorutin.
Importance of crowding out
So, preventing or detecting conflicts is a necessary aspect of computing systems that is not supported by competitive tools. Are there things that are provided by competitive tools, but are not needed in computing systems?
Of course - first of all, these are obvious queues. In computing systems, they are not only unnecessary, but also interfere with work, because, as we have seen, queues provoke race conditions, not data races, and you cannot track such situations.
Another thing that, in essence, is not needed in computing systems is the very low-cost, displaced threads / processes.
In event processing systems, it is sometimes necessary to respond to a wide variety of events very quickly, and this requires many preemptive processes. It is necessary that in a situation where 10,000 processes are busy with current work, the system could still activate the process 10001 as soon as the corresponding event occurs. Such a mechanism can work only under the condition that the displaced processes are very low-cost.
In computing systems, it is convenient to have low-cost tasks that could be mapped to relatively costly operating system streams — but tasks are inferior in potential to processes. Tasks are not activated during events. Tasks are in different queues and are processed when the workflow is released, which can start them. Unlike situations with gorutinami, etc. you cannot have more current tasks than there are threads in the operating system - this is not necessary.
The tasks function well at the level of a normal performing environment as compared to fully functional low-cost processes / cores / etc., Which, in my opinion, are required to handle the low-level aspects of the system more closely.
(Honestly, some benefit from crowding out can also be extracted in a competitive system — namely, increasing throughput if the program allows new tasks that are part of a critical path to crowd out other tasks on the fly. However, in my long and bitter experience such a planner who truly recognizes critical paths exists only in theory. A stupid greedy planner is not suitable for crowding out.
Differences between tools in the same family
Tools aimed at the realization of competition in event systems, as well as similar tools in computing systems. They belong to the same family, but they have significant differences.
Of course, much depends on the language in which you program - Erlang, Rust, Go and Haskell, respectively. And now about computing systems:
I wrote checkedthreads, so consider this a small advertisement; checkedthreads is a portable, free, secure environment that is already available in the most mainstream C and C ++ languages, unlike many systems designed for new languages or language extensions.
As for Cilk, work is underway to standardize it in C ++, but Cilk needs to add new keywords, but in the C ++ community they don’t like it. Cilk is available in gcc and LLVM branches, but it does not work on all platforms yet (it extends ABI). Some new Cilk features have been patented. Not all of them are freely available, etc. etc.
However, an important merit of Cilk is that Intel is responsible for its support, and for the support of checkedthreads - in essence, you yourself. If Cilk is right for you, and you decide to use it by reading my posts about checkedthreads, then my efforts to advertise automatic debugging of parallel programs were not in vain.
So: tools for competitive programming are not similar to each other, as well as tools for parallelism. I will not even argue that in this article I have pointed out all the important differences, a very intricate topic. However, the fact remains that we are talking about two very different classes of tools, and you decide which class to choose.
Conclusion
We discussed the differences between parallel, computing systems and competitive systems designed for event processing. The main areas of difference are:
The most important detail of event processing systems is competition, and parallelism is an element of only some solutions, usually good ones (two vending machines are clearly better than one). In computing systems, parallelism is a key feature, and competition is a detail of some decisions, usually bad ones (a pile of gifts is worse than a decision where all gifts are signed).
I hope I managed to smooth out a little the confusion that arises when mixing “concurrency / competition” with “calculations / event handling”. In addition, I hope that the event handling systems were not put in the most unattractive light - perhaps there are automated verification strategies that I don’t know about. Anyway, I do not claim that the terminology of this article and the view of things set forth in it are the only correct ones.
Some people who are interested in event processing systems share a fairly reasonable point of view: “competition is working with several tasks at the same time, concurrency is the simultaneous execution of several tasks”. In this interpretation, parallelism is the implementation detail, and competition determines the structure of the program.
I think that my point of view is not without logic, namely: “competition is the solution of inevitable conflicts related to timing, concurrency is avoiding unnecessary conflicts” - “vending machines vs signed gifts”. This is how it looks - now parallel arrows do not overlap, logically everything is exactly like this:

The most important conclusion: the computational code, unlike the code for event processing, can be easily cleared from bugs by almost one hundred percent, using either automatic debugging tools or static guarantees.
Handling concurrency with tools specifically designed for this is not new. Sawzall, the specialized parallel language of Rob Pike, where the code is guaranteed not to contain bugs with parallelism, was the forerunner of the competitive language Go, developed by the same Pike.
However, at the moment the tools for competition look more “promoted” than the tools for parallelism - and they allow you to work with parallelism, albeit relatively poorly. Loud and bad often eclipses the less catchy, but good. It would be sad if support for concurrency is no longer improved, considering it as a side effect of “priority” competition — or this support will die out where it already exists now. I even rephrase the phrase “an attempt to parallelize sequential code is the solution to the wrong task” like this: “the use of purely competitive tools in the computational code is the solution to the wrong task”. There is a simple fact: the C code, paralleled with the right tools, is faster and safer than with Erlang.
So, the whole point is to “solve the problem with the help of suitable tools” and not let anyone snitch your Apple iPhone.
competitor (noun): rival, opponent
Explanatory dictionary
')
Parallel straight lines are called straight lines that lie in the same plane and do not intersect.
Wikipedia
In this article, I will argue with Joe Armstrong and Rob Pike, showing for clarity how vending machines and gift boxes differ. Illustrations made by me, neatly drawn in the program Microsoft Paint.
Both parallelism and competition are very fashionable phenomena of our time. Many languages and tools are positioned as optimized for concurrency and competition, and often for that and for another at once.
I believe that fundamentally different tools are required for concurrency and competition, and any tool can be really well suited for either the first or the second. On fingers:
- Erlang , Rust , Go and STM Haskell are good for competition.
- Cilk , checkedthreads and parallel Haskell are good for concurrency
Tools of the first and second kind can coexist in the same language or system. For example, Haskell is obviously well equipped for both contention and concurrency. But, nevertheless, we are still talking about two different sets of tools, and the Haskell wiki explains that when implementing parallelism, you should not use the tools for competition:
The iron rule is: if you can, use Pure Parallelism, otherwise use Competition.
Haskell specialists realize that these two tasks cannot be solved with one tool. A similar situation arises in the new language ParaSail - there are both types of tools, and the documentation recommends not using competitive features in parallel, non-competitive programs.
This does not fit sharply with the beliefs of some people who are primarily interested in competition and who believe that their tools are great for concurrency. So, Rob Pike writes that it is easy to implement parallelism in Go, since it is a competitive language.
Similarly, Joe Armstrong declares that Erlang is very convenient for parallelism, because of its competitive nature. Armstrong even argues that attempts to parallelize inherited code written in a non-competitive language are “the solution to the wrong task . ”
Where do such different opinions come from? Why do supporters of Haskell and ParaSail think that for competition and concurrency, while Go and Erlang experts believe that competitive languages are good for concurrency?
I think people come to such different conclusions, because they solve dissimilar tasks, and they develop different ideas about the main differences between competition and parallelism. Joe Armstrong even drew a picture , depicting how he sees these differences. I’ll draw another one - but first I’ll show you the Armstrong image:
In principle, many aspects of the competition appear in one line, but I drew two, as in the original Armstrong. What is drawn here?
- "Parallelism" means that Coke moves faster.
- "Parallelism" means practically only this - in any case, we face the same competitive challenge.
- Coca-Cola used to get the one who used to stand in line
- In a sense, it doesn’t matter who gets Coke first — in any case, everyone gets it.
- ... except, perhaps, a few little men at the end, as Coca-Cola may end - but such is life, my friend. Someone has to be the last.
Actually, that's all you can say about the vending machine. What about the distribution of gifts to the horde of children? Is there a difference between jars of cola and gifts?
Yes there is. A vending machine is an event processing system : a person can approach the machine at any time, and each time will find a different number of jars in it. Gift giving is a computing system : you know the children, you know what you bought, you decide which child will receive which gift and how.
In the gift scenario, the opposition between competition and concurrency looks quite different:
How is “competitive” different from “parallel” in this example?
- The competitive distribution of gifts in many respects resembles the work of a vending machine: the first to receive gifts are those who have previously stood in a queue.
- Parallel distribution of gifts is built differently: each gift is marked, so you can imagine who will receive what.
- In the competitive case, a queue is needed so that two children do not fight for a gift / two tasks do not damage the shared data structure.
- In the parallel case, the queue can do. Regardless of who comes earlier, everyone will end up with gifts chosen for them.
The line in front of a bunch of gifts is “competitive” in the most direct sense: you want to get to the heap first, so that this Lego designer will go to you.
If gifts are marked, then there is no competition. Labels logically associate each child with his gift, and these are parallel, non-intersecting, non-conflicting lines. (Why did I draw arrows so that they intersect? Good question, we will discuss it further. Considering it, keep in mind that the paths of children / processes intersect when they pave the way for the present, but such intersections do not lead to conflicts).
Calculations vs event handling
In the case of event processing systems, such as vending machines, PBXs, web servers and banks, competition is inherent in the task by definition - you must resolve the inevitable conflicts between spontaneous requests. Parallelism is part of the solution; it speeds up work, but the real problem in this case is competition.
When working with computing systems (gift boxes, graphics, computer vision, scientific computing), competition is not part of the problem — you calculate the output based on previously known input, without the participation of any external events. Parallelism in this case provokes a problem - yes, the processing is accelerated, but bugs may occur.
Let's discuss other differences between event processing systems and computing systems. Let's start with the obvious things, such as determinism, but here more subtle consequences will come to light.
Determinism: preferably vs impossible
In computing systems, determinism is desirable because it greatly simplifies life. For example, it is convenient to test optimization and refactoring, making sure that the results do not change - this is possible only in deterministic programs.
Often, determinism is not a requirement - you may not care at all what kind of 100 pictures you will get, if they still have kittens, or to what decimal point Pi will be calculated if you are satisfied with any value in the range from 3 to 4. Determinism is simply very convenient - and possible.
However, determinism is impossible in event processing systems, in the sense that different order of events will inevitably produce different results. If I beat you, then I should get the last jar of cola, the last dollar in our joint bank account, etc. If you overtake me even for a millisecond, then all this will go to you.
Of course, with the simplest debugging, you can always run the system strictly sequentially, processing one event per unit of time. But if you imagine a slightly more realistic situation and begin to handle events even before you can handle all the tasks, then you cannot count on a specific result.
Even if you scroll through the event log in the debugging environment, which reflects how two users race to withdraw money from their bank account, then when you re-run you can get a different final alignment. The number of possible final states with an increase in the number of conflicts grows exponentially.
Oh.
Sign of reliable parallelism: determinism vs correctness
How to find out that when various events follow, you have bugs?
If you always get the same result on a computer system, then you probably don’t have concurrency bugs, even if the result is incorrect. So, if the system gives you pictures with dogs instead of pictures with cats, there is a bug, but it does not concern parallelism, if with each run they are the same dogs.
In event processing systems, the only true sign of the absence of bugs in parallelism is if you always get the correct result.
When two users race trying to withdraw money from an account, you cannot expect to always receive identical results. What to expect if we proceed from the health of the banking program? A lot of things. You will (probably) never have a negative balance on the account, you (probably) will not be able to empty your bank account twice, actually creating extra money, etc.
If none of these errors ever happens, then you have implemented a properly functioning bank, otherwise there is a bug. In the case of PBXs, everything is about the same, with the exception that a different set of conditions will correspond to the “correct result”.
There is no universal way to catch bugs related to timing, if you do not understand those aspects of the system that are not related to timing.
Oh!
Bugs with concurrency: easy to catch vs impossible to describe
In the case of marked gift boxes, it is easy to track bugs with concurrency - even if the signatures are in Chinese and you don’t know Chinese:
Even if you cannot read the signatures, it is enough to know that they are available. If two kids start arguing over a box, then something is wrong, and you need to call an adult who can read them.
If you are an automatic debugging tool, and do not know which task should process which data, it is enough to know that the task should not access data modified by another task . If this happens, tell the programmer to correctly assign the data to the tasks in order to avoid conflicts.
Such tools are not purely hypothetical, they exist. For example, such a tool is in Cilk. Checkedthreads has a Valgrind based tool for this.
In Parallel Haskell, this is not required - if only because there are no side effects, which means there will be no conflicts with the parallel computation of different entities. But even if you apply a dynamic test instead of a static one, then you practically guarantee that your parallelism bugs will disappear.
The bottom line is that in computing systems, you don't need to know a lot to isolate bugs and identify the problem they are causing. "This is the box that caused the fight." In error-handling systems, the supervising adult must be much more aware of the system in order to maintain discipline.
Just in case, there is a weaker, but no less universal rule: do not touch that with which someone is already working . You must wait for your turn. An adult can enforce this rule, which is better than nothing. But this is not enough to prevent many common ills:
When someone steals up for gifts out of turn, this is a clear violation. Bug found, order restored.
But a different situation is possible: someone unpacked a gift, left the queue, came back and found that someone else had taken his gift. This situation may be incorrect - or normal. In the end, the other child waited for his turn, that is, the only universal rule of event processing systems was observed - but this mischievous person still violated the rule that we give out gifts to.
Here is how the problem looks in code. The following erroneous money transfer implementation was flagged as incorrect with an automatic debugging tool:
src.balance -= amount dst.balance += amount Here we have no synchronization - the value of src.balance can be changed by two processes, and one does not have to wait until the other is finished. So, you may lose some reduction operations by one or something else. A data race detector, for example, Helgrind, will notice this bug by tracking memory accesses and detecting out of sync - this is no more difficult than checking in Cilk or checkedthreads.
True, the code below still contains bugs, but the data race detectors do not react to it:
atomic { src.balance -= amount } atomic { dst.balance += amount } Here “atomic” means that before changing balances everyone will have to wait in a kind of queue - we will consider it just a queue, albeit a very unusual one; more about this below. When the queue is built correctly, the data race detectors are calm - but is the bug still there?
The flow can be suspended after decreasing src.balance by one, but even before increasing dst.balance by one; there is an intermediate state in which money is "temporarily lost." This is problem? Maybe. Do you understand banking? I - no, and Helgrind just does not understand.
Here is a program with a more obvious error:
if src.balance - amount > 0: atomic { src.balance -= amount } atomic { dst.balance += amount } Here the flow can check whether there is a sufficient amount of money on src.balance so that it can be withdrawn, after which it will go for a smoke. In the meantime, another thread will come up, make a similar check and begin to withdraw money. The first thread returns, gets in line, waits in the wings and withdraws its amount - and this operation can no longer go through if the first thread has time to withdraw a lot of money.
The situation resembles the following: while you were away, someone came and took your iPhone. These are race conditions, not data race - that is, the situation arises regardless of how accurately the queue was built.
What is the "race conditions" ? Depends on the application. I have no doubt that the last fragment contains bugs, but I’m not so sure about the last but one; it all depends on how the bank works. If we cannot even give the definition of a “race of conditions” without knowing what the program is doing, it is impossible to hope that we can automatically track it.
Of course, race conditions may not be. For this, it would be necessary to simply implement the entire withdrawal procedure as atomic, which, of course, makes it possible to make any competition option. However, the situation with race conditions, as compared to, for example, issuing exceptions to the null pointer, is different in that you can send input to the program again and again, which provokes bugs, and the situation will repeat, albeit very rarely. This is where automatic deterministic debugging would be very useful, in which a bug is flagged whenever the system receives such input. Unfortunately, in event processing systems this is not possible.
Queues: implementation detail or part of an interface
When gifts are signed, the queue is not needed. Everyone can come and pick up their own.
Or not, definitely not. When thousands of children need to receive thousands of signed gifts, they will line up in a queue or several lines; otherwise they will simply fly over each other. The principle of operation of these lines is not important in the sense that everyone will receive their gifts one way or another. But the chosen method of the queue depends on how long you have to wait for your gift.
That is why I drew "logical parallel" lines connecting children with gifts, precisely so that they intersect - although in fact there are no conflicts for specific gifts.
The 4 processors accessing unrelated data elements across the entire memory bus create a situation in which the “logical parallel lines actually intersect”, and in fact the processors will have to wait in a kind of hardware queue to do their work. 1000 logically independent tasks distributed to these 4 processors by the load balancer scheduler can only be performed using queues.
Even in a fully parallel and conflict-free system, there are usually many queues — but these are implementation details that should not affect the result. You will get the same thing, no matter what place you occupy in any of the queues:
In contrast, in a competitive system, the queue is directly in the interface:
- The semaphore has a queue of threads waiting to block it, and the result depends on which of the threads gets to it first.
- The Erlang process has a message queue, and the result depends on who sends the message first.
- Gorutina listens to the channel, and the order of write operations to the channel affects the result.
- When using transactional memory, anyone who fails to complete a transaction becomes a queue.
- When using non-blocking containers, anyone who fails to update the container becomes a queue.
In event systems there can be both simple and intricate queues, but these are queues in the sense that order often influences the result, and this is normal - or there may be a race of conditions, such things.
In computational parallel conflict-free systems, the execution order should not affect the result — and you will need tools to ensure that the system is truly conflict-free.
Rob Pike on his slides shows how easy it is to write a load balancer on Go. Yes, just. Go is created for competition, and competition is associated with queues, as is load balancing. I would not say that load balancers are difficult to write in any language, but in a competitive language it is really simple.
But this is only part of the parallelism story. Next, you will need either static guarantees for the absence of conflicts, or dynamic checking. I’m not saying that you can’t do this on Go — you can definitely do it — just without it, you will not be able to use computing systems effectively. Having these mechanisms, you get a different set of interfaces and tools that differ from channels and Gorutin - even if it is implemented at the basic level with the help of channels and Gorutin.
Importance of crowding out
So, preventing or detecting conflicts is a necessary aspect of computing systems that is not supported by competitive tools. Are there things that are provided by competitive tools, but are not needed in computing systems?
Of course - first of all, these are obvious queues. In computing systems, they are not only unnecessary, but also interfere with work, because, as we have seen, queues provoke race conditions, not data races, and you cannot track such situations.
Another thing that, in essence, is not needed in computing systems is the very low-cost, displaced threads / processes.
In event processing systems, it is sometimes necessary to respond to a wide variety of events very quickly, and this requires many preemptive processes. It is necessary that in a situation where 10,000 processes are busy with current work, the system could still activate the process 10001 as soon as the corresponding event occurs. Such a mechanism can work only under the condition that the displaced processes are very low-cost.
In computing systems, it is convenient to have low-cost tasks that could be mapped to relatively costly operating system streams — but tasks are inferior in potential to processes. Tasks are not activated during events. Tasks are in different queues and are processed when the workflow is released, which can start them. Unlike situations with gorutinami, etc. you cannot have more current tasks than there are threads in the operating system - this is not necessary.
The tasks function well at the level of a normal performing environment as compared to fully functional low-cost processes / cores / etc., Which, in my opinion, are required to handle the low-level aspects of the system more closely.
(Honestly, some benefit from crowding out can also be extracted in a competitive system — namely, increasing throughput if the program allows new tasks that are part of a critical path to crowd out other tasks on the fly. However, in my long and bitter experience such a planner who truly recognizes critical paths exists only in theory. A stupid greedy planner is not suitable for crowding out.
Differences between tools in the same family
Tools aimed at the realization of competition in event systems, as well as similar tools in computing systems. They belong to the same family, but they have significant differences.
- Erlang does not allow processes to share memory at all. Thus, the data race will never occur, but this is not particularly impressive, because, as we have seen, the data race is easily detected automatically - and the race conditions are not eliminated by the ban on memory sharing. However, in this case, it is good that you can easily scale to multiple computers, and not just to multiple cores in the same processor.
- Rust does not allow sharing of memory, unless it is protected from changes. There is no simple scaling to several computers, but work on each computer is more efficient, there is no need for data race detectors, which can give false negative results due to poor test coverage. (It turned out that everything is a little different - this is an explanation, where it is also mentioned about plans to add tools for parallelism in Rust along with its competitive capabilities.)
- Go allows you to share anything, ensuring maximum performance due to the need for quite lifting (in my opinion) additional verification work. In the case of data races in Go there is a special detector , and the race conditions somehow occur in any systems.
- STM Haskell allows you to freely share immutable data, if you explicitly request it. In addition, it provides an interface for transactional memory - I think this is a cool thing, which is sometimes with great difficulty emulated by other methods. In Haskell, there are other tools for competition - for example, channels , and if you need scalability for several machines as in Erlang, then, obviously, this problem is solved with the help of Cloud Haskell .
Of course, much depends on the language in which you program - Erlang, Rust, Go and Haskell, respectively. And now about computing systems:
- Parallel Haskell just parallels clean code. Static guarantee of the absence of bugs with parallelism due to the absence of side effects.
- ParaSail allows for side effects, but with it you will have to give up many other things, such as pointers. As a result, it will calculate these or other things in parallel only if they do not share the variable data (for example, two elements of the array can be processed in parallel if the computer is sure that they do not overlap). Like Haskell, ParaSail supports competition to some extent, namely “competitive objects” that can be shared and changeable — and the documentation emphasizes the benefits of not using competitive tools if all you need is parallelism.
- Cilk is version C with keywords for parallel loops and function calls. This language allows shared use of mutable data (that is, you can shoot yourself in the foot, if you wish), but it is equipped with tools for the deterministic detection of such bugs if they do get caught in your test input. What is really useful is unlimited sharing of changeable data - this is an opportunity to do without a crossbow - that is, if the parallel loop normally performs calculations taking into account all the optimizations aimed at eliminating the side effects of any local task, and then ends, then no one can change the result these calculations. Again, the metaphor: the children get a gift each in a box of "Lego", then each builds something from their designer, and then everyone plays with the resulting toys together.
- The system checkedthreads is a lot like Cilk; it is not tied to language extensions, is completely open and free - not only the interface and the runtime, but also tools for finding bugs.
I wrote checkedthreads, so consider this a small advertisement; checkedthreads is a portable, free, secure environment that is already available in the most mainstream C and C ++ languages, unlike many systems designed for new languages or language extensions.
As for Cilk, work is underway to standardize it in C ++, but Cilk needs to add new keywords, but in the C ++ community they don’t like it. Cilk is available in gcc and LLVM branches, but it does not work on all platforms yet (it extends ABI). Some new Cilk features have been patented. Not all of them are freely available, etc. etc.
However, an important merit of Cilk is that Intel is responsible for its support, and for the support of checkedthreads - in essence, you yourself. If Cilk is right for you, and you decide to use it by reading my posts about checkedthreads, then my efforts to advertise automatic debugging of parallel programs were not in vain.
So: tools for competitive programming are not similar to each other, as well as tools for parallelism. I will not even argue that in this article I have pointed out all the important differences, a very intricate topic. However, the fact remains that we are talking about two very different classes of tools, and you decide which class to choose.
Conclusion
We discussed the differences between parallel, computing systems and competitive systems designed for event processing. The main areas of difference are:
- Determinism: desirable vs impossible
- Symptom of parallel security: identical results vs correct results
- Bugs with concurrency: easy to catch vs impossible to give a definition
- Queues: implementation detail vs interface part
- Repression: practically useless vs practically necessary
The most important detail of event processing systems is competition, and parallelism is an element of only some solutions, usually good ones (two vending machines are clearly better than one). In computing systems, parallelism is a key feature, and competition is a detail of some decisions, usually bad ones (a pile of gifts is worse than a decision where all gifts are signed).
I hope I managed to smooth out a little the confusion that arises when mixing “concurrency / competition” with “calculations / event handling”. In addition, I hope that the event handling systems were not put in the most unattractive light - perhaps there are automated verification strategies that I don’t know about. Anyway, I do not claim that the terminology of this article and the view of things set forth in it are the only correct ones.
Some people who are interested in event processing systems share a fairly reasonable point of view: “competition is working with several tasks at the same time, concurrency is the simultaneous execution of several tasks”. In this interpretation, parallelism is the implementation detail, and competition determines the structure of the program.
I think that my point of view is not without logic, namely: “competition is the solution of inevitable conflicts related to timing, concurrency is avoiding unnecessary conflicts” - “vending machines vs signed gifts”. This is how it looks - now parallel arrows do not overlap, logically everything is exactly like this:
The most important conclusion: the computational code, unlike the code for event processing, can be easily cleared from bugs by almost one hundred percent, using either automatic debugging tools or static guarantees.
Handling concurrency with tools specifically designed for this is not new. Sawzall, the specialized parallel language of Rob Pike, where the code is guaranteed not to contain bugs with parallelism, was the forerunner of the competitive language Go, developed by the same Pike.
However, at the moment the tools for competition look more “promoted” than the tools for parallelism - and they allow you to work with parallelism, albeit relatively poorly. Loud and bad often eclipses the less catchy, but good. It would be sad if support for concurrency is no longer improved, considering it as a side effect of “priority” competition — or this support will die out where it already exists now. I even rephrase the phrase “an attempt to parallelize sequential code is the solution to the wrong task” like this: “the use of purely competitive tools in the computational code is the solution to the wrong task”. There is a simple fact: the C code, paralleled with the right tools, is faster and safer than with Erlang.
So, the whole point is to “solve the problem with the help of suitable tools” and not let anyone snitch your Apple iPhone.
Source: https://habr.com/ru/post/274569/
All Articles