Graph databases: the holy grail for developers?
On Habré, debates about which databases are better and cooler, discussions about the prospects for SQL and NoSQL, do not abate. I could not resist and decided to speculate about where graph databases could be useful.

Before we begin, let's think about what information is on our agenda today? This is not just data - it is a very unpredictable structure, which over time can turn into either BigData or a complex semantic network, and often the developer cannot say in advance what it will be. So how do you choose a database — or at least its architecture — to create a really fast and efficient application?
To answer this question, let's try to systematize a little bit of the information about databases that we have. The first and most famous exploitation candidate is relational databases with their single SQL language. Simple, convenient and standard. It is through standardization that relational databases have gained popularity and dominate the market. But in fact, relational databases are just tables, where in each row there is a one-to-one correspondence between the key and its numerous (or few) parameters. While the applications were treated in separate tables and did not consider special interactions between themselves and different types of data, this was quite enough.
Relational database structure
As an alternative to SQL databases, the direction of NoSQL has been evolving since the early 2000s. Everything is combined into this category - from hierarchical and network databases (where, in addition to the hierarchy, additional links are provided) to simplified key-value databases and documentary databases without specific parameters for the values of each element. The reason for the evolution of this category of databases is the following: if you have primitive and single-type data sets, and queries concern a single table, then everything is OK, and you can work with SQL. But if not? If you need to refer to 10, 100, 1000 tables to process a request? Then the relational database starts to work slowly, and a lot of code is required to write a query.
')
Perhaps the most popular databases from the NoSQL category are documentary databases, in particular, MongoDB. They allow you to store objects with arbitrary sets of values, which is very convenient - for example, a payment order will have some fields, and an order will have others. And all this is stored in the same segment of the database, without subdivision into primitive tables. However, this approach also has limitations, which I will describe in a couple of paragraphs below.
Finally, a separate class, although they are traditionally attributed to NoSQL, are graph databases. They offer a more natural presentation of information based on the same logic that we encounter in real life. It is no secret that every social network is a graph, and the network model of the database is also actually a graph, but without the additional possibilities that the modern graph model opens. Therefore, graph databases are of particular interest to developers.
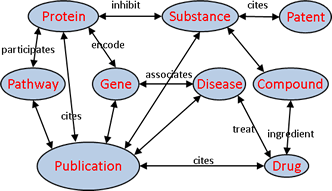
So, we have already talked about the relational architecture - this is an excellent solution for those cases when everything is simple and unequivocal, but completely cumbersome architecture for creating complex and flexible queries, processing diverse and multiple connections between objects. However, one should not forget about such advantages of SQL databases as the ability to create complex (JOIN) queries. This approach makes standardized relational databases more universal, because even with a large amount of code, each query can be implemented in them. For example, finding all people under the age of 20 who have red cars will be easy enough to do in SQL, while databases from the NoSQL category will require a lot of effort to solve this problem.

Illustration of a complex query in SQL
The direct alternative to SQL is document databases. Their main advantage is the absence of a single scheme of all elements (schemaless). Unlike SQL, these databases can save any complex object, for example, a document with a large number of fields in one operation, as well as output it in one operation. It is very convenient, for example, to add new categories of products to the online store catalog, because completely different properties will be used for a TV, microwave and iron. In the same MongoDB, you can work with them through short queries, while in SQL, to obtain and update such a complex record, you will have to create special procedures that perform many queries.
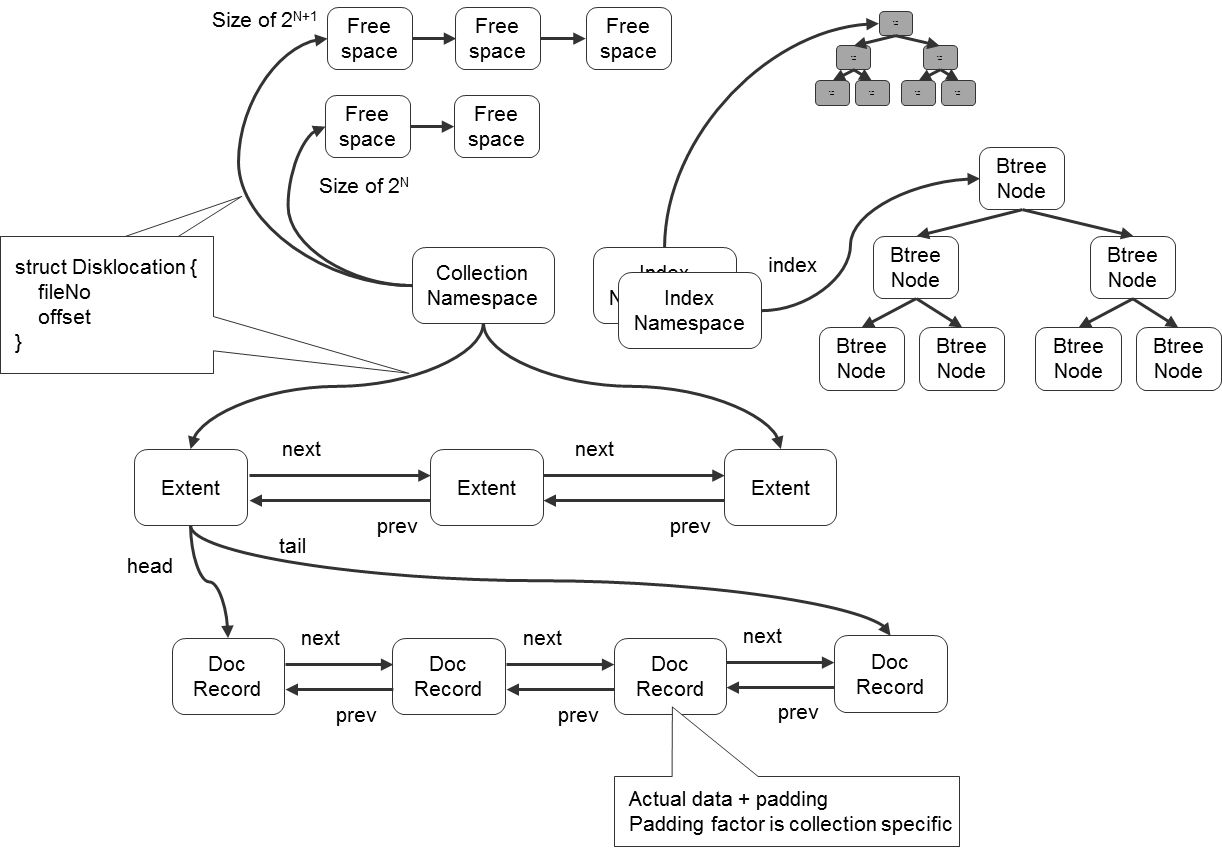
Illustration of storing various types of data in a document base
Cons of documentary bases also derive from their architectural features. For example, the document model does not imply such simple join functions (JOIN), as well as the ability to work with bidirectional links. In addition, the documentary base is designed for the storage of individual elements that do not have additional connections between them. A good example of the difficulties faced by the creators of the Diaspora social network is given here ( http://habrahabr.ru/post/231213/ ). The guys first began to actively exploit the advantages of the documentary model, but then they simply faced the fact that social data have many connections with each other and oh, it is very difficult to imagine in the form of separate “documents”. And they still had to go back to SQL.
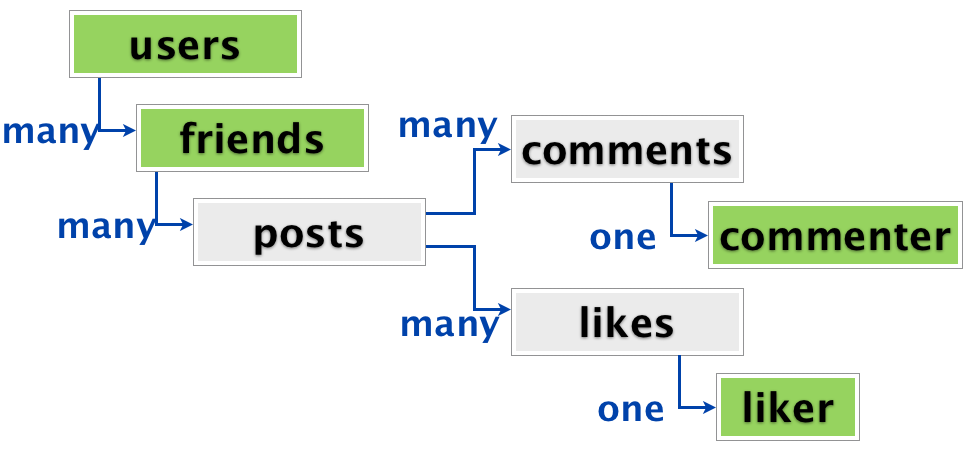
The structure of social data for which the documentary storage model did not fit
Now a little about the graphs. They are initially focused on relationships between objects, and these relationships may have different characteristics. For example, if a customer requires to develop a database of serials, where for each episode of each serial there are different actors, a hierarchical model that clearly fits in the document database emerges in the most obvious way. However, as soon as the customer says: “Listen, and let our system also display the actors' films in one click,” the entire hierarchy crumbles and you have to either modify the database (long and painfully) or change the data storage format.
The main advantage of graph databases in this light is universality, because they can store both relational, documentary and complex semantic data. And the database building model itself can change and be modified in the process of application development without changing the architecture and initial requests. And that means - you will not need to rewrite anything!
On the other hand, with a small number of connections and large amounts of data, graph database demonstrate significantly lower performance, and this must be kept in mind. Another important limitation is that at the moment there are practically no graph databases that would work well in parallel architectures.
However, since we are talking today about the development of applications, in the design process and even at the “grinding” stage, there are often new requirements for the data structure, and a good model can suddenly become bad. For example, the addition of new connections makes the document database unacceptable, and the increase in the number of JOINs dramatically reduces the performance of the relational database. In this case, the graphs are the most universal option, allowing to hedge against the case of changing requirements and expanding functionality in the future. Need to add extra relationships to relational data? No problem! Need to complicate the hierarchical documentary model? Easy!
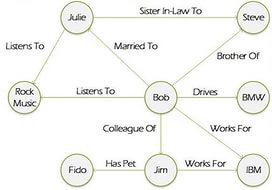
Graph data: many objects, many types of links between them
Moreover, today RDF, the main standard according to which graph databases work, is being actively developed. And, if we recall, it was SQL standardization that made relational databases so popular. At the same time, a number of projects demonstrate OData support for creating standard web requests via HTTP, as well as the SPARQL language, which has extensive capabilities for working with various types of queries and data (here you can draw an analogy with SQL for relational databases). But, finally, due to the development of the architecture, the performance of graph DBs is growing, and it may soon be higher than the relational one, even with a small number of links. So, perhaps, soon the graph database will become something like the Holy Grail for developers?
Before we begin, let's think about what information is on our agenda today? This is not just data - it is a very unpredictable structure, which over time can turn into either BigData or a complex semantic network, and often the developer cannot say in advance what it will be. So how do you choose a database — or at least its architecture — to create a really fast and efficient application?
To answer this question, let's try to systematize a little bit of the information about databases that we have. The first and most famous exploitation candidate is relational databases with their single SQL language. Simple, convenient and standard. It is through standardization that relational databases have gained popularity and dominate the market. But in fact, relational databases are just tables, where in each row there is a one-to-one correspondence between the key and its numerous (or few) parameters. While the applications were treated in separate tables and did not consider special interactions between themselves and different types of data, this was quite enough.
| City | Year of foundation | Population (persons) | Area (sq. Km) |
| St. Petersburg | 1703 | 5 131,942 | 1,439 |
| Moscow | 1147 | 12,108,257 | 2,511 |
| Yekaterinburg | 1723 | 1 412 346 | 495 |
| Vladivostok | 1860 | 603,244 | 3 3116 |
As an alternative to SQL databases, the direction of NoSQL has been evolving since the early 2000s. Everything is combined into this category - from hierarchical and network databases (where, in addition to the hierarchy, additional links are provided) to simplified key-value databases and documentary databases without specific parameters for the values of each element. The reason for the evolution of this category of databases is the following: if you have primitive and single-type data sets, and queries concern a single table, then everything is OK, and you can work with SQL. But if not? If you need to refer to 10, 100, 1000 tables to process a request? Then the relational database starts to work slowly, and a lot of code is required to write a query.
')
Perhaps the most popular databases from the NoSQL category are documentary databases, in particular, MongoDB. They allow you to store objects with arbitrary sets of values, which is very convenient - for example, a payment order will have some fields, and an order will have others. And all this is stored in the same segment of the database, without subdivision into primitive tables. However, this approach also has limitations, which I will describe in a couple of paragraphs below.
Finally, a separate class, although they are traditionally attributed to NoSQL, are graph databases. They offer a more natural presentation of information based on the same logic that we encounter in real life. It is no secret that every social network is a graph, and the network model of the database is also actually a graph, but without the additional possibilities that the modern graph model opens. Therefore, graph databases are of particular interest to developers.
Advantages and disadvantages
So, we have already talked about the relational architecture - this is an excellent solution for those cases when everything is simple and unequivocal, but completely cumbersome architecture for creating complex and flexible queries, processing diverse and multiple connections between objects. However, one should not forget about such advantages of SQL databases as the ability to create complex (JOIN) queries. This approach makes standardized relational databases more universal, because even with a large amount of code, each query can be implemented in them. For example, finding all people under the age of 20 who have red cars will be easy enough to do in SQL, while databases from the NoSQL category will require a lot of effort to solve this problem.
Illustration of a complex query in SQL
The direct alternative to SQL is document databases. Their main advantage is the absence of a single scheme of all elements (schemaless). Unlike SQL, these databases can save any complex object, for example, a document with a large number of fields in one operation, as well as output it in one operation. It is very convenient, for example, to add new categories of products to the online store catalog, because completely different properties will be used for a TV, microwave and iron. In the same MongoDB, you can work with them through short queries, while in SQL, to obtain and update such a complex record, you will have to create special procedures that perform many queries.
Illustration of storing various types of data in a document base
Cons of documentary bases also derive from their architectural features. For example, the document model does not imply such simple join functions (JOIN), as well as the ability to work with bidirectional links. In addition, the documentary base is designed for the storage of individual elements that do not have additional connections between them. A good example of the difficulties faced by the creators of the Diaspora social network is given here ( http://habrahabr.ru/post/231213/ ). The guys first began to actively exploit the advantages of the documentary model, but then they simply faced the fact that social data have many connections with each other and oh, it is very difficult to imagine in the form of separate “documents”. And they still had to go back to SQL.
The structure of social data for which the documentary storage model did not fit
Now a little about the graphs. They are initially focused on relationships between objects, and these relationships may have different characteristics. For example, if a customer requires to develop a database of serials, where for each episode of each serial there are different actors, a hierarchical model that clearly fits in the document database emerges in the most obvious way. However, as soon as the customer says: “Listen, and let our system also display the actors' films in one click,” the entire hierarchy crumbles and you have to either modify the database (long and painfully) or change the data storage format.
The main advantage of graph databases in this light is universality, because they can store both relational, documentary and complex semantic data. And the database building model itself can change and be modified in the process of application development without changing the architecture and initial requests. And that means - you will not need to rewrite anything!
On the other hand, with a small number of connections and large amounts of data, graph database demonstrate significantly lower performance, and this must be kept in mind. Another important limitation is that at the moment there are practically no graph databases that would work well in parallel architectures.
Are graphs still promising?
However, since we are talking today about the development of applications, in the design process and even at the “grinding” stage, there are often new requirements for the data structure, and a good model can suddenly become bad. For example, the addition of new connections makes the document database unacceptable, and the increase in the number of JOINs dramatically reduces the performance of the relational database. In this case, the graphs are the most universal option, allowing to hedge against the case of changing requirements and expanding functionality in the future. Need to add extra relationships to relational data? No problem! Need to complicate the hierarchical documentary model? Easy!
Graph data: many objects, many types of links between them
Moreover, today RDF, the main standard according to which graph databases work, is being actively developed. And, if we recall, it was SQL standardization that made relational databases so popular. At the same time, a number of projects demonstrate OData support for creating standard web requests via HTTP, as well as the SPARQL language, which has extensive capabilities for working with various types of queries and data (here you can draw an analogy with SQL for relational databases). But, finally, due to the development of the architecture, the performance of graph DBs is growing, and it may soon be higher than the relational one, even with a small number of links. So, perhaps, soon the graph database will become something like the Holy Grail for developers?
Source: https://habr.com/ru/post/274383/
All Articles