JOIN the dark side of the SQL
Unjustly ignored the emergence of SQL JOIN operations in a project based on Elasticsearch

The main difference between Crate.io and Elasticsearch is support for SQL as a query language and data modification in ES, as well as API and the ability to distribute binary data in a cluster.
I told a long time about the example of using the BLOB API in the Habré publication “How to find love or adventure with crate.io and kibana” . Elasticsearch allows you to store documents in a json cluster, index them and search them. Crate complements ES with the ability to work with data using SQL. In this article we will focus on the installation of crate, as well as on the execution of requests through the jdbc driver.
')
I suggest you approach to installing software from the maven repositories, which can be useful in java and groovy projects and not only for crate. In this article, we will install, configure, and launch a database server for experiments with JOIN using a script script.
To run the script, you need a special groovy-all: groovy-grape-aether-2.4.5.1.jar and the crate-io.groovy script itself :
This script creates the .crate-io directory in the user's home directory, checks if there is already the required version of the crate.io database inside the directory. If there is no compatible crate project repository from maven, the tar.gz format is downloaded and unpacked. In this case, the Elasticsearch API is enabled in the config / crate.yml configuration. In case of successful installation or if crate.io was installed earlier, the script starts the server.

After starting, you can connect to the web interface of the server http: // localhost: 4200 / admin in the browser

Thanks to the presto library and the developers of the crate.io project, it became possible to execute SQL queries in a database based on elasticsearch with the shared nothing architecture. From programs, you can perform queries using the client library for Java, Python, PHP, Erlang, REST API.
We are also interested in jdbc driver. And at the moment of downloading the driver there comes a horror from Crate JDBC standalone jar of 23.4MB size inside which for some reason all elasticsearch server is packed, and not just the client part of its API and transport implementation. Okay, I don’t feel sorry for the traffic, but why was it so ruthless to pack everything up !? If you have a maven proxy repository, this driver will be downloaded only once from your work network.
Maven dependency for Crate JDBC standalone from project repository :
To create a connection to the database did everything according to the instructions . But you can do the same programmatically, from another editor that supports the jdbc driver.
Configured driver:

Created and checked connection:

Created two tables:

Inserted entries in the table:

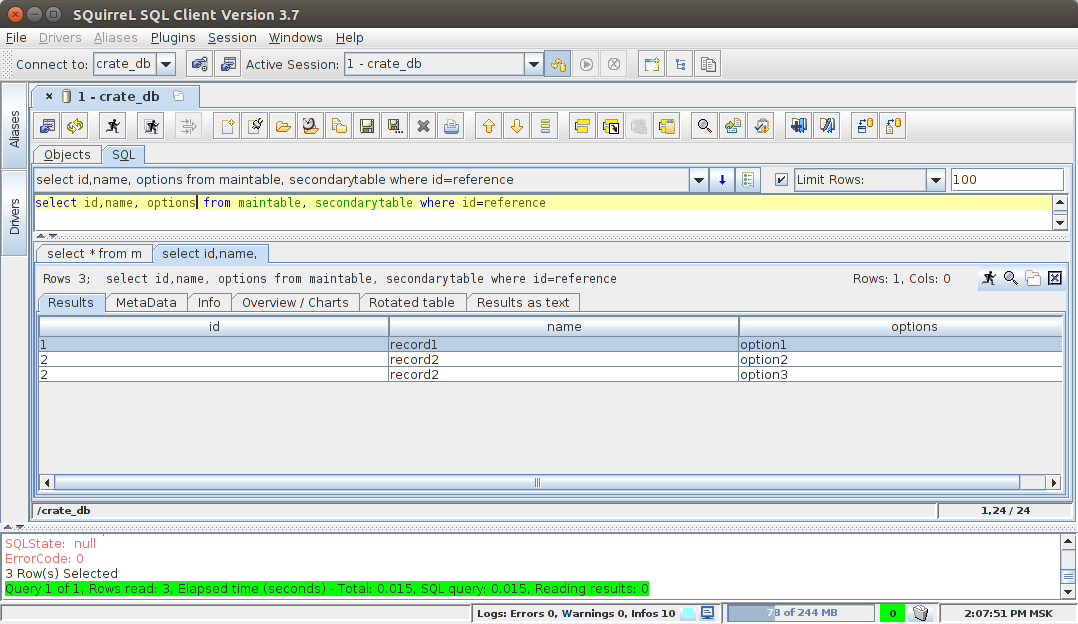
INNER JOIN:
CROSS JOIN:

Unfortunately, inner and cross join is all that crate.io can do for now. But the base is developing, so we are waiting for the outer join and further improvement of the existing functionality .
Crate.io - SQL add-on over NoSQL solution Elasticsearch, which in recent versions can do inner and cross join. To work with crate, you can use the jdbc driver and Kibana to visualize data, with some limitations. Crate can also store binary data distributed, in cluster process file systems.
Using the groovy script, we can install the version we need from the maven repository, update the configuration during the installation and start the server.
As with every solution, crate.io has its strengths:
The main difference between Crate.io and Elasticsearch is support for SQL as a query language and data modification in ES, as well as API and the ability to distribute binary data in a cluster.
I told a long time about the example of using the BLOB API in the Habré publication “How to find love or adventure with crate.io and kibana” . Elasticsearch allows you to store documents in a json cluster, index them and search them. Crate complements ES with the ability to work with data using SQL. In this article we will focus on the installation of crate, as well as on the execution of requests through the jdbc driver.
')
Install crate.io
I suggest you approach to installing software from the maven repositories, which can be useful in java and groovy projects and not only for crate. In this article, we will install, configure, and launch a database server for experiments with JOIN using a script script.
java -jar groovy-grape-aether-2.4.5.1.jar crate-io.groovy To run the script, you need a special groovy-all: groovy-grape-aether-2.4.5.1.jar and the crate-io.groovy script itself :
@Grab(group='org.codehaus.plexus', module='plexus-archiver', version='2.10.2') import org.codehaus.plexus.archiver.tar.TarGZipUnArchiver import com.github.igorsuhorukov.smreed.dropship.MavenClassLoader; @Grab(group='org.codehaus.plexus', module='plexus-container-default', version='1.6') import org.codehaus.plexus.logging.console.ConsoleLogger; def artifact = 'crate' def version = '0.54.1' def userHome= System.getProperty('user.home') def destDir = new File("$userHome/.crate-io") def crateIoDir= new File(destDir, "$artifact-$version"); if(!crateIoDir.exists()){ destDir.mkdirs() String sourceFile = MavenClassLoader.using("https://dl.bintray.com/crate/crate/").getArtifactUrlsCollection("io.crate:$artifact:tar.gz:$version", null).get(0).getFile() final TarGZipUnArchiver unArchiver = new TarGZipUnArchiver() unArchiver.setSourceFile(new File(sourceFile)) unArchiver.enableLogging(new ConsoleLogger(ConsoleLogger.LEVEL_DEBUG,"Logger")) unArchiver.setDestDirectory(destDir) unArchiver.extract() def crateCfg = new File("$crateIoDir.absolutePath/config/crate.yml") crateCfgText = crateCfg.text crateCfg.withWriter { w -> w << crateCfgText.replace('# es.api.enabled: false', 'es.api.enabled: true') } } def proc = "$crateIoDir.absolutePath/bin/crate".execute() proc.consumeProcessOutput(System.out, System.err) proc.waitFor() This script creates the .crate-io directory in the user's home directory, checks if there is already the required version of the crate.io database inside the directory. If there is no compatible crate project repository from maven, the tar.gz format is downloaded and unpacked. In this case, the Elasticsearch API is enabled in the config / crate.yml configuration. In case of successful installation or if crate.io was installed earlier, the script starts the server.
After starting, you can connect to the web interface of the server http: // localhost: 4200 / admin in the browser
Crate.io jdbc
Thanks to the presto library and the developers of the crate.io project, it became possible to execute SQL queries in a database based on elasticsearch with the shared nothing architecture. From programs, you can perform queries using the client library for Java, Python, PHP, Erlang, REST API.
We are also interested in jdbc driver. And at the moment of downloading the driver there comes a horror from Crate JDBC standalone jar of 23.4MB size inside which for some reason all elasticsearch server is packed, and not just the client part of its API and transport implementation. Okay, I don’t feel sorry for the traffic, but why was it so ruthless to pack everything up !? If you have a maven proxy repository, this driver will be downloaded only once from your work network.
Maven dependency for Crate JDBC standalone from project repository :
<dependency> <groupId>io.crate</groupId> <artifactId>crate-jdbc-standalone</artifactId> <version>1.9.3</version> <dependency> To create a connection to the database did everything according to the instructions . But you can do the same programmatically, from another editor that supports the jdbc driver.
Configured driver:
Created and checked connection:
Created two tables:
create table maintable( id integer primary key, name string ); create table secondarytable ( reference integer, options string ); Inserted entries in the table:
insert into maintable(id,name) values(1,'record1'); insert into maintable(id,name) values(2, 'record2'); insert into secondarytable(reference,options) values(1,'option1'); insert into secondarytable(reference,options) values(2,'option2'); insert into secondarytable(reference,options) values(2,'option3'); insert into secondarytable(reference,options) values(null,'other option'); INNER JOIN:
select id, name, options from maintable, secondarytable where id=reference CROSS JOIN:
select id,name, options from maintable, secondarytable Unfortunately, inner and cross join is all that crate.io can do for now. But the base is developing, so we are waiting for the outer join and further improvement of the existing functionality .
Conclusion
Crate.io - SQL add-on over NoSQL solution Elasticsearch, which in recent versions can do inner and cross join. To work with crate, you can use the jdbc driver and Kibana to visualize data, with some limitations. Crate can also store binary data distributed, in cluster process file systems.
Using the groovy script, we can install the version we need from the maven repository, update the configuration during the installation and start the server.
As with every solution, crate.io has its strengths:
- The possibility of horizontal scaling (shared nothing architecture)
- SQL as a query and data manipulation language, limited JOIN support in queries
- Distributed storage of binary data in the file system and access to it in a cluster
- Possibility (albeit limited) of using Elasticsearch API, Kibana and existing tools for ES
- Inferior object-relational databases on functionality
- From ACID Elasticsearch only supports Durability
Source: https://habr.com/ru/post/274315/
All Articles