Why does percentile calculation not work as expected?
Often clients ask us about the p99-metric (99th percentile).
This is definitely a reasonable request and we plan to add similar functionality to VividCortex (I’ll talk about this later). But at the same time, when customers ask about it, they imply something completely definite - something that can be a problem. They ask not the 99th percentile for some metric, they ask for the metric for the 99th percentile . This is common for systems such as Graphite , but this does not give the result that is expected from such systems. This post will tell you that you may have misconceptions about percentiles, the exact extent of your misconceptions, and what you can do right in this case.
(This is a translation of the article Baron Schwartz wrote.)
In the past few years, many people have immediately started talking about the fact that there are a number of problems in monitoring by means of averages. It is good that this topic has become actively discussed now, because for a long time the average values of the parameters in the monitoring were generated and accepted without any careful analysis.
')
Average values are a problem and hardly help when it comes to monitoring. If you are just watching the averages, you are likely to miss the data that has the greatest impact on your system: when looking for any problems, events that are especially important to you will, by definition, be emissions. There are two problems with average values in case of outliers:
So when you average any metric in the system with errors, you combine all the worst: you see the not quite normal state of the system, but at the same time you do not see anything unusual.
By the way, the work of most software systems is simply teeming with extreme emissions.
Viewing the emissions in the long tail by the frequency of occurrence is very important because it shows you exactly how badly you make inquiries in some rare cases. You will not see this if you work only with the average.
As Werner Vogels from Amazon said at the opening re: Invent: the only thing that averages can tell you is that half of your customers you serve are even worse. (Although this statement is absolutely correct in spirit, it does not quite reflect reality: it would be more correct to say about the median (it’s the 50th percentile) - it is this metric that provides the indicated property)
The company Optimizely published an entry in this post a couple of years ago. She perfectly explains why averages can lead to unexpected consequences:
Brendan Gregg also explained this well :
Percentiles (quantiles - in a broader sense) are often extolled as a means to overcome this fundamental lack of averages. The meaning of the 99th percentile is to collect the entire set of data (in other words, the entire collection of system measurements) and sort them, then discard the 1% largest and take the greatest value from the remaining ones. The resulting value has two important properties:
Of course, you do not have to choose exactly 99%. The 90th, 95th, and 99.9th (or even more nines) percentiles are common variants.
And now you suppose: the average is bad, and percentiles are great - let's calculate the percentages by metrics and store them in our storage for storing time series ( TSDB )? But everything is not so simple.
There is a big problem with percentiles in the time series of data. The problem is that most TSDBs almost always store aggregated metrics on time intervals, rather than the entire sample of measured events. Subsequently, TSDB averaged these metrics over time in a number of cases. The most important:
And here comes the problem. You are again dealing with averaging in some form. Percentile averaging does not work, because to calculate the percentile at a new scale, you must have a full sample of events. All calculations are in fact incorrect. Percentile averaging has no meaning. (The consequences of this can be arbitrary. I will come back to this later.)

Unfortunately, some common open-source monitoring products incite the use of percentile metrics, which in fact will then be resampled when saved. For example, StatsD, allows you to calculate the desired percentile and then generates a metric with a name like foo.upper_99 and periodically drops them to save to Graphite. Everything is fine if the discreteness of time does not change when viewed, but we know that this happens all the same.
A misunderstanding of how all these calculations occur is extremely common. Reading the comment thread for this StatsD GitHub ticket is an example of this. Some comrades there are talking about things that have nothing to do with reality.

Perhaps the shortest way to identify a problem would be to say this: Percentiles are calculated from a collection of dimensions and must be recalculated completely every time this collection changes. TSDB periodically averages data over different time intervals, but at the same time does not store the original sample of measurements.
But, if the calculation of percentiles really requires a complete selection of the original events (for example, each time each web page is loaded), then in this case we have a big problem. The problem of "Big Data" - it will be more accurate to say so. That is why the truthful calculation of percentiles is extremely expensive.
There are several ways to calculate * approximate "percentiles that are almost as good as storing a complete sample of measurements and then sorting and calculating it. You can find a lot of research in various areas including:
The essence of most of these solutions is to approximate the distribution of the collection in one way or another. From distribution information, you can calculate approximate percentiles, as well as some other interesting metrics. Again, from the Optimizely blog, you can give an interesting example of the distribution of response times, as well as the average and 99th percentile:

There are many ways to calculate and store approximate distributions, but histograms are especially popular because of their relative simplicity. Some monitoring solutions support histograms. Circonus for example, one of these. Theo Schlossnagle, CEO of Circonus, often writes about the advantages of histograms.
Ultimately, having the distribution of the original collection of events is useful not only for calculating percentiles, but also allows you to identify some things that percentiles cannot say. In the end, the percentile is just a number that is only trying to reflect a large amount of information about the data. I will not go as far as Theo did when he tweeted that “the 99th is no better than the average,” because here I agree with the fans of percentiles that they are much more informative than the average values in the presentation Some important characteristics of the original sample. Nevertheless, the percentiles are not so good to tell you about the data, as more detailed histograms. The illustration from Optimizely above contains an order of magnitude more information than any single number can do.
The best way to calculate percentiles in TSDB is to collect metrics by range. I made a similar assumption, since the multitude of TSDBs are in fact only key-value collections ordered by timestamp without the ability to store histograms.
Range metrics provide the same capabilities as a histogram sequence over time. All you need to do is select the limits that will divide the values by range, and then calculate all the metrics separately for each of the ranges. The metric will be the same as for the histogram: namely, the number of events whose values fall into this range.
But in general, the choice of ranges for separation is not an easy task. Usually a good choice would be ranges with logarithmically progressive sizes or ranges that provide storage of coarse values to speed up the calculations (at the cost of avoiding the smooth growth of counters). But ranges with the same size are unlikely to be a good choice. More information on this topic is in a note from Brendan Gregg .
There is a fundamental contradiction between the amount of stored data and their degree of accuracy. However, even a coarse distribution of the ranges provides a better presentation of the data than the average. For example, Phusion Passenger Union Station displays timeout metrics for 11 ranges. (It doesn’t seem to me at all that the above illustration is vivid; the value along the y axis is somewhat embarrassing, in fact, this is a 3D graph projected in a 2D nonlinear way. It doesn’t give him more information than the average value.)
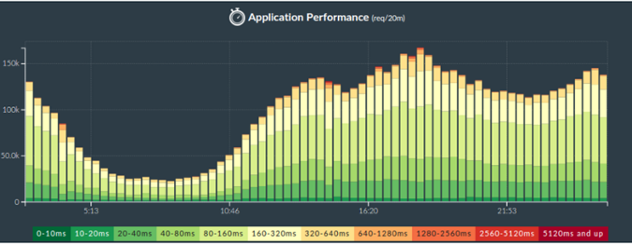
How can this be implemented using popular open-source products? You must define the ranges and create columns in the form of piles as in the figure above.
But to calculate the percentile from this data will now be much more difficult. You will have to go through all the ranges in the reverse order, from large to smaller, summarizing the number of events along the way. As soon as you get the sum of the number of events greater than 1% of the total, then this range will store the value of 99% of the percentile. There are a lot of nuances - lax equality; exactly how to handle borderline cases, what value to choose for the percentile (range from above or below? or maybe in the middle? or can be weighted from all?).
In general, such calculations can be very confusing. For example, you can assume that you need 100 ranges to calculate the 99th percentile, but in fact, everything could be different. If you have only two ranges and 1% of all values fall into the upper one, then you can get a 99% percentile and so on. (If this seems strange to you, then think about quantiles in general; I think that understanding the essence of quantiles is very valuable.)
So it's not all simple. This is possible in theory, but in practice it strongly depends on whether the repository supports the necessary types of queries to obtain approximate percentile values for range metrics. If you know the repositories in which this is possible - write in the comments (on the author’s website - approx. Lane )
The good thing is that in systems like Graphite (that is, those that expect that all metrics can be freely averaged and resampled), all range metrics are absolutely resistant to these types of transformations. You will get the correct values because all calculations are commutative with respect to time.
A percentile is just a number, as well as an average. The average displays the center of mass of the sample, the percentile shows the mark of the upper level of the specified fraction of the sample. Think of percentiles as traces of the waves on the beach. But, although the percentile displays the upper levels, and not only the central trend as an average, it is still not as informative and detailed as compared to the distribution, which in turn describes the entire sample as a whole.
Meet, there are heat maps - which are actually 3D graphs in which the histograms are rotated and aligned together over time, and the values are displayed in color. Again, Circonus provides an excellent example of heat map visualization .
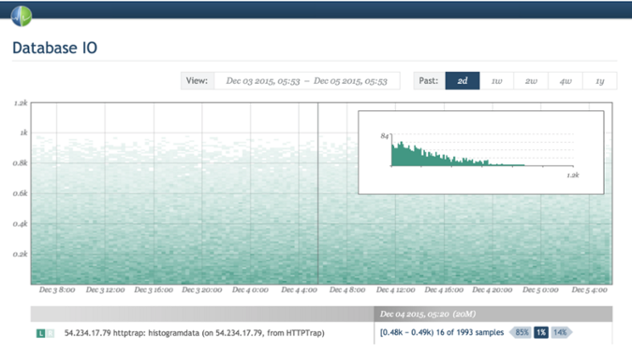
On the other hand, as I know, Graphite does not yet provide the ability to create heat maps for range metrics. If I'm wrong and this can be done with the help of some kind of trick - let me know.
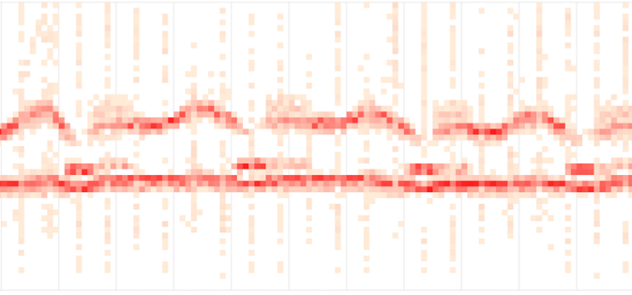
Heat maps are also great for displaying the shape and density of delays in particular. Another example of a delayed heatmap is a summary of streaming delivery from Fastly .
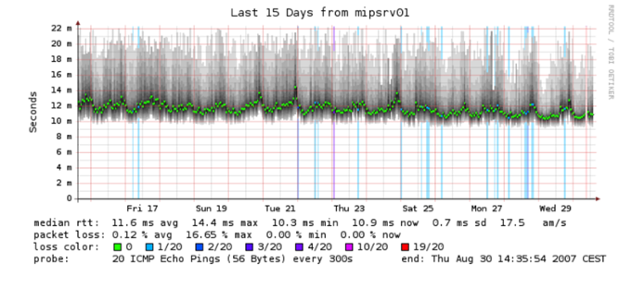
Even some ancient tools that already seem to you primitive can create heat maps. For example, Smokeping, uses shading to display ranges of values. Bright green indicates average:
Well, after all the mentioned difficulties and nuances that need to be taken into account, perhaps the good old StatsD-metric upper_99 to show percentiles does not seem so bad to you. In the end, it is very simple, convenient and ready to use. Is this metric so bad?
It all depends on the circumstances. For a variety of usage scenarios, they are great. I mean, in any case, you still limit yourself to the fact that the percentiles do not always describe the data well. But if it doesn't matter to you, then the biggest problem for you is oversampling of these metrics, which will mean that you will then watch for incorrect data.
But measuring is generally the wrong thing - in any case, and besides, a lot of essentially wrong things are nonetheless still somehow useful. For example, I could tell that a good half of the metrics that people look at are actually already deliberately distorted. For example, load average for systems is indicative. This parameter is undoubtedly useful, but as soon as you know exactly how this “sausage” is made , you may be shocked at first. (On Habré there is an excellent article about the calculation of LA - approx. Per. ) Similarly, many systems in the same way compactly display various metrics of their performance. Many of the Cassandra metrics are the result of the Metrics library (Coda Hale) and are in fact a floating average (an exponentially weighted floating average ) to which many people have a permanent aversion .
But back to the metrics on percentiles. If you save the p99 metric, then reduce and view the average version over a long period of time - although it may not be “correct” and it may even be that the graph will be quite different from the real value of the 99th percentile, but that it will wrong, does not necessarily mean that this schedule can not be used for the desired purposes, namely to understand the worst cases in the interaction of users with your application.
So it all depends on the case. If you understand how percented work and the fact that averaging percentiles is wrong, and it suits you, then storage of percentiles can be acceptable and even useful. But here you bring a moral dilemma: with this approach, you can greatly embarrass unsuspecting people (maybe even your colleagues). Look at the comments to the ticket on StatsD again: the lack of understanding of the essence of the process is directly felt.
Let me not draw the best analogy: I sometimes use from my fridge such things that I would never have suggested to others. Just ask my wife about it. (Author's wife - comment. ). If you give people a bottle labeled "alcohol" and it contains methanol, then these people will go blind. But some will ask: “what kind of alcohol is contained in this bottle?” You better stick to the same measure of responsibility in relation to such questions.
At the moment, our TSDB does not support histograms and we do not support the calculation and preservation of percentiles (although you can simply send us any of your metrics if necessary).
For the future, we plan to support the storage of high-resolution band metrics, that is, metrics with a large number of ranges. We will be able to implement something similar, since most of the ranges are likely to be empty and our TSDB will be able to efficiently process sparse data (it is also likely that after averaging over time they will not be so sparse anymore - approx. Per. ). This will enable us to display histograms once a second (all our data is stored with a resolution of 1 second). The band metrics will be redeclared to 1-minute resolution after the period specified in the settings, which is set to 3 days by default. In this case, the band metrics will be resampled to a 1-minute resolution without any mathematical problems.
And as a result, from these range metrics we will get the opportunity to get any desired percentile, show the estimated error, show the heat map and show the distribution curve.
This will not be fast in implementation and will require a lot of effort from engineers, but the work has begun and the system has already been designed to take all this into account. I cannot promise exactly when it will be implemented, but I consider it necessary to tell about our long-term plans.
The post turned out to be somewhat longer than I first conceived, but I touched on many topics.
Hope it was all helpful to you.
This is definitely a reasonable request and we plan to add similar functionality to VividCortex (I’ll talk about this later). But at the same time, when customers ask about it, they imply something completely definite - something that can be a problem. They ask not the 99th percentile for some metric, they ask for the metric for the 99th percentile . This is common for systems such as Graphite , but this does not give the result that is expected from such systems. This post will tell you that you may have misconceptions about percentiles, the exact extent of your misconceptions, and what you can do right in this case.
(This is a translation of the article Baron Schwartz wrote.)
We refuse average
In the past few years, many people have immediately started talking about the fact that there are a number of problems in monitoring by means of averages. It is good that this topic has become actively discussed now, because for a long time the average values of the parameters in the monitoring were generated and accepted without any careful analysis.
')
Average values are a problem and hardly help when it comes to monitoring. If you are just watching the averages, you are likely to miss the data that has the greatest impact on your system: when looking for any problems, events that are especially important to you will, by definition, be emissions. There are two problems with average values in case of outliers:
- Averages hide emissions and you don’t see them.
- Emissions shift the mean values, so that in the system in which there are outliers, the mean values no longer reflect the normal state of the system.
So when you average any metric in the system with errors, you combine all the worst: you see the not quite normal state of the system, but at the same time you do not see anything unusual.
By the way, the work of most software systems is simply teeming with extreme emissions.
Viewing the emissions in the long tail by the frequency of occurrence is very important because it shows you exactly how badly you make inquiries in some rare cases. You will not see this if you work only with the average.
As Werner Vogels from Amazon said at the opening re: Invent: the only thing that averages can tell you is that half of your customers you serve are even worse. (Although this statement is absolutely correct in spirit, it does not quite reflect reality: it would be more correct to say about the median (it’s the 50th percentile) - it is this metric that provides the indicated property)
The company Optimizely published an entry in this post a couple of years ago. She perfectly explains why averages can lead to unexpected consequences:
“Although the mean values are very easy to understand, they can also lead to the strongest misconceptions. Why? Because monitoring the average response time is like measuring the average temperature of a hospital. While what really cares for you is the temperature of each patient and, in particular, which patient needs your help first. ”
Brendan Gregg also explained this well :
“As a statistical characteristic, average values (including arithmetic average) have many advantages in practical use. However, the ability to describe the distribution of values is not one of them. ”
Forward to percentiles
Percentiles (quantiles - in a broader sense) are often extolled as a means to overcome this fundamental lack of averages. The meaning of the 99th percentile is to collect the entire set of data (in other words, the entire collection of system measurements) and sort them, then discard the 1% largest and take the greatest value from the remaining ones. The resulting value has two important properties:
- This is the largest value of the values obtained in 99% of cases. If this value, for example, is a measurement of the load time of a web page, then it reflects the worst case of service, which is obtained at least with 99% of visits to your service.
- This value is resistant to really strong emissions that occur for a variety of reasons, including measurement errors.
Of course, you do not have to choose exactly 99%. The 90th, 95th, and 99.9th (or even more nines) percentiles are common variants.
And now you suppose: the average is bad, and percentiles are great - let's calculate the percentages by metrics and store them in our storage for storing time series ( TSDB )? But everything is not so simple.
How exactly TSDB stores and processes metrics
There is a big problem with percentiles in the time series of data. The problem is that most TSDBs almost always store aggregated metrics on time intervals, rather than the entire sample of measured events. Subsequently, TSDB averaged these metrics over time in a number of cases. The most important:
- They average the metrics if the discreteness of time in your query differs from the discreteness of time that was used to aggregate the data while saving. If you want to display a graph of the metrics per day, for example, 600px wide, then each pixel will reflect 144 seconds of data. This averaging is implicit and users are unaware of it. But in reality, these services should have issued a warning!
- TSDBs average the data when they are stored for long-term storage at a lower resolution, which is what happens in most TSDBs.
And here comes the problem. You are again dealing with averaging in some form. Percentile averaging does not work, because to calculate the percentile at a new scale, you must have a full sample of events. All calculations are in fact incorrect. Percentile averaging has no meaning. (The consequences of this can be arbitrary. I will come back to this later.)
Unfortunately, some common open-source monitoring products incite the use of percentile metrics, which in fact will then be resampled when saved. For example, StatsD, allows you to calculate the desired percentile and then generates a metric with a name like foo.upper_99 and periodically drops them to save to Graphite. Everything is fine if the discreteness of time does not change when viewed, but we know that this happens all the same.
A misunderstanding of how all these calculations occur is extremely common. Reading the comment thread for this StatsD GitHub ticket is an example of this. Some comrades there are talking about things that have nothing to do with reality.
“Susie, how many are 12 + 7?”
- Billion!
- Thank!
“... uh, but that can't seem to be true?”
- the same thing she said about 3 + 4
Perhaps the shortest way to identify a problem would be to say this: Percentiles are calculated from a collection of dimensions and must be recalculated completely every time this collection changes. TSDB periodically averages data over different time intervals, but at the same time does not store the original sample of measurements.
Other ways to calculate percentiles
But, if the calculation of percentiles really requires a complete selection of the original events (for example, each time each web page is loaded), then in this case we have a big problem. The problem of "Big Data" - it will be more accurate to say so. That is why the truthful calculation of percentiles is extremely expensive.
There are several ways to calculate * approximate "percentiles that are almost as good as storing a complete sample of measurements and then sorting and calculating it. You can find a lot of research in various areas including:
- histograms that divide the entire collection of events by ranges (or baskets) and then calculate how many events fall into each of the ranges (baskets)
- approximate data stream structures and algorithms (sketching, "sketchs")
- repositories that select from a collection of events to provide approximate answers
- solutions with time, quantity, or both at once
The essence of most of these solutions is to approximate the distribution of the collection in one way or another. From distribution information, you can calculate approximate percentiles, as well as some other interesting metrics. Again, from the Optimizely blog, you can give an interesting example of the distribution of response times, as well as the average and 99th percentile:
There are many ways to calculate and store approximate distributions, but histograms are especially popular because of their relative simplicity. Some monitoring solutions support histograms. Circonus for example, one of these. Theo Schlossnagle, CEO of Circonus, often writes about the advantages of histograms.
Ultimately, having the distribution of the original collection of events is useful not only for calculating percentiles, but also allows you to identify some things that percentiles cannot say. In the end, the percentile is just a number that is only trying to reflect a large amount of information about the data. I will not go as far as Theo did when he tweeted that “the 99th is no better than the average,” because here I agree with the fans of percentiles that they are much more informative than the average values in the presentation Some important characteristics of the original sample. Nevertheless, the percentiles are not so good to tell you about the data, as more detailed histograms. The illustration from Optimizely above contains an order of magnitude more information than any single number can do.
Even better percentiles in TSDB
The best way to calculate percentiles in TSDB is to collect metrics by range. I made a similar assumption, since the multitude of TSDBs are in fact only key-value collections ordered by timestamp without the ability to store histograms.
Range metrics provide the same capabilities as a histogram sequence over time. All you need to do is select the limits that will divide the values by range, and then calculate all the metrics separately for each of the ranges. The metric will be the same as for the histogram: namely, the number of events whose values fall into this range.
But in general, the choice of ranges for separation is not an easy task. Usually a good choice would be ranges with logarithmically progressive sizes or ranges that provide storage of coarse values to speed up the calculations (at the cost of avoiding the smooth growth of counters). But ranges with the same size are unlikely to be a good choice. More information on this topic is in a note from Brendan Gregg .
There is a fundamental contradiction between the amount of stored data and their degree of accuracy. However, even a coarse distribution of the ranges provides a better presentation of the data than the average. For example, Phusion Passenger Union Station displays timeout metrics for 11 ranges. (It doesn’t seem to me at all that the above illustration is vivid; the value along the y axis is somewhat embarrassing, in fact, this is a 3D graph projected in a 2D nonlinear way. It doesn’t give him more information than the average value.)
How can this be implemented using popular open-source products? You must define the ranges and create columns in the form of piles as in the figure above.
But to calculate the percentile from this data will now be much more difficult. You will have to go through all the ranges in the reverse order, from large to smaller, summarizing the number of events along the way. As soon as you get the sum of the number of events greater than 1% of the total, then this range will store the value of 99% of the percentile. There are a lot of nuances - lax equality; exactly how to handle borderline cases, what value to choose for the percentile (range from above or below? or maybe in the middle? or can be weighted from all?).
In general, such calculations can be very confusing. For example, you can assume that you need 100 ranges to calculate the 99th percentile, but in fact, everything could be different. If you have only two ranges and 1% of all values fall into the upper one, then you can get a 99% percentile and so on. (If this seems strange to you, then think about quantiles in general; I think that understanding the essence of quantiles is very valuable.)
So it's not all simple. This is possible in theory, but in practice it strongly depends on whether the repository supports the necessary types of queries to obtain approximate percentile values for range metrics. If you know the repositories in which this is possible - write in the comments (on the author’s website - approx. Lane )
The good thing is that in systems like Graphite (that is, those that expect that all metrics can be freely averaged and resampled), all range metrics are absolutely resistant to these types of transformations. You will get the correct values because all calculations are commutative with respect to time.
Beyond Percentiles: Heat Maps
A percentile is just a number, as well as an average. The average displays the center of mass of the sample, the percentile shows the mark of the upper level of the specified fraction of the sample. Think of percentiles as traces of the waves on the beach. But, although the percentile displays the upper levels, and not only the central trend as an average, it is still not as informative and detailed as compared to the distribution, which in turn describes the entire sample as a whole.
Meet, there are heat maps - which are actually 3D graphs in which the histograms are rotated and aligned together over time, and the values are displayed in color. Again, Circonus provides an excellent example of heat map visualization .
On the other hand, as I know, Graphite does not yet provide the ability to create heat maps for range metrics. If I'm wrong and this can be done with the help of some kind of trick - let me know.
Heat maps are also great for displaying the shape and density of delays in particular. Another example of a delayed heatmap is a summary of streaming delivery from Fastly .
Even some ancient tools that already seem to you primitive can create heat maps. For example, Smokeping, uses shading to display ranges of values. Bright green indicates average:
But is it really bad to store metrics on percentiles?
Well, after all the mentioned difficulties and nuances that need to be taken into account, perhaps the good old StatsD-metric upper_99 to show percentiles does not seem so bad to you. In the end, it is very simple, convenient and ready to use. Is this metric so bad?
It all depends on the circumstances. For a variety of usage scenarios, they are great. I mean, in any case, you still limit yourself to the fact that the percentiles do not always describe the data well. But if it doesn't matter to you, then the biggest problem for you is oversampling of these metrics, which will mean that you will then watch for incorrect data.
But measuring is generally the wrong thing - in any case, and besides, a lot of essentially wrong things are nonetheless still somehow useful. For example, I could tell that a good half of the metrics that people look at are actually already deliberately distorted. For example, load average for systems is indicative. This parameter is undoubtedly useful, but as soon as you know exactly how this “sausage” is made , you may be shocked at first. (On Habré there is an excellent article about the calculation of LA - approx. Per. ) Similarly, many systems in the same way compactly display various metrics of their performance. Many of the Cassandra metrics are the result of the Metrics library (Coda Hale) and are in fact a floating average (an exponentially weighted floating average ) to which many people have a permanent aversion .
But back to the metrics on percentiles. If you save the p99 metric, then reduce and view the average version over a long period of time - although it may not be “correct” and it may even be that the graph will be quite different from the real value of the 99th percentile, but that it will wrong, does not necessarily mean that this schedule can not be used for the desired purposes, namely to understand the worst cases in the interaction of users with your application.
So it all depends on the case. If you understand how percented work and the fact that averaging percentiles is wrong, and it suits you, then storage of percentiles can be acceptable and even useful. But here you bring a moral dilemma: with this approach, you can greatly embarrass unsuspecting people (maybe even your colleagues). Look at the comments to the ticket on StatsD again: the lack of understanding of the essence of the process is directly felt.
Let me not draw the best analogy: I sometimes use from my fridge such things that I would never have suggested to others. Just ask my wife about it. (Author's wife - comment. ). If you give people a bottle labeled "alcohol" and it contains methanol, then these people will go blind. But some will ask: “what kind of alcohol is contained in this bottle?” You better stick to the same measure of responsibility in relation to such questions.
What exactly does VividCortex do?
At the moment, our TSDB does not support histograms and we do not support the calculation and preservation of percentiles (although you can simply send us any of your metrics if necessary).
For the future, we plan to support the storage of high-resolution band metrics, that is, metrics with a large number of ranges. We will be able to implement something similar, since most of the ranges are likely to be empty and our TSDB will be able to efficiently process sparse data (it is also likely that after averaging over time they will not be so sparse anymore - approx. Per. ). This will enable us to display histograms once a second (all our data is stored with a resolution of 1 second). The band metrics will be redeclared to 1-minute resolution after the period specified in the settings, which is set to 3 days by default. In this case, the band metrics will be resampled to a 1-minute resolution without any mathematical problems.
And as a result, from these range metrics we will get the opportunity to get any desired percentile, show the estimated error, show the heat map and show the distribution curve.
This will not be fast in implementation and will require a lot of effort from engineers, but the work has begun and the system has already been designed to take all this into account. I cannot promise exactly when it will be implemented, but I consider it necessary to tell about our long-term plans.
findings
The post turned out to be somewhat longer than I first conceived, but I touched on many topics.
- If you plan to calculate percentiles for some interval and then save the result in the form of time series - as some existing storages do - you may not get exactly what you are counting on.
- Exact calculation of percentiles requires large computational costs.
- Approximate values for percentiles can be calculated from histograms, range metrics, and other useful computing techniques.
- Such data will also allow to issue distributions and heatmaps, which will be even more informative than simple percentiles.
- If all this is not available right now or you cannot afford it, roll it, use metrics on pertsentiles, but remember the consequences.
Hope it was all helpful to you.
PS
- Someone mentioned on Twitter about the effect: “Oops, pntnko, I find myself doing something somehow wrong. But I switched to counting the percentage of requests that are executed in a time smaller / larger than the specified value and save this metric instead of the old one. ”But this also does not work. The approach with the calculation of the average shares (and the percentage is the share) still does not work. Instead, save the metric of the number of requests that are not executed in the desired time. Here it will work.
- I could not immediately find an excellent post from Theo on this topic. Here it is: http://www.circonus.com/problem-math/
Source: https://habr.com/ru/post/274303/
All Articles