The project to translate the Wolfram Language (Mathematica) into various languages

Translation of the post by Eila Stiegler " The Wolfram Language Worldwide Translations Project ".
The code given in the article can be downloaded here , additional code for the post can be downloaded here .
Many thanks to Kirill Guzenko KirillGuzenko for his help in translating and preparing the publication.
Quite a lot of time has passed since I graduated from college in Germany. And I still remember well those long sleepless nights that I spent on doing difficult homework, research, and the almost complete lack of free time. But I also remember programming lessons well. I tried to start them as late as possible. But when programming was already included in my list of compulsory subjects, I no longer had the opportunity to ignore it. And since English is not my native language, the programming principles were hard for me, which were something very abstract for me; I was constantly lost among the names of various functions that were given in English. And let me do it all very hard, I successfully completed my studies, and now, years later, I am part of a project that could help me a lot then - the Wolfram Language translation project into various languages.
The Wolfram Language translation project presents any non-English programmers an easy entry into learning Wolfram Language. The project serves to be able to work with the Wolfram Language, regardless of English language skills.
')
How do people usually learn programming? Judging by my experience, students are given a piece of code and explain what it is for. Thus, they have the opportunity to get acquainted with the structure and various functions. To facilitate this process, Wolfram Research has added functionality that annotates the Wolfram Language code in your preferred language. We are constantly developing this area and try to add as many languages as possible. At the moment there is already support for Japanese, Chinese traditional and simplified, Korean, Spanish, Russian, Ukrainian, Polish, German, French and Portuguese.
Also within the framework of this project, we added the translation of the menu into Traditional Chinese, Spanish, adding them to the already implemented Japanese and Simplified Chinese.
Code annotations
Returning to my student again: if I had the demonstration code “ Major Multinational Languages ”, an example from the Wolfram Demonstrations Project website, I could see this code annotated in German. Annotations do not alter the code in any way or limit its functionality. It is still computed and can be edited, and annotations to it change on the fly:

For the sake of experimentation, I could remember my eight years of Russian studies and try the following:

This feature can be enabled for a single cell / entire laptop or globally. Thus, I can compare the same code, annotated in German, with its Russian version. Code annotation can also be seen in the autocompletion section. For this case, I chose French.
A bit about the different lengths of lines
One of the first questions that arose at the start of this project was in different lengths of words in different languages. The descriptive constructs and function names in CamelCase ( Camel Register ) in English add problems when trying to keep a reasonable length for translations.
To illustrate this problem, let's take Spanish. The String function has been translated as " cadena de caracteres ". This translation was much longer than the original in English. And now we take into account the fact that this word is often found in the names of various functions, as an example of StringFreeQ and StringReplacePart ; You can imagine how long the translations will be.
Let's compare the Russian and Japanese translations of the $ FrontEnd symbol . Translations are available not only online, but also programmatically via WolframLanguageData with the “Translations” option:

The string lengths for the two translations differ by 66 characters. The question arises: how do our translations correlate in length with their English originals? First, let's load all the reserved names in the Wolfram Language, as well as their translations.

Now consider how the translations relate to their originals:

It is obvious that the Asian writing systems provide a much shorter translation. On the other hand, exploring deeper highs and lows in the difference between English and Polish, we see the following (move the cursor to ListPlot for a hint about comparing names in English and Polish):
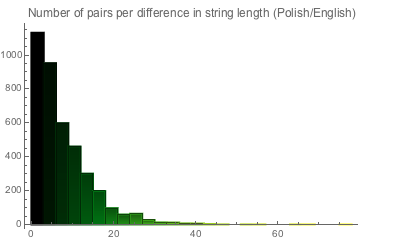

We get 251 cases of matching elements in length. Here are some examples:

Here is the pair with the biggest difference - as many as 75 characters:

Let's look at the length differences in different languages:
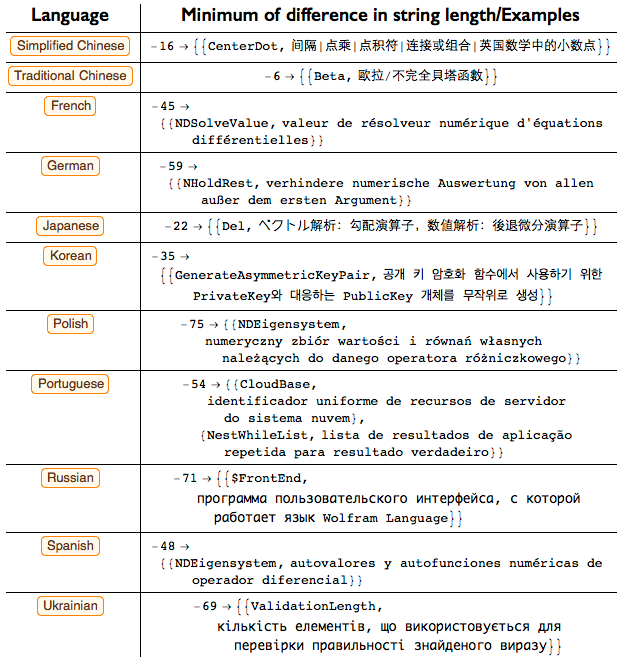

Given these discrepancies, we can find some interesting points about languages and their connections in this data set.
For example, what is the top 5 names that are closest in length to the original for all languages? These are Here , Byte , ColorQ , ListQ and Ball :


Which language has the most spaces? In Korean:

And in which language strings are the longest? In German:

Illustrate this:

How do we account for discrepancies in the lengths of translations in our interface? Returning to the code from the “Major Multinational Languages” example with German included annotations. In cases where the length of the annotation exceeds the length of the original in English, we replace the title with •••. When you hover over an annotation, it unfolds and is highlighted in bold.

Clouds of words
Using the new Wolfram Language WordCloud function , we can get a graphical representation of translations, in which the size of words corresponds to the frequency of their use. Taking the translations of the 120 most popular names, as well as using the recently added GeoGraphics function, we can build clouds from words along the contours of the borders of these countries. Here, for example, Germany and Portugal:

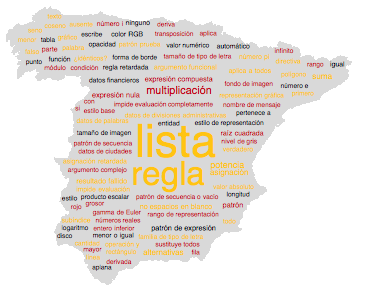
We can go further and draw clouds from words on a figure that describes the borders of this country. And it turns out very nice; Here, for example, Spain:
Complete translations
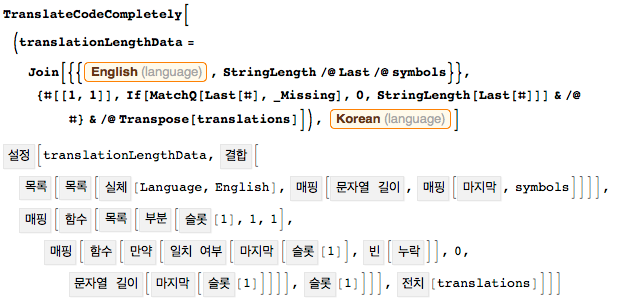
Having played with the translations and examined them from different angles, it would be logical to continue this and try to present the translations not just in the form of annotations, but in English instead of the original Wolfram Language code. Of course, having the TranslateCodeCompletely function at hand, it is easy to implement this. By passing the code fragment and the required language to the function as an argument, our new function returns a full translation. And this code is in full form:

Here is the code that gives a histogram with different lengths of names, shown above - now in Korean. User-defined names are in the same place where they were, and system names are fully translated and grayed out. In the enclosed CDF file below, you can hover the mouse over the translated functions and watch their original names.
A funny side effect for those who are already familiar with the Wolfram Language: if you are already familiar enough with the names of the functions of the language, then with the help of the new functionality you can improve your knowledge in some new natural language.
I hope this functionality will help a large number of new users to get used to the Wolfram Language world. In the future, we are not going to dwell on the mere expansion of the number of languages. We are planning to add translations for other sections of Wolfram Language - menus, hotkeys, and more. We will be happy to hear about the languages you would like to translate, which you would like to see in the Wolfram Language, and we will also be happy to hear your wishes and feedback.
Source: https://habr.com/ru/post/274281/
All Articles