Increase search performance by index partitioning in Apache Solr

Full text search is used almost everywhere in Wrike . Search in the header of the page allows you to quickly access the latest tasks, sorted by update date, with a match by name. This search option is presented in the sections "My Work" and "Taskbar".
Search in the task list works in all fields: name, description, file names of attachments, authors, comments, date of change. The maximum priority for tasks whose activity is related to the current user, with phrasal coincidence in the name, description, or comments.
Simplified search by name is used:
- when assigning dependencies for the Gantt chart (previous and next tasks),
- when adding links to tasks by name (mensenging),
- when adding subtasks.
In these sections, instant search with an implicit wildcard is used: the user sequentially enters u, up, upd, update, and search queries take the form: u *, up *, upd *, update *.
In addition, wildcards can be used in all search options.
Thus, often come “heavy” search queries that cause multiple readings of the index, increased CPU / IO load on servers and, as a result, general delays in processing requests at “peak hours”.
In this article, we will share our way to solving performance problems.
It will be about accelerating the search when working with the Apache Solr search server through partitioning collections. We have tested the described method on versions 4.9.0 and 4.10.2.
')
Problem
Some search queries on the site took tens of seconds, sometimes such delays lead to Gateway Timeout from end users.
Input conditions
Full text search is implemented on Apache Solr. Permanent indexing works. The whole index is in one collection. The size of RAM on the servers allows you to put the entire index into the file cache.
Here is the problem:
- In some cases, a single search query takes “too much time”
- Problem searches include a combination of multiple fields.
- The index is on the SSD
- Apache recommendations don't help
- The index schema (schema.xml) is fixed and there is an explicit criterion for partitioning.
Additionally, we find out:
- Long queries are queries with wildcards (like * q *, * w *, * e *)
- Time of full reading of the index files into the RAM: Tread = Tsearch / N, where Tsearch is the search time, N is the number of fields in the search query
Example
Let there be the following request to Apache Solr:
q = fieldA=q* OR fieldB=q* OR fieldC=q* OR fieldD=q*
Suppose it takes N seconds for the first request, the rest will work faster, because some of the data is already in the file cache and in the internal Apache Solr / Lucene caches. We find out that a simple reading of the full index in the RAM takes N / 4 seconds. Obviously, the problem is in the size of the index Solr has to work with.
What does Apache Solr and SolrCloud offer us?
- Apache optimization tips
- Setting caches does not suit us, since we have constant indexing, and sooner or later, the caches are reset, and we get a long query.
- filter queries - does not work, Solr still reads the full index, and filtering happens after.
- Distributed Search, SolrCloud and Sharding.
Features:- The difficulty of support, full re-indexing when updating the scheme.
- Opacity preparation shards.
- IndexPartitioning - things didn't get further than the idea.
We do not consider Distributed Search as an outdated technology, the flaws of which are presented in the SolrCloud description.
Cons sharding on SolrCloud
SolrCloud documentation offers two sharding options, automatic and manual, using the SPLITSHARD command .
In automatic mode, the number of shards is set in advance. SolrCloud with the help of ZooKeeper is engaged in balancing the loading of shards during indexing, shards are automatically selected for the search. In the “manual” mode, we ourselves choose the time and the shard to divide it into two.
Automatic mode does not suit us. We have a clear key for partitioning, that is, for routing documents on shards during indexing. The routing itself can be changed after indexing, when we can estimate the size of the shard. Automatic sharding rebalancing assumes that one of our partitions can be scattered across multiple shards, in the worst case, all. It does not suit us, if we have such a large partition that its parts are on all shards, we would like to allocate it into a separate shard without other partitions.
Manual mode could be used through the background service, invoking the SPLITSHARD command automatically, upon reaching the limits on the size of the shard, but the process is closed and not instantaneous.
Here is what we can get when SPLITSHARD is dropped on Solr 4.9.0:
- Preserved original collections.
- New ones are created (with the names * _shard1_0, * _shard1_1).
- New collections are created only on one node, information does not get into ZooKeeper.
- Real balancing of search queries does not occur.
- Created collections must be cleaned manually from the disk on the node where they were created.
The reason for this file was the timeout when Solr and ZooKeeper interact. Of course, one would like to avoid such drops in production, or have more control to simplify recovery.
Decision
What should be our solution?
- A significant decrease in the volume of the index with which a particular search query will work.
- Minimum support effort.
- Minimum effort to change the structure.
- Partitioning without downtime.
Partitions will be called collections (in Apache Solr terminology), because the solution works through the Solr Collections API and as partitions creates collections and replicas for them.
We have stipulated in advance that we can split the data unequivocally by key (batchId), and also:
- In one collection can get data with one or more batchId.
- Different collections cannot contain data with the same batchId.
The scheme of the search engine before the introduction of partitioning looked like this:
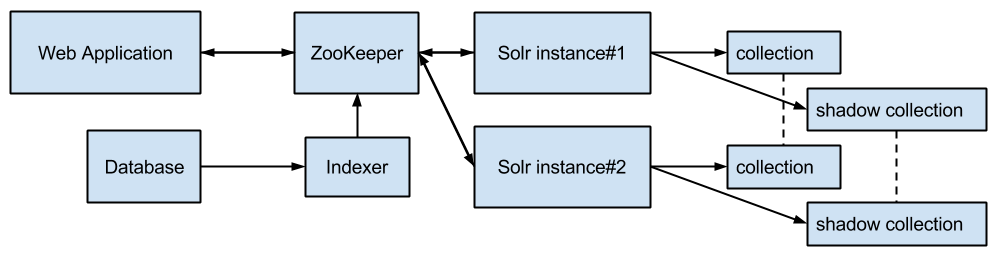
Web Application - performs search queries.
Indexer - a service that performs delta indexing and full re-indexing (only in the shadow collection), works in a separate infrastructure for background processes.
Solr instance # 1, instance # 2 - two servers with Apache Solr for fault tolerance.
collection - two index instances, replication occurs via SolrCloud / ZooKeeper.
shadow collection - two copies of the index for full re-indexing when changing the index scheme, after which the collection and the shadow collection are swapped.
The scheme works as follows. Search queries are sent alternately to all Apache Solr nodes. For routing requests, the LBHttpSolrServer class from the solrj client library is used, the speed of requests with it is higher than with CloudSolrServer, but it’s necessary to track down the nodes manually and re-request the actual information from ZooKeeper. Requests for indexing can also be done through LBHttpSolrServer / CloudSolrServer / ZooKeeper, or directly to one of the Apache Solr nodes, leaving the second node less loaded to speed up search queries.
We need to break the working collections, based on the amount of data in the partitions received by the batchId key. To implement our solution, we need another service that will manage the process of partitioning collections. Let's call the service - index manager (IndexManager). Manager functions:
- monitoring the size of current collections
- initiation of creation of new when the limits are exceeded (partitioning)
- initiation of the union of collections, if their size fell below a predetermined limit (union)
- monitoring and managing the re-indexing process in new collections (through indexer commands)
- switching work collections after indexing to new and deleting old ones
You can estimate the volume that the index will occupy for one or several partitions, either indirectly or after creating the index.
An indirect estimate looks like this:
R all - the total number of entries for all partitions.
V all - total index volume (collection)
R n - the number of entries for the partition N
V n = R n ⋅V all / R all - estimated volume of collection for partition N
The M collection is formed from the 1..k partitions until S summ <S limit , S summ is the total size of the collection, S limit is the specified limit on the collection size.
The scheme of the new service is as follows:
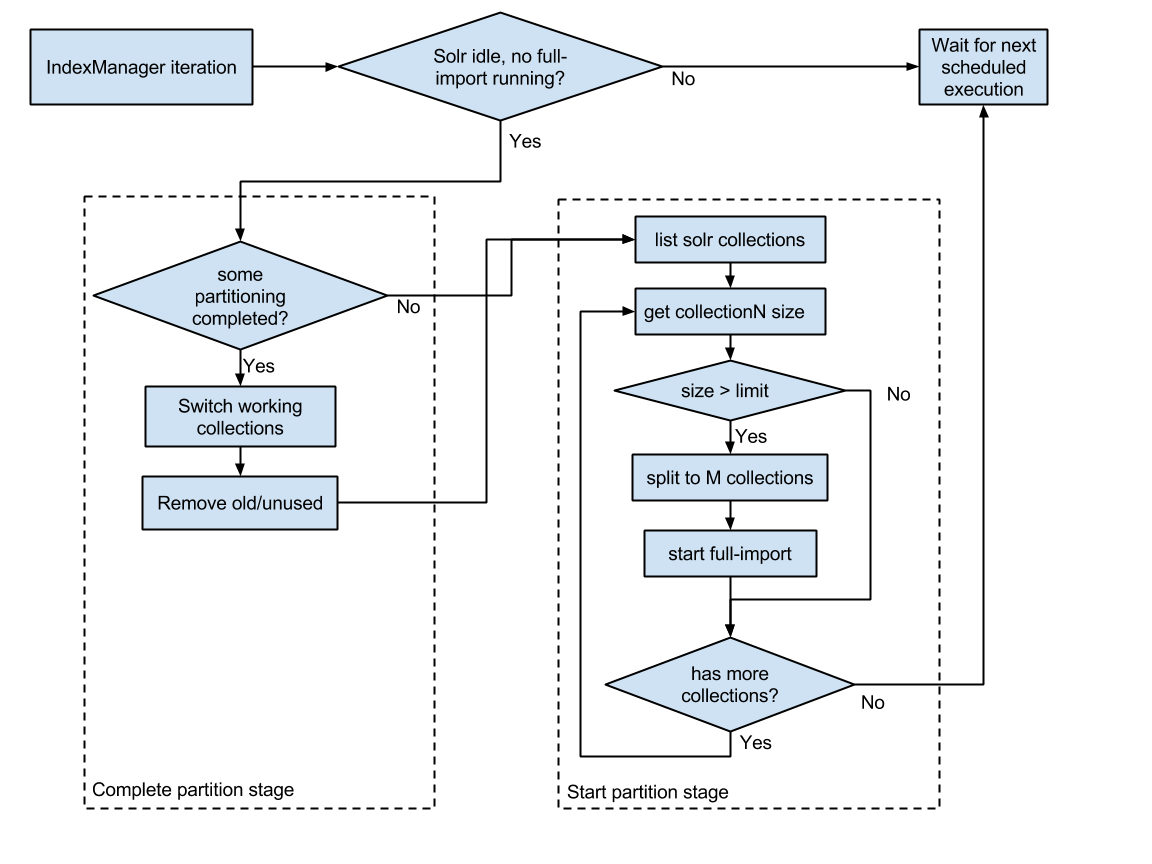
As a result of the work of IndexManager, collections are created / deleted, data in separate collections are re-indexed, actual collections are switched. The association of collections and source data (batchId) is stored in the database.
The scheme of a search engine with index partitioning looks like this:
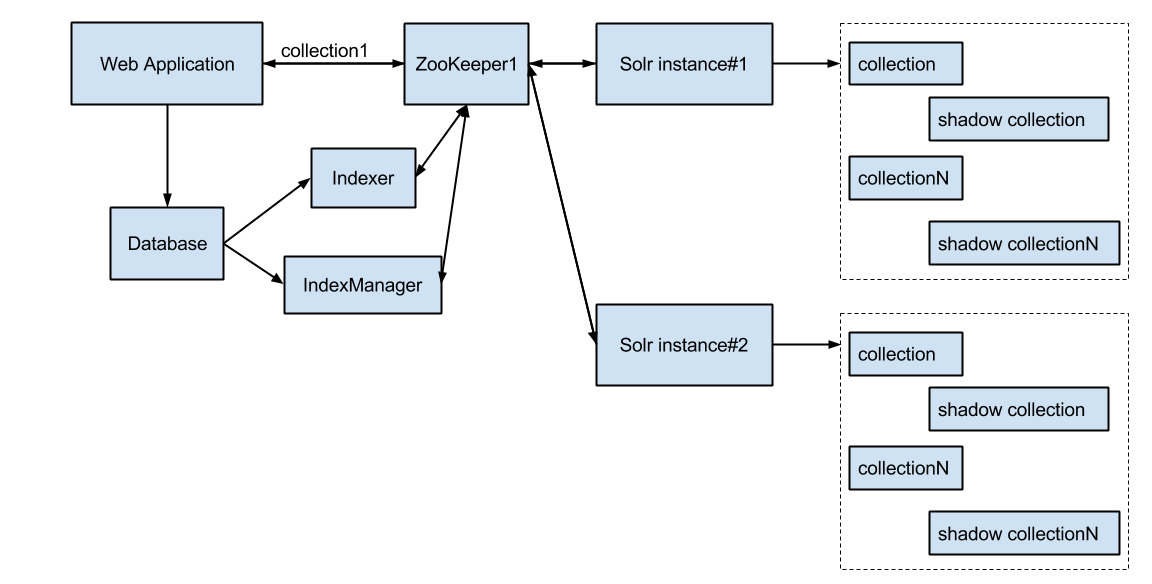
The index in this scheme represents N collections and N reserve collections in case of a change in the index scheme with subsequent re-indexing. These N collections are stored on each Apache Solr node, replication occurs by native SolrCloud + ZooKeeper agents.
Acceleration of search occurs due to search on the index limited to one collection. For this purpose, the HTTP parameter collection (collection = batchId) is added to the search query.
After starting, creating and re-indexing collections, we obtained the maximum collection size of 0.1 from the original and the following distribution of query execution time:
| Execution time (ms) | To (% of total) | After (% of total count) |
|---|---|---|
| > = 10,000 | 2.2% | 0 |
| 1000 - 10,000 | 3.8% | 0 |
| 500 - 1000 | 4.3% | 0 |
| 100 - 500 | 17.1% | 8.1% |
| 0 - 100 | 72.4% | 91.9% |
results
- The decrease in the index involved in the search is implemented through the control of the size of collections by the index manager.
- Minimum support effort:
- server: the same configuration before and after partitioning. The IndexManager service works in the general infrastructure of services and does not require separate administration.
- one-time configuration update in ZooKeeper when changing the index scheme
- Minimum effort to change the structure:
- index schema change done once for base collections
- resizing collections, adding new ones and deleting unnecessary ones after merging - automatically
- Absence of downtime - any operation (splitting, combining collections) before its completion does not affect search indexes and indexing; after completion, an atomic switch occurs.
- Significantly faster query processing.
Source: https://habr.com/ru/post/274059/
All Articles