Interactive Client Map - Apache Spark Streaming and Yandex.Maps
Bigdata is pushing. It is not enough for business to be able to process the data accumulated during the day at night and make a decision with a delay of 24 hours. They want the system to analyze data online and respond quickly to:
etc. If you do not know how, then the smoothies are no longer poured.

Increasingly, we hear about lambda architecture . Increasingly, they want to cluster data online. We hear more about the use of online machine learning (pre-learning). Guard.

You can begin to tear the hair on your head, but you can and rather need to train methodically, develop an understanding of technologies and algorithms and in practice, in conditions of "hard combat" and high loads, to separate useful and effective technological solutions from academic theorizing.
Today I’ll tell you how we made an interactive map of our clients using Apache Spark Streaming and the Yandex.Maps API . But before, we will repeat the architectural approaches and briefly in essence go through the available tools.
')
This issue is over 50 years old. The bottom line is that there are roughly 2 fundamental approaches to the task of processing large amounts of information - Data Parallelizm and Task Parallelizm .
In the first case, the same chain of calculations is launched in parallel over the disjoint unchanged parts of the original data. It is according to this principle that Apache Spark and Hadoop MapReduce work.
In the second case, the opposite is true - several chains of computations begin to run in parallel on one piece of data: the popular Apache Spark Streaming , Apache Storm and, with some stretch, Apache Flume work on this principle.
These concepts are very important to understand and assimilate, because systems for batch and stream data processing, because of their relative simplicity, have already produced a lot, like mushrooms after a rain, which, of course, confuses beginners.

Essentially, Apache Spark Streaming (thanks to UC Berkeley and DataBricks) that Apache Storm (thanks, Twitter) implement the concept of stream processing in the Task Parallel architecture, but Spark Streaming went further and allows the package to be processed (discretized RDD) in parallel the spirit of Data Parallel. This feature makes it easy to "tie" the online clustering package - group the data into a cluster for visualization, invite girls for dinner ... so what is it about me.
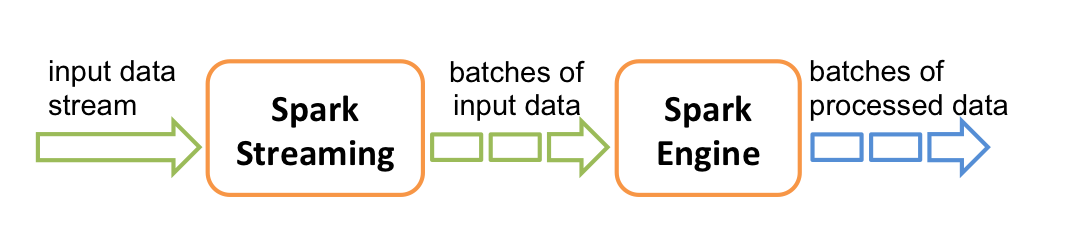
You can read the documentation yourself, I will only explain the essence with 2-3 words. I hate populism, cleverness and juggling with incomprehensible terms - I want the knowledge to be transmitted in a simple, accessible language and the transfer process is enjoyable. You collect data that arrives many times per second at:
and where your heart desires. The data, for simplicity, is ordered. You need to process each item of data:
Spark Streaming collects data items in an ordered immutable RDD for a certain fixed time interval (say, 10 seconds) and calls your handler, passing the RDD to the input. RDD is just a collection of data collected over an interval, no more.
If during the interval you managed to collect a rather large RDD, you need to try to process it BEFORE the next RDD comes in the next interval. Therefore, RDD is practical to process in parallel on multiple servers in a cluster. The larger the input data stream, the more servers are added to the stream cluster. I hope everything is clear explained.
And if everything fell? A piece of the cluster fell off, there was a null pointer exception in your package handler ...

A small arcade insert. Not so long ago, at the mention of RabbitMQ or ZeroMQ, there was silence and reverent awe indulged the group of developers, architects and the stray designer who accidentally got lost. And experienced fighters with experience of survival in the enterprise recalled the Message-oriented middleware and let out a tear.
But, as we said at the beginning of the post, Bigdat is pushing. And it does it roughly and unceremoniously. Increasingly, we hear that the message queue architecture, in which Consumers are coordinated and multiplexed centrally on the queue server (s), becomes “non-kosher” because when the load and the number of clients increase, it becomes bad (of course, you need to keep all contexts with the counters of all clients, run through the sockets ready for processing by select / pool and do other sadomazachism). And the “Orthodox” architecture is increasingly considered to be implemented in Apache Kafka, where each consumer client remembers and maintains its position in the queue, and the server (s) is only involved in issuing messages on the iterator sent by the client (or rather, the transferred offset in the file, in which messages are stored on the old, good, bearded hard drive). Of course, this is hack-work and the transfer of responsibility to customers - but ... Bigdat - is pressing and it turns out that the architecture is not so irresponsible. And even Amazon Kinesis took it on board. Read about it - useful. Only there is a lot of text, pour a cup of coffee and more Arabica.

What are we staying at? Everything fell ... who, what girls? Oh, I remembered. So, when everything fell, the consumer, in this case its role is played by the driver (there are several of them out of the box), which pulls messages from the queues, must transfer the stored position in the queue again and start reading the messages again. In our case, we read messages in Spark Streaming from Amazon Kinesis and the driver regularly (adjusted), saves the position read from the queue to the DymanoDB nameplate (this is available from the box).
When clients work with Bitrix24 portals, javascript sends to the cloud a packet describing the client’s action, IP address and impersonal information that is used in the system of personal recommendations, CRM , business intelligence and various machine learning models within the company.
Comes in peak every second more than 1000 events. Events are collected in Amazon Kinesis (which, as we remember, with “kosher architecture”).
To handle these> 1000 events per second, a small cluster of Yarn was raised with Spark Streaming (2 cars). Pay attention to the amount of memory allocated Spark driver. It seems you can allocate even less memory:
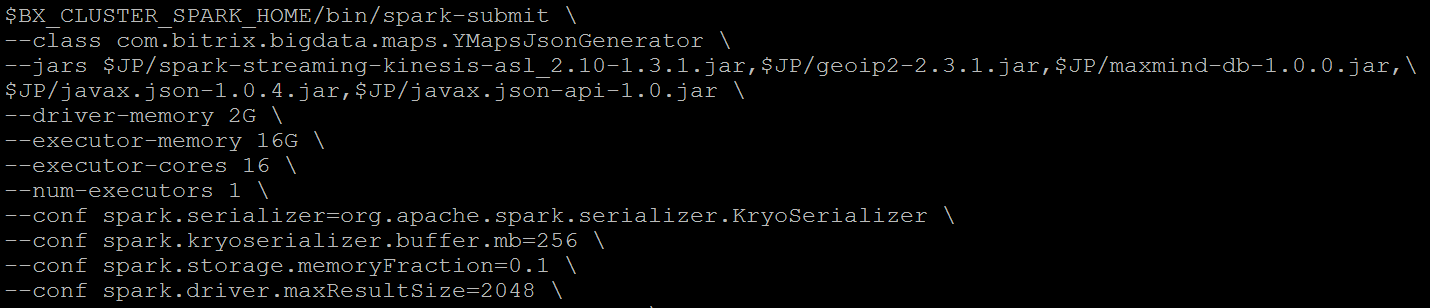
The following screenshot is even more interesting. It shows that we have time to process> 1000 hits per second before the next packet arrives at a 30 second interval:

Yes, exactly, the Spark driver memory consumes less than 200MB, so right now we will cut it to him :-):

In general, it is clear that quite a bit of memory is used and the entire processing flow can easily fit into 2 pieces of hardware, and if you wish, you can do it on one and no one will notice. Cool. Effective technology:> 1000 events per second on the "dead" gland.
Now the fun part. We need to get each client’s client’s IP address and ... display its domain with a dot on Yandex.Map, but so that the zoom on the map works and doesn’t slow down!
To translate IP addresses to coordinates, we use one of the popular libraries . One problem is that the library objects in java are not serialized out of the box, so the translation of IP addresses to coordinates is still performed in one stream inside the Spark driver. If you wish, of course, you can raise a separate address resolver for each partition RDD interval - but for now the performance is enough for the eyes.
Next, for each hit, we define the project domain and save a pair in the hash table: domain — coordinates and update time. Couples older than a few days - clean.
At certain time intervals (adjustable), we unload the domain binding to the coordinates, i.e. future points on the map, in a json file for further display on Yandex.Map. At the moment, about 20k points.

I had to remember javascript :-). The underwater stone when displaying points on Yandex.Map turned out to be one - 20k points on the map with integrated clustering hamper the client browser terribly and the map opens in minutes. Therefore, we took the opportunity of server clustering - we wrote our own simple rasterizer-clusterer, to which we connected the card.
About how the card itself is implemented, how we do server rasterization and pitfalls, - I will write a separate post, if you're interested, tell me. The overall architecture is as follows:
It turned out quickly and simply. Yes, you can not read the json-file, but refer to NoSQL ... but so far everything works fast and there is such a word - laziness :-)
The rasterizer is written in PHP, and k-means is suicidal on the fly, so everything is simplified and rasterization is done instead of clustering. If interested, I will describe a separate post.
Here’s what the Bitrix24 active client domain map looks like (https://www.bitrix24.ru/online-domains-map) :

Here is the zoom:

It turned out a nice online map of domains Bitrix24. Zoom and server clustering work pretty fast. I was pleased with Spark Streaming and the rather pleasant process of creating a map through the Yandex.Maps API. Write what might be more interesting on this topic - we will try to tell you in detail. Good luck to all!
- change of quotes
- user actions in the online game
- displayed aggregated information from social networks in various projections
etc. If you do not know how, then the smoothies are no longer poured.
Increasingly, we hear about lambda architecture . Increasingly, they want to cluster data online. We hear more about the use of online machine learning (pre-learning). Guard.
You can begin to tear the hair on your head, but you can and rather need to train methodically, develop an understanding of technologies and algorithms and in practice, in conditions of "hard combat" and high loads, to separate useful and effective technological solutions from academic theorizing.
Today I’ll tell you how we made an interactive map of our clients using Apache Spark Streaming and the Yandex.Maps API . But before, we will repeat the architectural approaches and briefly in essence go through the available tools.
')
Approaches to processing data arrays
This issue is over 50 years old. The bottom line is that there are roughly 2 fundamental approaches to the task of processing large amounts of information - Data Parallelizm and Task Parallelizm .
In the first case, the same chain of calculations is launched in parallel over the disjoint unchanged parts of the original data. It is according to this principle that Apache Spark and Hadoop MapReduce work.
In the second case, the opposite is true - several chains of computations begin to run in parallel on one piece of data: the popular Apache Spark Streaming , Apache Storm and, with some stretch, Apache Flume work on this principle.
These concepts are very important to understand and assimilate, because systems for batch and stream data processing, because of their relative simplicity, have already produced a lot, like mushrooms after a rain, which, of course, confuses beginners.
Essentially, Apache Spark Streaming (thanks to UC Berkeley and DataBricks) that Apache Storm (thanks, Twitter) implement the concept of stream processing in the Task Parallel architecture, but Spark Streaming went further and allows the package to be processed (discretized RDD) in parallel the spirit of Data Parallel. This feature makes it easy to "tie" the online clustering package - group the data into a cluster for visualization, invite girls for dinner ... so what is it about me.
How Apache Spark Streaming Works
You can read the documentation yourself, I will only explain the essence with 2-3 words. I hate populism, cleverness and juggling with incomprehensible terms - I want the knowledge to be transmitted in a simple, accessible language and the transfer process is enjoyable. You collect data that arrives many times per second at:
and where your heart desires. The data, for simplicity, is ordered. You need to process each item of data:
- add a hit to the amount of hits per day
- register client's address by IP address
- send a push notification to the user about the operation
Spark Streaming collects data items in an ordered immutable RDD for a certain fixed time interval (say, 10 seconds) and calls your handler, passing the RDD to the input. RDD is just a collection of data collected over an interval, no more.
If during the interval you managed to collect a rather large RDD, you need to try to process it BEFORE the next RDD comes in the next interval. Therefore, RDD is practical to process in parallel on multiple servers in a cluster. The larger the input data stream, the more servers are added to the stream cluster. I hope everything is clear explained.
And if everything fell? A piece of the cluster fell off, there was a null pointer exception in your package handler ...
“Kosher” and “Orthodox” message queue architectures
A small arcade insert. Not so long ago, at the mention of RabbitMQ or ZeroMQ, there was silence and reverent awe indulged the group of developers, architects and the stray designer who accidentally got lost. And experienced fighters with experience of survival in the enterprise recalled the Message-oriented middleware and let out a tear.
But, as we said at the beginning of the post, Bigdat is pushing. And it does it roughly and unceremoniously. Increasingly, we hear that the message queue architecture, in which Consumers are coordinated and multiplexed centrally on the queue server (s), becomes “non-kosher” because when the load and the number of clients increase, it becomes bad (of course, you need to keep all contexts with the counters of all clients, run through the sockets ready for processing by select / pool and do other sadomazachism). And the “Orthodox” architecture is increasingly considered to be implemented in Apache Kafka, where each consumer client remembers and maintains its position in the queue, and the server (s) is only involved in issuing messages on the iterator sent by the client (or rather, the transferred offset in the file, in which messages are stored on the old, good, bearded hard drive). Of course, this is hack-work and the transfer of responsibility to customers - but ... Bigdat - is pressing and it turns out that the architecture is not so irresponsible. And even Amazon Kinesis took it on board. Read about it - useful. Only there is a lot of text, pour a cup of coffee and more Arabica.
Disaster recovery
What are we staying at? Everything fell ... who, what girls? Oh, I remembered. So, when everything fell, the consumer, in this case its role is played by the driver (there are several of them out of the box), which pulls messages from the queues, must transfer the stored position in the queue again and start reading the messages again. In our case, we read messages in Spark Streaming from Amazon Kinesis and the driver regularly (adjusted), saves the position read from the queue to the DymanoDB nameplate (this is available from the box).
How our project is arranged - “Interactive Client Card”
Sources of events
When clients work with Bitrix24 portals, javascript sends to the cloud a packet describing the client’s action, IP address and impersonal information that is used in the system of personal recommendations, CRM , business intelligence and various machine learning models within the company.
Comes in peak every second more than 1000 events. Events are collected in Amazon Kinesis (which, as we remember, with “kosher architecture”).
Sending events to Spark Streaming
To handle these> 1000 events per second, a small cluster of Yarn was raised with Spark Streaming (2 cars). Pay attention to the amount of memory allocated Spark driver. It seems you can allocate even less memory:
The following screenshot is even more interesting. It shows that we have time to process> 1000 hits per second before the next packet arrives at a 30 second interval:
Yes, exactly, the Spark driver memory consumes less than 200MB, so right now we will cut it to him :-):
In general, it is clear that quite a bit of memory is used and the entire processing flow can easily fit into 2 pieces of hardware, and if you wish, you can do it on one and no one will notice. Cool. Effective technology:> 1000 events per second on the "dead" gland.
Event handling
Now the fun part. We need to get each client’s client’s IP address and ... display its domain with a dot on Yandex.Map, but so that the zoom on the map works and doesn’t slow down!
To translate IP addresses to coordinates, we use one of the popular libraries . One problem is that the library objects in java are not serialized out of the box, so the translation of IP addresses to coordinates is still performed in one stream inside the Spark driver. If you wish, of course, you can raise a separate address resolver for each partition RDD interval - but for now the performance is enough for the eyes.
Next, for each hit, we define the project domain and save a pair in the hash table: domain — coordinates and update time. Couples older than a few days - clean.
Uploading data for Yandex.Maps
At certain time intervals (adjustable), we unload the domain binding to the coordinates, i.e. future points on the map, in a json file for further display on Yandex.Map. At the moment, about 20k points.
Rasterizer clustering for Yandex.Maps
I had to remember javascript :-). The underwater stone when displaying points on Yandex.Map turned out to be one - 20k points on the map with integrated clustering hamper the client browser terribly and the map opens in minutes. Therefore, we took the opportunity of server clustering - we wrote our own simple rasterizer-clusterer, to which we connected the card.
About how the card itself is implemented, how we do server rasterization and pitfalls, - I will write a separate post, if you're interested, tell me. The overall architecture is as follows:
- The map accesses the server rasterizer, passing the coordinates of the displayed area
- The rasterizer reads a json file with pairs: domain-domain, clusters points on the fly and gives the result
- The map displays server rasterization-clustering results.
It turned out quickly and simply. Yes, you can not read the json-file, but refer to NoSQL ... but so far everything works fast and there is such a word - laziness :-)
The rasterizer is written in PHP, and k-means is suicidal on the fly, so everything is simplified and rasterization is done instead of clustering. If interested, I will describe a separate post.
Results
Here’s what the Bitrix24 active client domain map looks like (https://www.bitrix24.ru/online-domains-map) :
Here is the zoom:
It turned out a nice online map of domains Bitrix24. Zoom and server clustering work pretty fast. I was pleased with Spark Streaming and the rather pleasant process of creating a map through the Yandex.Maps API. Write what might be more interesting on this topic - we will try to tell you in detail. Good luck to all!
Source: https://habr.com/ru/post/274041/
All Articles