PostgreSQL Partitioning - What? What for? How?
Unfortunately, not many people actively use the table partitioning feature in PostgreSQL. In my opinion, it is very worthy of her talks in his work Hubert Lubaczewski ( depesz.com ). I offer you another translation of his article!
Recently, I noticed that more and more often I come across case studies where partitioning could be used. And although, theoretically, most people know about its existence, in fact, this feature is not well understood, and some are even afraid of it.
So I will try to explain to the best of my knowledge and capabilities, what it is, why it should be used and how to do it.
As you probably know, there are tables in PostgreSQL, and there are data in the tables. Sometimes it's just a few lines, and sometimes it's billions.
Partitioning is a method of dividing large (based on the number of records, not columns) tables into many small ones. And it is desirable that this happens in a transparent way for the application.
')
One of the rarely used features of PostgreSQL is the fact that it is an object-relational database. And “object” is a keyword here, because objects (or, rather, classes) know what is called “inheritance”. This is what is used for partitioning.
Let's see what it is about.
I will create a regular users table:
Now, for completeness, let's add a few lines and an additional index:
So, we have a test table:
With some random data:
Now that the table is ready, I can create partitions, which means inherited tables:
Thus, we have a new table, which has certain interesting properties:
Let's try again, but this time with a more “explosive” effect:
Now we have all the indices and restrictions, but we have lost the information about inheritance. But we can add it later with:
We could do it in one step, but then there are various unpleasant notifications:
In any case, we now have two tables - the main and the first partition.
If I perform any action — select / update / delete — with users, both tables will be scanned:
But if I turn to the partition directly, the request will be executed only on it:
If we wanted, we could only refer to the user table without its partitions using the ONLY keyword:
You may have noticed that I said that fetch / update / delete works on all partitions. What about inserts? The insert needs to add some data somewhere, so it always works as if ONLY was used. Therefore, if I need to add a line to users_1, I have to do this:
It doesn’t look too good, but don’t worry, there are ways around it.
Let's try to do real partitioning. First we need to decide what the partitioning key will be - in other words, by which algorithm the partitions will be selected.
There are a couple of the most obvious:
There are a couple of other, not so often used options, like "partitioning by hash on behalf of the user."
Why it is worth using one scheme, but not another? Let's understand their advantages and disadvantages:
The last drawback of the hashed username approach is quite interesting. Let's see what happens there.
First I need to create more partitions:
Now the users table has 10 partitions:
PostgreSQL has the constraint_exclusion option. And if you configure it to “on” or “partition”, PostgreSQL will skip partitions that cannot contain matching lines.
In my Pg, this is the default:
So, since all my partitions and the base table have no meaningful restrictions, so any query will scan all 11 tables at once (the main one and 10 partitions):
This is not very effective, but we can put a limit.
Suppose our partitions were formed by partisation by id, and 100,000 identifiers are stored in each partition.
We can add a few restrictions:
Now we repeat the previous query:
It scans only 2 tables: the main one (in which all data are now, and there are no restrictions, so it cannot be excluded) and a suitable partition.
Great, right?
We can easily add such partitioning conditions by username or created_on. But look what happens when the partitioning key is more complex:
In case you do not know, hashtext () takes a string and returns an integer in the range from -2147483648 to 2147483647.
Thanks to simple arithmetic, we know that abs (hashtext (string))% 10 will always produce a value in the range of 0..9, and is easy to calculate for any parameter.
Does PostgreSQL know about this?
Not. Does not know. Essentially, PostgreSQL can only automatically exclude partitions for range-based (or equality) checks. Nothing based on features. Even a simple module from a number is already a search:
It is sad. Because partition keys based on number modules have one huge (in my opinion) advantage - a stable number of partitions. You do not have to create them in the future, unless you decide to re-partition when you reach some higher amount of data.
Does this mean that you cannot use complex (based on functions or modules on numbers) partitioning keys? Not. You can use them, but then the requests are more complex:
Here I added another condition, like this:
PostgreSQL can rewrite it in the process of parsing an expression:
because it knows that the% operator for integers is immutable. And now, as part of the query, I have the exact partitioning key - id% 10 = 3. Thus, Pg can use only those partitions that either do not have a partitioning key (that is, the base table), or have a key corresponding to the query .
Is it worth it to introduce additional complication - you decide.
If you prefer not to change requests, and it doesn’t make it difficult for you to add new partitions from time to time, then you should familiarize yourself with the PG Partition Manger written by my former colleague Keith Fiske - this is a set of functions that you manually start to define partitions which you run over the crown, and it takes on the creation of new partitions for future data.
I already mentioned the inserts, but did not explain how to get around the problem with inserts that should be added to the partitions.
In general, this is a trigger job. Pg_partman from Kita creates such triggers for you, but I want you to understand what is happening and not use pg_partman as a black box, but rather as an auxiliary tool that does the tedious work for you.
Now my partitioning scheme is based on the module of the number (as far as I know, partman cannot do this), so let's write the appropriate trigger function. It will be called when inserting data into the users table and should redirect the insert to the appropriate partition without errors. So, we write:
And now the definition of a trigger:
Let's try to add a line:
Let's see if the data is visible:
It looks good, but where are they? In the main table?
Not. So maybe in the right partitions?
Yes. The trigger worked. But this method has one drawback. Namely - “RETURNING" does not work:
This happens because, from the point of view of the performer, the insertion did not return anything - the trigger returned NULL.
I have not managed to find a successful solution to this problem. In my cases, I just prefer to get the original key value in advance, using nextval (), and then insert the finished value - so that it already exists after the insert:
To all this there is one clarification. Routing all inserts via a trigger slows them down, because for each PG line you will need to perform another “insert".
For urgent bulk inserts, the best solution would be to get them to work directly with partitions. Therefore, for example, instead of
you first find out how many identifiers you need, for example, in this way:
And then you issue the appropriate ones:
, , .
, , , . : ?
: .
, users, 1 (1,000,000,000).
, , .
.
:
users 10,000 . 0.020 – .
:
0.025. 0.005 , - 110,000 , , .
, . , , id – Pg ( , ).
, – - , , ? , , Pg .
, , , . ( , vacuum, pg_reorg/pg_repack, pg_dump) , . 20 , , , !
, . : , .
. , , () .
, . , , , , , . , «» .
, , . : . , – . , , - : « ».
, , ? ?
Let's get a look. pgbench 97 . , 83 , pgbench_accounts, 666,600,000 .
:
aid, 1 666,600,000.
, aid.
, 10 , 67 .
, ? Very simple. pgbench . , , , pgbench.
:
10- , .
, :
, , :
-””:
, , 666 . ?
. , :
, . SQL.
- , sql, . : – . , , . .
psql ( ruby, perl, python – ), , , .
, :
– 1000, , , , (666 ).
:
psql, /tmp/run.batch.migration.sql, (97 ), 666,600 , :
, , (, «screen» «tmux», , ssh ):
. ~ 92, , 17 .
7 . Not bad.
pgbench_accounts ~ 83 (, , pgbench, vacuum).
, , :
pgbench ?
4 :
Results?
, . , , SATA , SSD, – pgbench , .
, - , vacuum . -, .
:
, , :
- « ».
, () . . ( 9.6) , , .
, .
PostgreSQL ? PG Day'16 Russia ! early bird , !
Recently, I noticed that more and more often I come across case studies where partitioning could be used. And although, theoretically, most people know about its existence, in fact, this feature is not well understood, and some are even afraid of it.
So I will try to explain to the best of my knowledge and capabilities, what it is, why it should be used and how to do it.
As you probably know, there are tables in PostgreSQL, and there are data in the tables. Sometimes it's just a few lines, and sometimes it's billions.
Partitioning is a method of dividing large (based on the number of records, not columns) tables into many small ones. And it is desirable that this happens in a transparent way for the application.
')
One of the rarely used features of PostgreSQL is the fact that it is an object-relational database. And “object” is a keyword here, because objects (or, rather, classes) know what is called “inheritance”. This is what is used for partitioning.
Let's see what it is about.
I will create a regular users table:
$ create table users ( id serial primary key, username text not null unique, password text, created_on timestamptz not null, last_logged_on timestamptz not null ); Now, for completeness, let's add a few lines and an additional index:
$ insert into users (username, password, created_on, last_logged_on) select random_string( (random() * 4 + 5)::int4), random_string( 20 ), now() - '2 years'::interval * random(), now() - '2 years'::interval * random() from generate_series(1, 10000); $ create index newest_users on users (created_on); So, we have a test table:
$ \d Table "public.users" Column | Type | Modifiers ----------------+--------------------------+---------------------------------------------------- id | integer | not null default nextval('users_id_seq'::regclass) username | text | not null password | text | created_on | timestamp with time zone | not null last_logged_on | timestamp with time zone | not null Indexes: "users_pkey" PRIMARY KEY, btree (id) "users_username_key" UNIQUE CONSTRAINT, btree (username) "newest_users" btree (created_on) With some random data:
$ select * from users limit 10; id | username | password | created_on | last_logged_on ----+----------+----------------------+-------------------------------+------------------------------- 1 | ityfce3 | 2ukgbflj_l2ndo3vilt2 | 2015-01-02 16:56:41.346113+01 | 2015-04-15 12:34:58.318913+02 2 | _xg_pv | u8hy20aifyblg9f3_rf2 | 2014-09-27 05:41:05.317313+02 | 2014-08-07 14:46:14.197313+02 3 | uvi1wo | h09ae85v_f_cx0gf6_8r | 2013-06-17 18:48:44.389313+02 | 2014-06-03 06:53:49.640513+02 4 | o6rgs | vzbrkwhnsucxco5pjep0 | 2015-01-30 11:33:25.150913+01 | 2013-11-05 07:18:47.730113+01 5 | nk61jw77 | lidk_mnpe_olffmod7ed | 2014-06-15 07:18:34.597313+02 | 2014-03-21 17:42:44.763713+01 6 | 3w326_2u | pyoqg87feemojhql7jrn | 2015-01-20 05:41:54.133313+01 | 2014-09-07 20:33:23.682113+02 7 | m9rk9mnx | 6pvt94s6ol46kn0yl62b | 2013-07-17 15:13:36.315713+02 | 2013-11-12 10:53:06.123713+01 8 | adk6c | egfp8re0z492e6ri8urz | 2014-07-23 11:41:11.883713+02 | 2013-10-22 07:19:36.200513+02 9 | rsyaedw | ond0tie9er92oqhmdj39 | 2015-05-11 16:45:40.472513+02 | 2013-08-31 17:29:18.910913+02 10 | prlobe46 | _3br5v97t2xngcd7xz4n | 2015-01-10 20:13:29.461313+01 | 2014-05-04 06:25:56.072513+02 (10 rows) Now that the table is ready, I can create partitions, which means inherited tables:
$ create table users_1 () inherits (users); $ \d users_1 Table "public.users_1" Column | Type | Modifiers ----------------+--------------------------+---------------------------------------------------- id | integer | not null default nextval('users_id_seq'::regclass) username | text | not null password | text | created_on | timestamp with time zone | not null last_logged_on | timestamp with time zone | not null Inherits: users Thus, we have a new table, which has certain interesting properties:
- it uses the same sequence as the main table for its id column;
- all columns have the same definition, including non null constraints;
- there is no primary key, no uniqueness restrictions for the user name, no index for created_on.
Let's try again, but this time with a more “explosive” effect:
$ drop table users_1; $ create table users_1 ( like users including all ); $ \d users_1 Table "public.users_1" Column | Type | Modifiers ----------------+--------------------------+---------------------------------------------------- id | integer | not null default nextval('users_id_seq'::regclass) username | text | not null password | text | created_on | timestamp with time zone | not null last_logged_on | timestamp with time zone | not null Indexes: "users_1_pkey" PRIMARY KEY, btree (id) "users_1_username_key" UNIQUE CONSTRAINT, btree (username) "users_1_created_on_idx" btree (created_on) Now we have all the indices and restrictions, but we have lost the information about inheritance. But we can add it later with:
$ alter table users_1 inherit users; $ \d users_1 Table "public.users_1" Column | Type | Modifiers ----------------+--------------------------+---------------------------------------------------- id | integer | not null default nextval('users_id_seq'::regclass) username | text | not null password | text | created_on | timestamp with time zone | not null last_logged_on | timestamp with time zone | not null Indexes: "users_1_pkey" PRIMARY KEY, btree (id) "users_1_username_key" UNIQUE CONSTRAINT, btree (username) "users_1_created_on_idx" btree (created_on) Inherits: users We could do it in one step, but then there are various unpleasant notifications:
$ drop table users_1; $ create table users_1 ( like users including all ) inherits (users); NOTICE: merging column "id" with inherited definition NOTICE: merging column "username" with inherited definition NOTICE: merging column "password" with inherited definition NOTICE: merging column "created_on" with inherited definition NOTICE: merging column "last_logged_on" with inherited definition $ \d users_1 Table "public.users_1" Column | Type | Modifiers ----------------+--------------------------+---------------------------------------------------- id | integer | not null default nextval('users_id_seq'::regclass) username | text | not null password | text | created_on | timestamp with time zone | not null last_logged_on | timestamp with time zone | not null Indexes: "users_1_pkey" PRIMARY KEY, btree (id) "users_1_username_key" UNIQUE CONSTRAINT, btree (username) "users_1_created_on_idx" btree (created_on) Inherits: users In any case, we now have two tables - the main and the first partition.
If I perform any action — select / update / delete — with users, both tables will be scanned:
$ explain analyze select * from users where id = 123; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------- Append (cost=0.29..16.47 rows=2 width=66) (actual time=0.008..0.009 rows=1 loops=1) -> Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1) Index Cond: (id = 123) -> Index Scan using users_1_pkey on users_1 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) Planning time: 0.327 ms Execution time: 0.031 ms (7 rows) But if I turn to the partition directly, the request will be executed only on it:
$ explain analyze select * from users_1 where id = 123; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------- Index Scan using users_1_pkey on users_1 (cost=0.15..8.17 rows=1 width=84) (actual time=0.002..0.002 rows=0 loops=1) Index Cond: (id = 123) Planning time: 0.162 ms Execution time: 0.022 ms (4 rows) If we wanted, we could only refer to the user table without its partitions using the ONLY keyword:
$ explain analyze select * from only users where id = 123; QUERY PLAN ------------------------------------------------------------------------------------------------------------------- Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1) Index Cond: (id = 123) Planning time: 0.229 ms Execution time: 0.031 ms (4 rows) You may have noticed that I said that fetch / update / delete works on all partitions. What about inserts? The insert needs to add some data somewhere, so it always works as if ONLY was used. Therefore, if I need to add a line to users_1, I have to do this:
INSERT INTO users_1 ... It doesn’t look too good, but don’t worry, there are ways around it.
Let's try to do real partitioning. First we need to decide what the partitioning key will be - in other words, by which algorithm the partitions will be selected.
There are a couple of the most obvious:
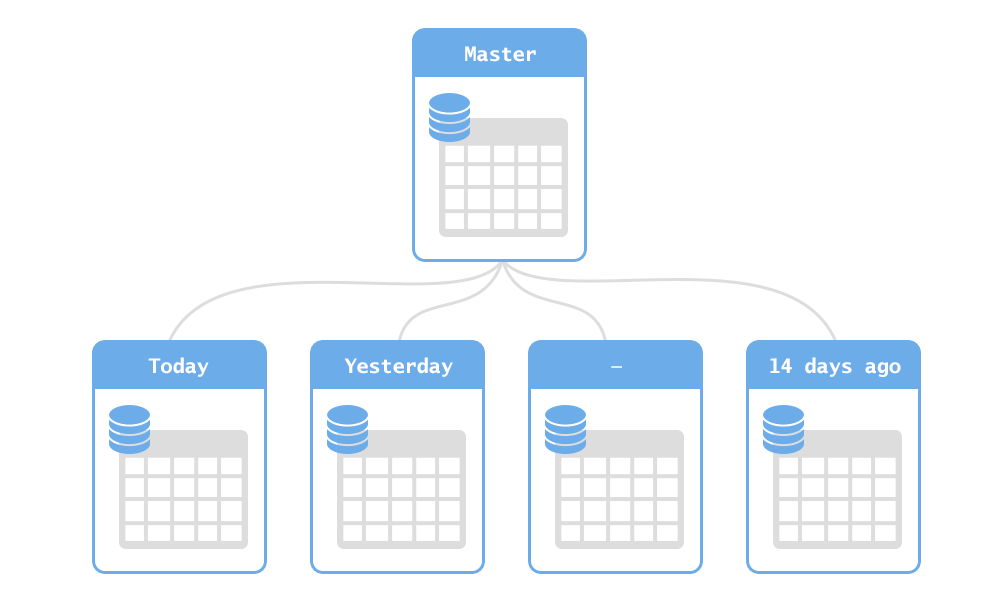
- partition by date - for example, select partitions based on the year in which the user was created;
- partitioning by range of identifiers — for example, the first million users, the second million users, and so on;
- partitioning on something else - for example, on the first letter of the user name.
There are a couple of other, not so often used options, like "partitioning by hash on behalf of the user."
Why it is worth using one scheme, but not another? Let's understand their advantages and disadvantages:
- partitioning by date:
- merits:
- easy to understand;
- the number of rows in this table will be fairly stable;
- limitations:
- requires support - from time to time we will have to add new partitions;
- searching by username or id will require scanning all partitions;
- merits:
- id partitioning:
- merits:
- easy to understand;
- the number of rows in the partition will be 100% stable;
- limitations:
- requires support - from time to time we will have to add new partitions;
- searching by username or id will require scanning all partitions;
- merits:
- partitioning by first letter of username:
- merits:
- easy to understand;
- no support - there is a strictly defined set of partitions and we will never have to add new ones;
- limitations:
- the number of rows in the partitions will grow steadily;
- in some partitions there will be significantly more lines than in others (more people with nicknames starting with “t *" than with “y *");
- searching by id will require scanning all partitions;
- merits:
- username hash partitioning:
- merits:
- no support - there is a strictly defined set of partitions and we will never have to add new ones;
- lines will be equally distributed between partitions;
- limitations:
- the number of rows in the partitions will grow steadily;
- searching by id will require scanning all partitions;
- searching by user name will scan only one partition, but only if additional conditions are used.
- merits:
The last drawback of the hashed username approach is quite interesting. Let's see what happens there.
First I need to create more partitions:
$ create table users_2 ( like users including all ); $ alter table users_2 inherit users; ... $ create table users_10 ( like users including all ); $ alter table users_10 inherit users; Now the users table has 10 partitions:
$ \d users Table "public.users" Column | Type | Modifiers ----------------+--------------------------+---------------------------------------------------- id | integer | not null default nextval('users_id_seq'::regclass) username | text | not null password | text | created_on | timestamp with time zone | not null last_logged_on | timestamp with time zone | not null Indexes: "users_pkey" PRIMARY KEY, btree (id) "users_username_key" UNIQUE CONSTRAINT, btree (username) "newest_users" btree (created_on) Number of child tables: 10 (Use \d+ to list them.) PostgreSQL has the constraint_exclusion option. And if you configure it to “on” or “partition”, PostgreSQL will skip partitions that cannot contain matching lines.
In my Pg, this is the default:
$ show constraint_exclusion; constraint_exclusion ---------------------- partition (1 row) So, since all my partitions and the base table have no meaningful restrictions, so any query will scan all 11 tables at once (the main one and 10 partitions):
$ explain analyze select * from users where id = 123; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------- Append (cost=0.29..89.98 rows=11 width=81) (actual time=0.009..0.013 rows=1 loops=1) -> Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=48) (actual time=0.007..0.007 rows=1 loops=1) Index Cond: (id = 123) -> Index Scan using users_1_pkey on users_1 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_2_pkey on users_2 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_3_pkey on users_3 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_4_pkey on users_4 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_5_pkey on users_5 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_6_pkey on users_6 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_7_pkey on users_7 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_8_pkey on users_8 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_9_pkey on users_9 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_10_pkey on users_10 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) Planning time: 1.321 ms Execution time: 0.087 ms (25 rows) This is not very effective, but we can put a limit.
Suppose our partitions were formed by partisation by id, and 100,000 identifiers are stored in each partition.
We can add a few restrictions:
$ alter table users_1 add constraint partition_check check (id >= 0 and id < 100000); $ alter table users_2 add constraint partition_check check (id >= 100000 and id < 200000); ... $ alter table users_10 add constraint partition_check check (id >= 900000 and id < 1000000); Now we repeat the previous query:
$ explain analyze select * from users where id = 123; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------- Append (cost=0.29..16.47 rows=2 width=66) (actual time=0.008..0.009 rows=1 loops=1) -> Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1) Index Cond: (id = 123) -> Index Scan using users_1_pkey on users_1 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) Planning time: 1.104 ms Execution time: 0.031 ms (7 rows) It scans only 2 tables: the main one (in which all data are now, and there are no restrictions, so it cannot be excluded) and a suitable partition.
Great, right?
We can easily add such partitioning conditions by username or created_on. But look what happens when the partitioning key is more complex:
$ alter table users_1 drop constraint partition_check, add constraint partition_check check (abs( hashtext(username) ) % 10 = 0); $ alter table users_2 drop constraint partition_check, add constraint partition_check check (abs( hashtext(username) ) % 10 = 1); ... $ alter table users_10 drop constraint partition_check, add constraint partition_check check (abs( hashtext(username) ) % 10 = 9); In case you do not know, hashtext () takes a string and returns an integer in the range from -2147483648 to 2147483647.
Thanks to simple arithmetic, we know that abs (hashtext (string))% 10 will always produce a value in the range of 0..9, and is easy to calculate for any parameter.
Does PostgreSQL know about this?
$ explain analyze select * from users where username = 'depesz'; QUERY PLAN --------------------------------------------------------------------------------------------------------------------------------------- Append (cost=0.29..89.98 rows=11 width=81) (actual time=0.023..0.023 rows=0 loops=1) -> Index Scan using users_username_key on users (cost=0.29..8.30 rows=1 width=48) (actual time=0.016..0.016 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_1_username_key on users_1 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_2_username_key on users_2 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_3_username_key on users_3 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_4_username_key on users_4 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_5_username_key on users_5 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_6_username_key on users_6 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_7_username_key on users_7 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_8_username_key on users_8 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_9_username_key on users_9 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (username = 'depesz'::text) -> Index Scan using users_10_username_key on users_10 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (username = 'depesz'::text) Planning time: 1.092 ms Execution time: 0.095 ms (25 rows) Not. Does not know. Essentially, PostgreSQL can only automatically exclude partitions for range-based (or equality) checks. Nothing based on features. Even a simple module from a number is already a search:
$ alter table users_1 drop constraint partition_check, add constraint partition_check check ( id % 10 = 0); $ alter table users_2 drop constraint partition_check, add constraint partition_check check ( id % 10 = 1); ... $ alter table users_10 drop constraint partition_check, add constraint partition_check check ( id % 10 = 9); $ explain analyze select * from users where id = 123; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------- Append (cost=0.29..89.98 rows=11 width=81) (actual time=0.009..0.016 rows=1 loops=1) -> Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1) Index Cond: (id = 123) -> Index Scan using users_1_pkey on users_1 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_2_pkey on users_2 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_3_pkey on users_3 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_4_pkey on users_4 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_5_pkey on users_5 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_6_pkey on users_6 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_7_pkey on users_7 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_8_pkey on users_8 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_9_pkey on users_9 (cost=0.15..8.17 rows=1 width=84) (actual time=0.000..0.000 rows=0 loops=1) Index Cond: (id = 123) -> Index Scan using users_10_pkey on users_10 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) Planning time: 0.973 ms Execution time: 0.086 ms (25 rows) It is sad. Because partition keys based on number modules have one huge (in my opinion) advantage - a stable number of partitions. You do not have to create them in the future, unless you decide to re-partition when you reach some higher amount of data.
Does this mean that you cannot use complex (based on functions or modules on numbers) partitioning keys? Not. You can use them, but then the requests are more complex:
$ explain analyze select * from users where id = 123 and id % 10 = 123 % 10; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------- Append (cost=0.29..16.48 rows=2 width=66) (actual time=0.010..0.011 rows=1 loops=1) -> Index Scan using users_pkey on users (cost=0.29..8.31 rows=1 width=48) (actual time=0.010..0.010 rows=1 loops=1) Index Cond: (id = 123) Filter: ((id % 10) = 3) -> Index Scan using users_4_pkey on users_4 (cost=0.15..8.17 rows=1 width=84) (actual time=0.001..0.001 rows=0 loops=1) Index Cond: (id = 123) Filter: ((id % 10) = 3) Planning time: 1.018 ms Execution time: 0.033 ms (9 rows) Here I added another condition, like this:
id % 10 = 123 % 10 PostgreSQL can rewrite it in the process of parsing an expression:
id % 10 = 3 because it knows that the% operator for integers is immutable. And now, as part of the query, I have the exact partitioning key - id% 10 = 3. Thus, Pg can use only those partitions that either do not have a partitioning key (that is, the base table), or have a key corresponding to the query .
Is it worth it to introduce additional complication - you decide.
If you prefer not to change requests, and it doesn’t make it difficult for you to add new partitions from time to time, then you should familiarize yourself with the PG Partition Manger written by my former colleague Keith Fiske - this is a set of functions that you manually start to define partitions which you run over the crown, and it takes on the creation of new partitions for future data.
I already mentioned the inserts, but did not explain how to get around the problem with inserts that should be added to the partitions.
In general, this is a trigger job. Pg_partman from Kita creates such triggers for you, but I want you to understand what is happening and not use pg_partman as a black box, but rather as an auxiliary tool that does the tedious work for you.
Now my partitioning scheme is based on the module of the number (as far as I know, partman cannot do this), so let's write the appropriate trigger function. It will be called when inserting data into the users table and should redirect the insert to the appropriate partition without errors. So, we write:
$ create function partition_for_users() returns trigger as $$ DECLARE v_parition_name text; BEGIN v_parition_name := format( 'users_%s', 1 + NEW.id % 10 ); execute 'INSERT INTO ' || v_parition_name || ' VALUES ( ($1).* )' USING NEW; return NULL; END; $$ language plpgsql; And now the definition of a trigger:
$ create trigger partition_users before insert on users for each row execute procedure partition_for_users(); Let's try to add a line:
$ insert into users (username, password, created_on, last_logged_on) values ( 'depesz', random_string( 20 ), now() - '2 years'::interval * random(), now() - '2 years'::interval * random() ); $ select currval('users_id_seq'); currval --------- 10003 (1 row) Let's see if the data is visible:
$ select * from users where username = 'depesz'; id | username | password | created_on | last_logged_on -------+----------+----------------------+-------------------------------+------------------------------- 10003 | depesz | bp7zwy8k3t3a37chf1hf | 2014-10-24 02:45:51.398824+02 | 2015-02-05 18:24:57.072424+01 (1 row) It looks good, but where are they? In the main table?
$ select * from only users where username = 'depesz'; id | username | password | created_on | last_logged_on ----+----------+----------+------------+---------------- (0 rows) Not. So maybe in the right partitions?
$ select * from users_4 where username = 'depesz'; id | username | password | created_on | last_logged_on -------+----------+----------------------+-------------------------------+------------------------------- 10003 | depesz | bp7zwy8k3t3a37chf1hf | 2014-10-24 02:45:51.398824+02 | 2015-02-05 18:24:57.072424+01 Yes. The trigger worked. But this method has one drawback. Namely - “RETURNING" does not work:
$ insert into users (username, password, created_on, last_logged_on) values ( 'test', random_string( 20 ), now() - '2 years'::interval * random(), now() - '2 years'::interval * random() ) returning *; id | username | password | created_on | last_logged_on ----+----------+----------+------------+---------------- (0 rows) This happens because, from the point of view of the performer, the insertion did not return anything - the trigger returned NULL.
I have not managed to find a successful solution to this problem. In my cases, I just prefer to get the original key value in advance, using nextval (), and then insert the finished value - so that it already exists after the insert:
$ select nextval('users_id_seq'); nextval --------- 10005 (1 row) $ insert into users (id, username, password, created_on, last_logged_on) values ( 10005, 'test', random_string( 20 ), now() - '2 years'::interval * random(), now() - '2 years'::interval * random() ); To all this there is one clarification. Routing all inserts via a trigger slows them down, because for each PG line you will need to perform another “insert".
For urgent bulk inserts, the best solution would be to get them to work directly with partitions. Therefore, for example, instead of
COPY users FROM stdin; .... \. you first find out how many identifiers you need, for example, in this way:
select nextval('users_id_seq') from generate_series(1, 100); And then you issue the appropriate ones:
COPY users_p1 FROM stdin; .... \. COPY users_p2 FROM stdin; .... \. ... , , .
, , , . : ?
: .
, users, 1 (1,000,000,000).
, , .
.
:
$ drop table users_1; $ drop table users_2; ... $ drop table users_10; $ drop trigger partition_users on users; users 10,000 . 0.020 – .
:
$ insert into users (username, password, created_on, last_logged_on) select random_string( (random() * 4 + 5)::int4), random_string( 20 ), now() - '2 years'::interval * random(), now() - '2 years'::interval * random() from generate_series(1, 100000); 0.025. 0.005 , - 110,000 , , .
, . , , id – Pg ( , ).
, – - , , ? , , Pg .
, , , . ( , vacuum, pg_reorg/pg_repack, pg_dump) , . 20 , , , !
, . : , .
. , , () .
, . , , , , , . , «» .
, , . : . , – . , , - : « ».
, , ? ?
Let's get a look. pgbench 97 . , 83 , pgbench_accounts, 666,600,000 .
:
Table "public.pgbench_accounts" Column | Type | Modifiers ----------+---------------+----------- aid | integer | not null bid | integer | abalance | integer | filler | character(84) | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid) aid, 1 666,600,000.
, aid.
, 10 , 67 .
, ? Very simple. pgbench . , , , pgbench.
:
$ while true do date pgbench -T 10 -c 2 bench done 2>&1 | tee pgbench.log 10- , .
, :
do $$ declare i int4; aid_min INT4; aid_max INT4; begin for i in 1..67 loop aid_min := (i - 1) * 10000000 + 1; aid_max := i * 10000000; execute format('CREATE TABLE pgbench_accounts_p_%s ( like pgbench_accounts including all )', i ); execute format('ALTER TABLE pgbench_accounts_p_%s inherit pgbench_accounts', i); execute format('ALTER TABLE pgbench_accounts_p_%s add constraint partitioning_check check ( aid >= %s AND aid <= %s )', i, aid_min, aid_max ); end loop; end; $$; , , :
$ explain analyze select * from pgbench_accounts where aid = 123; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------------------------- Append (cost=0.57..16.75 rows=2 width=224) (actual time=6.468..6.473 rows=1 loops=1) -> Index Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.57..8.59 rows=1 width=97) (actual time=6.468..6.469 rows=1 loops=1) Index Cond: (aid = 123) -> Index Scan using pgbench_accounts_p_1_pkey on pgbench_accounts_p_1 (cost=0.14..8.16 rows=1 width=352) (actual time=0.004..0.004 rows=0 loops=1) Index Cond: (aid = 123) Planning time: 3.475 ms Execution time: 6.497 ms (7 rows) -””:
$ create function partition_for_accounts() returns trigger as $$ DECLARE v_parition_name text; BEGIN v_parition_name := format( 'pgbench_accounts_p_%s', 1 + ( NEW.aid - 1 ) / 10000000 ); execute 'INSERT INTO ' || v_parition_name || ' VALUES ( ($1).* )' USING NEW; return NULL; END; $$ language plpgsql; $ create trigger partition_users before insert on pgbench_accounts for each row execute procedure partition_for_accounts(); , , 666 . ?
. , :
- ( , ).
- , .
, . SQL.
- , sql, . : – . , , . .
psql ( ruby, perl, python – ), , , .
, :
with x as (delete from only pgbench_accounts where aid between .. and .. returning *) insert into appropriate_partition select * from x; – 1000, , , , (666 ).
:
\pset format unaligned \pset tuples_only true \o /tmp/run.batch.migration.sql SELECT format( 'with x as (DELETE FROM ONLY pgbench_accounts WHERE aid >= %s AND aid <= %s returning *) INSERT INTO pgbench_accounts_p_%s SELECT * FROM x;', i, i + 999, ( i - 1 ) / 10000000 + 1 ) FROM generate_series( 1, 666600000, 1000 ) i; \o psql, /tmp/run.batch.migration.sql, (97 ), 666,600 , :
with x as (DELETE FROM ONLY pgbench_accounts WHERE aid >= 1 AND aid <= 1000 returning *) INSERT INTO pgbench_accounts_p_1 SELECT * FROM x; with x as (DELETE FROM ONLY pgbench_accounts WHERE aid >= 1001 AND aid <= 2000 returning *) INSERT INTO pgbench_accounts_p_1 SELECT * FROM x; with x as (DELETE FROM ONLY pgbench_accounts WHERE aid >= 2001 AND aid <= 3000 returning *) INSERT INTO pgbench_accounts_p_1 SELECT * FROM x; , , (, «screen» «tmux», , ssh ):
$ psql -d bench -f /tmp/run.batch.migration.sql . ~ 92, , 17 .
7 . Not bad.
pgbench_accounts ~ 83 (, , pgbench, vacuum).
, , :
$ select count(*) from only pgbench_accounts; count ------- 0 (1 row) pgbench ?
4 :
- .
- .
- .
- .
Results?
phase | min | avg | max ---------+-----------+------------------+----------- Phase 1 | 28.662223 | 64.0359512839506 | 87.219148 Phase 2 | 21.147816 | 56.2721418360656 | 75.967217 Phase 3 | 23.868018 | 58.6375074477612 | 75.335558 Phase 4 | 5.222364 | 23.6086916565574 | 65.770852 (4 rows) , . , , SATA , SSD, – pgbench , .
, - , vacuum . -, .
:
$ truncate only pgbench_accounts; , , :
$ select count(*) from pgbench_accounts; count ----------- 666600000 (1 row) - « ».
, () . . ( 9.6) , , .
, .
PostgreSQL ? PG Day'16 Russia ! early bird , !
Source: https://habr.com/ru/post/273933/
All Articles