Swift. Functional programming

Author: Igor Litvinenko, Senior Mobile Developer.
In this article I will talk about functional programming. Or rather, we will look at the problems of imperative and object-oriented programming, then we will look at functional programming and try to find a solution to these problems in it. We will also see when it is necessary to use functionally programming and when it is not necessary.
History tour
A bit of history. It so happened that all development methodologies came from academic sources. Then it had to go somewhere from two to several decades in order for the methodology to become popular. This was partly the case because we, the developers, need time to change our vision in order to change our ways of solving problems.
')
I really liked the example from the book “We Think Functionally” (or “Functional Thinking”). Imagine that you are a lumberjack, and you have the biggest ax in the forest, which allows you to be the best and most successful lumberjack. But then you read in some magazine a marketer's note that they have now invented a new, extremely effective and modern concept of felling the forest - with the help of chainsaws. Then you order a chainsaw - you deliver it, you unpack it, but you don’t know how it turns on. But you know very well how to chop wood with an ax. And you take a chainsaw and try to cut trees with it just as you usually chop with an ax. And, of course, you can’t do anything - you have no choice but to return to the ax again. But then a neighbor comes to you and explains how to start a chainsaw - and you finally begin to effectively cut down the forest with a chainsaw.
I say this to the fact that an idea, concept or methodology will not take off until it becomes overgrown with accompanying materials (for example, manuals, best practices), and so far a layer of tasks that we can perfectly solve with the help of a new methodology stand out.
If we look at the history, we see that procedural programming coped well with its tasks - it was very fast. And when they invented the first object-oriented language (Simula 67) in 1967, no one understood why this language is needed - everyone paid attention only to the performance losses associated with the need to find the correct implementation of the method, or the right heir, etc. But then the programs began to perform a larger layer of tasks: they became more complicated, the development teams became larger, and it turned out that the object-oriented approach was lacking. As a result, the imperative object-oriented approach to software development became popular with the introduction of C ++, introduced in 1983.
The same story - with cross-platform languages like Java and .NET. The concept originated in 1980: the environment allowed to run the code on Pascal on two machines: Apple 2 and IBM PC. But then there was no power at all to transfer to bytecode and its subsequent translation into machine code. And in the 90s, Sun introduced Java. Now, cross-platform Java and .NET languages are much more in demand than specialists in various machine languages. After all, in the 90s it became clear that it is better to put more expensive powerful hardware on the server, where all the necessary code will be executed during production, but at the same time save on development. After getting acquainted with Java, which has a very good object-oriented model and a garbage collector, most people no longer want, of course, to move to manual memory management.
The problems of the imperative (and object-oriented) approach
However, the imperative, object-oriented approach has its drawbacks.
- Threshold of entry . First, we need to understand the terminology: for example, we need to know what inheritance is and how to use it and, more importantly, when not to use it, but to use an ordinary composition. Secondly, there is a threshold for entry into the project. For example, when you come to a project at the stage of active development, you will have to deal with objects and their interactions.
- Nontrivial splitting into abstractions . It does not always make sense to directly transfer physical objects into programming objects — you still have to somehow split up these objects, introduce additional ones, create different levels of abstraction. At the same time, it is impossible to learn how to do it correctly in any book - it will still come with experience. From books you can only learn about design patterns, but there is another problem:
- Misunderstanding patterns are anti-patterns . Design patterns are designed to ensure that the part of the code that can potentially be changed is transferred as deeply as possible, that is, to go down as low as possible to a specific implementation, but the general logic remains unchanged. This, of course, is very convenient, but people are lazy and do not always understand what they are doing. Because of this, anti-design patterns have appeared. For example, a “divine object” appeared, which “knows” everything about everyone and deprives us of most of its flexibility. The poltergeist class has also appeared: you see what this class does, but you do not understand why it is here. So in imperative programming, we have a lot of these kinds of side effects that any class can cause.
- Unobvious side effects on the interface .
Of course, some problems can be solved by attracting experienced guys who can do refactoring. But when we talk about multithreading, the concept of imperative programming stops working. After all, it is rather difficult to follow the changes in the state of objects in different streams and synchronize them, to do some atomic operations. You can not just take the program out of the box and parallelize it on multiple processors. Moreover, if a non-parallelized code within a program is more than 30%, you will not be able to get any benefits from multiprocessor systems: too much time will be spent on synchronization and atomic actions. Hence the following disadvantages:
- The concept of state change itself stops working.
When the concept does not work, people start looking for others. And then we will see that, in one way or another, functional programming has begun to creep into our favorite languages. We had blocks in Objective-C, we have closures in Swift, we have support for lambda functions in C ++ starting from the 11th standard, and even Java began to acquire lambda expressions. At the hearing, now such languages as Clojure and Scala. So now let's see what functional programming is.
Functionally programming (FP) and its basic principles
If you thought that functional programming is programming with functions, you are right. In this case, we write in a more mathematical style. We always have input and output data, and we write functions, as if composing a pipe within which the data flows.
The main pillars of OP:
The main pillars of OP:
● Constant input data.
• No side effects.
• Multithreading.
● Changing the level of abstraction due to higher-order functions.
• More reusable code.
• Better readability of the code.
• Preservation of context.
The invariability of the input data ensures that all side effects are cut off. This means that you can no longer worry about multi-threaded systems: nothing changes and no synchronization is needed.
Using higher order functions. This means that you can write functions that take other functions as parameters, which allows you to go to the next level of abstraction when you write more general logic, and the way a particular implementation of an action is passed as a parameter of your functions.
Input invariance
Let's now take a closer look at the immutability of the input data. When you come to a project and ask a colleague to help you figure it out, you always have to draw a diagram: objects, methods, messages, what state you should go to, etc. And then you start watching the function. And when you watch a function, you need to:
- Understand what this function does.
- Understand how it will be called - inside this object or outside, or caused by a timer, or by notification, or something else.
- You are watching the interface of an object. How many other objects are affected by this interface?
Of course, you can not answer this question. You cannot even say what will happen in a global sense if you call a particular method. This is the main problem.
Here is some example code:

Suppose we have a class “User”, there is a “ViewController” that stores this “User”, and we have a class “NetworkOperation” - that is, roughly speaking, a request. Since the type “User” is reference, that is, is passed by reference, you, having changed something in “ViewController”, change something in “Network Operation”, very far, and then, as they say, fun debag!
What to do with it? There are two types of data in Swift: reference type and value type. The reference data type is something living, something that somehow reacts and can change its state. Significant type is something dead and unresponsive, simple data. The concept itself says that we need to abandon the use of active objects, that is, from the reference type, and go to using only values. Thus, already at the level of the language, you will get rid of side effects: there is only simple data that doesn’t change itself inside and does not create any additional links. And it is already much easier.
Suppose we have an array "a", which includes the elements "1", "2", "3". The array “b” is a reference to “a”:
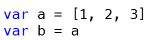
And let's say you want to add an element to the “b” array. Then, if b were an object, it would change. Here, your “a” remains unchanged, that is, there are no side effects at the value level:

If we work with “View”, which works as a reference type, when changing “alpha” in the variable “beta”, we change “alpha” in the variable “a”:

Of course, you might think that a significant type seems to be cut off a little - these are simple data with which, it would seem, nothing can be done. But in reality, this is not the case: in Swift, enumerated types (enum) and structures (struct) are significant types. And the structures are able to implement protocols, store methods, make some calculations - in fact, they are already starting to gradually go out on the same level with objects. However, they have three main advantages:
- First, the structure is always constant and cannot change over time.
- Secondly, isolation: significant types are always isolated. When we, for example, use the reference type “User”, we create dependencies between components inside. If we use a structure, that is, a significant type, we have no dependencies, and all data is isolated. Here, in brief, about significant types.
- Thirdly, it is interchangeability. There is no “instance-structure” concept, as is the case with objects — in other words, we do not have an ID. By and large, the significant type is characterized only by the topics of the data that it has inside - this means that they can be interchangeable. For example, when you say a = [1, 2, 3], it does not matter to me where physically, this object lies in memory. That is, if I turn to “a”, there will be an array with this data. Where they come from me is another question.
Changing the level of abstraction due to higher order functions
Changing the level of abstraction due to higher-order functions means that we can take a function inside our function and execute it as an argument. It also means that in Swift, functions have become 1st class variables - we can handle them in the same way as ordinary variables (cache, accept inside a function, return as results of another function). At the Swift language level, we have already implemented the basic functions of the FP, such as “ map ”, “ filter ” and “ reduce ”. An example of using these functions:

“ Map ” simply transfers a collection of objects of one type to a collection of objects of another type. An example from life. In my previous project, the model of the entire system was written on meaningful types. But some values needed to be saved to the database. When we save to the database, we can operate on the object level with the class “NSManagedObject” (this is a reference data type). And here the “map” function helped me a lot: let's say when you make a query to the database, these objects are returned to you, and you return the wrong collection that returned to you, and you write “map” (“translate to the significant type "), and the data of the significant type is returned to you.
To make the code even more readable and beautiful, Swift provides an abbreviation (shorthand notation), allowing you to organize very fast access to variables. When you write “$ 0”, “$ 1”, “$ 2”, you refer to the parameter number that went inside your circuit.
And one more supplement. If your closure returns some value, the result of the last line, if you did not write “return”, will be returned as the result of your operation. Because of this, in this case, the “map” function simply returns the squares of these numbers.
The next function is “ filter ”. Here we simply pass the closure, which must necessarily return a bool, so that we can determine whether to include this or that expression in the result set.
The “ reduce ” function compresses our collection to one value. For example, the above is an example of how to count the number of chapters in the first act of Romeo and Juliet.
Since functions do not change anything and have no global effect, already at this stage, when we compiled the application, functions like “map”, “filter” and “reduce” automatically work on all processors. That is, we do not change anything outside and know exactly what to do with each individual element - we all scattered all of the processors and returned our result. Everything works very well!
Optional data types and Swift sugar
Let's now look at other features that are present in Swift, but are not mandatory for a functional language.
- Generic types (generics) are always cool. We write more abstract code.
- Static typing makes it easier to understand the written code and simplifies testing.
- Operator overloading allows us to write clear and intuitive code.
- The optional types have greatly changed the API that the SDK itself provides. Suppose we have an “indexOfObject” in Objective C - it always returns a value, but you need to compare the resulting value with the constant “NSNotFound”, and if they are not equal, we find something: “(NSUInteger) indexOfObject :( ObjectType) anObject ”. In Swift, everything is much simpler: we return an optional “index” element: if this element is in the collection, then “index” is returned, if not, then “index” is not present:
public func indexOf(element: Self.Generator.Element) -> Self.Index?public func indexOf(element: Self.Generator.Element) -> Self.Index?
We understand examples
And now let's move from theory to practice.
Example 1. Validation of a local file
First we consider the imperative solution of the problem, and then we move on to the functional one.
Suppose we have a function with which we pass the URL to a local file, and it determines whether the file is obsolete:

When using an imperative object-oriented approach, the solution would be something like the following: we would take a link to the file, check if it exists. Then, if it exists, would take attributes from it. If attributes exist, try extracting the date from the attributes and checking if the file is obsolete or not. That is, we have a clear sequence of actions so that we can get an answer. If we could not expand any optional types, then we, of course, return “false”.
OP proposes to start with splitting into small functions:

The first function will simply determine whether the file exists: accept a string, return an optional string (do one operation — if the file exists, return). The next one is getting the attributes, where we get the input line to an already exactly existing file, and return the possible attributes that we managed to get. The next function will pull the date from the previously received attributes - here we use the abbreviation (“$ 0”). It turns out that the whole path, that is, a pipe composed of functions, will be like this: we get the path, check the existence of the file, extract the attributes and check the creation date.
To make the solution even more beautiful, we define the “bind” function, which will bind the two functions, and define an operator that simply refers to this function. The “bind” function takes an optional value and an optional function (something needs to be done with this value) and also returns an optional value. If the value is, the function is executed, and if not, it is not.

As a result, we have such a very visual method:
return filePath >> = fileExists >> = retrieveFileAttributes >> = extractCreationDate >> = checkExpired ?? false
I do not know about you, but I am very annoyed with work with social networks. For example, to write to Facebook you need to: check whether the user is logged in or not (if not logged in, log in); if logged in, check whether there is a right to post entries, if not, ask for it, if there is, collect the entry. Now imagine how this would all turn into such a small chain of calls: you immediately see what it does if errors occur, know exactly what function it is caused by.
Example 2
The second example shows how easy it is to understand a program in a functional language:

Here we have an array of names. What are we doing with him? First, “filter” - cut off all names that have one character. Then we make the first capital letter and combine it all with a separator with a comma. It turns out that we take the input array, remove the names with one character, and turn it into a string. And now think how much time it would take for you to write such a code in an imperative language, and how much time it would take if you saw such a code in someone else’s project.
When it is not necessary to apply the OP
But not always a functional solution is the best. Suppose we need to count the number of occurrences of each word in the input string. For this we would do something like this:

That is, we would create a result that was a dictionary. We would break the string on the regular line and check for all matches whether the given word is a pretext: if not, we would increase the value of its index.
And in a functional language, it would look like this:
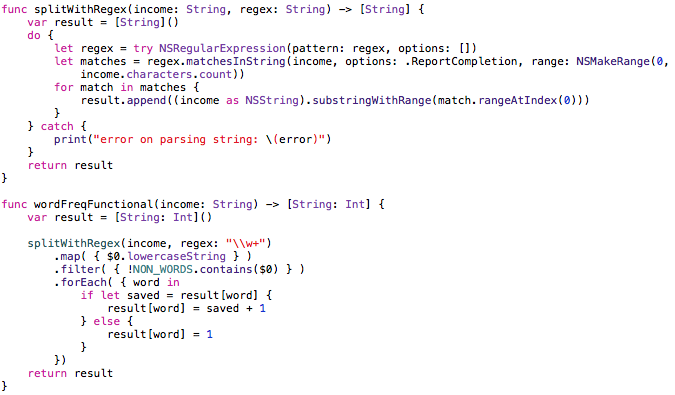
Here we split off separately the function that accepts the input string, and the regular expression - it breaks and returns the result. And then the fun begins. Our main function first makes a “map”, which translates the input data into lower case. Next step: we check whether this word is independent or just a preposition. And then we begin “forEach”, which says that this piece is made for each element.
Yes, our functions like “map”, “filter” and “forEach” are optimized and all that. But just think how many iterations will be done! After all, first we go down and make a “map” for all the elements, then we will filter the extra words, and only then we apply it for all of them. In the first case, all this was solved in one cycle.
Such is the example of the unsuccessful transfer of the functional style.
Conclusion
I do not want to say that we all need to go from our favorite object-oriented programming to functional. Let's be honest - the time for universal application of functional programming has passed. I say that we should use an object-oriented approach where it is needed: where we have UI components, where it is important to have inheritance, where it is important that some methods be defined in the ancestor, where we define all this logic. But we also have a huge reservoir of tasks (for example, data processing, list filtering, etc.), which are very well solved with the help of FP.
Therefore, I urge to write UI as an object-oriented method, and to make the model on meaningful types. Then we get a gain in performance and readability, get rid of unwanted effects. Moreover, our code will become testable.
After all, how is the testing written in the imperative language? We create the universe, perform some actions and see what has changed in the universe.
If we want to test something that is deep in the tests, we need to make a chain of challenges. In the OP, everything is simple: we know that the function always returns the same value for the same input data, which allows writing short data for tests.
Source: https://habr.com/ru/post/273727/
All Articles