Data Driven Realtime Rule Engine in Wargaming: Data Collection
The field of activity of our company extends far beyond the game development. In parallel with it, we have dozens of internal projects, and the Data Driven Realtime Rule Engine (DDRRE) is one of the most ambitious ones.
Data Driven Realtime Rule Engine is a special system that, by analyzing large amounts of data in real time, allows you to personalize the interaction with the player through the recommendations received by the user based on the context of his latest gaming experience.
DDRRE allows our players to get more pleasure from the game, improves their user experience, and also eliminates the viewing of unnecessary promotional and promotional messages.
')
DDRRE architecture
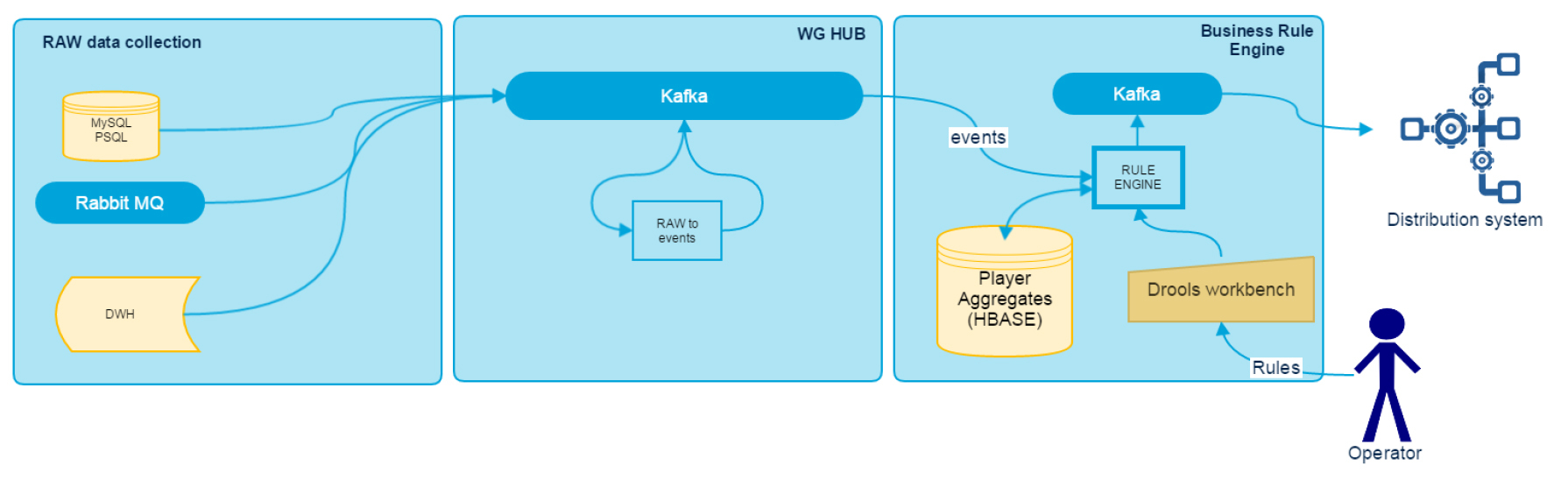
Data Driven Realtime Rule Engine can be divided into several components: RAW Data Collection, WG HUB and Business Rule Engine. Their architecture can be seen in the diagram.
In this article we will talk about adapters for data collection and analysis, and in the following publications we will look at other components of the system in detail.
Data collection is carried out using a common bus, which is used as Kafka. All game subsystems in real time write logs of the set format to the bus. For subsystems that, due to technical limitations, cannot do this, we wrote adapters that collect and redirect logs to Kafka. In particular, our stack contains adapters for MySQL, PSQL, RabbitMQ, as well as an adapter for loading archived data from DWH, via the Hive JDBC interface. Each of them exports metrics about processing speed and lagging behind the source to JMX, where Grafana is used for data visualization, and Zabbix is used to report problems. All adapters are designed as standalone Java applications for Java 8 and Scala.
Adapter for MySQL, psql
It is based on the Tungsten replicator, to which the producer is written in Kafka. We use replication as it is a reliable way to get data without additional load on the database server of the data source.
The current pipeline in Tungsten is as follows:
where the asynckafka module is written by us.
Asynckafka receives data from the previous stage and writes it to Kafka. The last recorded offset is stored in the zookeeper, because it is always there with Kafka. As an option, tungsten can save data to a file or MySQL, but this is not very reliable in case of loss of the host with the adapter. In our case, with the crash, the module reads the offset, and binlog processing continues from the last value saved in Kafka.
Record in Kafka
Saving offset
Recovery offset
Adapter for RabbitMQ
A fairly simple adapter that shifts data from one queue to another. Records are transferred one by one to Kafka, after which they are acknowledged in RabbitMQ. The service delivers the message guaranteed at least once, deduplication occurs on the data side.
Adapter for DWH
When it is necessary to process historical data, we turn to DWH. The storage is based on Hadoop technology, so we use Hive or Impala for data acquisition. To make the loading interface more universal, we implemented it via JDBC. The main problem of working with DWH is that the data in it is normalized, and to collect the entire document, it is necessary to combine several tables.
What we have at the entrance:
• data of the required tables is partitioned by date
• the period for which we want to load data is known
• the document grouping key is known for each table.
To group tables:
• use Spark SQL Data Frame
• we integrate by a cycle on dates from the set range
• we merge several DataFrame by grouping key into one document and write to Kafka using Spark.
An example of setting a datasource using the property file.
In this example, we are building two DataFrame.
The application counts the number of days between the specified dates and performs a cycle from the configuration file:
hdfs_kafka.from = 2015-06-25
hdfs_kafka.to = 2015-06-26
We will describe how the collected information is processed, as well as other components of DDRRE, in the next post. If you have any questions about the described technologies - be sure to ask them in the comments.
Data Driven Realtime Rule Engine is a special system that, by analyzing large amounts of data in real time, allows you to personalize the interaction with the player through the recommendations received by the user based on the context of his latest gaming experience.
DDRRE allows our players to get more pleasure from the game, improves their user experience, and also eliminates the viewing of unnecessary promotional and promotional messages.
')
DDRRE architecture
Data Driven Realtime Rule Engine can be divided into several components: RAW Data Collection, WG HUB and Business Rule Engine. Their architecture can be seen in the diagram.
In this article we will talk about adapters for data collection and analysis, and in the following publications we will look at other components of the system in detail.
Data collection is carried out using a common bus, which is used as Kafka. All game subsystems in real time write logs of the set format to the bus. For subsystems that, due to technical limitations, cannot do this, we wrote adapters that collect and redirect logs to Kafka. In particular, our stack contains adapters for MySQL, PSQL, RabbitMQ, as well as an adapter for loading archived data from DWH, via the Hive JDBC interface. Each of them exports metrics about processing speed and lagging behind the source to JMX, where Grafana is used for data visualization, and Zabbix is used to report problems. All adapters are designed as standalone Java applications for Java 8 and Scala.
Adapter for MySQL, psql
It is based on the Tungsten replicator, to which the producer is written in Kafka. We use replication as it is a reliable way to get data without additional load on the database server of the data source.
The current pipeline in Tungsten is as follows:
replicator.pipelines = slave
replicator.pipeline.slave = d-binlog-to-q, q-to-kafka
replicator.pipeline.slave.stores = parallel-queue
replicator.pipeline.slave.services = datasource
replicator.pipeline.slave.syncTHLWithExtractor = false
replicator.stage.d-binlog-to-q = com.continuent.tungsten.replicator.pipeline.SingleThreadStageTask
replicator.stage.d-binlog-to-q.extractor = dbms
replicator.stage.d-binlog-to-q.applier = parallel-q-applier
replicator.stage.d-binlog-to-q.filters = replicate, colnames, schemachange
replicator.stage.d-binlog-to-q.blockCommitRowCount = $ {replicator.global.buffer.size}
replicator.stage.q-to-kafka = com.continuent.tungsten.replicator.pipeline.SingleThreadStageTask
replicator.stage.q-to-kafka.extractor = parallel-q-extractor
replicator.stage.q-to-kafka.applier = asynckafka
replicator.stage.q-to-kafka.taskCount = $ {replicator.global.apply.channels}
replicator.stage.q-to-kafka.blockCommitRowCount = $ {replicator.global.buffer.size}
where the asynckafka module is written by us.
Asynckafka receives data from the previous stage and writes it to Kafka. The last recorded offset is stored in the zookeeper, because it is always there with Kafka. As an option, tungsten can save data to a file or MySQL, but this is not very reliable in case of loss of the host with the adapter. In our case, with the crash, the module reads the offset, and binlog processing continues from the last value saved in Kafka.
Record in Kafka
override def commit(): Unit = { try { import scala.collection.JavaConversions._ val msgs : java.util.concurrent.ConcurrentLinkedQueue[(String,String,String,Option[Callback])] = new java.util.concurrent.ConcurrentLinkedQueue[(String,String,String,Option[Callback])]() data.foreach(e => { msgs.addAll(ruleProcessor.get.processToMsg(e._1, e._2).map(e => (e._1, e._2, e._3, None))) }) kafkaSender.get.send(msgs.toSeq:_*) } catch { case kpe: KafkaProducerException => { logger.error(kpe.getMessage, kpe) throw new ReplicatorException(kpe); } } lastHeader.map(saveLastHeader(_)) resetEventsToSend() } Saving offset
def saveLastHeader(header: ReplDBMSHeader): Unit = { zkCurator.map { zk => try { val dhd = DbmsHeaderData( header.getSeqno, header.getFragno, header.getLastFrag, header.getSourceId, header.getEpochNumber, header.getEventId, header.getShardId, header.getExtractedTstamp.getTime, header.getAppliedLatency, if (null == header.getUpdateTstamp) { 0 } else { header.getUpdateTstamp.getTime }, if (null == header.getTaskId) { 0 } else { header.getTaskId }) logger.info("{}", writePretty(dhd)) zk.setData().forPath(getZkDirectoryPath(context), writePretty(dhd).getBytes("utf8")) } catch { case t: Throwable => logger.error("error while safe last header to zk", t) } } } Recovery offset
override def getLastEvent: ReplDBMSHeader = { lastHeader.getOrElse { var result = new ReplDBMSHeaderData(0, 0, false, "", 0, "", "", new Timestamp(System.currentTimeMillis()), 0) zkCurator.map { zk => try { val json = new String(zk.getData().forPath(getZkDirectoryPath(context)), "utf8") logger.info("found previous header {}", json) val headerDto = read[DbmsHeaderData](json) result = new ReplDBMSHeaderData(headerDto.seqno, headerDto.fragno, headerDto.lastFrag, headerDto.sourceId, headerDto.epochNumber, headerDto.eventId, headerDto.shardId, new Timestamp(headerDto.extractedTstamp), headerDto.appliedLatency, new Timestamp(headerDto.updateTstamp), headerDto.taskId) } catch { case t: Throwable => logger.error("error while safe last header to zk", t) } } result } } , headerDto.lastFrag, headerDto.sourceId, headerDto.epochNumber, headerDto.eventId, headerDto.shardId, new Timestamp (headerDto.extractedTstamp), headerDto.appliedLatency, new Timestamp (headerDto. override def getLastEvent: ReplDBMSHeader = { lastHeader.getOrElse { var result = new ReplDBMSHeaderData(0, 0, false, "", 0, "", "", new Timestamp(System.currentTimeMillis()), 0) zkCurator.map { zk => try { val json = new String(zk.getData().forPath(getZkDirectoryPath(context)), "utf8") logger.info("found previous header {}", json) val headerDto = read[DbmsHeaderData](json) result = new ReplDBMSHeaderData(headerDto.seqno, headerDto.fragno, headerDto.lastFrag, headerDto.sourceId, headerDto.epochNumber, headerDto.eventId, headerDto.shardId, new Timestamp(headerDto.extractedTstamp), headerDto.appliedLatency, new Timestamp(headerDto.updateTstamp), headerDto.taskId) } catch { case t: Throwable => logger.error("error while safe last header to zk", t) } } result } } Adapter for RabbitMQ
A fairly simple adapter that shifts data from one queue to another. Records are transferred one by one to Kafka, after which they are acknowledged in RabbitMQ. The service delivers the message guaranteed at least once, deduplication occurs on the data side.
RabbitMQConsumerCallback callback = new RabbitMQConsumerCallback() { @Override public void apply(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) { // callback- RabbitMQ String routingKey = envelope.getRoutingKey(); Tuple3<String, String, String> routingExpr = routingExprMap.get(routingKey); // topic Kafka routingKey if (routingExpr == null) throw new RuntimeException("No mapping for routing key " + routingKey); String expr = routingExpr._1(), topic = Objects.firstNonNull(routingExpr._2(), kafkaProducerMainTopic), sourceDoc = routingExpr._3(); Object data = rabbitMQConsumerSerializer.deserialize(body); // , RabbitMQMessageEnvelope msgEnvelope = new RabbitMQMessageEnvelope(envelope, properties, data, sourceDoc); // byte[] key = getValueByExpression(data, expr).getBytes(); byte[] msg = kafkaProducerSerializer.serialize(msgEnvelope); kafkaProducer.addMsg(topic, key, msg, envelope.getDeliveryTag()); // Kafka try { checkForSendBatch(); } catch (IOException e) { this.errBack(e); } } @Override public void errBack(Exception e) { logger.error("{}", e.fillInStackTrace()); close(); } Adapter for DWH
When it is necessary to process historical data, we turn to DWH. The storage is based on Hadoop technology, so we use Hive or Impala for data acquisition. To make the loading interface more universal, we implemented it via JDBC. The main problem of working with DWH is that the data in it is normalized, and to collect the entire document, it is necessary to combine several tables.
What we have at the entrance:
• data of the required tables is partitioned by date
• the period for which we want to load data is known
• the document grouping key is known for each table.
To group tables:
• use Spark SQL Data Frame
• we integrate by a cycle on dates from the set range
• we merge several DataFrame by grouping key into one document and write to Kafka using Spark.
An example of setting a datasource using the property file.
hdfs_kafka.dataframe.df1.uri="jdbc:hive2://[HiveUri]:10000/test;user=hdfs" // jbdc uri hdfs_kafka.dataframe.df1.sql=select * from test.log_arenas_p1_v1 where dt='%s' hdfs_kafka.dataframe.df1.keyField=arena_id // SQL- '%s' hdfs_kafka.dataframe.df1.outKeyField=arena_id // , . hdfs_kafka.dataframe.df1.tableName=test.log_arenas_p1_v hdfs_kafka.dataframe.df2.uri="jdbc:hive2://[HiveUri]:10000/test;user=hdfs" hdfs_kafka.dataframe.df2.sql=select * from test.log_arenas_members where dt='%s' hdfs_kafka.dataframe.df2.keyField=arena_id hdfs_kafka.dataframe.df2.outKeyField=arena_id // , Kafka hdfs_kafka.dataframe.df2.tableName=test.log_arenas_members_p1_v // , In this example, we are building two DataFrame.
The application counts the number of days between the specified dates and performs a cycle from the configuration file:
hdfs_kafka.from = 2015-06-25
hdfs_kafka.to = 2015-06-26
val dates = Utils.getRange(configuration.dateFormat, configuration.from, configuration.to) // , sql dates.map( date => { // val dataFrames = configuration.dataframes.map( dfconf => { val df = executeJdbc(sqlContext, Utils.makeQuery(dfconf.sql, date), dfconf.uri) (dfconf, df) }) val keysExtracted = dataFrames.map( e => { // DataFrame dataFrameProcessor.extractKey(e._2.rdd, e._1.keyField, e._1.tableName) }) // RDD[Key, Row] keyBy keyField val grouped = keysExtracted.reduce(_.union(_)).map( e => (e._1, Seq(e._2))) // dataFrame grouped.reduceByKey(_ ++ _) // Row dataFrameProcessor.applySeq(grouped) }) // We will describe how the collected information is processed, as well as other components of DDRRE, in the next post. If you have any questions about the described technologies - be sure to ask them in the comments.
Source: https://habr.com/ru/post/273607/
All Articles