Pro workflow organization
Hi, Habr!
In this article, we will describe how the development process of the 1C: Enterprise platform is built, how we work on quality assurance, and share the lessons we have gained by creating one of the largest Russian software systems.
The platform employs several groups of up to 10 programmers each, three-quarters of which are written in C ++, and the rest in Java and JavaScript.
Each group works on a separate direction of development, for example:
Total groups more than a dozen. Separately, there is a quality assurance team.
Of course, on a project of this size (more than 10 million lines of code) we are not talking about general ownership of the code, it’s impossible to keep such a volume in mind. We are trying to move towards ensuring the “ bus factor ” in a group of at least two.
We try to maintain a balance between the independence of teams, which gives flexibility and increases the speed of development, and homogeneity, allowing teams to effectively interact with each other and the outside world. So, we have a common version control system, build server and task tracker (we’ll talk about them below), as well as the C ++ coding standard, design documentation templates, error handling rules from users and some other aspects. The rules that all teams must comply with are developed and adopted by a common decision of the team leaders.
On the other hand, in the practices that are directed “inward”, the commands are quite autonomous. For example, code inspections are now applied in all teams (and there are general rules defining the obligatory passage of a review), but they were implemented at different times and the process is structured according to different rules.
The same applies to the organization of the process - someone practicing Agile options, someone using other styles of project management. There seems to be no canonical SCRUM anywhere — the specifics of the boxed product imposes its limitations. For example, the wonderful practice of demonstration is not applicable unchanged. Other practices, for example, the role of Product Owner, have our own counterparts. As the Product Owner in its direction is usually the team leader. In addition to technical leadership in the team, one of its most important tasks is to determine the future directions of development. The process of developing a strategy and tactics for the development of a platform is a complex and interesting topic, to which we will devote a separate article.
')
When a decision is made on the implementation of a particular functional, its appearance is determined in a series of discussions involving, at a minimum, the developer responsible for the task and the team leader. Often, other team members or staff from other groups are involved with the necessary expertise. The final version is approved by the management of the development of the 1C: Enterprise platform.
In such discussions decisions are made:
In addition, recently we are trying to discuss the problem with a wider range of potential consumers - for example, at the last open seminar we talked about the new possibilities for working with binary data that were in the process of designing, answered the questions and managed to pick out several possible applications from the discussion, who have not thought before.
When you start working on a new function, a task is created for it in the task tracker. The tracker, by the way, is written in "1C: Enterprise" and is artlessly called the "Task Base". For each task in the task tracker is stored a project document - in fact, the specification for the task. It consists of three main parts:
Preparation of the project document may begin before implementation, and may start later, if for the task some research or prototype is done first. In any case, this iterative process, unlike the waterfall model, the development and refinement of the project document is done in parallel with the implementation. The main thing is that by the time when the task is ready, the project document has been approved in detail. And there may be many such details, for example:
In addition, the draft teaches the discussion of the problem, so that later it can be understood why certain options were adopted or rejected.
After the project is approved and the developer has implemented a new feature in the task branch (feature branch) in SVN (and when developing a new IDE - in Git), the task is inspected by code and manually checked by other team members. In addition, automatic tests are run on the task branch, which are described below. At the same stage, another technical document is created - a task description, which is intended for testers and technical writers. Unlike the project, the document does not contain technical implementation details, but it is structured in such a way that it helps to quickly understand which sections of the documentation need to be supplemented, whether the new function introduces incompatible changes, etc.
The checked and corrected task joins the main branch of the release and becomes available to the testing group.
In general, “quality” and “quality assurance” are very broad terms. At a minimum, two processes can be distinguished - verification and validation. Verification is usually understood as conformance of software behavior to specifications and the absence of other obvious errors, and validation as verification of compliance with user needs. This section focuses on quality assurance in terms of verification.
Testers get access to the task after it has been injected, but the quality assurance process starts much earlier. Recently we had to make significant efforts to improve it, because it became obvious that the existing mechanisms were not adequately adequate to the increased volume of functionality and noticeably increased complexity. These efforts, in the opinion of partners about the new version 8.3.6, it seems to us, have already had an effect, but a lot of work, of course, is still ahead.
Existing quality assurance mechanisms can be divided into organizational and technological ones. Let's start with the last.
When it comes to quality assurance mechanisms, tests immediately come to mind. Of course, we also use them, and in several versions:
In C ++, we write unit tests. As mentioned in the previous article , we use modified versions of the Google Test and Google Mock . For example, a typical test that checks the ampersand character escaping ("&") when writing JSON might look like this:
The next level of testing is integration tests written in 1C: Enterprise. They form the main part of our tests. A typical set of tests is a separate information base stored in a * .dt file. The test infrastructure loads this database and calls in it a previously known method, which already calls individual tests written by developers, and formats their results so that the CI ( Continuous Integration ) infrastructure can interpret them.
In this case, if the result of the recording diverges from the standard, an exception will be thrown, which the infrastructure will intercept and interpret as a test failure.
Our CI system itself performs these tests for various versions of the OS and DBMS, including 32-bit and 64-bit Windows and Linux, and from the DBMS - MS SQL Server, Oracle, PostgreSQL, IBM DB2, as well as our own file database.
The third and most cumbersome type of tests is the so-called. "Custom test systems." They are used when the checked scenario goes beyond the limits of one base on 1C, for example, when testing interaction with external systems through web services. For each group of tests, one or several virtual machines are allocated, on each of which a special agent program is installed. Otherwise, the test developer has complete freedom, limited only by the requirement to issue the result as a file in the Google Test format, which can be read by CI.
For example, a service written in C # is used to test a SOAP web services client, and a volumetric test framework written in python is used to test various features of the configurator.
The flip side of this freedom is the need to manually configure tests for each OS, manage a fleet of virtual machines and other overhead costs. Therefore, as our integration tests (described in the previous section) evolve, we plan to limit the use of custom test systems.
The above-mentioned tests are written by the platform developers themselves, in C ++ or by creating small configurations (application solutions), sharpened for testing a specific functional. This is a necessary condition for the absence of errors, but not sufficient, especially in such a system as the 1C: Enterprise platform, where most of the possibilities are not applied (used by the user directly), but serve as the basis for building application programs. Therefore, there is one more echelon of testing: automated and manual scenario tests on real application solutions. To the same group can be attributed, and load tests. This is an interesting and big topic about which we are planning a separate article.
In this case, all types of tests are performed on the CI. Jenkins is used as a continuous integration server. Here is what it looks like at the time of this writing:
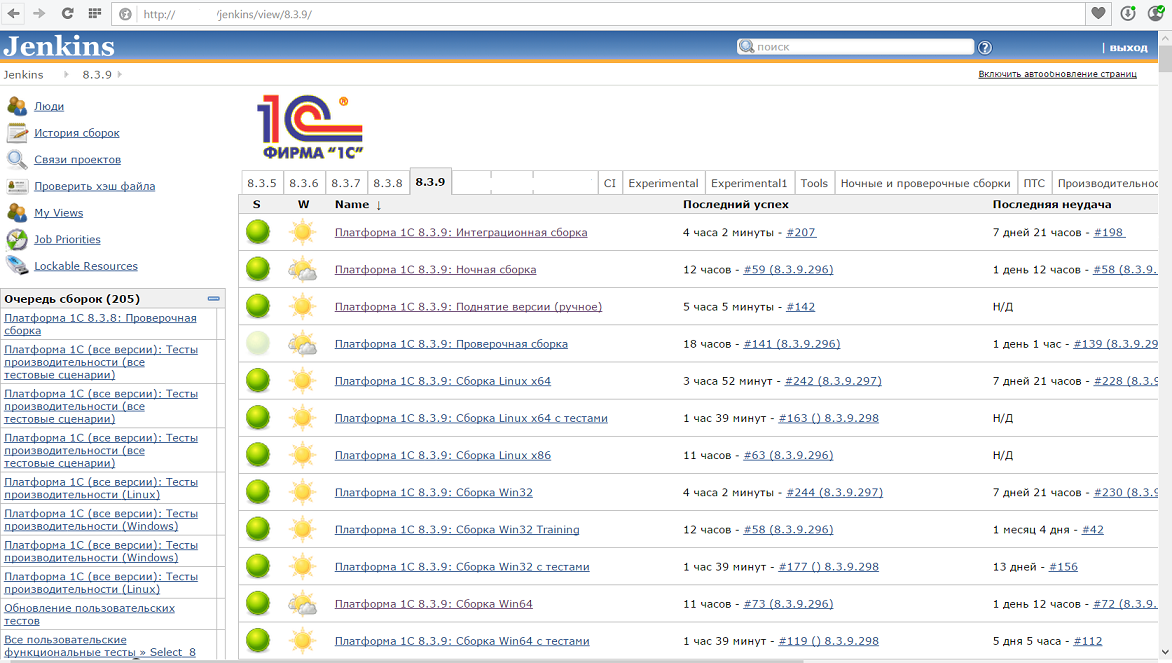
For each configuration of the assembly (Windows x86 and x64, Linux x86 and x64), their own assembly tasks were started, which are run in parallel on different machines. Building one configuration takes a long time - even on powerful hardware, compiling and linking large volumes of C ++ is not an easy task. In addition, the creation of packages for Linux (deb and rpm), as it turned out, takes time comparable to compilation.
Therefore, during the day, the “shortened build” works, which checks compilability under Windows x86 and Linux x64 and performs a minimal set of tests, and the regular build runs every night, collecting all the configurations and running all the tests. Each assembled and tested nightly assembly is marked with a tag - so that the developer, creating a branch for the task or infusing changes from the main branch, was sure to work with a compiled and workable copy. Now we are working to ensure that the regular build runs more often and includes more tests. The ultimate goal of this work is to detect an error with tests (if it can be detected by tests) for no more than two hours after the commit, so that the error found is corrected before the end of the working day. Such a reaction time dramatically increases efficiency: firstly, the developer himself does not need to restore the context with which he worked while introducing an error, secondly, there is less chance that the error will block someone else’s work.
But man does not live by tests alone! We also use static code analysis, which has proven its effectiveness over many years. Once a week there is at least one mistake, and often there is one that surface testing would not catch.
We use three different analyzers:
They all work a little differently, find different types of errors and we like how they complement each other.
In addition to static tools, we also check the system behavior at runtime using the Address Sanitizer tools (part of the CLang project) and Valgrind .
These two very different methods of operation are used approximately for the same thing - searching for situations of incorrect memory handling, for example
Several times the dynamic analysis found errors that had been trying to investigate for a long time manually. This served as a stimulus for organizing the automated periodic launch of some groups of tests with dynamic analysis enabled. Constantly using dynamic analysis for all groups of tests does not allow for performance limitations - when using Memory Sanitizer, performance decreases by about 3 times, and when using Valgrind - by 1-2 orders of magnitude! But even their limited use yields quite good results.
In addition to the automatic checks performed by the machines, we try to build quality assurance into the daily development process.
The most widely used practice for this is peer code review. As our experience shows, constant code inspections do not catch specific errors (although this happens periodically), but prevent their occurrence by providing more readable and well-organized code, i.e. provide quality "in long."
Other goals are pursued by manual testing of each other's work by programmers within the group — it turns out that even superficial testing by a person who is not immersed in a task helps to identify errors at an early stage, even before the task is infused into the trunk.
But the most effective of all organizational measures is the approach that at Microsoft is called “eat your own dogfood”, in which product developers are its first users. In our case, the “product” is our task tracker (the “Task Database” mentioned above), with which the developer works during the day. Every day, this configuration is transferred to the latest version of the platform compiled on the CI, and all the shortcomings and shortcomings immediately affect their authors.
I would like to emphasize that the “Task Database” is a serious information system that stores information about tens of thousands of tasks and errors, and the number of users exceeds a hundred. This is not comparable with the largest implementations of 1C: Enterprise , but is quite comparable with a medium-sized firm. Of course, not all mechanisms can be checked in this way (for example, the accounting subsystem is not involved), but in order to increase the coverage of the functional being tested, it is agreed that different groups of developers use different connection methods, for example, someone uses a web client. , someone thin client on Windows, and someone on Linux. In addition, several instances of the task database server are used, operating in different configurations (different versions, different operating systems, etc.), which are synchronized with each other using the mechanisms included in the platform.
In addition to the Task Base, there are other “experimental” bases, but less functional and less loaded.
The development of the quality assurance system will continue (and indeed, it is hardly ever possible to put an end to this path), and now we are ready to share some conclusions:
And one more conclusion, which does not follow directly from the articles, but will serve as an announcement of the following: the best testing framework is the testing of the application built on it. But how we test the Platform using application solutions, such as 1C: Accounting, we will tell in one of the following articles.
In this article, we will describe how the development process of the 1C: Enterprise platform is built, how we work on quality assurance, and share the lessons we have gained by creating one of the largest Russian software systems.
People and processes
The platform employs several groups of up to 10 programmers each, three-quarters of which are written in C ++, and the rest in Java and JavaScript.
Each group works on a separate direction of development, for example:
- Development Tools (Configurator)
- Web client
- Server infrastructure and failover cluster
- etc.
Total groups more than a dozen. Separately, there is a quality assurance team.
Of course, on a project of this size (more than 10 million lines of code) we are not talking about general ownership of the code, it’s impossible to keep such a volume in mind. We are trying to move towards ensuring the “ bus factor ” in a group of at least two.
We try to maintain a balance between the independence of teams, which gives flexibility and increases the speed of development, and homogeneity, allowing teams to effectively interact with each other and the outside world. So, we have a common version control system, build server and task tracker (we’ll talk about them below), as well as the C ++ coding standard, design documentation templates, error handling rules from users and some other aspects. The rules that all teams must comply with are developed and adopted by a common decision of the team leaders.
On the other hand, in the practices that are directed “inward”, the commands are quite autonomous. For example, code inspections are now applied in all teams (and there are general rules defining the obligatory passage of a review), but they were implemented at different times and the process is structured according to different rules.
The same applies to the organization of the process - someone practicing Agile options, someone using other styles of project management. There seems to be no canonical SCRUM anywhere — the specifics of the boxed product imposes its limitations. For example, the wonderful practice of demonstration is not applicable unchanged. Other practices, for example, the role of Product Owner, have our own counterparts. As the Product Owner in its direction is usually the team leader. In addition to technical leadership in the team, one of its most important tasks is to determine the future directions of development. The process of developing a strategy and tactics for the development of a platform is a complex and interesting topic, to which we will devote a separate article.
')
Work on tasks
When a decision is made on the implementation of a particular functional, its appearance is determined in a series of discussions involving, at a minimum, the developer responsible for the task and the team leader. Often, other team members or staff from other groups are involved with the necessary expertise. The final version is approved by the management of the development of the 1C: Enterprise platform.
In such discussions decisions are made:
- what is included and what is not included in the scope of the task
- what we imagine usage scenarios. It is even more important to understand which possible scenarios we will not support.
- what the user interfaces will look like
- what the API for the application developer will look like
- how the new mechanism will be combined with existing ones
- what will happen to security
- etc.
In addition, recently we are trying to discuss the problem with a wider range of potential consumers - for example, at the last open seminar we talked about the new possibilities for working with binary data that were in the process of designing, answered the questions and managed to pick out several possible applications from the discussion, who have not thought before.
When you start working on a new function, a task is created for it in the task tracker. The tracker, by the way, is written in "1C: Enterprise" and is artlessly called the "Task Base". For each task in the task tracker is stored a project document - in fact, the specification for the task. It consists of three main parts:
- Problem analysis and solutions
- Description of the selected solution
- Descriptions of technical implementation details
Preparation of the project document may begin before implementation, and may start later, if for the task some research or prototype is done first. In any case, this iterative process, unlike the waterfall model, the development and refinement of the project document is done in parallel with the implementation. The main thing is that by the time when the task is ready, the project document has been approved in detail. And there may be many such details, for example:
- The unity of the terms used. If the term “write” was used in one place of the Platform in a similar situation, then the use of “save” should be very seriously justified.
- Unity of approaches. Sometimes, in order to simplify learning and a common experience of use, old approaches have to be repeated in new tasks, even if their disadvantages are obvious.
- Compatibility. In cases where the old behavior can not be saved, you still need to think about compatibility. It often happens that application solutions can be tied to an error and a drastic change will lead to inoperability on the side of end users. Therefore, we often leave the old behavior "in compatibility mode". Existing configurations running on a new release of the platform will use the “compatibility mode” until a conscious decision is made by the developer to disable it.
In addition, the draft teaches the discussion of the problem, so that later it can be understood why certain options were adopted or rejected.
After the project is approved and the developer has implemented a new feature in the task branch (feature branch) in SVN (and when developing a new IDE - in Git), the task is inspected by code and manually checked by other team members. In addition, automatic tests are run on the task branch, which are described below. At the same stage, another technical document is created - a task description, which is intended for testers and technical writers. Unlike the project, the document does not contain technical implementation details, but it is structured in such a way that it helps to quickly understand which sections of the documentation need to be supplemented, whether the new function introduces incompatible changes, etc.
The checked and corrected task joins the main branch of the release and becomes available to the testing group.
Lessons and recipes
- The value of a project document, like any documentation, is not always obvious. For us, it is as follows:
- During design, it helps all participants to quickly restore the discussion context and to make sure that the decisions made will not be forgotten or distorted.
- Later, in doubtful situations, when we are not sure of the correct behavior, the project document helps to remember the decision itself and the motivation that was behind its adoption.
- The project document serves as a starting point for user documentation. The developer does not need to write something from scratch or verbally explain to technical writers - there is already a ready basis.
- It is always necessary to describe scenarios for using the created functional, and not with general phrases, but the more detailed, the better. If this is not done, then decisions can be made that will be either inconvenient or impossible, and the cause may be some small detail. In Agile-development, such details are easily corrected at the next iteration, and in our case, the fix can reach the user in years (full cycle: until the final version of the platform is released-> configurations are released, using innovations -> feedback from users is collected -> made a fix -> a new version is released -> updated configurations taking into account a fix -> the user will install a new version of the configuration for himself).
- Even better than scripts, the use of the prototype by real users (configuration developers) before the official release of the version and fixing the behavior helps. This practice is just beginning to be widely used in our country, and in almost all cases it brought valuable knowledge. Often this knowledge could not be related to the functional capabilities, but related to non-functional behavioral features (for example, the presence of logging or the ease of diagnosing errors).
- In the same way, it is necessary to determine in advance the performance criteria and check their implementation. While these requirements were not added to the checklist when the task was submitted, this was not always done.
Quality assurance
In general, “quality” and “quality assurance” are very broad terms. At a minimum, two processes can be distinguished - verification and validation. Verification is usually understood as conformance of software behavior to specifications and the absence of other obvious errors, and validation as verification of compliance with user needs. This section focuses on quality assurance in terms of verification.
Testers get access to the task after it has been injected, but the quality assurance process starts much earlier. Recently we had to make significant efforts to improve it, because it became obvious that the existing mechanisms were not adequately adequate to the increased volume of functionality and noticeably increased complexity. These efforts, in the opinion of partners about the new version 8.3.6, it seems to us, have already had an effect, but a lot of work, of course, is still ahead.
Existing quality assurance mechanisms can be divided into organizational and technological ones. Let's start with the last.
Tests
When it comes to quality assurance mechanisms, tests immediately come to mind. Of course, we also use them, and in several versions:
Unit tests
In C ++, we write unit tests. As mentioned in the previous article , we use modified versions of the Google Test and Google Mock . For example, a typical test that checks the ampersand character escaping ("&") when writing JSON might look like this:
TEST(TestEscaping, EscapeAmpersand) { // Arrange IFileExPtr file = create_instance<ITempFile>(SCOM_CLSIDOF(TempFile)); JSONWriterSettings settings; settings.escapeAmpersand = true; settings.newLineSymbols = eJSONNewLineSymbolsNone; JSONStreamWriter::Ptr writer = create_json_writer(file, &settings); // Act writer->writeStartObject(); writer->writePropertyName(L"_&_Prop"); writer->writeStringValue(L"_&_Value"); writer->writeEndObject(); writer->close(); // Assert std::wstring result = helpers::read_from_file(file); std::wstring expected = std::wstring(L"{\"_\\u0026_Prop\":\"_\\u0026_Value\"}"); ASSERT_EQ(expected, result); } Integration tests
The next level of testing is integration tests written in 1C: Enterprise. They form the main part of our tests. A typical set of tests is a separate information base stored in a * .dt file. The test infrastructure loads this database and calls in it a previously known method, which already calls individual tests written by developers, and formats their results so that the CI ( Continuous Integration ) infrastructure can interpret them.
& __() = ("json"); = "__"; = .(); JSON = JSON(); JSON(JSON, ); JSON.(); .(, ); In this case, if the result of the recording diverges from the standard, an exception will be thrown, which the infrastructure will intercept and interpret as a test failure.
Our CI system itself performs these tests for various versions of the OS and DBMS, including 32-bit and 64-bit Windows and Linux, and from the DBMS - MS SQL Server, Oracle, PostgreSQL, IBM DB2, as well as our own file database.
Custom test systems
The third and most cumbersome type of tests is the so-called. "Custom test systems." They are used when the checked scenario goes beyond the limits of one base on 1C, for example, when testing interaction with external systems through web services. For each group of tests, one or several virtual machines are allocated, on each of which a special agent program is installed. Otherwise, the test developer has complete freedom, limited only by the requirement to issue the result as a file in the Google Test format, which can be read by CI.
For example, a service written in C # is used to test a SOAP web services client, and a volumetric test framework written in python is used to test various features of the configurator.
The flip side of this freedom is the need to manually configure tests for each OS, manage a fleet of virtual machines and other overhead costs. Therefore, as our integration tests (described in the previous section) evolve, we plan to limit the use of custom test systems.
The above-mentioned tests are written by the platform developers themselves, in C ++ or by creating small configurations (application solutions), sharpened for testing a specific functional. This is a necessary condition for the absence of errors, but not sufficient, especially in such a system as the 1C: Enterprise platform, where most of the possibilities are not applied (used by the user directly), but serve as the basis for building application programs. Therefore, there is one more echelon of testing: automated and manual scenario tests on real application solutions. To the same group can be attributed, and load tests. This is an interesting and big topic about which we are planning a separate article.
In this case, all types of tests are performed on the CI. Jenkins is used as a continuous integration server. Here is what it looks like at the time of this writing:
For each configuration of the assembly (Windows x86 and x64, Linux x86 and x64), their own assembly tasks were started, which are run in parallel on different machines. Building one configuration takes a long time - even on powerful hardware, compiling and linking large volumes of C ++ is not an easy task. In addition, the creation of packages for Linux (deb and rpm), as it turned out, takes time comparable to compilation.
Therefore, during the day, the “shortened build” works, which checks compilability under Windows x86 and Linux x64 and performs a minimal set of tests, and the regular build runs every night, collecting all the configurations and running all the tests. Each assembled and tested nightly assembly is marked with a tag - so that the developer, creating a branch for the task or infusing changes from the main branch, was sure to work with a compiled and workable copy. Now we are working to ensure that the regular build runs more often and includes more tests. The ultimate goal of this work is to detect an error with tests (if it can be detected by tests) for no more than two hours after the commit, so that the error found is corrected before the end of the working day. Such a reaction time dramatically increases efficiency: firstly, the developer himself does not need to restore the context with which he worked while introducing an error, secondly, there is less chance that the error will block someone else’s work.
Static and dynamic analysis
But man does not live by tests alone! We also use static code analysis, which has proven its effectiveness over many years. Once a week there is at least one mistake, and often there is one that surface testing would not catch.
We use three different analyzers:
- Cppcheck
- PVS-Studio
- Built in Microsoft Visual Studio
They all work a little differently, find different types of errors and we like how they complement each other.
In addition to static tools, we also check the system behavior at runtime using the Address Sanitizer tools (part of the CLang project) and Valgrind .
These two very different methods of operation are used approximately for the same thing - searching for situations of incorrect memory handling, for example
- uninitialized memory accesses
- recourse to freed memory
- overruns of an array, etc.
Several times the dynamic analysis found errors that had been trying to investigate for a long time manually. This served as a stimulus for organizing the automated periodic launch of some groups of tests with dynamic analysis enabled. Constantly using dynamic analysis for all groups of tests does not allow for performance limitations - when using Memory Sanitizer, performance decreases by about 3 times, and when using Valgrind - by 1-2 orders of magnitude! But even their limited use yields quite good results.
Organizational quality assurance measures
In addition to the automatic checks performed by the machines, we try to build quality assurance into the daily development process.
The most widely used practice for this is peer code review. As our experience shows, constant code inspections do not catch specific errors (although this happens periodically), but prevent their occurrence by providing more readable and well-organized code, i.e. provide quality "in long."
Other goals are pursued by manual testing of each other's work by programmers within the group — it turns out that even superficial testing by a person who is not immersed in a task helps to identify errors at an early stage, even before the task is infused into the trunk.
Eat your own dogfood
But the most effective of all organizational measures is the approach that at Microsoft is called “eat your own dogfood”, in which product developers are its first users. In our case, the “product” is our task tracker (the “Task Database” mentioned above), with which the developer works during the day. Every day, this configuration is transferred to the latest version of the platform compiled on the CI, and all the shortcomings and shortcomings immediately affect their authors.
I would like to emphasize that the “Task Database” is a serious information system that stores information about tens of thousands of tasks and errors, and the number of users exceeds a hundred. This is not comparable with the largest implementations of 1C: Enterprise , but is quite comparable with a medium-sized firm. Of course, not all mechanisms can be checked in this way (for example, the accounting subsystem is not involved), but in order to increase the coverage of the functional being tested, it is agreed that different groups of developers use different connection methods, for example, someone uses a web client. , someone thin client on Windows, and someone on Linux. In addition, several instances of the task database server are used, operating in different configurations (different versions, different operating systems, etc.), which are synchronized with each other using the mechanisms included in the platform.
In addition to the Task Base, there are other “experimental” bases, but less functional and less loaded.
Lessons learned
The development of the quality assurance system will continue (and indeed, it is hardly ever possible to put an end to this path), and now we are ready to share some conclusions:
- In such a large and massively used product it is cheaper to write a test than not to write. If there is an error in the functionality and it will be missed - the costs for end users, partners, support services and even one development department associated with reproducing, correcting and then checking the error will be much more.
- Even if writing automated tests is difficult, you can ask the developer to prepare a formalized description of the manual tests. After reading it, it will be possible to find lacunae in the way the developer checked his brainchild, and thus potential errors.
- Creating an infrastructure for CI and tests is a costly business, both in finance and in time. Especially if you have to do this for an already mature project. So start as early as possible!
And one more conclusion, which does not follow directly from the articles, but will serve as an announcement of the following: the best testing framework is the testing of the application built on it. But how we test the Platform using application solutions, such as 1C: Accounting, we will tell in one of the following articles.
Source: https://habr.com/ru/post/273591/
All Articles