Evolution of data structures in Yandex. Metric
Yandex.Metrica today is not only a web analytics system, but AppMetrica is an analytics system for applications. At the entrance to the Metric we have a stream of data - events occurring on sites or in applications. Our task is to process this data and present it in a form suitable for analysis.
But data processing is not a problem. The problem is how and in what form to save the results of processing so that they can be convenient to work with. In the development process, we had to completely change the approach to organizing data storage several times. We started with MyISAM tables, used LSM-trees and eventually came to a column-oriented database. In this article I want to tell you what made us do it.
')
Yandex.Metrica has been working since 2008 - more than seven years. Each time, a change in the data storage approach was due to the fact that a particular solution worked too poorly - with insufficient performance margin, insufficiently reliable and with a large number of operational problems, used too much computing resources, or simply did not allow us to realize that what we want.
In the old Metrics for sites, there are about 40 "fixed" reports (for example, a geography report of visitors), several tools for in-page analytics (for example, a click-through map), a Web browser (it allows you to study in detail the actions of individual visitors) and, separately, report designer.
In the new Metric , as well as in Appmetrica instead of “fixed” reports, each report can be arbitrarily changed. You can add new dimensions (for example, add more partitioning to the site login pages in the report on search phrases), segment and compare (you can compare traffic sources to the site for all visitors and visitors from Moscow), change the set of metrics, and so on. Of course, this requires completely different approaches to data storage.
At the very beginning, the Metric was created as part of Direct. In Yandex.Direct, MyISAM tables were used to solve the problem of storing statistics, and we also started with this. We used MyISAM to store “fixed” reports from 2008 to 2011.
Let me tell you what should be the structure of the table for the report, for example, by geography. The report is shown for a specific site (more precisely, the number of the Metrics counter). This means that the primary key must include the counter number - CounterID. The user can select an arbitrary reporting period. It would be unreasonable to save data for each pair of dates, so they are saved for each date and then, when requested, are summed up for a given interval. That is, the primary key includes the date - Date.
In the report, data are displayed for regions as a tree from countries, regions, cities, or as a list. It is reasonable to put a region identifier (RegionID) in the primary key of the table, and collect data in a tree already on the side of the application code, and not the database.
Another is, for example, the average duration of the visit. This means that the columns of the table should contain the number of visits and the total duration of visits.
As a result, the table structure is: CounterID, Date, RegionID -> Visits, SumVisitTime, ... Consider what happens when we want to receive a report. A
MyISAM table is a data file and an index file. If nothing was deleted from the table and the lines did not change their length during the update, the data file would be serialized lines arranged in a row in the order in which they were added. The index (including the primary key) is a B-tree, in the leaves of which there are offsets in the data file. When we read data on an index range, from an index the set of shifts in a file with data gets. Then, over this set of offsets, reads are made from the data file.
Suppose a natural situation when the index is in RAM (key cache in MySQL or system page cache), and the data is not cached in it. Suppose we use hard drives. Time for reading data depends on how much data you need to read and how much you need to do seek. The number of seek-s is determined by the location of the data on the disk.
Events in the Metric come in order, almost corresponding to the time of events. In this incoming stream, the data of different counters are scattered in a completely arbitrary manner. That is, the incoming data is local in time, but not local in the counter number. When writing to the MyISAM table, the data of different counters will also be arranged in a completely random manner, which means that to read the report data, you will need to perform approximately as many random reads as there are necessary rows in the table.
A typical 7200 RPM hard disk can perform from 100 to 200 random reads per second, and a RAID array, if used properly, is proportionally larger. One five-year-old SSD can perform 30,000 random reads per second, but we cannot afford to store our data on an SSD. Thus, if for our report you need to read 10,000 lines, it is unlikely to take less than 10 seconds, which is completely unacceptable.
For reading on a range of a primary key, InnoDB is better suited, since InnoDB uses a clustered primary key (that is, data is stored orderly by the primary key). But InnoDB was impossible to use due to low write speed. If reading this text, you remembered about TokuDB , then continue to read this text.
In order for MyISAM to work faster when selecting a primary key range, some tricks were applied.
Sort the table . Since the data needs to be updated incrementally, it’s not enough to sort the table once, and it’s impossible to sort it every time. However, this can be done periodically for old data.
Partitioning The table is divided into a number of smaller ones in the ranges of the primary key. At the same time, it is hoped that the data of one partition will be stored more or less locally, and queries on the range of the primary key will work faster. This method can be called "cluster primary key manually." In this case, the insertion of data is somewhat slow. Choosing the number of partitions, as a rule, it is possible to reach a compromise between the speed of inserts and reads.
Separation of data into generations . With one partitioning scheme, the reads may be too slow, with the other, inserts, and with an intermediate one, both. In this case, it is possible to divide the data into several generations. For example, the first generation is called operational data - there the partitioning is done in the order of insertion (in time) or not at all. The second generation is called archival data - there it is produced in the order of reading (according to the number of the counter). Data is transferred from generation to generation by the script, but not too often (for example, once a day). Data is read immediately from all generations. This, as a rule, helps, but adds quite a lot of difficulties.
All these tricks (and some others) were used in Yandex. Metric once upon a time so that everything at least somehow worked.
We summarize what are the disadvantages:
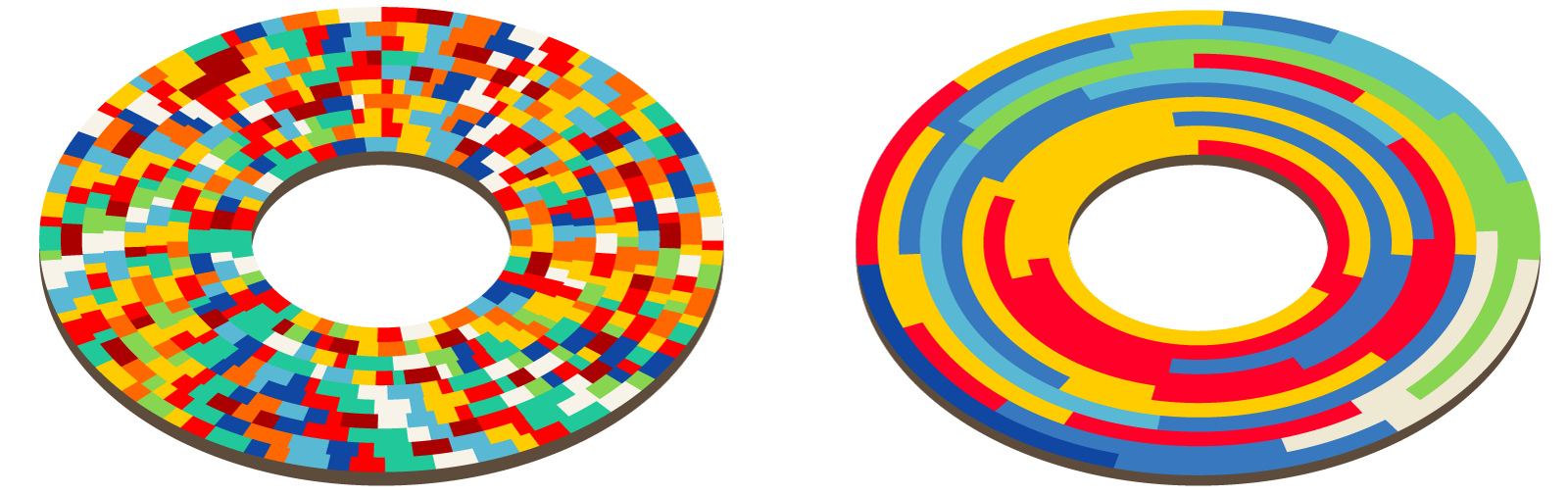
Local data on disk, figurative representation
Overall, the use of MyISAM was extremely uncomfortable. During the daytime, the servers worked with a 100% load on disk arrays (constant head movement). In such conditions, drives fail more often than usual. On the servers, we used disk shelves (16 drives) - that is, quite often we had to restore RAID arrays. At the same time, the replication lagged behind even more, and sometimes the replica had to be replenished. Switching master is extremely inconvenient. We used MySQL Proxy to select the replica to which requests are sent, and this use was very unfortunate (then we replaced it with HAProxy).
Despite these shortcomings, as of 2011, we stored more than 580 billion rows in MyISAM tables. Then everything was converted to Metrage, removed and eventually released many servers.
We use Metrage to store fixed reports from 2010 to the present. Suppose you have the following script work:
For such a well suited fairly common data structure LSM-Tree . It is a relatively small set of “pieces” of data on a disk, each of which contains data sorted by the primary key. New data is first located in any data structure in RAM (MemTable), then written to disk in a new sorted piece. Periodically in the background several sorted pieces are combined into one larger sorted (compaction). Thus, a relatively small set of pieces is constantly maintained.
Among the embedded data structures LSM-Tree implement LevelDB , RocksDB . It is used in HBase and Cassandra .

Metrage is also an LSM-Tree. As the "lines" in it can be used arbitrary data structures (fixed at the compilation stage). Each line is a pair of key, value. The key is a structure with comparison operations for equality and inequality. Value is an arbitrary structure with update (add something) and merge (aggregate, merge with another value) operations. In short, this is a CRDT .
Values can be either simple structures (a tuple of numbers) or more complex ones (a hash table for calculating the number of unique visitors, a structure for a click map). Using the update and merge operations, incremental data aggregation is constantly performed:
Metrage also contains the domain-specific logic we need, which is executed upon requests. For example, for a report by region, the key in the table will contain the identifier of the lowest region (city, settlement), and if we need to receive a report by country, then the data will be aggregated into country data on the database server side.
I will list the advantages of this data structure:
Since reads are not performed very often, but at the same time they read quite a lot of lines, the increase in latency due to the presence of many pieces and the expansion of the data block and the reading of extra lines due to the sparsity of the index does not matter.
Recorded pieces of data are not modified. This allows you to read and write without locks - a snapshot of data is taken for reading. A simple and uniform code is used, but at the same time we can easily implement all the domain-specific logic we need.
We had to write Metrage instead of finalizing any existing solution, because there was no existing solution. For example, LevelDB did not exist in 2010. TokuDB at that time was only available for money.
All systems implementing LSM-Tree were suitable for storing unstructured data and displaying the BLOB -> BLOB type with slight variations. Adapting this to working with arbitrary CRDTs would take much longer than developing Metrage.
Converting data from MySQL to Metrazh was quite laborious: the net time for the conversion program to work was only about a week, but the main part of the work was completed in only two months.
After translating the reports to Metrage, we immediately got an advantage in the speed of the Metrics interface. So, the 90% percentile of the loading time of the report on page headers has decreased from 26 seconds to 0.8 seconds (total time, including the work of all database queries and subsequent data conversions). The time for processing requests by Metrage itself (for all reports) is: median - 6 ms, 90% - 31 ms, 99% - 334 ms.
We used Metrage for five years, and it proved to be a reliable, trouble-free solution. For all the time there were only a few minor failures. The advantages in efficiency and ease of use, compared to the storage of data in MyISAM, are cardinal.
We currently store 3.37 trillion lines in Metrage. For this, 39 * 2 servers are used. We are gradually abandoning data storage in Metrage and have already deleted some of the largest tables. But this system also has a drawback - you can work effectively only with fixed reports. Metrage performs data aggregation and stores aggregated data. And in order to do this, you need to pre-list all the ways in which we want to aggregate data. If we do this in 40 different ways, it means that there will be 40 reports in the Metric, but no more.
In Yandex.Metrica, the amount of data and load size are large enough that the main problem was to make a solution that at least works - solves the problem and at the same time copes with the load within an adequate amount of computing resources. Therefore, often the main efforts are spent on creating a minimal working prototype.
One such prototype was the OLAPServer. We used OLAPServer from 2009 to 2013 as the data structure for the report designer.
Our task is to receive arbitrary reports, the structure of which becomes known only at the moment when the user wants to receive a report. For this it is impossible to use pre-aggregated data, because it is impossible to foresee in advance all combinations of measurements, metrics, conditions. So, you need to store non-aggregated data. For example, for reports calculated on the basis of visits, it is necessary to have a table where each visit will correspond to a line, and each parameter by which a report can be calculated is a column.
We have the following work scenario:
For such a work scenario (let's call it OLAP work script), column DBMS ( column-oriented DBMS ) are best suited. So called DBMS, in which the data for each column are stored separately, and the data of one column - together.
Column DBMS effectively work for OLAP script work for the following reasons:
1. By I / O.
For example, for the query “calculate the number of entries for each advertising system”, it is required to read one column “Advertising system identifier”, which occupies 1 byte in uncompressed form. If the majority of transitions were not from advertising systems, then you can count on at least a tenfold compression of this column. Using the fast compression algorithm, data may be decompressed at a speed of more than a few gigabytes of uncompressed data per second. That is, such a query can be executed at a speed of about several billion lines per second on a single server.

2. According to the CPU.
Since to execute a query, you need to process a sufficiently large number of rows, it becomes relevant to dispatch all operations not for individual rows, but for whole vectors (for example, the vector engine in the VectorWise DBMS) or implement the query execution engine so that the dispatching costs are approximately zero ( An example is code generation with LLVM in Cloudera Impala ). If this is not done, then for any not too bad disk subsystem, the query interpreter will inevitably rest on the CPU. It makes sense not only to store data by columns, but also to process them, if possible, also by columns.
There is a lot of column DBMS. These are, for example, Vertica , Paraccel ( Actian Matrix ) ( Amazon Redshift ), Sybase IQ (SAP IQ), Exasol , Infobright , InfiniDB , MonetDB (VectorWise) ( Actian Vector ), LucidDB , SAP HANA , Google Dremel , Google PowerDrill , Metamarkets Druid , kdb + , etc.
In traditionally string DBMS, solutions for storing data by columns have also recently begun to appear. Examples - column store index in MS SQL Server , MemSQL , cstore_fdw for Postgres, ORC-File formats and Parquet for Hadoop.
OLAPServer is the simplest and extremely limited implementation of a column database. So OLAPServer supports only one table, specified in compile time, - the table of visits. Updating data is not done in real time, as everywhere in the Metric, but several times a day. As data types, only fixed numbers of 1-8 bytes are supported. And as a query, only the option
Despite this limited functionality, OLAPServer successfully coped with the task of the report designer. But I did not cope with the task of realizing the possibility of customizing each Yandex.Metrica report. , URL-, , OLAPServer URL-; — .
2013 OLAPServer- 728 . ClickHouse .
OLAPServer, , ad-hoc . , , , , Metrage?
, , . , . :
, , . , .
, , ( ), . — .
, — . , , .
. , - . , , .
ad-hoc , : Cloudera Impala , Spark SQL , Presto , Apache Drill . , - , .
— ClickHouse. , , .
. . ClickHouse . 2015 11,4 ( ). — , . 200 .
. ClickHouse . , . 60 394 . , -. ClickHouse . 1 ( , ).
. . , ClickHouse , , . , ClickHouse 2,8-3,4 , Vertica. ClickHouse , .
-. SQL, JOIN- ( ). SQL: -, , , sketching . . ClickHouse .
ClickHouse .. , . , . ClickHouse .
ClickHouse . , ., , ClickHouse .
Appmetrica — , ClickHouse . , ClickHouse. , Appmetrica, SELECT.
ClickHouse . Logstash ElasticSearch, - .
ClickHouse — , Graphite Ceres/Whisper. .
ClickHouse . , ClickHouse ( MR) . . , , .
, , . , . , , — .
, . , . ClickHouse , .
, , . , . ClickHouse, «» : «» .
, . - . 200 2009 20 2015 . , , .
. , , , , : , SSD, , . , , , .
. , . , , key-value . , , .
, . . . . . , , . , , ..
But data processing is not a problem. The problem is how and in what form to save the results of processing so that they can be convenient to work with. In the development process, we had to completely change the approach to organizing data storage several times. We started with MyISAM tables, used LSM-trees and eventually came to a column-oriented database. In this article I want to tell you what made us do it.
')
Yandex.Metrica has been working since 2008 - more than seven years. Each time, a change in the data storage approach was due to the fact that a particular solution worked too poorly - with insufficient performance margin, insufficiently reliable and with a large number of operational problems, used too much computing resources, or simply did not allow us to realize that what we want.
In the old Metrics for sites, there are about 40 "fixed" reports (for example, a geography report of visitors), several tools for in-page analytics (for example, a click-through map), a Web browser (it allows you to study in detail the actions of individual visitors) and, separately, report designer.
In the new Metric , as well as in Appmetrica instead of “fixed” reports, each report can be arbitrarily changed. You can add new dimensions (for example, add more partitioning to the site login pages in the report on search phrases), segment and compare (you can compare traffic sources to the site for all visitors and visitors from Moscow), change the set of metrics, and so on. Of course, this requires completely different approaches to data storage.
MyISAM
At the very beginning, the Metric was created as part of Direct. In Yandex.Direct, MyISAM tables were used to solve the problem of storing statistics, and we also started with this. We used MyISAM to store “fixed” reports from 2008 to 2011.
Let me tell you what should be the structure of the table for the report, for example, by geography. The report is shown for a specific site (more precisely, the number of the Metrics counter). This means that the primary key must include the counter number - CounterID. The user can select an arbitrary reporting period. It would be unreasonable to save data for each pair of dates, so they are saved for each date and then, when requested, are summed up for a given interval. That is, the primary key includes the date - Date.
In the report, data are displayed for regions as a tree from countries, regions, cities, or as a list. It is reasonable to put a region identifier (RegionID) in the primary key of the table, and collect data in a tree already on the side of the application code, and not the database.
Another is, for example, the average duration of the visit. This means that the columns of the table should contain the number of visits and the total duration of visits.
As a result, the table structure is: CounterID, Date, RegionID -> Visits, SumVisitTime, ... Consider what happens when we want to receive a report. A
SELECT query is made with the WHERE CounterID = c AND Date BETWEEN min_date AND max_date . That is, reading on the range of the primary key.How is the data actually stored on disk?
MyISAM table is a data file and an index file. If nothing was deleted from the table and the lines did not change their length during the update, the data file would be serialized lines arranged in a row in the order in which they were added. The index (including the primary key) is a B-tree, in the leaves of which there are offsets in the data file. When we read data on an index range, from an index the set of shifts in a file with data gets. Then, over this set of offsets, reads are made from the data file.
Suppose a natural situation when the index is in RAM (key cache in MySQL or system page cache), and the data is not cached in it. Suppose we use hard drives. Time for reading data depends on how much data you need to read and how much you need to do seek. The number of seek-s is determined by the location of the data on the disk.
Events in the Metric come in order, almost corresponding to the time of events. In this incoming stream, the data of different counters are scattered in a completely arbitrary manner. That is, the incoming data is local in time, but not local in the counter number. When writing to the MyISAM table, the data of different counters will also be arranged in a completely random manner, which means that to read the report data, you will need to perform approximately as many random reads as there are necessary rows in the table.
A typical 7200 RPM hard disk can perform from 100 to 200 random reads per second, and a RAID array, if used properly, is proportionally larger. One five-year-old SSD can perform 30,000 random reads per second, but we cannot afford to store our data on an SSD. Thus, if for our report you need to read 10,000 lines, it is unlikely to take less than 10 seconds, which is completely unacceptable.
For reading on a range of a primary key, InnoDB is better suited, since InnoDB uses a clustered primary key (that is, data is stored orderly by the primary key). But InnoDB was impossible to use due to low write speed. If reading this text, you remembered about TokuDB , then continue to read this text.
In order for MyISAM to work faster when selecting a primary key range, some tricks were applied.
Sort the table . Since the data needs to be updated incrementally, it’s not enough to sort the table once, and it’s impossible to sort it every time. However, this can be done periodically for old data.
Partitioning The table is divided into a number of smaller ones in the ranges of the primary key. At the same time, it is hoped that the data of one partition will be stored more or less locally, and queries on the range of the primary key will work faster. This method can be called "cluster primary key manually." In this case, the insertion of data is somewhat slow. Choosing the number of partitions, as a rule, it is possible to reach a compromise between the speed of inserts and reads.
Separation of data into generations . With one partitioning scheme, the reads may be too slow, with the other, inserts, and with an intermediate one, both. In this case, it is possible to divide the data into several generations. For example, the first generation is called operational data - there the partitioning is done in the order of insertion (in time) or not at all. The second generation is called archival data - there it is produced in the order of reading (according to the number of the counter). Data is transferred from generation to generation by the script, but not too often (for example, once a day). Data is read immediately from all generations. This, as a rule, helps, but adds quite a lot of difficulties.
All these tricks (and some others) were used in Yandex. Metric once upon a time so that everything at least somehow worked.
We summarize what are the disadvantages:
- disk data locality is very difficult to maintain;
- tables are locked when writing data;
- replication is slow, replicas are often lagging behind;
- data consistency after failure is not ensured;
- units such as the number of unique users are very difficult to calculate and store;
- data compression is difficult to use; it works inefficiently;
- indexes occupy a lot of space and often do not fit into the RAM;
- data must be shardirovat manually;
- many calculations have to be done on the side of the application code after the SELECT;
- difficult operation.
Local data on disk, figurative representation
Overall, the use of MyISAM was extremely uncomfortable. During the daytime, the servers worked with a 100% load on disk arrays (constant head movement). In such conditions, drives fail more often than usual. On the servers, we used disk shelves (16 drives) - that is, quite often we had to restore RAID arrays. At the same time, the replication lagged behind even more, and sometimes the replica had to be replenished. Switching master is extremely inconvenient. We used MySQL Proxy to select the replica to which requests are sent, and this use was very unfortunate (then we replaced it with HAProxy).
Despite these shortcomings, as of 2011, we stored more than 580 billion rows in MyISAM tables. Then everything was converted to Metrage, removed and eventually released many servers.
Metrage
We use Metrage to store fixed reports from 2010 to the present. Suppose you have the following script work:
- data is constantly recorded in the database with small batch;
- Record stream is relatively large - several hundred thousand lines per second;
- read requests are relatively small - tens to hundreds of requests per second;
- all reads - by primary key range, up to millions of rows per request;
- The lines are quite short - about 100 bytes in uncompressed form.
For such a well suited fairly common data structure LSM-Tree . It is a relatively small set of “pieces” of data on a disk, each of which contains data sorted by the primary key. New data is first located in any data structure in RAM (MemTable), then written to disk in a new sorted piece. Periodically in the background several sorted pieces are combined into one larger sorted (compaction). Thus, a relatively small set of pieces is constantly maintained.
Among the embedded data structures LSM-Tree implement LevelDB , RocksDB . It is used in HBase and Cassandra .
Metrage is also an LSM-Tree. As the "lines" in it can be used arbitrary data structures (fixed at the compilation stage). Each line is a pair of key, value. The key is a structure with comparison operations for equality and inequality. Value is an arbitrary structure with update (add something) and merge (aggregate, merge with another value) operations. In short, this is a CRDT .
Values can be either simple structures (a tuple of numbers) or more complex ones (a hash table for calculating the number of unique visitors, a structure for a click map). Using the update and merge operations, incremental data aggregation is constantly performed:
- during the insertion of data, when forming a new pack in the RAM;
- during background mergers;
- when reading requests.
Metrage also contains the domain-specific logic we need, which is executed upon requests. For example, for a report by region, the key in the table will contain the identifier of the lowest region (city, settlement), and if we need to receive a report by country, then the data will be aggregated into country data on the database server side.
I will list the advantages of this data structure:
- The data is located locally on the hard disk, readings on the primary key range work quickly.
- Data is compressed in blocks. Due to the storage in an ordered form, the compression is quite strong when using fast compression algorithms (in 2010, we used QuickLZ , from 2011 we use LZ4 ).
- Storing data in an ordered manner allows the use of a sparse index. A sparse index is an array of primary key values for each Nth row (N is on the order of thousands). Such an index is obtained as compact as possible and always fits in RAM.
Since reads are not performed very often, but at the same time they read quite a lot of lines, the increase in latency due to the presence of many pieces and the expansion of the data block and the reading of extra lines due to the sparsity of the index does not matter.
Recorded pieces of data are not modified. This allows you to read and write without locks - a snapshot of data is taken for reading. A simple and uniform code is used, but at the same time we can easily implement all the domain-specific logic we need.
We had to write Metrage instead of finalizing any existing solution, because there was no existing solution. For example, LevelDB did not exist in 2010. TokuDB at that time was only available for money.
All systems implementing LSM-Tree were suitable for storing unstructured data and displaying the BLOB -> BLOB type with slight variations. Adapting this to working with arbitrary CRDTs would take much longer than developing Metrage.
Converting data from MySQL to Metrazh was quite laborious: the net time for the conversion program to work was only about a week, but the main part of the work was completed in only two months.
After translating the reports to Metrage, we immediately got an advantage in the speed of the Metrics interface. So, the 90% percentile of the loading time of the report on page headers has decreased from 26 seconds to 0.8 seconds (total time, including the work of all database queries and subsequent data conversions). The time for processing requests by Metrage itself (for all reports) is: median - 6 ms, 90% - 31 ms, 99% - 334 ms.
We used Metrage for five years, and it proved to be a reliable, trouble-free solution. For all the time there were only a few minor failures. The advantages in efficiency and ease of use, compared to the storage of data in MyISAM, are cardinal.
We currently store 3.37 trillion lines in Metrage. For this, 39 * 2 servers are used. We are gradually abandoning data storage in Metrage and have already deleted some of the largest tables. But this system also has a drawback - you can work effectively only with fixed reports. Metrage performs data aggregation and stores aggregated data. And in order to do this, you need to pre-list all the ways in which we want to aggregate data. If we do this in 40 different ways, it means that there will be 40 reports in the Metric, but no more.
OLAPServer
In Yandex.Metrica, the amount of data and load size are large enough that the main problem was to make a solution that at least works - solves the problem and at the same time copes with the load within an adequate amount of computing resources. Therefore, often the main efforts are spent on creating a minimal working prototype.
One such prototype was the OLAPServer. We used OLAPServer from 2009 to 2013 as the data structure for the report designer.
Our task is to receive arbitrary reports, the structure of which becomes known only at the moment when the user wants to receive a report. For this it is impossible to use pre-aggregated data, because it is impossible to foresee in advance all combinations of measurements, metrics, conditions. So, you need to store non-aggregated data. For example, for reports calculated on the basis of visits, it is necessary to have a table where each visit will correspond to a line, and each parameter by which a report can be calculated is a column.
We have the following work scenario:
- there is a broad “ fact table ” containing a large number of columns (hundreds);
- when reading, a sufficiently large number of rows is removed from the database, but only a small subset of the columns;
- read requests are relatively rare (usually no more than a hundred per second per server);
- when performing simple queries, delays of around 50ms are permissible;
- the values in the columns are rather small - numbers and small lines (example - 60 bytes per URL);
- high throughput is required when processing one request (up to billions of lines per second per server);
- the result of the query is substantially less than the original data - that is, the data is filtered or aggregated;
- a relatively simple data update script, usually append-only batch; no complicated transactions.
For such a work scenario (let's call it OLAP work script), column DBMS ( column-oriented DBMS ) are best suited. So called DBMS, in which the data for each column are stored separately, and the data of one column - together.
Column DBMS effectively work for OLAP script work for the following reasons:
1. By I / O.
- To perform an analytical query, you need to read a small number of table columns. In the column database for this you can read only the necessary data. For example, if you need only 5 columns out of 100, then you should count on a 20-fold reduction in I / O.
- Since the data is read in batches, it is easier to compress them. Column data is also better compressed. This further reduces the amount of I / O.
- By reducing I / O, more data gets into the system cache.
For example, for the query “calculate the number of entries for each advertising system”, it is required to read one column “Advertising system identifier”, which occupies 1 byte in uncompressed form. If the majority of transitions were not from advertising systems, then you can count on at least a tenfold compression of this column. Using the fast compression algorithm, data may be decompressed at a speed of more than a few gigabytes of uncompressed data per second. That is, such a query can be executed at a speed of about several billion lines per second on a single server.
2. According to the CPU.
Since to execute a query, you need to process a sufficiently large number of rows, it becomes relevant to dispatch all operations not for individual rows, but for whole vectors (for example, the vector engine in the VectorWise DBMS) or implement the query execution engine so that the dispatching costs are approximately zero ( An example is code generation with LLVM in Cloudera Impala ). If this is not done, then for any not too bad disk subsystem, the query interpreter will inevitably rest on the CPU. It makes sense not only to store data by columns, but also to process them, if possible, also by columns.
There is a lot of column DBMS. These are, for example, Vertica , Paraccel ( Actian Matrix ) ( Amazon Redshift ), Sybase IQ (SAP IQ), Exasol , Infobright , InfiniDB , MonetDB (VectorWise) ( Actian Vector ), LucidDB , SAP HANA , Google Dremel , Google PowerDrill , Metamarkets Druid , kdb + , etc.
In traditionally string DBMS, solutions for storing data by columns have also recently begun to appear. Examples - column store index in MS SQL Server , MemSQL , cstore_fdw for Postgres, ORC-File formats and Parquet for Hadoop.
OLAPServer is the simplest and extremely limited implementation of a column database. So OLAPServer supports only one table, specified in compile time, - the table of visits. Updating data is not done in real time, as everywhere in the Metric, but several times a day. As data types, only fixed numbers of 1-8 bytes are supported. And as a query, only the option
SELECT keys..., aggregates... FROM table WHERE condition1 AND condition2 AND... GROUP BY keys ORDER BY column_nums... is supported SELECT keys..., aggregates... FROM table WHERE condition1 AND condition2 AND... GROUP BY keys ORDER BY column_nums...Despite this limited functionality, OLAPServer successfully coped with the task of the report designer. But I did not cope with the task of realizing the possibility of customizing each Yandex.Metrica report. , URL-, , OLAPServer URL-; — .
2013 OLAPServer- 728 . ClickHouse .
ClickHouse
OLAPServer, , ad-hoc . , , , , Metrage?
, , . , . :
- , ;
- , ;
- ;
- ( );
- (, URL) ( 2 );
- - , ;
, . — , ; - .
, , . , .
, , ( ), . — .
, — . , , .
. , - . , , .
ad-hoc , : Cloudera Impala , Spark SQL , Presto , Apache Drill . , - , .
— ClickHouse. , , .
. . ClickHouse . 2015 11,4 ( ). — , . 200 .
. ClickHouse . , . 60 394 . , -. ClickHouse . 1 ( , ).
. . , ClickHouse , , . , ClickHouse 2,8-3,4 , Vertica. ClickHouse , .
-. SQL, JOIN- ( ). SQL: -, , , sketching . . ClickHouse .
ClickHouse .. , . , . ClickHouse .
ClickHouse . , ., , ClickHouse .
Appmetrica — , ClickHouse . , ClickHouse. , Appmetrica, SELECT.
ClickHouse . Logstash ElasticSearch, - .
ClickHouse — , Graphite Ceres/Whisper. .
ClickHouse . , ClickHouse ( MR) . . , , .
, , . , . , , — .
, . , . ClickHouse , .
, , . , . ClickHouse, «» : «» .
findings
, . - . 200 2009 20 2015 . , , .
. , , , , : , SSD, , . , , , .
. , . , , key-value . , , .
, . . . . . , , . , , ..
Source: https://habr.com/ru/post/273305/
All Articles