Open source application architecture: How nginx works

We at Latera are creating billing for telecom operators and telling about the development of our product in Habré, as well as publishing interesting technical translation materials. And today we present to your attention an adapted translation of one of the chapters of the book “ Architecture of open-source applications ”, which describes the prerequisites for the emergence, architecture and organization of the popular web server nginx.
Multithreading value
Nowadays, the Internet has penetrated everywhere, and it is very difficult to imagine that even 10-15 years ago, the global network was much less developed. The Internet has evolved from simple HTML text-clickable websites running on NCSA and Apache web servers to a constantly-functioning communication medium used by billions of people around the world. The number of devices permanently connected to the network is growing, and the Internet landscape is changing, contributing to the flow of entire industries to online. Online services are becoming more complex, and their success requires the ability to instantly get the right information. The security aspects of online business have also changed significantly. Therefore, the current sites are much more complicated than before, and in general, much more engineering effort is required to ensure their sustainability and scaling.
')
One of the main challenges for site architects at all times was multithreading. Since the beginning of the web services era, the degree of multithreading has steadily increased. Today, a popular site can simultaneously serve hundreds of thousands and even millions of users, and this will surprise no one. Not so long ago, multithreading was needed to work with slow ADSL or dial-up connections. Now, multithreading is needed to work with mobile devices and new application architectures that require a constant and fast connection - the client should receive updates of tweets, news, information from the ribbon of social networks, etc. Another important factor affecting multithreading is the changing behavior of browsers, which, to speed up the loading of a site, open from four to six simultaneous connections to it.
Imagine a simple Apache server that generates 100KB short responses — a simple web page with text or images. It can take a split second to generate and render a page, but it takes 10 seconds for a client to transmit it if there is a bandwidth of 80 kbps. The web server will be able to “pull out” 100 kilobytes of content relatively quickly, and then for 10 seconds it will slowly send them to the client. Now imagine that you have 1000 simultaneously connected clients who have requested the same content. If each client requires the allocation of 1 MB of additional memory, it will take only 1 GB of memory in order to send 1000 clients 100 kilobytes of content.
In the case of persistent connections, the problem of processing multithreading becomes even more acute, since in order to avoid delays associated with the establishment of a new HTTP connection, clients will remain connected.
In order to handle the increased volume of workload associated with the expansion of the Internet audience and, as a result, increasing levels of multithreading, the foundation of the site’s functionality should consist of very efficient blocks. In this equation, all components are important - hardware (CPU, memory, disks), network capacity, application architecture and data storage - however, client requests are accepted and processed by the web server. Therefore, it must have the ability to non-linear scaling with a growing number of simultaneous connections and requests processed per second.
Apache problems
Apache web server still occupies a prominent place on the Internet. The roots of this project go back to the beginning of the 1990s, and initially its architecture was sharpened for the existing systems and hardware, as well as the general degree of development of the Internet. Then the website, as a rule, was a separate physical server, on which a single Apache instance was running. By the beginning of the two thousandths, it became apparent that a model with a single physical server could not be effectively replicated to meet the needs of growing web services. Despite the fact that Apache is a good platform for further development, it was originally designed to create a copy of the web server for each new connection, which in modern conditions does not allow for the necessary scalability.
Ultimately, a powerful ecosystem of third-party services developed around Apache, which allows developers to get almost any tools for building applications. But everything has a price, and in this case for a large number of tools for working with a single software product, you need to pay with less scaling options.
Traditional thread-based or process-based processing models for simultaneous connections involve processing each connection using a separate process or thread and blocking I / O operations. Depending on the application, this approach can be extremely inefficient in terms of the cost of processor and memory resources. Creating a separate process or thread requires preparing a new launch environment, including allocating stack and heap memory, as well as creating a new execution context. Additional processor time is wasted on all of this, which in the end can lead to performance problems due to redundant context switches. All these problems are fully manifested when using the web servers of the old architecture, such as Apache.

A practical comparison of the work of the two most popular web servers is published on Habré in this material .
Nginx web server architecture overview
From the very beginning of its existence, nginx had to play the role of a specialized tool that allows you to achieve higher performance and more economical use of server resources, at the same time allowing for the dynamic growth of a website. As a result, nginx received an asynchronous, modular, event-oriented architecture.
Nginx actively uses multiplexing and notification of events, assigning specific tasks to individual processes. Connections are handled through an efficient execution loop using a specific number of single-threaded processes called workers. Inside each worker, nginx can handle many thousands of simultaneous connections and requests per second.
Code structure
Worker in nginx includes kernel and function modules. The nginx kernel is responsible for maintaining the execution cycle and execution of the appropriate sections of the module code at each step of the processing process. Modules provide most of the application-level functionality. The modules also read and write to the network and the repository, transform the content, perform outgoing filtering and, in the case of work in the proxy mode, transmit requests to higher servers.
The nginx modular architecture allows developers to extend the functionality of a web server without the need to modify its kernel code. There are several types of nginx modules — kernel modules, event modules, phase handlers, protocols, filters, load balancers, variable handlers, etc. At the same time, nginx does not support dynamically loaded modules, that is, they are compiled together with the kernel at the stage of assembly creation. Developers plan to add functionality to loadable modules in the future.
To organize various actions related to receiving, processing and managing network connections and downloading content, nginx uses notification mechanisms and several mechanisms to improve disk I / O performance in Linux, Solaris, and BSD systems — among them, kqueue, epoll, and event ports.
A high-level view of the nginx architecture is shown below:
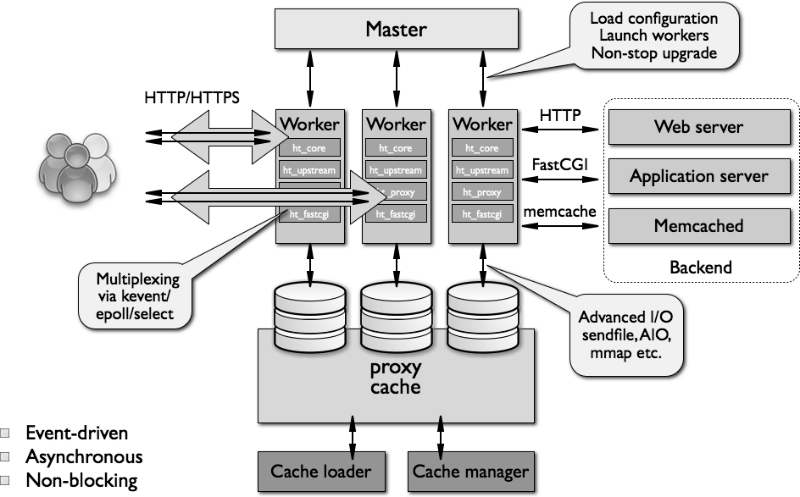
Worker Work Model
As noted above, nginx does not create a process or thread for each connection. Instead, a dedicated worker handles the reception of new requests from a common “listening” socket and starts a highly efficient execution loop within each worker process — this allows processing thousands of connections for one worker. There are no special mechanisms for distributing connections between different worker-processes in nginx, this work is done in the OS kernel. During the download, a set of listening sockets is created, and then the worker constantly receives, reads and writes to sockets during the processing of HTTP requests and responses.
The most difficult part of the nginx “workers” code is the description of the run loop. It includes all kinds of internal calls and actively uses the concept of asynchronous task processing. Asynchronous operations are implemented through modularity, event notifications, as well as extensive use of callback functions and modified timers. The main goal of all this is to get rid of the use of locks to the maximum. The only case where nginx can use them is the situation of insufficient performance of the disk storage performance worker.
Since nginx does not create processes and threads for each connection, in most cases the web server is very conservative and works very efficiently with memory. In addition, it saves processor cycles, since in the case of nginx there is no pattern of constantly creating and destroying processes and threads. Nginx checks the state of the network and storage, initializes new connections, adds them to the execution loop, and then asynchronously processes them to the "victorious end", after which the connection is deactivated and excluded from the loop. Thanks to this mechanism, as well as thoughtful use of system calls and high-quality implementation of supporting interfaces like memory allocators (pool and slab), nginx allows to achieve low or medium CPU utilization even in case of extreme loads.
Using multiple worker processes to handle connections also makes the web server highly scalable to work with multiple cores. Efficient use of multicore architectures is ensured by creating one worker-process for each core, and also allows you to avoid blocking and trash of threads. Resource control mechanisms are isolated within single-threaded worker-processes — this model also contributes to more efficient scaling of physical storage devices, allows for higher disk utilization and avoiding blocking of disk I / O. As a result, server resources are used more efficiently, and the load is distributed among several worker processes.
For different patterns of CPU and disk utilization, the number of nginx worker processes may vary. Web server developers recommend that system administrators try various configuration options to get the best results in terms of performance. If the pattern can be described as “CPU intensive” - for example, in the case of processing a large number of TCP / IP connections, compressing or using SSL, the number of “workers” must match the number of cores. If the load mainly falls on the disk system - for example, if it is necessary to load and unload large amounts of content from the storage, then the number of worker processes may be 1.5-2 times the number of cores.
In the next versions of the web server, nginx developers plan to solve the problem of disk I / O blocking situations. At the time of this writing, in case of insufficient storage performance when performing disk operations of a specific worker process, read or write access may be blocked for it. To minimize this probability, you can use various combinations of directives of configuration files and existing mechanisms — for example, the sendfile and AIO options usually make it possible to significantly improve storage performance.
Another problem with the existing worker-process model is associated with limited support for embedded scripts. In the case of the standard version of nginx, only embedding Perl scripts is available. This situation is simply explained - the main problem is the likelihood that the embedded script will be blocked during the execution of the operation or end unexpectedly. In both cases, the worker process will hang, which can affect thousands of connections at once.
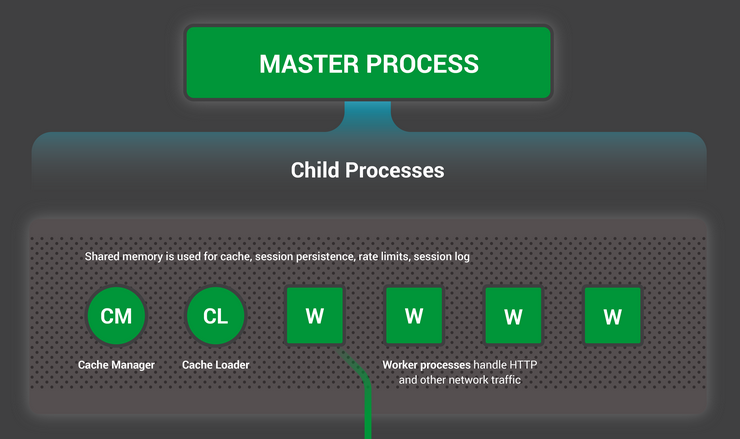
Nginx process roles
Nginx runs several processes in memory - one master process and several “workers”. There are also several service processes — for example, a manager and cache loader. In versions of nginx 1.x, all processes are single-threaded. They all use memory sharing mechanisms to interact with each other. The master process runs as root. Service and worker processes run without superuser privileges.
The master process is responsible for the following tasks:
- configuration reading and validation;
- create, bind and close sockets;
- start, interrupt, and support a configured number of worker processes;
- reconfiguration without interrupting the service;
- control of permanent binary updates (launch of new “binaries” and rollback to the previous version if necessary);
- reopening of log files;
- compiling embedded Perl scripts.
The internal nginx device was described on Habré in this article
Worker processes accept and process connections from clients, provide reverse proxy and filtering functionality, and do almost everything that nginx needs to do. In general, in order to track the current state of a web server, the system administrator needs to look at the workers because they are his [state] is best reflected.
The process of the cache loader is responsible for checking the items in the cache on the disk, as well as updating the in-memory database with metadata. The loader prepares nginx instances to work with files already stored on the disk. It traverses directories, examines the metadata of the content in the cache, updates the necessary elements in the shared memory, and then exits.
The cache manager is mainly responsible for monitoring cache relevance. During normal operation of the web server, it is in memory, and in case of failure, it restarts the master process.
A quick overview of caching in nginx
In nginx, caching is implemented in the form of a hierarchical data storage system in the file system. Cache keys can be configured, and you can control what goes into it using various query parameters. Cache keys and metadata are stored in shared memory segments that can be accessed by the workers, as well as by the loader and the cache manager. Currently, in nginx there is no file caching in the internal memory, except for the optimization capabilities that are available when working with the mechanisms of the OS virtual file system. Each cached response is placed in a separate file system file. The hierarchy is controlled by the nginx configuration directives. When the response is written to the cache directory structure, the path and file name are extracted from the MD5 hash of the proxy URL.
The process of putting content into the cache goes like this: when nginx reads the response from the upstream server, the content is first written to a temporary file outside the cache directory structure. When the web server finishes processing the request, it changes the name of the temporary file and moves it to the cache directory. If the temporary files directory is located on a different file system, then the file will be copied, so it is recommended to place the temporary and cache directories on the same file system. In addition, from a security point of view, a good solution if you need to clean up the files will be to remove them from the cache, since there are third-party extensions for nginx that can provide remote access to cached content.
Nginx configuration
The creation of the nginx configuration system was inspired by Igor Sysoev’s experience with Apache. The developer believed that a scalable configuration system was required for the web server. And the main problem of scalability arose when it was necessary to support a large number of complex configurations with multiple virtual servers, directories and data sets. Maintaining and scaling a relatively large web infrastructure can turn into a real hell.
As a result, the nginx configuration was designed to simplify routine web server support operations and provide tools for further system expansion.
The nginx configuration is stored in several text files, which are usually located in the / usr / local / etc / nginx or / etc / nginx directories. The main configuration file is usually called nginx.conf. To make it more readable, parts of the configuration can be spread across different files, which are then included in the main. It is important to note that nginx does not support .htaccess files — all configuration information should be located in a centralized set of files.
The initial reading and verification of configuration files is carried out by the master process. The compiled configuration form for reading is available to worker-processes after they are extracted from the master-process. Configuration structures are automatically separated by virtual memory management mechanisms.
There are several different contexts for blocks and directives main, http, server, upstream, location (mail, for mail proxy). For example, you cannot place a location block in a block of main directives. Also, in order not to add unnecessary complexity, there is no “global web server” configuration in nginx. As Sysoyev himself says:
Locations, directories and other blocks in the configuration of a global web server are something that I never liked in Apache, so they never appeared in nginx.
The syntax and formatting of the nginx configuration follows the standard for the design of the C code (“C-style convention”). Although some nginx directives reflect certain parts of the Apache configuration, the overall configuration of the two web servers is seriously different. For example, nginx supports rewriting rules, and in the case of Apache, the administrator must manually adapt the legacy configuration for this. The implementation of the rewriting engine is also different.
Nginx also supports several useful original mechanisms. For example - variables and directives try_files. In nginx, variables are used to implement a powerful mechanism for controlling the run-time configuration of a web server. They can be used with various configuration directives to provide additional flexibility in describing query processing conditions.
The try_files directive was originally created as a replacement for conditional if statements, as well as for quickly and efficiently matching different URLs and content.
Internal nginx device
Nginx consists of a kernel and a number of modules. The kernel is responsible for creating the foundation of the web server, for running the functionality of the web and reverse proxy. It is also responsible for using network protocols, building the launch environment and ensuring seamless interoperability between different modules. However, most of the functions associated with protocols and applications are implemented using modules, rather than the kernel.
Connections are processed by nginx using a pipe or a chain of modules. In other words, for each operation there is a module that performs the necessary work - for example, compression, content modification, server inclusion, interaction with external servers via FastCGI or uwsgi-protocols, or communication with memcahed.
There are a couple of modules that are located between the kernel and the “functional” modules - these are http and mail-modules. They provide an extra layer of abstraction between the core and low-level components. With their help, the processing of sequences of events associated with a specific network protocol like HTTP, SMTP or IMAP is implemented. Together with the core, these high-level modules are responsible for maintaining the correct order of calls to the corresponding function modules. Currently, the HTTP protocol is implemented as part of the http module, but in the future, developers plan to allocate it as a separate functional module - this is dictated by the need to support other protocols (for example, SPDY ).
Most of the existing modules complement the HTTP functionality of nginx, but the event and protocol modules are also used to work with mail. Event modules provide an event notification mechanism for various operating systems — for example, kqueue or epoll. The choice of module used by nginx depends on the configuration of the assembly and the capabilities of the operating system. Protocol modules allow nginx to work via HTTPS, TLS / SSL, SMTP, POP3 and IMAP.
This is what a typical HTTP request loop looks like:
- The client sends an HTTP request.
- The kernel, in accordance with the configured location for the nginx request, selects the desired phase handler.
- In the case of proxy functionality enabled, the load balancing module selects an upstream server for proxying.
- The phase handler finishes its work and passes the output buffer to the first filter.
- The first filter passes the output to the second filter.
- The second filter passes the output to the third filter (and so on).
- The final response is sent to the client.
The call of modules in nginx can be configured, it is carried out using callbacks with pointers to executable functions. The disadvantage here is that if a developer wants to write his own module, then he will need to clearly state how and where he should be launched. For example, at what points this may occur:
- Before reading and processing the configuration file.
- At the time of completion of the initial configuration of the main configuration.
- After server initialization (host / port).
- When the server configuration merges with the main one.
- When the master process starts or ends.
- At the time of starting or completing a new worker-process.
- At the time of processing the request.
- In the process of filtering the header and body of the response.
- When selecting the initial and reinitialize the request to the upstream server.
- In the process of processing the response from the upstream server.
- At the time of completion of interaction with this server.
Inside the worker, the sequence of actions leading to the processing cycle, where the response is generated, is as follows:
- Start ngx_worker_process_cycle ().
- Events are handled using OS mechanisms (for example, epoll or kqueue).
- Events are accepted, appropriate actions are sent.
- The process / proxy requests the header and body.
- The response content (header, response) is generated and sent to the client.
- The request is being finalized.
- Timers and events are reinitialized.
A more detailed description of processing an HTTP request can be represented as follows:
- Initialization of request processing.
- Header handling
- Body treatment
- Call the appropriate handler.
- The passage of the processing phase.
During processing, the request goes through several phases. On each of them, the corresponding handlers are called. Usually they perform four tasks: get a location configuration, generate an appropriate response, send a header, and then a body. The handler has one argument: a specific structure that describes the request. The query structure contains a large amount of useful information: for example, the query method, URL, and title.
After reading the HTTP request header, nginx looks at the associated virtual server configuration. If a virtual server is found, the request goes through six phases:
- Phase rewrite server.
- Location search phrase.
- Overwrite location.
- The access control phase.
- Work phase try_files.
- The logging phase.
In the process of creating content in response to a request, nginx sends it to various content handlers. At first, the request can get to the so-called unconditional handlers like perl, proxy_pass, flv, mp4. If the request does not match any of these content handlers, then it is chained to the following handlers: random index, index, autoindex, gzip_static, static.
If a specialized module like mp4 or autoindex does not fit, then the content is treated as a directory on the disk (that is, as static) and the content handler static is responsible for it.
After that, the content is transmitted to filters that work according to a certain scheme. The filter receives a call, starts working, calls the next filter and so on until the last filter in the chain is called. There are header and body filters. The work of the header filter consists of three basic steps:
- Determining the need for action in response to a request.
- Processing request.
- Call the next filter.
Body filters transform the generated content. Among their possible actions:
- Server power on.
- XSLT filtering.
- Filtering images (for example, resizing images on the fly).
- Modification of the coding.
- Gzip compression.
- Fragment coding (chunked encoding).
After passing the filter chain, the response is transmitted to the recording module. There are also two special filters - copy and postpone. The first of them is responsible for filling the memory buffers with relevant content of responses, and the second is used for subqueries.
Subqueries are a very important and very powerful mechanism for processing requests and responses. nginx URL, . - , nginx — , . («-»), , , «--».
, . . , SSI- (server side include) , include URL-. , URL, URL .
nginx upstream-. . . Upstream- , , . :
- .
- ( ).
- , .
- ( ).
- , nginx .
- ( ).
proxy_pass — , . .
nginx , . nginx , , : geo map. geo IP-. , IP- . , map, , runtime-.
worker- nginx Apache. nginx : , , . Nginx - , memcpy.
nginx. , , SSL- , (). nginx slab-. ( ). nginx - . , -regex .
nginx:
Source: https://habr.com/ru/post/273283/
All Articles