We study the graph-oriented DBMS Neo4j on the example of the lexical database Wordnet
 DBMS Neo4j is a NoSQL database, focused on graph storage. The highlight of the product is Cypher's declarative query language.
DBMS Neo4j is a NoSQL database, focused on graph storage. The highlight of the product is Cypher's declarative query language.Cypher borrowed WHERE, ORDER BY keywords from SQL; syntax from such different languages as Python, Haskell, SPARQL; and as a result, a language appeared that allows you to make inquiries to graphs in a visual form like ASCII art . For example, I would present the title of this article as a graph (Neo4j) - [study] -> (Wordnet) . And this is almost a ready database query!
To study a graph-oriented database, you need some kind of graph. This could be a social network, a wikipedia dump, or a rail map. We will go in a simple way and use the huge public graph of the Wordnet lexical database. Princeton linguists have done a tremendous job in systematizing the vocabulary of the English language, and enthusiasts have translated the database into many languages, including Russian. For example, in this database there are over 80 thousand nouns connected by lexical relations, such as “synonym”, “part of the larger”, “material for”, etc. This base is a natural graph, and we import it into Neo4j.
')
Neo4j installation
The installation process for different operating systems is described on the site . All the software described here is platform-independent, but for definiteness all instructions will be for Debian / Ubuntu.
1. Add repository
wget -O - https://debian.neo4j.org/neotechnology.gpg.key | sudo apt-key add - echo 'deb http://debian.neo4j.org/repo stable/' >/tmp/neo4j.list sudo mv /tmp/neo4j.list /etc/apt/sources.list.d sudo apt-get update 2. Install Neo4j (community edition)
sudo apt-get install neo4j This command will install the software in your home directory and start a service that will run on behalf of the user neo4j.
3. Allow remote access
If you installed Neo4j on your computer, skip this step. If access to the server from other computers on the local network is required, edit the file /var/lib/neo4j/conf/neo4j-server.properties
To access from any computer on the local network, set the following parameters:
org.neo4j.server.webserver.address=0.0.0.0 dbms.security.auth_enabled=false The default port 7474 is used, you can change the port by adding a line to the same file:
org.neo4j.server.webserver.port=7474 Please note that we have not configured the security of the DBMS! Read more instructions .
You can verify the installation by typing the server address and port in the browser. Neo4j implements a luxurious graphical console through a browser. REST requests to the database from the client software, which we will install in the next step, go through the same port.
Client Installation (Python)
In order to import the Wordnet base into Neo4j, we will use the Python script.
1. First you need to install the py2neo library .
pip install py2neo 2. Download my script from github
mkdir habrawordnet2neo4j cd habrawordnet2neo4j git clone https://github.com/sergey-zarealye-com/wordnet2neo4j.git The script hardly pretends to industrial quality code, but if you want to experiment with Neo4j from Python, then look at the code, this will help you start programming faster.
Getting lexical Wordnet database
On the Download page of the Wordnet project you are offered to download the database along with the software for viewing it. But we want to use Neo4j for viewing! Therefore, it is enough to download only data files:
- The latest version of the English Wordnet database is available at the link.
- Previous versions (for example, for compatibility with ImageNet)
- I suggest to download the Russian version from the site wordnet.ru
Unzip files to accessible place.
Import data in Neo4j
Lexical data in Wordnet are in the files in parts of speech. For example, nouns are in the data.noun file; verbs - in data.verb; but with other parts of speech, I have not tried.
1. Import of nouns
To import nouns, go to the directory where my scripts were placed (we just called it habrawordnet2neo4j) and run the command in the console:
python wordnet2neo4j.py -i rwn3/data.noun --neo4j http://127.0.0.1:7474 --nodelabel Ruswordnet --reltype Pointer --encoding cp1251 --limit 1000 Let's look at the parameters in more detail.
-i path to wordnet data file --neo4j URL of the Neo4j database server --nodelabel Label nodes matching Wordnet words in the created graph (in Neo4j, the nodes of the graph provide text labels; it's just an id) --reltype type of edges of the graph corresponding to Wordnet pointers (in Neo4j, graph edges can be of type; this is just identifier) --encoding Data file encoding; Russian language base is recorded cp1251 encoded; for english files this the parameter does not need to be specified --limit Maximum number of file lines to be processed; the fact is that my script is pretty slow and to try you can limit the amount of imported data, such as the first 1000 lines of a file; for import full parameter this parameter does not need to be specified, and get ready to wait an hour and a half.
2. Import of verbs
To import verbs run the command in the console:
python wordnet2neo4j.py -i rwn3/data.verb --neo4j http://127.0.0.1:7474 --nodelabel Ruswordnet --reltype Pointer --encoding cp1251 --limit 1000 It is not necessary to import verbs, although some of them are related to nouns, and it is interesting to study.
3. Make sure the data is imported.
To do this, open the Neo4j console (enter the address and port of the database server) in the browser and enter the following query:
MATCH (node)-[relation]-() RETURN node, relation LIMIT 100 If you got an image of a graph on the screen, then everything went well.
Perform simple queries
All further actions will be performed in the browser, in the Neo4j console. I will assume that you used Ruswordnet as the node labels and Pointer as the type of edges (as indicated in the previous section). And that you imported the Russian Wordnet database entirely .
1. Hello World
As indicated on the Russian Wordnet website, about half of the semantic units containing the most commonly used words have been translated. Therefore, we will try to find in the database the first thing that came to mind:
MATCH (n:Ruswordnet {name: "_"}) RETURN n Perform a query, make sure that this concept is found, which means, according to Russian linguists, it is among the most commonly used. Let's analyze this simple query.
The MATCH keyword is about the same as SELECT in SQL. Roughly speaking, “find the elements of the graph that match the pattern”.
Parentheses indicate nodes of the graph. The template (n: Ruswordnet) would indicate that we want to find all nodes with the label “Ruswordnet”. Here n is an identifier, you can say "variable".
The nodes of the graph (and the edges too) can be supplied with arbitrary attributes. In order to find a specific node, we specified a condition for the attributes in the request in a format similar to JSON: {name: “digging_ of the corpse”} . Thus, the phrase
MATCH (n:Ruswordnet {name: "_"}) means that all nodes with the Ruswordnet tag and the name attribute equal to the concept specified there will be selected from the entire graph.
The keyword RETURN tells us which variables we are interested in. In this case, we just wanted to see the node (s) corresponding to the specified conditions, so we write RETURN n . It is important to understand that n is a collection of nodes that satisfy the query. To verify this, simply replace the concept in the query:
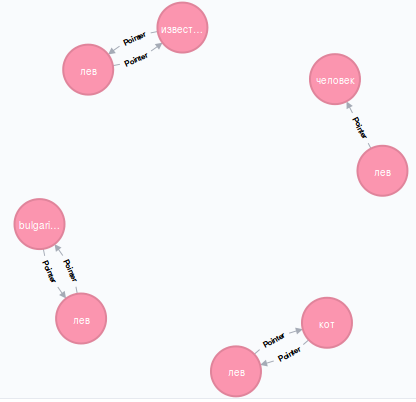
MATCH (n:Ruswordnet {name: ""}) RETURN n If you have imported the entire Wordnet database, you will see six nodes of the "lion" concept. Let's see why.
2. Variables = collections
Let's execute such request:
match (n:Ruswordnet {name: ""})--(m) return n,m Here we have set a more complex search pattern. We want to find all nodes (n) corresponding to the concept of "lion", as well as all nodes (m) associated with lions. A link, i.e., a graph edge, is denoted by two hyphens. You can explicitly indicate the direction of interest to us as a symbol -> (this is what I called ASCII art).

If you do not see the names of the meaningful units, click on the Ruswordnet button (23) in the upper left corner of the graph, and in the status bar at the bottom of the console, select “name” in the Caption field. So it will be clearer.
Now we understand that this lion turns out to be not only the Bulgarian currency (bulgarian_money), for which the Stotinka is a penny, but also a big cat, a constellation, an astrological sign, and something related to pride.
3. Connect the edges
In the Wordnet base, edges are called pointers (Pointer), and a large number of linguistic pointers are used. They are denoted by symbols, some of which I list in the table:
| Symbol | English name linguistic relations | Linguistic attitude |
|---|---|---|
| ! | Antonym | Antonym |
| @ | Hypernym | Generalization |
| @i | Instance hypernym | Generalization instance |
| ~ | Hyponym | Refinement |
| ~ i | Instance hyponym | Specification Refinement |
| #m | Member holonym | The concept that includes this concept |
| #s | Substance holonym | The substance that makes up the subject |
| #p | Part holonym | Item that includes this item as part |
| % m | Member meronym | Part of a more general concept |
| % s | Substance meronym | What substance does the subject consist of? |
| % p | Part meronym | Part of the subject |
| = | Attribute | Attribute |
| + | Derivationally related form | Derivative form |
During the import process, we assigned the pointer_symbol attribute to the graph edges, and now we can make requests taking into account the edge attributes. Let's see what a generalization (hypernum) is:
MATCH (n:Ruswordnet {name: ""})-[p:Pointer {pointer_symbol: "@"}]->(m) RETURN n,m Square brackets denote edge specifications. In this query, we want to find the edges of the Pointer type, whose attribute pointer_symbol is “@”, i.e., the generalization symbol. By the way, the symbol of refinement “~”, opposite to generalization.
Now it is clear that a generalization for a lion is a cat, as well as a man. Of course, we are talking about different semantic units: the lion (cat) is one node of the graph, and the lion (man) is another node corresponding to the sign of the zodiac. Leo (fame) is the result of a poor translation into Russian; refers to the lion (celebrity), i.e. celebrity, secular lion.
Let's see what part holonym is:
MATCH (n:Ruswordnet {name: ""})-[p:Pointer {pointer_symbol: "#p"}]->(m) RETURN n,m And now it is clear: the lion enters the zodiac as an integral part, which means the zodiac is part holonym for the lion.
The table shows that Wordnet contains many interesting relationships, for example, from what substances what has been done. Unfortunately, there is no information that the lion is made of meat, so we put the question differently: to find such nodes in the graph that are related by the relation "of what substance is made."
MATCH (n)-[p:Pointer {pointer_symbol: "#s"}]->(m) RETURN n,m LIMIT 10 In this query, we do not impose any conditions on the nodes (n) and (m) . We only want the edges to be linked to the "#s" attribute. Notice that the LIMIT keyword, familiar to us from SQL, has appeared. If he were not here, the server would give us a lot of results, and it would be bad for our browser.
As a result of the request, we learned that cigarettes are made of marijuana, and the soup of oxen tails is made of oxtails.
4. Chains of arbitrary length
In childhood, everyone played this game: turn a fly into an elephant. To do this, it was necessary to change one letter in the word, until the word MUHA turned into the word ELEPHANT. Let's find out in the lexical graph whether the LION and the WAEC are connected.
MATCH (n:Ruswordnet {name: ""})-[p:Pointer*1..3]-(m:Ruswordnet {name: ""}) RETURN n,m,p The design [p: Pointer * 1..3] says that it is required to find a chain of edges of the Pointer type from one to three in length, connecting the “lion” node with the “sheep” node.

This is different from the classic children's game, but also interesting: WASTE - PROSTAK - MAN - LEO ... it sounds proud. By the way, you can try to find a connection between the fly and the elephant, only slightly increase the maximum length of the chain. I used the value 6. By the way, do not try to immediately put 100 - the search process is likely to fail because the number of options for iterating over the path in the graph will be too large. So, here's how the elephant and the fly are connected lexically:
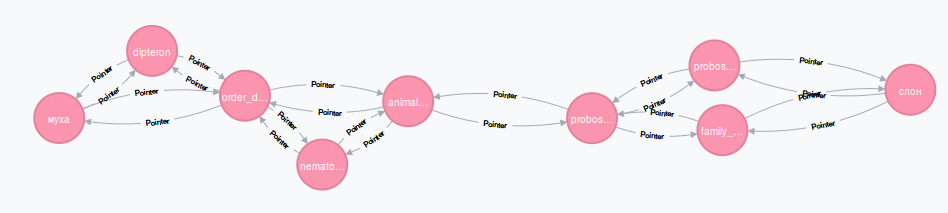
I think at this stage you have understood a lot about the Neo4j database, and are able to independently discover many interesting things in the Wordnet database, or you can apply Neo4j in your projects. We use a bunch of Neo4j c Wordnet in the search system for film archives. If you want to engage in research in the field of machine learning, I invite you for an internship or a permanent job at NIKFI - a film and photo research institute.
Source: https://habr.com/ru/post/273241/
All Articles