How we made ABBYY FineReader, or a story that happened 20 years ago
 ABBYY FineReader is a program for text recognition, which in Russia has been known to many since student times. This year FineReader is 22 years old, it is a bit younger than our Lingvo dictionary. How did it happen that, together with the dictionary, young programmers from BIT Software (at that time ABBYY was called this way) were engaged in text recognition? And what helped Fine become one of the most recognizable programs on the market?
ABBYY FineReader is a program for text recognition, which in Russia has been known to many since student times. This year FineReader is 22 years old, it is a bit younger than our Lingvo dictionary. How did it happen that, together with the dictionary, young programmers from BIT Software (at that time ABBYY was called this way) were engaged in text recognition? And what helped Fine become one of the most recognizable programs on the market?In fact, everything is very logical. If it were not for Lingvo, FineReader could not have been. It all began with a large-scale and ambitious complex called Lingvo Systems. With it, a person could scan the text in one language, skip it through the program and get the translation, however, a draft, but to understand it it was enough.
Lingvo Systems combined four programs: from third-party companies - character recognition, proofreader, translator, as well as our Lingvo dictionary. And the weakest link was the recognition: the program needed to be taught each font for a long time, but even after that the quality left much to be desired. The program was supposed to meet at least several copies of one letter and each time needed a hint. Little by little, she “began to see” and began to understand more and more symbols. So went through the learning process. But as soon as the font was changed or at least its size, everything had to be repeated from the beginning.
')
It should be said that then, in the early 90s, organizations that had spun off from various research institutes had already begun to develop their OCR systems (optical character recognition). It was a rather demanded technology - quality recognition was necessary not only for us for our Lingvo Systems, but also for the market. And we had a choice - wait for someone else to make a cool program, or develop your own.
We decided not to wait. Of course, the task seemed to be non-trivial: whole scientific institutions were engaged in the problem of character recognition, but we had no such experience. But we were young and ambitious, we thought that we could do any tasks, so we enthusiastically set about developing a high-quality program.
We started to create a program in November 1992, and planned to finish by May 1993. The lack of a quality recognition program significantly interfered with sales, the competitors were not asleep, so we had to hurry. Realizing that it was impossible to develop all the technology from scratch at such a time, we acquired some ideas from a young scientist who worked at home on a similar program in his spare time — without a special goal, simply from personal interest in the subject.
Its technology was in a state far from commercial application, and we put a lot of effort into getting the program to produce a useful result. One thing is experimental development, another is a working product. Initially, the program code was developed under MS DOS, and we needed to transfer everything under Windows. In addition, the technology supported only one simplest image format (uncompressed BMP), and the commercial product was required to support all the main formats at that time — at least the TIFF format. But in those days it was a very unstable format, each of them wrote as he wanted: now with alignment, and different, now without, then in the direct version, now in negative. In general, it was necessary to tinker, and still TIFF files were still there for a long time, which caused reading problems.
And most importantly: there were practically no ready-made descriptions of characters in the system, and there were no tools for creating these descriptions at all. As such a tool, a set of large text files was used, in which generalized character outlines were drawn in pseudographic form. They were supposed to be edited and improved right in this file in a regular text editor. At some point, David Yang personally sat down to prepare the data for the system - before that, several of the girls hired for this job refused it, it was very hard. The tool was very inconvenient, and the work was large, complex and very tedious. It was necessary for hours to thumb through huge text files, something there to look out for and edit, studying the results of test runs. The work seemed eternal, progress was taking small steps. It needed a strong psyche to cope with this. And David two months without days off every day for 12-14 hours brought to the mind the recognition base.
In parallel, we began to delve into the subject area. We communicated with specialists, met Alexander Lvovich Shamis - an outstanding scientist who was engaged in practical and theoretical problems of artificial intelligence, developed applied technologies in the field of machine perception (Alexander Lvovich still works as a scientific consultant at ABBYY). And by the time FineReader 1.0 was released, we already knew what the next version should be. You will ask why all the good things that we have invented were not included in the first version - we will answer that the first version had to be done quickly. Companies needed money - without the first version, we would not have had enough money to develop the next one. The next version was significantly better than the first - not even on the head, but on many heads. She made significantly fewer mistakes, coped with difficult problems much better, retained formatting much better, and for those times had just record accuracy of work.
Of course, we approached the development wisely, imagined how an ideal program should look like. And we immediately had two advantages - font independence and multilingualism.
Everything is simple with multilingualism: it is obvious that many technical texts, even written in Russian, contain quite a lot of words and terms in Latin, most often in English. But at that time for some reason nobody thought about it, and the first recognition systems understood only one language. And we specifically included in the program support for Russian and English, so that such texts can be processed efficiently. Here we were helped by the presence in the team of Vladimir Selegay, who had considerable experience in developing spelling checkers for various languages. In general, since then and still vocabulary support is the strength of our recognition technology.
Font independence (omnifonto) means that the program did not need to be configured to recognize each new font, that is, it recognizes characters of almost any size and type. Our FineReader was the first omnifontovoy program that supports the Cyrillic alphabet. Now we are accustomed to, that if the program did not recognize the font, it means that it is somehow very complex or bizarre, and then even for ordinary book fonts, it was necessary to conduct training. Step to the left, step to the right - and the program cannot even perceive the font that actually knows. For example, if it is of a different size or image quality is worse.
This is how the box of the first FineReader looked:


Immediately after the release of the program, a huge interest arose in it. The demand was great, and the programs that existed before the appearance of FineReader did not satisfy him. We were lucky - we were in the right place at the right time.
The first version of FineReader has a circulation of 500 copies. In the first month, we sold more than a hundred copies - for those times it was a landmark number! Even sales of Lingvo, which was already very popular at that time and cost several times less, rarely reached 100 copies per month.
Of course, we still had a lot of work to bring the program to the highest level. And, by the way, the competition with one of the Russian companies helped us in this. As a result, in the heat of hot competition, we created a product that turned out to be better than many foreign analogues.
The release of the second version of FineReader was accompanied by another interesting story. FineReader 2.0 was a 32-bit application. We planned to release it in the spring of 1995, and were going to podgadat directly under the release of Windows 95 (earlier Microsoft announced that the new version of Windows will be released in April). The new Windows favorably differed from the old one; we understood that people would immediately upgrade and our sales would go uphill. But at the same time, we had a “spare airfield” in the form of a Win32s component - an addition to the 16-bit Windows 3.1x, which allowed us to run specially adapted 32-bit applications for it. But two problems arose at the same time: Microsoft moved the release of Windows 95 to August, and in Win32s version 1.2, an error with Unicode support was detected, due to which Russian letters were not displayed in the interface. We had to urgently get involved with Microsoft, which at the time was practically impossible - it was the largest monopolist in the software market, on which almost everything in the industry depended, and expect a reaction from it to the needs of a small company in distant Russia with a paltry Microsoft market would be insane.
But a miracle happened: the same problem happened to Autodesk, which was a strategic partner of Microsoft. As a result, we were combined with Autodesk into one case and singled out a special manager who corresponded with us. As a result, it was possible to agree that in version 1.3, which, however, came out simultaneously with Windows 95, this error was corrected. And before that, we found a workaround - the resulting version did not work correctly under Windows 95, but it worked for the time being in Windows 3.1x.
This is how FineReader 1.3 looked like:


In general, our risky undertaking with the release of a 32-bit boxed product has spoiled us a lot of blood. 16-bit Windows was still widespread, and Win32s was not stable. I remember how for almost a week we caught some terrible mistake in the depths of Win32s itself using the kernel debugger via the com port in command-line mode. Found a problem - something worked incorrectly in the system memory allocator, and could come up with a bypass. But the new FineReader shone on Windows 95, being a native application for it, and the 32-bit mode was very important for the OCR program, since it made it possible to significantly optimize work with big data in memory, which is typical for recognition tasks. This gave us a head start for many years ahead of our competitors and in many ways predetermined our success in the market for licensing recognition technology.
And here is FineReader 2.0:


The program was loaded from four floppy disks:

User's manual:

Of course, you are waiting for screenshots. Here is how the FineReader 3.0 interface looked:
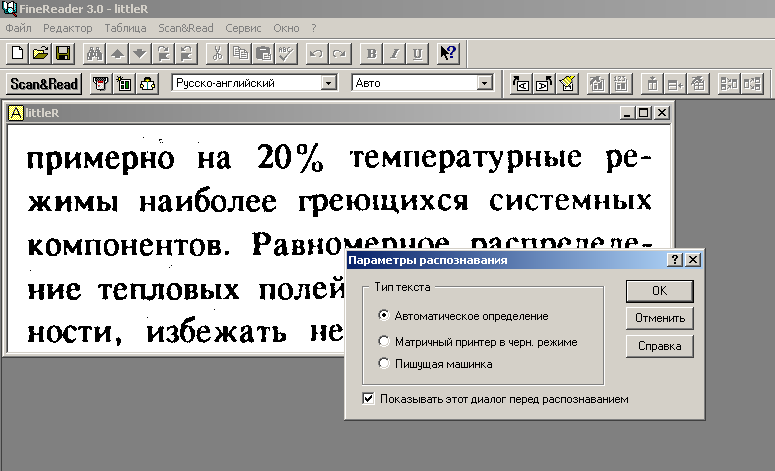
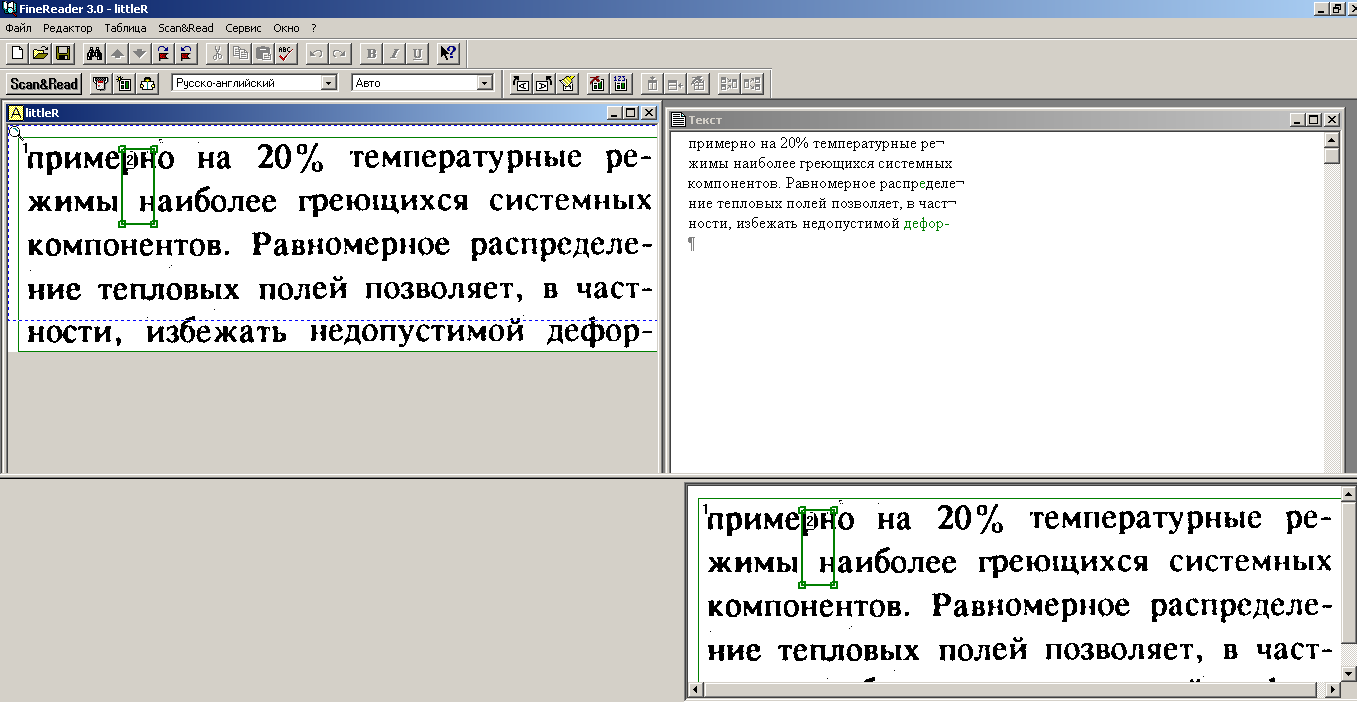
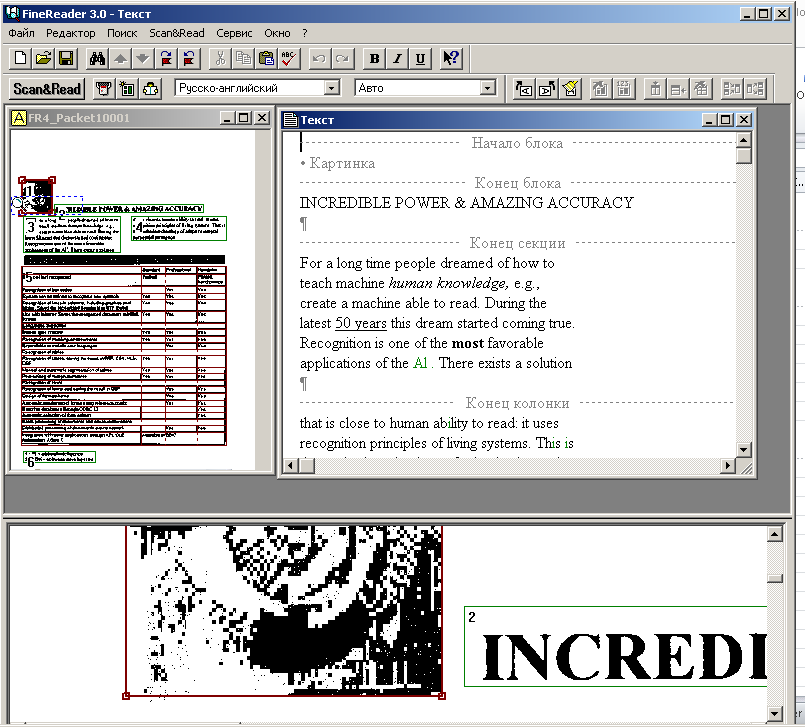
FineReader has become a landmark program for us. It was with him that we entered the international market. Today, this program is used by more than 20 million people in the world. And the text recognition technology underlying FineReader is licensed by the world's largest companies - Microsoft, Samsung, Fujitsu, Panasonic and many others.
Then, 22 years ago, we could not even guess where everything would go. And today we understand that we were able to achieve such an impressive result thanks to:
• Great and hard work. Yes, yes, from the last strength, but with a huge drive (remember about 12-14 hours a day without days off).
• Ability to find and create competitive advantages - the very multilingual and independence from the font.
• And courage. Now we understand how important it is not to be afraid of obstacles on the way.
Source: https://habr.com/ru/post/273219/
All Articles