HTML5 Mastery: Fragments
There are several types of DOM nodes, such as Document, Element, Text, and many others, which form a common Node. One of the most interesting nodes is the DocumentFragment, despite the fact that until now it has hardly been used. It is, for the most part, a special container for other nodes.
DocumentFragment is handled in most DOM algorithms in a special way. In this article, we will look at some of the API methods developed for use with DocumentFragment. We also learn that the concept of a node container plays an important role in other modern web technologies, such as the template element or the entire shadow DOM API. But before we begin, let's take a quick look at parsing fragments, which is not directly related to DocumentFragment.
The HTML5 parser can be used not only to analyze the whole document. It can also be used to parse parts of a document. To trigger fragment parsing, you need to set properties such as innerHTML or outerHTML. Fragment analysis is performed in the same way as regular parsing, with some exceptions. The most significant difference is the need for a contextual root.
The analyzed fragment is most likely to be placed as a child of some other element, which may or may not have additional parent elements. This information is extremely important for determining the current parsing mode, which depends on the current tree hierarchy. In addition, fragment parsing does not lead to script execution for security reasons.
')
Therefore, we can use code like the one below, but we will not get additional results. This will not execute the script.
Using fragment parsing is an easy way to reduce the number of DOM operations. Instead of creating, modifying and adding nodes, each of which involves context switching, and thus DOM operations, we work exclusively with building a string, which is then evaluated and processed by the parser. Thus, we have only one or two DOM operations. The disadvantage of this method is that we need a parser, and we need to do more work in JavaScript. The main question is this: What needs more time? Are various DOM operations more expensive than all the necessary JavaScript manipulations, or vice versa?
It is clear that everything depends on the situation. Regarding this scenario, Grgur Grisogono compared performance using several methods. It also depends on the browser, especially on how fast the JavaScript engine is. The higher the value - the more operations, and the more desirable such a result.
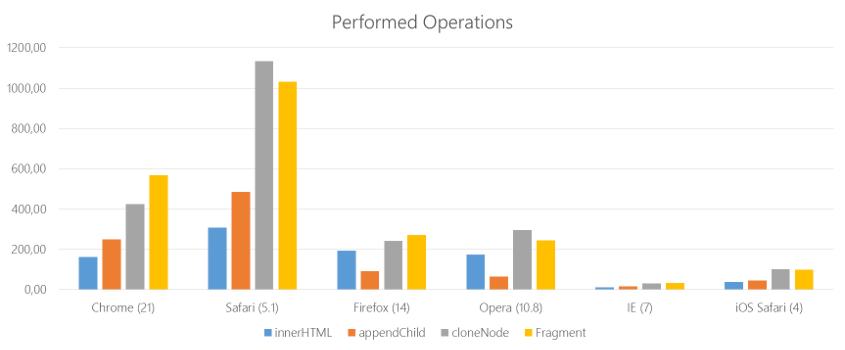
Although browsers are much faster today, relative behavior still matters. This should motivate us to look for optimal solutions and study DocumentFragment in more detail.
The meaning of the DocumentFragment node is quite simple: it is a container for Node objects. When a DocumentFragment is added, it expands to the extent that it only adds the contents of the container, not the container itself. When a complete copy of the DocumentFragment is requested, its content is also cloned. The container itself is never attached to another node, even if it must have an owner, which is the document from which the fragment was created.
Creating a DocumentFragment is as follows:
From this point of view, fragment behaves in the same way as any other parent DOM node. We can add, remove nodes, or access already existing nodes. There is an option to launch CSS queries using querySelector and querySelectorAll. Most importantly, as mentioned, we can clone a node with cloneNode ().
In essence, DocumentFragment cannot be built in pure HTML, since this concept can only be implemented through the DOM API. Therefore, containers can only be created in JavaScript. This greatly understates the benefits. We start by putting our template in a pseudo-element script. This element is a pseudo-element because the type attribute will be set to an invalid mime type. Thus, nothing will be executed, but the text content of the element will use different parsing rules.
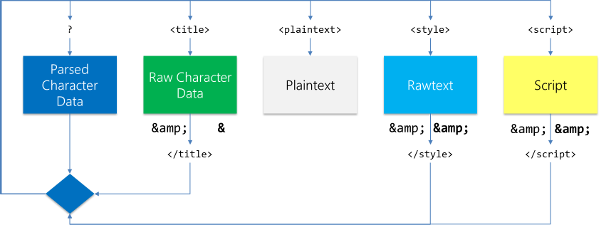
The above image shows tokenization states. For script tags, special parsing rules are used, since the parsing will be performed in a special tokenization state. In HTML, there are five tokenization states, but the fifth, Plaintext, is not particularly interesting.
The state of Rawtext is very similar to Script, and therefore we need to explain only three states.
Let's take an example. We use three elements that fairly well reflect each of the remaining states. The div element, like many others, is in parsed characters mode (PCData). textarea uses RCData like the title element. The Rawtext state is even more like free characters that can be represented using the style element. There are some minor differences between exiting Rawtext and Script. Therefore, in the following discussion, we will consider them the same.
Perhaps we could expect to get the same result, but, even realizing that there are differences, what will be the final result?
Only in the latter case, the input line is the same. That is, we have a winner. But here the fun begins. Most engines create a function from a string that takes a model and breaks it up for viewing into a list of generated DOM nodes.
Some may associate values in advance, depending on the model. The most important part is the generation of the node that is most focused on the string, at least during the first iteration.
W3C recognized the situation and responded by introducing the template element. The element can be recognized as a DocumentFragment media. Since DocumentFragment is not directly involved in the DOM tree, it is attached to the node through a property.
Using an element is quite simple, as the following example demonstrates:
In the DOM, we will not find a single child of this element. All child objects are attached to a nested DocumentFragment instance, which can be accessed through the content property.
Let's get these child elements:
The text is enclosed in braces, which reflects our intention to treat it as a stub. There is no system for automatic filling.
Let's create a function to return processed nodes. To do this, adjust the code to the previous example.
A generalization is possible by iterating all the attributes of elements and child nodes, replacing the text corresponding to a predefined structure in attributes and text nodes. And finally, the processed nodes can be added somewhere:
There are three important aspects of the template element:
Finally, DocumentFragment is so useful that it can even be used to make small parts of sites reusable and more flexible.
Recently, the demand for web components has increased significantly. Most front-end frameworks attempt to replicate their structure. However, you still need to have real support for DOM, even though you can use polyfills.
Shadow DOM allows us to add a DocumentFragment to any Element. There are three limitations:
These restrictions have consequences.
One of the consequences of the ShadowRoot application for an element is that the element is not displayed, the contents of the root element of the shadow tree are displayed instead. Content has a special purpose, which means that it can follow its own design rules.
Also, the entire event handling process will be slightly different. As a result, another new concept appears: slots. We can define slots in our shadow DOM that are filled with nodes from the element containing ShadowRoot. It seems obvious that creating custom elements that contain a shadow DOM is a good idea. The entire specification of custom elements is a reaction to this.
So how can we use a shadow DOM? To understand the API, run some JavaScript. Let's start with the following HTML fragment:
At this point, everything behaves as usual. Here we need JavaScript skills:
At this stage, we have achieved little. We started with a few elements and returned to them. An effectively composed DOM tree looks like this:
By default, all nodes of our shadow root are assigned a standard slot, if there is one. The default slot has no name property. So what have we achieved? We integrated several transparent elements. But, more importantly, to change the structure, attributes, or layout of our DOM tree, you don’t have to change our original markup. We only need to change which elements will be added to the shadow root, and that's it. We broke the front-end into modules.
Now you might think that we already had similar techniques on the server. And of course, some client frameworks also tried to generalize the code in a similar way. However, there are some major differences.
First, we have full browser support.
Secondly, the sandbox simplifies the drawing of this module by special rules - no overlaps with existing CSS rules. This ensures that the module will work on every page. No more debugging in a search where the CSS rules interfere with each other. And finally, we have a more accurate code. It is easy to generate and transfer, and we can expect more performance.
DocumentFragment is an efficient helper that has the ability to significantly reduce the number of DOM operations. It is also an important cornerstone of modern technology, especially in the field of web components. It has already led to the emergence of two outstanding technologies: the template element and ShadowRoot. While the former greatly simplifies the creation of templates, allowing for good performance improvements and easy transfer of pre-generated nodes, the latter is the basis of the components.
Is the real virtual DOM faster? Of course, but it may not be so fast if you do not use DocumentFragment to summarize multiple operations.
DocumentFragment is handled in most DOM algorithms in a special way. In this article, we will look at some of the API methods developed for use with DocumentFragment. We also learn that the concept of a node container plays an important role in other modern web technologies, such as the template element or the entire shadow DOM API. But before we begin, let's take a quick look at parsing fragments, which is not directly related to DocumentFragment.
Fragment parsing
The HTML5 parser can be used not only to analyze the whole document. It can also be used to parse parts of a document. To trigger fragment parsing, you need to set properties such as innerHTML or outerHTML. Fragment analysis is performed in the same way as regular parsing, with some exceptions. The most significant difference is the need for a contextual root.
The analyzed fragment is most likely to be placed as a child of some other element, which may or may not have additional parent elements. This information is extremely important for determining the current parsing mode, which depends on the current tree hierarchy. In addition, fragment parsing does not lead to script execution for security reasons.
')
Therefore, we can use code like the one below, but we will not get additional results. This will not execute the script.
var foo = document.querySelector('#foo'); foo.innerHTML = '<b>Hallo World!</b><script>alert("Hi.");</script>'; Using fragment parsing is an easy way to reduce the number of DOM operations. Instead of creating, modifying and adding nodes, each of which involves context switching, and thus DOM operations, we work exclusively with building a string, which is then evaluated and processed by the parser. Thus, we have only one or two DOM operations. The disadvantage of this method is that we need a parser, and we need to do more work in JavaScript. The main question is this: What needs more time? Are various DOM operations more expensive than all the necessary JavaScript manipulations, or vice versa?
It is clear that everything depends on the situation. Regarding this scenario, Grgur Grisogono compared performance using several methods. It also depends on the browser, especially on how fast the JavaScript engine is. The higher the value - the more operations, and the more desirable such a result.
Although browsers are much faster today, relative behavior still matters. This should motivate us to look for optimal solutions and study DocumentFragment in more detail.
Generalized DOM operations
The meaning of the DocumentFragment node is quite simple: it is a container for Node objects. When a DocumentFragment is added, it expands to the extent that it only adds the contents of the container, not the container itself. When a complete copy of the DocumentFragment is requested, its content is also cloned. The container itself is never attached to another node, even if it must have an owner, which is the document from which the fragment was created.
Creating a DocumentFragment is as follows:
var fragment = document.createDocumentFragment(); From this point of view, fragment behaves in the same way as any other parent DOM node. We can add, remove nodes, or access already existing nodes. There is an option to launch CSS queries using querySelector and querySelectorAll. Most importantly, as mentioned, we can clone a node with cloneNode ().
Creating HTML Templates
In essence, DocumentFragment cannot be built in pure HTML, since this concept can only be implemented through the DOM API. Therefore, containers can only be created in JavaScript. This greatly understates the benefits. We start by putting our template in a pseudo-element script. This element is a pseudo-element because the type attribute will be set to an invalid mime type. Thus, nothing will be executed, but the text content of the element will use different parsing rules.
The above image shows tokenization states. For script tags, special parsing rules are used, since the parsing will be performed in a special tokenization state. In HTML, there are five tokenization states, but the fifth, Plaintext, is not particularly interesting.
The state of Rawtext is very similar to Script, and therefore we need to explain only three states.
Let's take an example. We use three elements that fairly well reflect each of the remaining states. The div element, like many others, is in parsed characters mode (PCData). textarea uses RCData like the title element. The Rawtext state is even more like free characters that can be represented using the style element. There are some minor differences between exiting Rawtext and Script. Therefore, in the following discussion, we will consider them the same.
var example = '<br>me & you > them'; var types = ["div", "textarea", "script"]; types.forEach(function (type) { var foo = document.createElement(type); foo.innerHTML = example; console.log(foo.innerHTML); }) Perhaps we could expect to get the same result, but, even realizing that there are differences, what will be the final result?
<br>me & you > them <br>me & you > them <br>me & you > them Only in the latter case, the input line is the same. That is, we have a winner. But here the fun begins. Most engines create a function from a string that takes a model and breaks it up for viewing into a list of generated DOM nodes.
Some may associate values in advance, depending on the model. The most important part is the generation of the node that is most focused on the string, at least during the first iteration.
W3C recognized the situation and responded by introducing the template element. The element can be recognized as a DocumentFragment media. Since DocumentFragment is not directly involved in the DOM tree, it is attached to the node through a property.
Using an element is quite simple, as the following example demonstrates:
<template> <img src="{src}" alt="{alt}"> <div class="comment">{comment}</div> </template> In the DOM, we will not find a single child of this element. All child objects are attached to a nested DocumentFragment instance, which can be accessed through the content property.
Let's get these child elements:
var fragment = document.querySelector('template').content; var img = fragment.querySelector('img'); var comments = fragment.querySelectorAll('.comment'); The text is enclosed in braces, which reflects our intention to treat it as a stub. There is no system for automatic filling.
Let's create a function to return processed nodes. To do this, adjust the code to the previous example.
function createNodes (model) { var fragment = document.querySelector('template').content; var instance = fragment.clone(true);//deep cloning! var img = instance.querySelector('img'); img.setAttribute('src', model.src); img.setAttribute('alt', model.alt); var div = instance.querySelector('div'); div.textContent = model.comment; return instance; } A generalization is possible by iterating all the attributes of elements and child nodes, replacing the text corresponding to a predefined structure in attributes and text nodes. And finally, the processed nodes can be added somewhere:
var nodes = createNodes({ src: 'image.png', alt: 'Image', comment: 'Great!' }); document.querySelector('#comments').appendChild(nodes); There are three important aspects of the template element:
- It calls a different parsing mode. Therefore, it is more than just an element.
- Its child element will not be appended to the DOM, but a DocumentFragment will be available through content.
- We need to make an exact copy of the fragment before using it.
Finally, DocumentFragment is so useful that it can even be used to make small parts of sites reusable and more flexible.
Shadow DOM
Recently, the demand for web components has increased significantly. Most front-end frameworks attempt to replicate their structure. However, you still need to have real support for DOM, even though you can use polyfills.
Shadow DOM allows us to add a DocumentFragment to any Element. There are three limitations:
- The DocumentFragment must be specific - it must be a ShadowRoot.
- Each Element can contain only one ShadowRoot, or none.
- The contents of the ShadowRoot should be separated from the original DOM.
These restrictions have consequences.
One of the consequences of the ShadowRoot application for an element is that the element is not displayed, the contents of the root element of the shadow tree are displayed instead. Content has a special purpose, which means that it can follow its own design rules.
Also, the entire event handling process will be slightly different. As a result, another new concept appears: slots. We can define slots in our shadow DOM that are filled with nodes from the element containing ShadowRoot. It seems obvious that creating custom elements that contain a shadow DOM is a good idea. The entire specification of custom elements is a reaction to this.
So how can we use a shadow DOM? To understand the API, run some JavaScript. Let's start with the following HTML fragment:
<div id="#shadow-dialog"> <span slot="header"> My header title </span> <div slot="content"> <strong>Some very important content</strong> </div> </div> At this point, everything behaves as usual. Here we need JavaScript skills:
var context = document.querySelector('#shadow-dialog'); var root = context.attachShadow({ mode: 'open' }); var headerSlot = document.createElement('slot'); headerSlot.name = 'header'; root.appendChild(headerSlot); var contentSlot = document.createElement('slot'); contentSlot.name = 'content'; root.appendChild(contentSlot); At this stage, we have achieved little. We started with a few elements and returned to them. An effectively composed DOM tree looks like this:
<div id="#shadow-dialog"> <slot name="header"> <span slot="header"> My header title </span> </slot> <slot name="content"> <div slot="content"> <strong>Some very important content</strong> </div> </slot> </div> By default, all nodes of our shadow root are assigned a standard slot, if there is one. The default slot has no name property. So what have we achieved? We integrated several transparent elements. But, more importantly, to change the structure, attributes, or layout of our DOM tree, you don’t have to change our original markup. We only need to change which elements will be added to the shadow root, and that's it. We broke the front-end into modules.
Now you might think that we already had similar techniques on the server. And of course, some client frameworks also tried to generalize the code in a similar way. However, there are some major differences.
First, we have full browser support.
Secondly, the sandbox simplifies the drawing of this module by special rules - no overlaps with existing CSS rules. This ensures that the module will work on every page. No more debugging in a search where the CSS rules interfere with each other. And finally, we have a more accurate code. It is easy to generate and transfer, and we can expect more performance.
Conclusion
DocumentFragment is an efficient helper that has the ability to significantly reduce the number of DOM operations. It is also an important cornerstone of modern technology, especially in the field of web components. It has already led to the emergence of two outstanding technologies: the template element and ShadowRoot. While the former greatly simplifies the creation of templates, allowing for good performance improvements and easy transfer of pre-generated nodes, the latter is the basis of the components.
Is the real virtual DOM faster? Of course, but it may not be so fast if you do not use DocumentFragment to summarize multiple operations.
Paysto payment solutions for Habr readers:
→ Get paid by credit card right now. Without a site, PI and LLC.
→ Accept payments from companies via the Internet. Without a site, PI and LLC.
→ Acceptance of payments from companies for your site. With document circulation and exchange of originals.
→ Automation of sales and service transactions with legal entities. Without intermediary in the calculations.
→ Accept payments from companies via the Internet. Without a site, PI and LLC.
→ Acceptance of payments from companies for your site. With document circulation and exchange of originals.
→ Automation of sales and service transactions with legal entities. Without intermediary in the calculations.
Source: https://habr.com/ru/post/273217/
All Articles