XML, XQuery and Triple Grief with Performance
A trip to Dnepropetrovsk to meet the Dnepr SQL User Group , a chronic lack of sleep over the last couple of days, but a nice bonus upon arrival in Kharkov ... Winter weather, which motivates you to write something interesting ...
It has long been in the plans to tell about the "pitfalls" when working with XML and XQuery , which can lead to tricky performance problems.
For those who frequently use SQL Server , XQuery and like to parse values from XML, it is recommended to read the following material ...
To begin with, we will generate test XML on which we will conduct experiments:
')
For those who have xp_cmdshell disabled, do the following:
As a result, we will create a file with the following structure along the specified path:
Now we start the fence experiments ...
What is the most efficient way to load data from XML ? Probably, it is not necessary to open the file with a notepad, copy the contents and paste into a variable ... I think that it would be more correct to use OPENROWSET :
But there is a funny trick. As it turned out, the combination of loading and parsing of values from XML can lead to a significant decrease in performance. Suppose we need to get obj_id values from a previously created file:
On my machine, this query takes a very long time:
Let's try to separate the loading and parsing:
Everything worked very quickly:
So what was the problem? Let's analyze the execution plan:

As it turned out, the problem lies in the type conversion, so try to initially pass a parameter in the XML type to the nodes function.
Next, we consider a typical situation when you need to perform filtering during parsing ... In such cases, you need to remember that SQL Server does not optimize the function calls for working with XML .
For clarity, I will show that in this query, the value function will be executed twice:

This nuance may reduce performance, so it is recommended to reduce the function calls:

Alternatively, you can filter more like this:
but there is no significant gain. Although QueryCost suggests otherwise:
It is shown that the third option is the most optimal ... Let it be another argument not to trust QueryCost , which is just an internal assessment.
And the most interesting example for a snack ... There is another VERY important feature when parsing from XML . Run the query:
and look at the execution time, which can only suit those who are not in a hurry:
Why is this happening? SQL Server has problems with reading parent nodes from children (if it is easier to say, SQL Server is hard to “look back”):

How can we be in such a case? It's very simple ... start reading from the parent nodes and read the children using CROSS / OUTER APPLY :
It is also interesting to consider the situation when we need to look at level 2 above. The problem with reading the parent element I have not reproduced:
I also wanted to mention one interesting feature. Problems with reading parent elements OPENXML does not have:
But now you don’t need to think that OPENXML has distinct advantages over XQuery . OPENXML also has enough jambs. For example, if we forget to call sp_xml_removedocument , then there may be severe memory leaks.
Everything was tested on SQL Server 2012 SP3 (11.00.6020) .
If you want to share this article with an English-speaking audience:
XML, XQuery & Performance Issues
It has long been in the plans to tell about the "pitfalls" when working with XML and XQuery , which can lead to tricky performance problems.
For those who frequently use SQL Server , XQuery and like to parse values from XML, it is recommended to read the following material ...
To begin with, we will generate test XML on which we will conduct experiments:
')
USE AdventureWorks2012 GO IF OBJECT_ID('tempdb.dbo.##temp') IS NOT NULL DROP TABLE ##temp GO SELECT val = ( SELECT [@obj_id] = o.[object_id] , [@obj_name] = o.name , [@sch_name] = s.name , ( SELECT i.name, i.column_id, i.user_type_id, i.is_nullable, i.is_identity FROM sys.all_columns i WHERE i.[object_id] = o.[object_id] FOR XML AUTO, TYPE ) FROM sys.all_objects o JOIN sys.schemas s ON o.[schema_id] = s.[schema_id] WHERE o.[type] IN ('U', 'V') FOR XML PATH('obj'), ROOT('objects') ) INTO ##temp DECLARE @sql NVARCHAR(4000) = 'bcp "SELECT * FROM ##temp" queryout "D:\sample.xml" -S ' + @@servername + ' -T -w -r -t' EXEC sys.xp_cmdshell @sql IF OBJECT_ID('tempdb.dbo.##temp') IS NOT NULL DROP TABLE ##temp For those who have xp_cmdshell disabled, do the following:
EXEC sp_configure 'show advanced options', 1 GO RECONFIGURE GO EXEC sp_configure 'xp_cmdshell', 1 GO RECONFIGURE GO As a result, we will create a file with the following structure along the specified path:
<objects> <obj obj_id="245575913" obj_name="DatabaseLog" sch_name="dbo"> <i name="DatabaseLogID" column_id="1" user_type_id="56" is_nullable="0" is_identity="1" /> <i name="PostTime" column_id="2" user_type_id="61" is_nullable="0" is_identity="0" /> <i name="DatabaseUser" column_id="3" user_type_id="256" is_nullable="0" is_identity="0" /> <i name="Event" column_id="4" user_type_id="256" is_nullable="0" is_identity="0" /> <i name="Schema" column_id="5" user_type_id="256" is_nullable="1" is_identity="0" /> <i name="Object" column_id="6" user_type_id="256" is_nullable="1" is_identity="0" /> <i name="TSQL" column_id="7" user_type_id="231" is_nullable="0" is_identity="0" /> <i name="XmlEvent" column_id="8" user_type_id="241" is_nullable="0" is_identity="0" /> </obj> ... <obj obj_id="1237579447" obj_name="Employee" sch_name="HumanResources"> <i name="BusinessEntityID" column_id="1" user_type_id="56" is_nullable="0" is_identity="0" /> <i name="NationalIDNumber" column_id="2" user_type_id="231" is_nullable="0" is_identity="0" /> <i name="LoginID" column_id="3" user_type_id="231" is_nullable="0" is_identity="0" /> <i name="OrganizationNode" column_id="4" user_type_id="128" is_nullable="1" is_identity="0" /> <i name="OrganizationLevel" column_id="5" user_type_id="52" is_nullable="1" is_identity="0" /> <i name="JobTitle" column_id="6" user_type_id="231" is_nullable="0" is_identity="0" /> <i name="BirthDate" column_id="7" user_type_id="40" is_nullable="0" is_identity="0" /> ... </obj> ... </objects> Now we start the fence experiments ...
What is the most efficient way to load data from XML ? Probably, it is not necessary to open the file with a notepad, copy the contents and paste into a variable ... I think that it would be more correct to use OPENROWSET :
DECLARE @xml XML SELECT @xml = BulkColumn FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x SELECT @xml But there is a funny trick. As it turned out, the combination of loading and parsing of values from XML can lead to a significant decrease in performance. Suppose we need to get obj_id values from a previously created file:
;WITH cte AS ( SELECT x = CAST(BulkColumn AS XML) FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x ) SELECT tcvalue('@obj_id', 'INT') FROM cte CROSS APPLY x.nodes('objects/obj') t(c) On my machine, this query takes a very long time:
(495 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 20788, ..., lob logical reads 7817781, ..., lob read-ahead reads 1022368. SQL Server Execution Times: CPU time = 53688 ms, elapsed time = 53911 ms. Let's try to separate the loading and parsing:
DECLARE @xml XML SELECT @xml = BulkColumn FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x SELECT tcvalue('@obj_id', 'INT') FROM @xml.nodes('objects/obj') t(c) Everything worked very quickly:
(1 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 7, ..., lob logical reads 2691, ..., lob read-ahead reads 344. SQL Server Execution Times: CPU time = 15 ms, elapsed time = 51 ms. (495 row(s) affected) SQL Server Execution Times: CPU time = 47 ms, elapsed time = 125 ms. So what was the problem? Let's analyze the execution plan:
As it turned out, the problem lies in the type conversion, so try to initially pass a parameter in the XML type to the nodes function.
Next, we consider a typical situation when you need to perform filtering during parsing ... In such cases, you need to remember that SQL Server does not optimize the function calls for working with XML .
For clarity, I will show that in this query, the value function will be executed twice:
SELECT tcvalue('@obj_id', 'INT') FROM @xml.nodes('objects/obj') t(c) WHERE tcvalue('@obj_id', 'INT') < 0 (404 row(s) affected) SQL Server Execution Times: CPU time = 116 ms, elapsed time = 120 ms. This nuance may reduce performance, so it is recommended to reduce the function calls:
SELECT * FROM ( SELECT id = tcvalue('@obj_id', 'INT') FROM @xml.nodes('objects/obj') t(c) ) t WHERE t.id < 0 (404 row(s) affected) SQL Server Execution Times: CPU time = 62 ms, elapsed time = 74 ms. Alternatively, you can filter more like this:
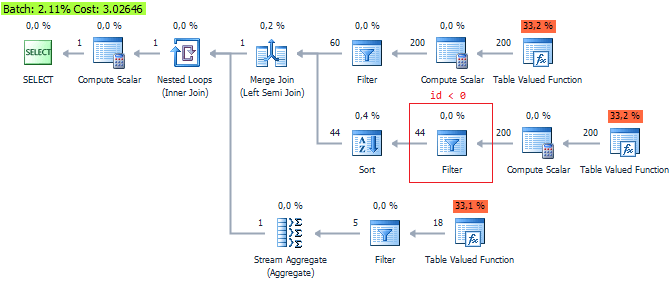
SELECT tcvalue('@obj_id', 'INT') FROM @xml.nodes('objects/obj[@obj_id < 0]') t(c) (404 row(s) affected) SQL Server Execution Times: CPU time = 110 ms, elapsed time = 119 ms. but there is no significant gain. Although QueryCost suggests otherwise:
It is shown that the third option is the most optimal ... Let it be another argument not to trust QueryCost , which is just an internal assessment.
And the most interesting example for a snack ... There is another VERY important feature when parsing from XML . Run the query:
SELECT tcvalue('../@obj_name', 'SYSNAME') , tcvalue('@name', 'SYSNAME') FROM @xml.nodes('objects/obj/*') t(c) and look at the execution time, which can only suit those who are not in a hurry:
(5273 row(s) affected) SQL Server Execution Times: CPU time = 66578 ms, elapsed time = 66714 ms. Why is this happening? SQL Server has problems with reading parent nodes from children (if it is easier to say, SQL Server is hard to “look back”):
How can we be in such a case? It's very simple ... start reading from the parent nodes and read the children using CROSS / OUTER APPLY :
SELECT tcvalue('@obj_name', 'SYSNAME') , t2.c2.value('@name', 'SYSNAME') FROM @xml.nodes('objects/obj') t(c) CROSS APPLY tcnodes('*') t2(c2) (5273 row(s) affected) SQL Server Execution Times: CPU time = 156 ms, elapsed time = 184 ms. It is also interesting to consider the situation when we need to look at level 2 above. The problem with reading the parent element I have not reproduced:
USE AdventureWorks2012 GO DECLARE @xml XML SELECT @xml = ( SELECT [@obj_name] = o.name , [columns] = ( SELECT i.name FROM sys.all_columns i WHERE i.[object_id] = o.[object_id] FOR XML AUTO, TYPE ) FROM sys.all_objects o WHERE o.[type] IN ('U', 'V') FOR XML PATH('obj') ) SELECT tcvalue('../../@obj_name', 'SYSNAME') , tcvalue('@name', 'SYSNAME') FROM @xml.nodes('obj/columns/*') t(c) I also wanted to mention one interesting feature. Problems with reading parent elements OPENXML does not have:
DECLARE @xml XML , @idoc INT SELECT @xml = BulkColumn FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x EXEC sys.sp_xml_preparedocument @idoc OUTPUT, @xml SELECT * FROM OPENXML(@idoc, '/objects/obj/*') WITH ( name SYSNAME '../@obj_name', col SYSNAME '@name' ) EXEC sys.sp_xml_removedocument @idoc (5273 row(s) affected) SQL Server Execution Times: CPU time = 47 ms, elapsed time = 137 ms. But now you don’t need to think that OPENXML has distinct advantages over XQuery . OPENXML also has enough jambs. For example, if we forget to call sp_xml_removedocument , then there may be severe memory leaks.
Everything was tested on SQL Server 2012 SP3 (11.00.6020) .
If you want to share this article with an English-speaking audience:
XML, XQuery & Performance Issues
Source: https://habr.com/ru/post/273189/
All Articles