Big educational program: distributed data storage systems in practical binding for administrators of medium and large businesses
Modern networks and data centers are striding briskly to the full and total program-defined scheme, when in fact it doesn't matter what hardware you cram inside, everything will be on software. For mobile operators, this began with the fact that they did not want to install 20 antennas per house (their nodes are reconfigured, change frequencies and parameters simply by updating the config), and in data centers, first with server virtualization, which is now masthead, and then continued and storage virtualization.
But back to Russia in 2015. Below, I will show you how to save money, increase reliability and solve a number of typical tasks for sysadmins of medium and large business how to use “from improvised means” (x86 machines and any “stores”).
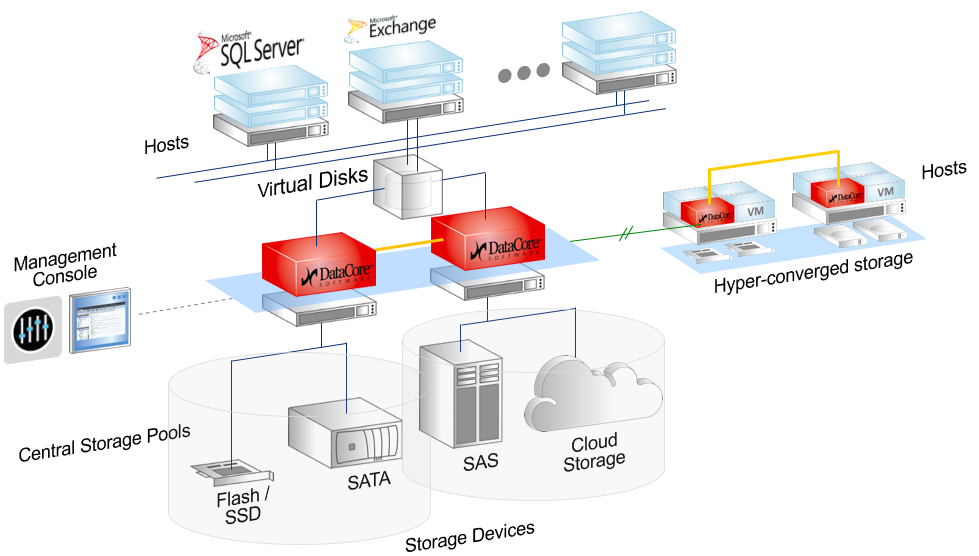
In this diagram, both architectures are visible, which will be discussed. SDS - two red controllers in the center with any backend, from internal disks to FC shelves and clouds. And virtual SAN, on the Hyper-converged storage scheme.
')
The most important thing:
At the same time we consider a couple of typical tasks with specific hardware and prices.
In fact, SDS-software for data storage creates a management server (or cluster) in which different types of storage are connected: disk shelves, disks and RAM of servers (as a cache), PCI-SSD, SSD shelves, as well as individual "cabinets" storage systems of different types and models from different vendors and with different disks and connection protocols.

From this point on, this whole space becomes common. But at the same time, the software understands that the “fast” data should be stored there, and the slow archive data should be stored there in general. You as a sysadmin, roughly speaking, stop thinking in terms of the “RAID group on storage” category, and you start thinking with such concepts as “there is a data set, you need to place them in the FAST profile”. Of course, agreeing with the master or predestined that this profile is FAST on such and such disks of such a data storage system.
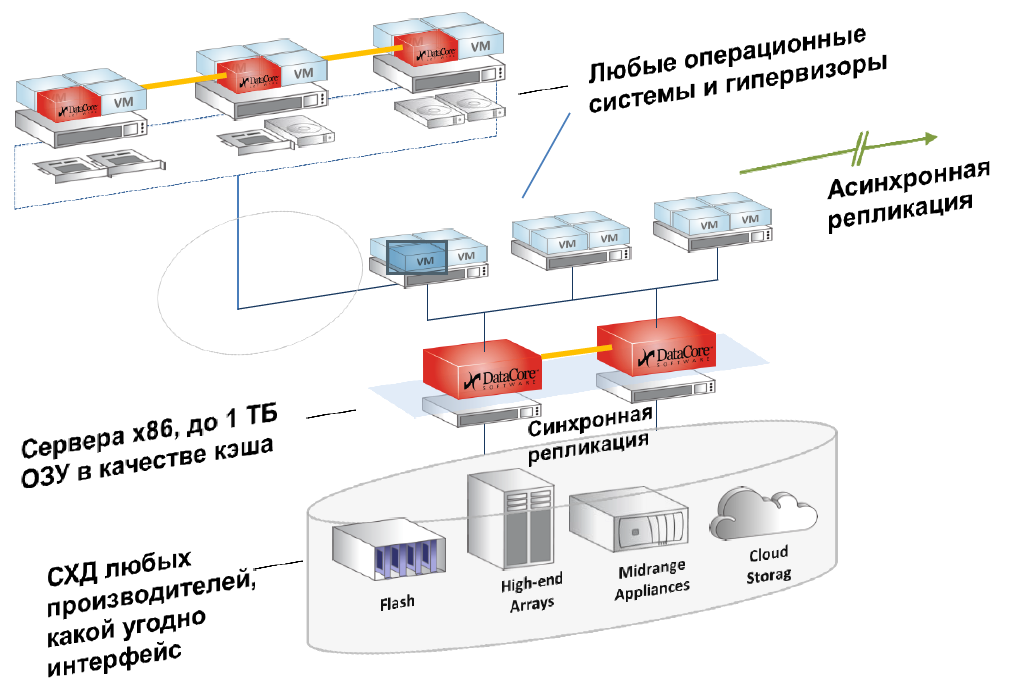
The same software uses RAM servers (virtual storage controllers) as a cache. That is, the usual x86 RAM, up to 1TB in size, cache and reads and writes, plus there are buns like preventive reading, grouping blocks, multithreading and really interesting Random Wrire Accelerator (but more on that below).
The most frequent applications are:
The difference between software-defined infrastructures and the usual “static” ones is about the same as what happened between the good old electrical circuits on lamps and the “new” ones on transistors. That is very, very significant, but at first it is quite difficult to master it. We need new approaches and a new understanding of architecture.
I note that there is nothing directly fundamentally new in the very concept of Software-defined, and the basic principles were applied 15 years ago at least back. It was simply called differently and was found far from everywhere.
In this post, we discuss SDS (Software Defined Storage), only about storage, disk arrays and other storage devices, as well as their interfaces.
I will talk about technology based on DataCore software. This is not the only vendor, but it covers almost all the tasks of data warehousing virtualization completely.
Here are a few other vendors that solve data storage tasks on software-defined architectures:
• EMC with their ScaleIO allows you to combine any number of x86 servers with disk shelves into a single fast storage. Here is a theory , but the practice of a fault-tolerant system for domestic not the most reliable servers.
• Domestic RAIDIX . That's about them and their mushrooms .
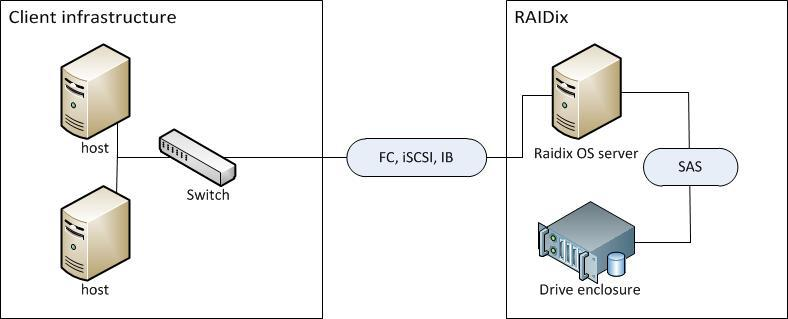
Their architecture replaces for a number of specific tasks such as video editing for 10–20 thousand dollars with a storage system costing 80–100 thousand
• Riverbed has a cool solution, with the help of which we connected all the branches of the bank in the Moscow storage system so they saw it in their city LAN-network and made a quasi-synchronous replication through the cache.
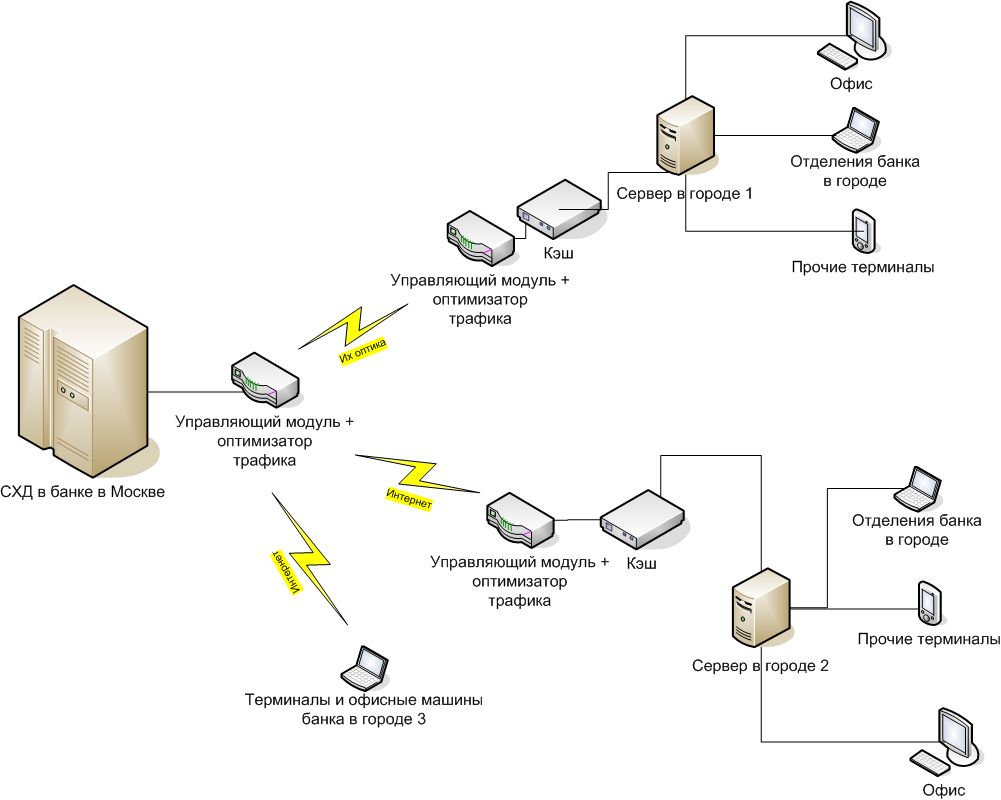
Servers in cities 1 and 2 are addressed to storage systems in Moscow as to their “in-box” disks with LAN speeds. If necessary, you can work directly (case 3, disaster recovery office), but this already means the usual signal delays from the city to Moscow and back.
• In addition, Citrix and some other vendors have similar solutions, but, as a rule, they are more focused on the company's own products.
• Nutanix solves the problems of hyper storages, but it is often expensive because they make a hardware-software complex, and there the software is separated from the iron only on very, very large volumes.
• RED HAT offers CEPH or Gluster products, but these seemingly red-eyed guys at first glance supported the sanctions.
I have the most experience with DataCore , so I ask you to forgive in advance (and add) if I accidentally bypass someone’s cool features.
Actually, what you need to know about this company: Americans (but did not join the sanctions, because they were not even placed on the stock exchange), have been on the market for 18 years, all this time they are sawing under the guidance of the same peasant as at the very beginning, product - software for building storage - SANsymphony-V, which I will continue to call SSV for short. Since their chief is an engineer, they sabotaged the technology, but did not even think about marketing. As a result, nobody knew them as such until the last year, and they earned their money by embedding their technologies into foreign partner solutions not under their own brand.
SSV is a software repository. From the consumer (host) side, the SSV looks like a regular storage system; in fact, it looks like a disk stuck directly into the server. In our case, in practice, this is usually a virtual multiport disk, two physical copies of which are available through two different DataCore nodes.
From here, the first basic function of SSV, synchronous replication, follows, and most of the actual DataCore LUNs used are fault tolerant disks.
The software can be placed on any x86 server (almost), almost any block devices can be used as resources: external storage systems (FC, iSCSI), internal disks (including PCI-SSD), DAS, JBOD, up to connected cloud storages. Almost - because there are requirements for the gland.
SSV virtual disks can be presented to any host (IBM i5 OS exception).
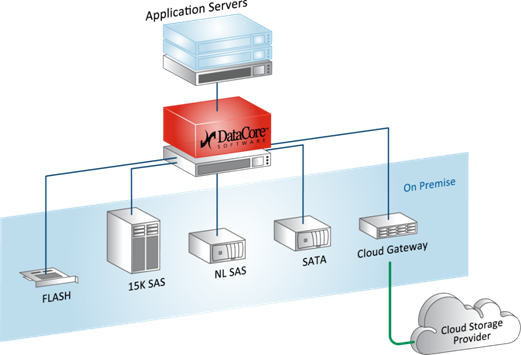
Simple application (virtualizer / FC / iSCSI target):
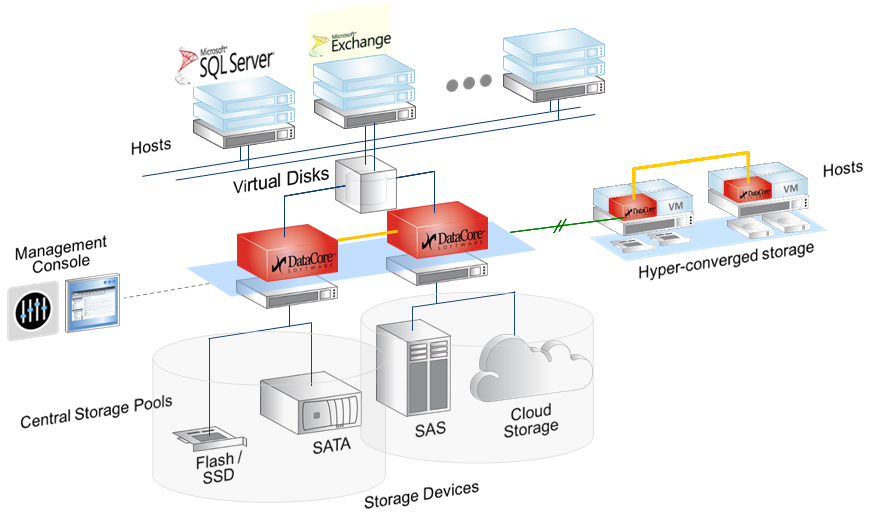
And more interesting:
SSV has a whole range of functions - caching, load balancing, Auto-Tiering and Random Write Accelerator.
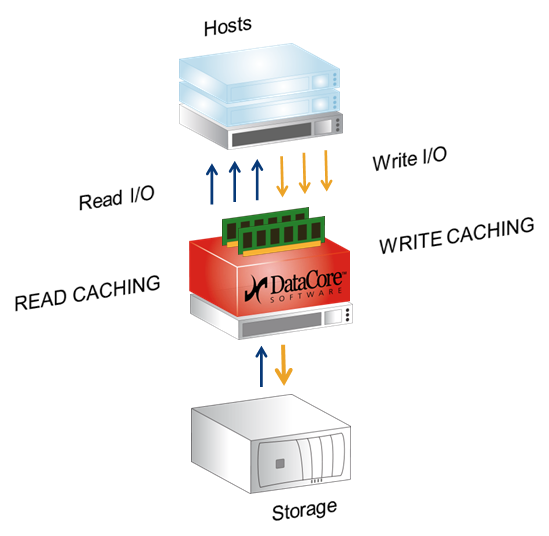
Let's start with caching. The cache here is the entire free RAM of the server on which DC is installed, works both for writing and reading, the maximum amount is 1Tb. The same ScaleIO and RAIDIX do not use RAM, but they load the disks of "their" servers or controllers. This provides a faster cache.
In this DC-architecture, the bet is made on speed and reliability. In my opinion, for practical tasks of medium-sized businesses today we get the fastest and yet quite accessible cache.
In the same cache, on the basis of the RAM of the servers, the function of randomized write optimization works, for example, under the OLTP load.
The principle of the optimizer is very simple: the host uploads random data blocks (for example, SQL) to a virtual disk, they get into the cache (RAM), which is technologically able to write random blocks quickly by arranging these blocks in sequence. When a sufficient array of sequential data is typed, they are transferred to the disk subsystem.
Approximately here, read forwarding, block grouping, multithreading, block consolidation, protection from boot / login - storm, blender effect are done. If the management software understands what the host application does (for example, reads a VDI image according to the standard scheme), then the reading can be done before the host requests the data, because he read the same several times in the same situation. It is reasonable to put this in the cache at the moment when it becomes clear what exactly he is doing there.
Auto-Tiering is when any virtual disk is based on a pool in which a variety of media can be included - from PCI-SSD and FC storage to slow SATA and even external cloud storage. Each of the carriers is assigned a level from 0 to 14, and the software automatically redistributes the blocks between the carriers, depending on the frequency of access to the block. That is, archived data is placed on SATA and other slow carriers, and hot database fragments, for example, on SSD. Moreover, all available resources are automatically and optimally used; this is not manual file processing.
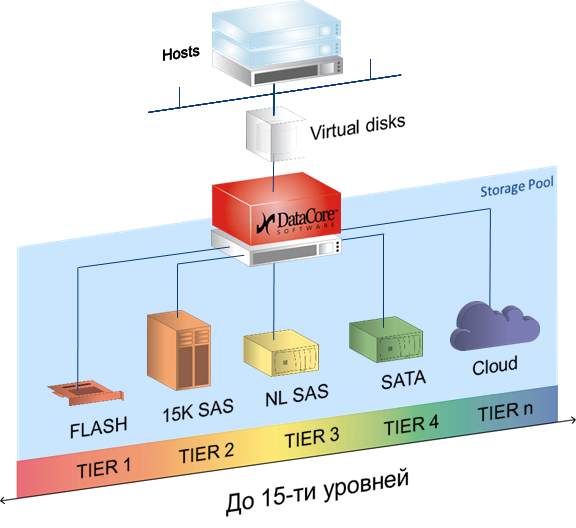
Evaluation of statistics and the subsequent movement of blocks occurs by default once every 30 seconds, but in case this does not create delays for current reading and writing tasks. Load balancing is present as an analogue of RAID 0 - striping between physical media in the disk pool, and also as an opportunity to fully use both cluster nodes (active-active) as the main one, which allows you to more efficiently load adapters and a SAN network.
Using SSV, you can, for example, organize a metrocluster between storage systems that do not support this feature or require additional expensive equipment for this. And at the same time not to lose (if there is a fast channel between the nodes), but to grow in performance and functionality, plus have a performance margin.
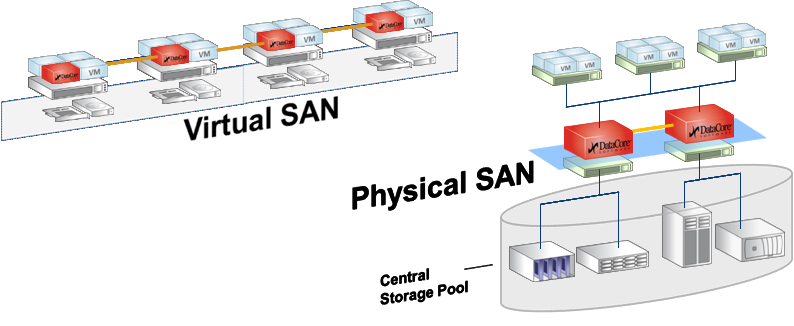
There are only two SSV architectures.
The first is SDS, software-defined storage. The classic “heavy” storage system is, for example, a physical rack, where there is a RISC server and an SSD factory (or HDD arrays). In addition, in fact, the price of disks, the cost of this rack is largely determined by the difference in architectures, which is very important for high reliability solutions (for example, banks). The difference in price between the x86th Chinese crafts and the similar in size storage system of the same EMC, HP or other vendor ranges from about two to a similar set of disks. Approximately half of this difference is in architecture.
So, of course, you can combine several x86 servers with disk shelves into one fast network and teach how to work as a cluster. For this there is a special software, for example EMC Vipr. Or you can build on the basis of a single x86-th server storage, scoring his discs to the eyeballs.
SDS is actually such a server. With the only difference that in 99% of cases in practice these will be 2 nodes, and on the back end there can be just about anything.
Technically, these are two x86 servers. They are Windows and DataCore SSV, between them are synchronization links (block) and control (IP). These servers are located between the host (consumer) and storage resources, for example - a bunch of shelves with disks. Restriction - there should be block access both there and there.
The most clear description of the architecture will be the block recording procedure. The virtual disk is presented to the host as an ordinary block device. The application writes a block to the disk, the block enters the RAM of the first node (1), then over the synchronization channel is recorded in the RAM of the second node (2), then recorded (3), recorded (4).
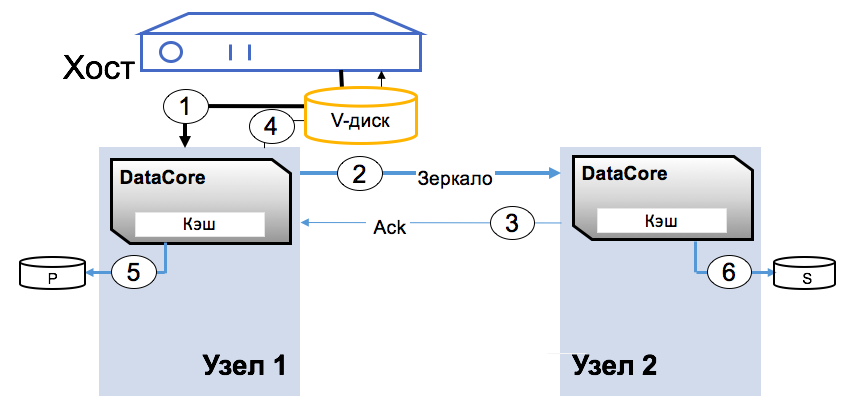
As soon as the block appears in two copies, the application receives a confirmation of the record. The configuration of the DC platform and backend depends only on the load requirements of the hosts. How correctly system performance is limited by the resources of adapters and SAN-network.
The second is Virtual SAN, that is, virtual storage. DC SSV is located in a virtual machine running Windows Server, DC is allocated storage resources connected to this host (hypervisor). It can be both internal disks and external storage systems, such nodes can be from 2 to 64 pieces in the current version. DC allows you to combine resources "under" all hypervisors and dynamically distribute this volume.
There are also two physical copies of each block, as in the previous architecture. In practice, these are most often internal server disks. The practice is to build a fault-tolerant mini-data center without using external storage: these are 2–5 nodes that can be added if necessary for new computing or storage resources. This is a particular example of the now fashionable idea of a hyperconvergent environment that is used by Google, Amazon and others.
Simply put, you can build an Enterprise environment, and you can take a bunch of not the most reliable and not the fastest x86-technology, drive cars with disks and fly to capture the world on a small price list.
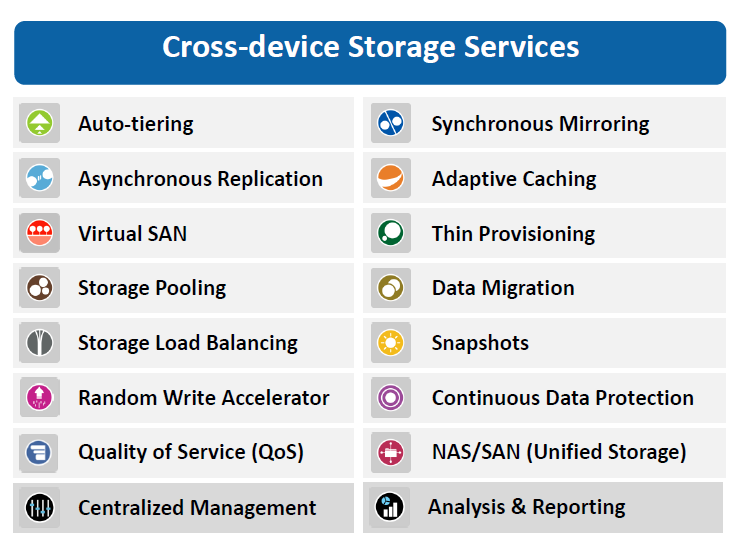
This is what the resulting system can do:
Task number 1. Build a virtual SAN. There are three virtualization servers located in the Data Center (2 servers) and the Backup Data Center (1 server).
Decision:
• Use existing hardware to create a virtualization subsystem.
• On the basis of the same equipment and internal server storage devices, create a virtual storage network with the function of synchronous replication of volumes using DataCore software.
A virtual server — a DataCore node — is deployed on each virtualization server, and virtual disks created on the local disk resources of the virtualization servers are additionally connected to the DataCore nodes. These disks are combined into pools of disk resources, on the basis of which mirror virtual disks are created. The disks are mirrored between the two DataCore Virtual SAN nodes - so the “original” disk is placed on the disk resource pool of one node, the “mirror copy” is placed on the second. Next, virtual disks are presented to virtualization servers (hypervisors) or virtual machines directly.
It turns out cheap and angry (colleagues suggest: a competitive solution for the price) and without additional iron. In addition to solving the immediate problem, the storage network gets a lot of useful additional functionality: increased performance, the ability to integrate with VMware, snapshots for the entire volume, and so on. With further growth, you only need to add virtual cluster nodes or update existing ones.
Here is the diagram:

Task number 2. Unified Storage System (NAS / SAN).
It all started with the Windows Failover cluster for the file server. The customer needed to make a file to store documents - with high availability and data backup and with almost instant data recovery. It was decided to build a cluster.
From the existing equipment, the customer had two Supermicro servers (one of which has SAS JBOD connected). There is more than enough disk space in two servers (about 10 TB per server), however, for the organization of a cluster, shared storage is required. It was also planned to have a backup of the data, since a single storage system is a single point of failure, preferably with a CDP covering the work week. The data must be available all the time, the maximum idle time is 30 minutes (and heads can fly). The standard solution included the purchase of storage, another server for backups.
Decision:
• DataCore software is installed on each server.
In DataCore architecture, Windows Failover Cluster can be deployed without using shared SAN storage (using internal server disks) or using DAS, JBOD or external storage systems with full implementation of DataCore Unified Storage (SAN & NAS) architecture, taking full advantage of Windows Server 2012 and NFS & SMB (CIFS) and providing SAN service to external hosts. Such an architecture was eventually deployed, and the disk space not used for a file server was not presented as a SAN for ESXi hosts.
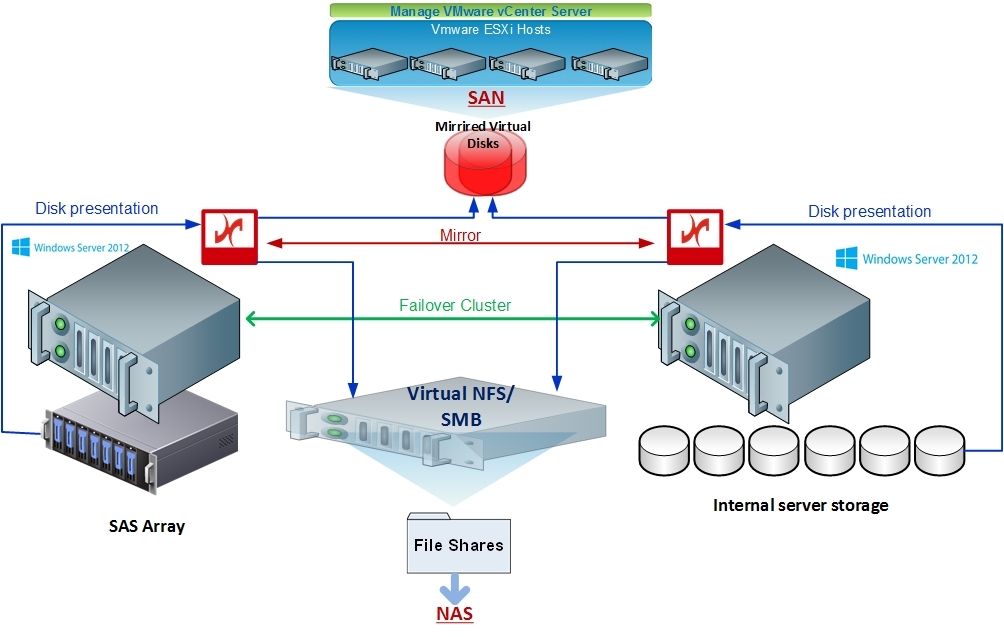
It turned out very cheap in comparison with traditional solutions, plus:
The basic principle of storage virtualization is, on the one hand, to hide the entire backend from the consumer, on the other hand, to provide any real competitive functionality to any backend.
But back to Russia in 2015. Below, I will show you how to save money, increase reliability and solve a number of typical tasks for sysadmins of medium and large business how to use “from improvised means” (x86 machines and any “stores”).
In this diagram, both architectures are visible, which will be discussed. SDS - two red controllers in the center with any backend, from internal disks to FC shelves and clouds. And virtual SAN, on the Hyper-converged storage scheme.
')
The most important thing:
- You don't care what hardware stands for: disks, SSD, manufacturers' zoo, old and new models ... - all this is given to the orchestrating software, and it leads to the virtual architecture that you need as a result. Roughly speaking, it combines into one volume or allows you to cut as you like.
- You don't care what interfaces these systems have. SDS is built on top.
- You do not care what functions your store could, and which could not (again, now they can do what they need: decides the software above).
At the same time we consider a couple of typical tasks with specific hardware and prices.
Who needs it and why?
In fact, SDS-software for data storage creates a management server (or cluster) in which different types of storage are connected: disk shelves, disks and RAM of servers (as a cache), PCI-SSD, SSD shelves, as well as individual "cabinets" storage systems of different types and models from different vendors and with different disks and connection protocols.
From this point on, this whole space becomes common. But at the same time, the software understands that the “fast” data should be stored there, and the slow archive data should be stored there in general. You as a sysadmin, roughly speaking, stop thinking in terms of the “RAID group on storage” category, and you start thinking with such concepts as “there is a data set, you need to place them in the FAST profile”. Of course, agreeing with the master or predestined that this profile is FAST on such and such disks of such a data storage system.
The same software uses RAM servers (virtual storage controllers) as a cache. That is, the usual x86 RAM, up to 1TB in size, cache and reads and writes, plus there are buns like preventive reading, grouping blocks, multithreading and really interesting Random Wrire Accelerator (but more on that below).
The most frequent applications are:
- When an inquisitive mind and / or sad experience led to the realization that honest synchronous replication between storage systems is indispensable.
- Banal lack of productivity and budget at the same time.
- Many storages have accumulated. A large park, or rather, a zoo: there is no single standard, the protocol changes, and sometimes there is a feeling that everything must be done from scratch. No need, enough virtualization. The same zoo, but on the hosts side (a bunch of different operating systems and two or even three different hypervisors). And the desire or more often the need to use both iSCSI and FC. Alternatively, when using a classic storage system - in this case, you can also use many operating systems.
- I want to use the old iron, so as not to throw it away. As a rule, even 8-year-old servers quite well cope with node roles — the RAM speed has not changed much since then, and there is no need for more, the bottleneck is usually the network.
- You have a lot of random entries or you need to write in many threads at once. A random entry becomes sequential if you use the cache and its features. You can even use the old, very old data storage system as a quick file storage for the office.
What is a Software-defined Data Center and how SDS is included in the SDDC philosophy
The difference between software-defined infrastructures and the usual “static” ones is about the same as what happened between the good old electrical circuits on lamps and the “new” ones on transistors. That is very, very significant, but at first it is quite difficult to master it. We need new approaches and a new understanding of architecture.
I note that there is nothing directly fundamentally new in the very concept of Software-defined, and the basic principles were applied 15 years ago at least back. It was simply called differently and was found far from everywhere.
In this post, we discuss SDS (Software Defined Storage), only about storage, disk arrays and other storage devices, as well as their interfaces.
I will talk about technology based on DataCore software. This is not the only vendor, but it covers almost all the tasks of data warehousing virtualization completely.
Here are a few other vendors that solve data storage tasks on software-defined architectures:
• EMC with their ScaleIO allows you to combine any number of x86 servers with disk shelves into a single fast storage. Here is a theory , but the practice of a fault-tolerant system for domestic not the most reliable servers.
• Domestic RAIDIX . That's about them and their mushrooms .
Their architecture replaces for a number of specific tasks such as video editing for 10–20 thousand dollars with a storage system costing 80–100 thousand
• Riverbed has a cool solution, with the help of which we connected all the branches of the bank in the Moscow storage system so they saw it in their city LAN-network and made a quasi-synchronous replication through the cache.
Servers in cities 1 and 2 are addressed to storage systems in Moscow as to their “in-box” disks with LAN speeds. If necessary, you can work directly (case 3, disaster recovery office), but this already means the usual signal delays from the city to Moscow and back.
• In addition, Citrix and some other vendors have similar solutions, but, as a rule, they are more focused on the company's own products.
• Nutanix solves the problems of hyper storages, but it is often expensive because they make a hardware-software complex, and there the software is separated from the iron only on very, very large volumes.
• RED HAT offers CEPH or Gluster products, but these seemingly red-eyed guys at first glance supported the sanctions.
I have the most experience with DataCore , so I ask you to forgive in advance (and add) if I accidentally bypass someone’s cool features.
Actually, what you need to know about this company: Americans (but did not join the sanctions, because they were not even placed on the stock exchange), have been on the market for 18 years, all this time they are sawing under the guidance of the same peasant as at the very beginning, product - software for building storage - SANsymphony-V, which I will continue to call SSV for short. Since their chief is an engineer, they sabotaged the technology, but did not even think about marketing. As a result, nobody knew them as such until the last year, and they earned their money by embedding their technologies into foreign partner solutions not under their own brand.
About symphony
SSV is a software repository. From the consumer (host) side, the SSV looks like a regular storage system; in fact, it looks like a disk stuck directly into the server. In our case, in practice, this is usually a virtual multiport disk, two physical copies of which are available through two different DataCore nodes.
From here, the first basic function of SSV, synchronous replication, follows, and most of the actual DataCore LUNs used are fault tolerant disks.
The software can be placed on any x86 server (almost), almost any block devices can be used as resources: external storage systems (FC, iSCSI), internal disks (including PCI-SSD), DAS, JBOD, up to connected cloud storages. Almost - because there are requirements for the gland.
SSV virtual disks can be presented to any host (IBM i5 OS exception).
Simple application (virtualizer / FC / iSCSI target):
And more interesting:
Sweet functionality
SSV has a whole range of functions - caching, load balancing, Auto-Tiering and Random Write Accelerator.
Let's start with caching. The cache here is the entire free RAM of the server on which DC is installed, works both for writing and reading, the maximum amount is 1Tb. The same ScaleIO and RAIDIX do not use RAM, but they load the disks of "their" servers or controllers. This provides a faster cache.
In this DC-architecture, the bet is made on speed and reliability. In my opinion, for practical tasks of medium-sized businesses today we get the fastest and yet quite accessible cache.
In the same cache, on the basis of the RAM of the servers, the function of randomized write optimization works, for example, under the OLTP load.
The principle of the optimizer is very simple: the host uploads random data blocks (for example, SQL) to a virtual disk, they get into the cache (RAM), which is technologically able to write random blocks quickly by arranging these blocks in sequence. When a sufficient array of sequential data is typed, they are transferred to the disk subsystem.
Approximately here, read forwarding, block grouping, multithreading, block consolidation, protection from boot / login - storm, blender effect are done. If the management software understands what the host application does (for example, reads a VDI image according to the standard scheme), then the reading can be done before the host requests the data, because he read the same several times in the same situation. It is reasonable to put this in the cache at the moment when it becomes clear what exactly he is doing there.
Auto-Tiering is when any virtual disk is based on a pool in which a variety of media can be included - from PCI-SSD and FC storage to slow SATA and even external cloud storage. Each of the carriers is assigned a level from 0 to 14, and the software automatically redistributes the blocks between the carriers, depending on the frequency of access to the block. That is, archived data is placed on SATA and other slow carriers, and hot database fragments, for example, on SSD. Moreover, all available resources are automatically and optimally used; this is not manual file processing.
Evaluation of statistics and the subsequent movement of blocks occurs by default once every 30 seconds, but in case this does not create delays for current reading and writing tasks. Load balancing is present as an analogue of RAID 0 - striping between physical media in the disk pool, and also as an opportunity to fully use both cluster nodes (active-active) as the main one, which allows you to more efficiently load adapters and a SAN network.
Using SSV, you can, for example, organize a metrocluster between storage systems that do not support this feature or require additional expensive equipment for this. And at the same time not to lose (if there is a fast channel between the nodes), but to grow in performance and functionality, plus have a performance margin.
Architecture
There are only two SSV architectures.
The first is SDS, software-defined storage. The classic “heavy” storage system is, for example, a physical rack, where there is a RISC server and an SSD factory (or HDD arrays). In addition, in fact, the price of disks, the cost of this rack is largely determined by the difference in architectures, which is very important for high reliability solutions (for example, banks). The difference in price between the x86th Chinese crafts and the similar in size storage system of the same EMC, HP or other vendor ranges from about two to a similar set of disks. Approximately half of this difference is in architecture.
So, of course, you can combine several x86 servers with disk shelves into one fast network and teach how to work as a cluster. For this there is a special software, for example EMC Vipr. Or you can build on the basis of a single x86-th server storage, scoring his discs to the eyeballs.
SDS is actually such a server. With the only difference that in 99% of cases in practice these will be 2 nodes, and on the back end there can be just about anything.
Technically, these are two x86 servers. They are Windows and DataCore SSV, between them are synchronization links (block) and control (IP). These servers are located between the host (consumer) and storage resources, for example - a bunch of shelves with disks. Restriction - there should be block access both there and there.
The most clear description of the architecture will be the block recording procedure. The virtual disk is presented to the host as an ordinary block device. The application writes a block to the disk, the block enters the RAM of the first node (1), then over the synchronization channel is recorded in the RAM of the second node (2), then recorded (3), recorded (4).
As soon as the block appears in two copies, the application receives a confirmation of the record. The configuration of the DC platform and backend depends only on the load requirements of the hosts. How correctly system performance is limited by the resources of adapters and SAN-network.
The second is Virtual SAN, that is, virtual storage. DC SSV is located in a virtual machine running Windows Server, DC is allocated storage resources connected to this host (hypervisor). It can be both internal disks and external storage systems, such nodes can be from 2 to 64 pieces in the current version. DC allows you to combine resources "under" all hypervisors and dynamically distribute this volume.
There are also two physical copies of each block, as in the previous architecture. In practice, these are most often internal server disks. The practice is to build a fault-tolerant mini-data center without using external storage: these are 2–5 nodes that can be added if necessary for new computing or storage resources. This is a particular example of the now fashionable idea of a hyperconvergent environment that is used by Google, Amazon and others.
Simply put, you can build an Enterprise environment, and you can take a bunch of not the most reliable and not the fastest x86-technology, drive cars with disks and fly to capture the world on a small price list.
This is what the resulting system can do:
Two practical tasks
Task number 1. Build a virtual SAN. There are three virtualization servers located in the Data Center (2 servers) and the Backup Data Center (1 server).
It is necessary to unite into a single geographically distributed cluster of virtualization of VMware vSphere 5.5, to ensure the implementation of the fault tolerance and backup functions using technologies:
• VMware High Availability technology;
• VMware DRS load balancing technology;
• data channel backup technology;
• virtual network storage technology.
Provide the following modes of operation:
1) Normal operation.
A regular mode of operation is characterized by the functioning of all VMs in the Virtualization Center of the DPC and RCOD.
2) Emergency operation.
Emergency mode of operation is characterized by the following condition:
a) all virtual machines continue to work in the data center (DRC) in the following cases:
- network isolation server virtualization within the data center (RCMS);
- Failure of the virtual storage network between the data center and the RCOD;
- LAN failure between the data center and RZOD.
b) all virtual machines are automatically restarted on other nodes of the cluster in the data center (DRC) in the following cases:
- failure of one or two virtualization servers;
- the failure of the data center site (RCOD) during a disaster (failure of all virtualization servers).
Server hardware specifications | |
Server number 1 | |
Server | HP DL380e Gen8 |
2 x processor | Intel Xeon Processor E5-2640 v2 |
RAM capacity | 128 GB |
10 x HDD | HP 300 GB 6G SAS 15K 2.5in SC ENT HDD |
Network interface | 2 * 10Gb, 4 * 1Gb |
Server number 2 | |
Server | HP DL380e Gen8 |
2 x processor | Intel Xeon Processor E5-2650 |
RAM capacity | 120 GB |
8 x HDD | HP 300 GB 6G SAS 15K 2.5in SC ENT HDD |
Network interface | 2 * 10Gb, 4 * 1Gb |
Server number 3 | |
Server | IBM x3690 X5 |
2 x processor | Intel Xeon Processor X7560 8C |
Type of RAM | IBM 8GB PC3-8500 CL7 ECC DDR3 1066 MHz LP RDIMM |
RAM capacity | 264 |
16 x HDD | IBM 146 GB 6G SAS 15K 2.5in SFF SLIM HDD |
Network interface | 2 * 10Gb, 2 * 1Gb |
Decision:
• Use existing hardware to create a virtualization subsystem.
• On the basis of the same equipment and internal server storage devices, create a virtual storage network with the function of synchronous replication of volumes using DataCore software.
A virtual server — a DataCore node — is deployed on each virtualization server, and virtual disks created on the local disk resources of the virtualization servers are additionally connected to the DataCore nodes. These disks are combined into pools of disk resources, on the basis of which mirror virtual disks are created. The disks are mirrored between the two DataCore Virtual SAN nodes - so the “original” disk is placed on the disk resource pool of one node, the “mirror copy” is placed on the second. Next, virtual disks are presented to virtualization servers (hypervisors) or virtual machines directly.
It turns out cheap and angry (colleagues suggest: a competitive solution for the price) and without additional iron. In addition to solving the immediate problem, the storage network gets a lot of useful additional functionality: increased performance, the ability to integrate with VMware, snapshots for the entire volume, and so on. With further growth, you only need to add virtual cluster nodes or update existing ones.
Here is the diagram:
Task number 2. Unified Storage System (NAS / SAN).
It all started with the Windows Failover cluster for the file server. The customer needed to make a file to store documents - with high availability and data backup and with almost instant data recovery. It was decided to build a cluster.
From the existing equipment, the customer had two Supermicro servers (one of which has SAS JBOD connected). There is more than enough disk space in two servers (about 10 TB per server), however, for the organization of a cluster, shared storage is required. It was also planned to have a backup of the data, since a single storage system is a single point of failure, preferably with a CDP covering the work week. The data must be available all the time, the maximum idle time is 30 minutes (and heads can fly). The standard solution included the purchase of storage, another server for backups.
Decision:
• DataCore software is installed on each server.
In DataCore architecture, Windows Failover Cluster can be deployed without using shared SAN storage (using internal server disks) or using DAS, JBOD or external storage systems with full implementation of DataCore Unified Storage (SAN & NAS) architecture, taking full advantage of Windows Server 2012 and NFS & SMB (CIFS) and providing SAN service to external hosts. Such an architecture was eventually deployed, and the disk space not used for a file server was not presented as a SAN for ESXi hosts.
It turned out very cheap in comparison with traditional solutions, plus:
- Failover of storage resources (including in the context of the Windows Failover Cluster). Two mirror copies of data are available at any time.
- Thanks to the virtualization functions, Windows Cluster DataCore itself provides a mirrored multiport virtual disk, i.e. the problem of a long chkdsk ceases to exist as such.
- Further scaling of the system (for example, increasing the volume of data requires connecting an additional disk array or increasing the volume in the server itself) is an extremely simple process without stopping the service.
- Perform any technological work on the maintenance of cluster nodes - without stopping the file access service.
- CDP at SANsymphony-V10 is a built-in function and is limited only by the free space on the disks.
- Increased storage performance by taking advantage of DataCore, namely Adaptive Caching, when the entire free RAM of servers is used as a cache for connected storage systems, and the cache works both for writing and reading, but this is more important for ESXi hosts than for file ball.
Main principle
The basic principle of storage virtualization is, on the one hand, to hide the entire backend from the consumer, on the other hand, to provide any real competitive functionality to any backend.
Important practical notes about Datacore
- In the second architecture, DataCore does almost the same thing as, for example, ScaleIO.
- If you have a task to provide data storage of branches across Russia, but you do not want to link them with the current storage system and do not want to install new storage systems in the branches, that is, a simple method like a log. You take three servers with 24 disks each and get an acceptable volume and acceptable performance for the operation of most services.
- If you need to streamline the zoo - it will be cheaper and easier to find an option. The dates are as follows: the last example is 8 days for implementation. Design is about a week before that. The equipment used is available, in principle, not purchased. Bought only dice operatives in the cache. Datacore license went a little more than a week, but we lay two.
- DC is licensed by volume - in packs of 8, 16 TB. If interested, I can throw off the conditional street price (important: in fact, everything is quite flexible, licensing is done by host or TB, and you can choose some functions, so in fact the prices are very different, if you need to calculate for your case - also write in a personal).
In one of our tasks, we had the organization of a DMZ segment of a large company. To save storage and optimize access to local storage, they put just DC. A common SAN core with a DMZ was not shared, so one would have to either buy a storage system and another firewall-like piece of hardware with secure links for secure access inside, or move the braces. We combined 3 virtualization hosts into a single space plus optimized access. It turned out cheap and fast.
In another task, we had to optimize access under SQL. There we were able to use the old slow storage. Record thanks to the DC cache went ten times faster than directly.
There is RAID Striping useful for some situations (you can build software RAID0 and RAID1, even if the connected DAS cannot do this).
Good reports are visual and statistical tools for providing data on various performance parameters with indication of “bottlenecks”.
QoS Control allows DBMS and critical applications to work faster, setting I / O traffic limits for less important workloads.
I cut down the nodes on the tests on nutrition (within reasonable limits, retaining the required number of nodes for correct recovery), but could not catch the corraps. Synchronous Mirroring & Auto Failover - there is a synchronous replication and mechanisms for automatic and custom recovery after failures. The self-healing function of disk pools is this: if a physical disk in a pool fails or is marked for replacement, DataCore automatically restores the pool to available resources. Plus a change log on the disk with the ability to recover from any state or from any time. The planned replacement of the discs, of course, is done without interruption. As usual, data is smeared between other instances, and then at the first opportunity, the volume “crawls” onto a new disk. Approximately by a similar principle migration between TsODs becomes, only "replacement of disks" has mass character.
There is Virtual Disk Migration - simple and efficient data migration from physical resources to virtual resources and vice versa. And without stopping applications. There is an opportunity for everyone to connect to a live installation and touch the console with their own hands.
Source: https://habr.com/ru/post/272795/
All Articles