Optimizing hyperparameters in Vowpal Wabbit with the new vw-hyperopt module
Hi, Habr! In this article we will discuss this not very pleasant aspect of machine learning, as the optimization of hyperparameters. Two weeks ago, the vw-hyperopt.py module, which can find good configurations of hyper parameters of Vowpal Wabbit models in large spaces, was poured into a very well-known and useful Vowpal Wabbit project. The module was developed inside DCA (Data-Centric Alliance).

To find good configurations, vw-hyperopt uses algorithms from the Python library Hyperopt and can optimize hyperparameters adaptively using the Tree-Structured Parzen Estimators (TPE) method. This allows you to find better optima than a simple grid search, with an equal number of iterations.
This article will be interesting to everyone who deals with Vowpal Wabbit, and especially to those who are annoyed by the lack of methods for tuning numerous model handles in the source code, and either manually typing them or by optimizing on their own.
What are hyperparameters? These are all “degrees of freedom” of the algorithm, which it does not directly optimize, but on which the result depends. Sometimes the result depends quite a bit, and then, if it is not a kaggle, you can get by with default values or select manually. But sometimes an unsuccessful configuration can spoil everything: the algorithm is either greatly retrained, or, conversely, will not be able to use most of the information.
')
In the narrow sense, hyperparameters are often understood only as regularization and other “obvious” settings of machine learning methods. However, in a broad sense, hyperparameters are generally any manipulations with data that can affect the result: engineering of features, weighing observations, undersampling, etc.
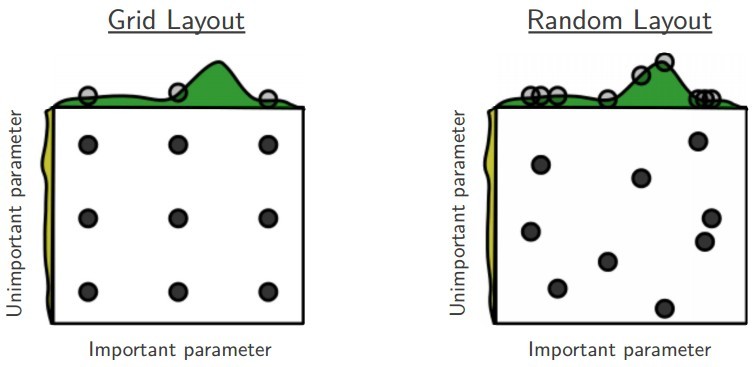
Of course, it would be nice to have an algorithm that, in addition to optimizing parameters, would also optimize hyperparameters. Even better, if we could trust this algorithm more than intuition. Some steps in this direction, of course, have long been made. Naive methods are built into many machine learning libraries: grid search - a grid scan, or random search - sampling points from a fixed distribution (the most well-known instances are GridSearchCV and RandomizedGridSearchCV to sklearn). The advantage of passing through the grid is that it is easy to code it yourself and easy to parallelize. However, it has serious drawbacks:
In order to reduce the number of iterations to find a good configuration, adaptive Bayesian methods are invented. They choose the next point to check, taking into account the results on the already checked points. The idea is to find a compromise at every step between (a) exploring regions near the most successful points among those found and (b) exploring regions with great uncertainty, where even more successful points can be found. This is often called the explore-exploit dilemma or “learning vs earning”. Thus, in situations where checking every new point is expensive (in machine learning, checking = training + validation), you can get closer to the global optimum in a much smaller number of steps.
Similar algorithms in different variations are implemented in the MOE , Spearmint , SMAC , BayesOpt and Hyperopt tools . We will dwell on the latter in more detail, since
Many of you have probably used this tool or at least heard about it. In short, it is one of the fastest (if not the fastest) machine learning library in the world. To train the model for our CTR-predictor (binary classification) on 30 million observations and tens of millions of features takes only a few gigabytes of RAM and 6 minutes on one core. Vowpal Wabbit implements several online algorithms:
In addition, feed-forward neural networks, batch optimization (BFGS) and LDA are implemented in it. You can run Vowpal Wabbit in the background and take the data stream to the input, either by learning to them or simply by making predictions.
FTRL and SGD can solve both regression and classification problems, this is regulated only by the loss function. These algorithms are linear with respect to features, but non-linearity can easily be achieved with the help of polynomial features. There is a very useful mechanism for early stopping in order to avoid retraining if too many epochs are indicated.
Vowpal Wabbit is also famous for its feature hashing, which serves as an additional regularization if there are a lot of features. Due to this, it is possible to study categorical features with billions of rare categories, fitting the model into the operational memory without sacrificing quality.
Vowpal Wabbit requires a special input data format , but it is easy to understand. It is naturally sparse and takes up little space. Only one observation (or several, for LDA) is loaded into RAM at any time. Learning is easiest to run through the console.
Those interested can read the tutorial and other examples and articles in their repositories, as well as the presentation . About the insides of Vowpal Wabbit can be read in detail in the publications of John Langford and in his blog . Habré also has a suitable post . The list of arguments can be obtained through
In Vowpal Wabbit, there is a vw-hypersearch module , which can pick up one hyperparameter using the golden section method . However, if there are several local minima, this method is likely to find a far from the best option. In addition, it is often necessary to optimize many hyperparameters at once, and this is not in vw-hypersearch. A couple of months ago I tried to write a multidimensional method of the golden section, but the number of steps that he needed for convergence exceeded any grid search, so this option was dropped. It was decided to use Hyperopt.
This library, written in python, implements the Tree-Structured Parzen Estimators (TPE) optimization algorithm. Its advantage is that it can work with very “awkward” spaces: when one hyperparameter is continuous, the other is categorical; the third is discrete, but its neighboring values are correlated with each other; Finally, some combinations of parameter values may simply not make sense. TPE takes as input a hierarchical search space with a priori probabilities, and at each step mixes them with a Gaussian distribution with a center at a new point. Its author, James Bergster, claims that this algorithm solves the problem of explore-exploit quite well and works better both on grid search and expert busting, at least for deep learning tasks, where there are especially many hyperparameters. Read more about it here and here . About the TPE algorithm itself can be read here . Perhaps in the future it will be possible to write a detailed post about him.
Although Hyperopt was not built into the source code of known machine learning libraries, many use it. For example, here is a great tutorial on hyperopt + sklearn . Here is the application of hyperopt + xgboost . All my input is a similar wrapper for Vowpal Wabbit, a more or less tolerable syntax for defining the search space and running it all from the command line. Since Vowpal Wabbit did not yet have this functionality, Langford liked my module, and it was poured into it. In fact, anyone can try Hyperopt for their favorite machine learning tool: this is easy to do, and everything you need is in this tutorial .
We now turn to using the
Attention! The latest changes (in particular, the new command syntax) so far (as of December 15) are not merged into the main repository. In the coming days, I hope the problem will be solved, but for now you can use the latest version of the code from my branch . EDIT: On December 22, the changes are merged, now you can use the main repository.
The input module requires training and validation samples, as well as a priori distribution of hyper
Optionally, you can change the loss function on the validation sample and the maximum number of iterations (
Since it is not customary to lay out detailed documentation on Habrahabr, I will limit myself to referring to it. You can read about all the semantics in the Russian-language wiki in my fork or wait for the English version in the main Vowpal Wabbit repository.
In the future, it is planned to add to the module:
I would be very happy if someone uses the module and it will help someone. I will welcome any suggestions, ideas or bugs found. You can write them here or create an issue on the githaba .
Pull request with the latest changes in the main repository Vowpal Wabbit, so that you can now use it, not a branch.
To find good configurations, vw-hyperopt uses algorithms from the Python library Hyperopt and can optimize hyperparameters adaptively using the Tree-Structured Parzen Estimators (TPE) method. This allows you to find better optima than a simple grid search, with an equal number of iterations.
This article will be interesting to everyone who deals with Vowpal Wabbit, and especially to those who are annoyed by the lack of methods for tuning numerous model handles in the source code, and either manually typing them or by optimizing on their own.
Hyperparameters
What are hyperparameters? These are all “degrees of freedom” of the algorithm, which it does not directly optimize, but on which the result depends. Sometimes the result depends quite a bit, and then, if it is not a kaggle, you can get by with default values or select manually. But sometimes an unsuccessful configuration can spoil everything: the algorithm is either greatly retrained, or, conversely, will not be able to use most of the information.
')
In the narrow sense, hyperparameters are often understood only as regularization and other “obvious” settings of machine learning methods. However, in a broad sense, hyperparameters are generally any manipulations with data that can affect the result: engineering of features, weighing observations, undersampling, etc.
Grid search
Of course, it would be nice to have an algorithm that, in addition to optimizing parameters, would also optimize hyperparameters. Even better, if we could trust this algorithm more than intuition. Some steps in this direction, of course, have long been made. Naive methods are built into many machine learning libraries: grid search - a grid scan, or random search - sampling points from a fixed distribution (the most well-known instances are GridSearchCV and RandomizedGridSearchCV to sklearn). The advantage of passing through the grid is that it is easy to code it yourself and easy to parallelize. However, it has serious drawbacks:
- He goes through many obviously unsuccessful points. Suppose there is already a set of some configurations with results or some other information. A person can understand which configurations will accurately provide a settling result, and will guess not to check these regions once again. Grid search can't do that.
- If there are many hyperparameters, then the size of the “cell” has to be made too large, and you can miss a good optimum. Thus, if we include in the search space a lot of unnecessary hyperparameters that do not affect the result in any way, then grid search will work much worse with the same number of iterations. However, for random search this is true to a lesser extent:
Bayesian methods
In order to reduce the number of iterations to find a good configuration, adaptive Bayesian methods are invented. They choose the next point to check, taking into account the results on the already checked points. The idea is to find a compromise at every step between (a) exploring regions near the most successful points among those found and (b) exploring regions with great uncertainty, where even more successful points can be found. This is often called the explore-exploit dilemma or “learning vs earning”. Thus, in situations where checking every new point is expensive (in machine learning, checking = training + validation), you can get closer to the global optimum in a much smaller number of steps.
Similar algorithms in different variations are implemented in the MOE , Spearmint , SMAC , BayesOpt and Hyperopt tools . We will dwell on the latter in more detail, since
vw-hyperopt is a wrapper over Hyperopt, but first you need to write a little about Vowpal Wabbit.Vowpal wabbit
Many of you have probably used this tool or at least heard about it. In short, it is one of the fastest (if not the fastest) machine learning library in the world. To train the model for our CTR-predictor (binary classification) on 30 million observations and tens of millions of features takes only a few gigabytes of RAM and 6 minutes on one core. Vowpal Wabbit implements several online algorithms:
- Stochastic gradient descent with different bells and whistles;
- FTRL-Proximal, which you can read about here ;
- Online similarity to SVM;
- Online boosting;
- Factoring machines.
In addition, feed-forward neural networks, batch optimization (BFGS) and LDA are implemented in it. You can run Vowpal Wabbit in the background and take the data stream to the input, either by learning to them or simply by making predictions.
FTRL and SGD can solve both regression and classification problems, this is regulated only by the loss function. These algorithms are linear with respect to features, but non-linearity can easily be achieved with the help of polynomial features. There is a very useful mechanism for early stopping in order to avoid retraining if too many epochs are indicated.
Vowpal Wabbit is also famous for its feature hashing, which serves as an additional regularization if there are a lot of features. Due to this, it is possible to study categorical features with billions of rare categories, fitting the model into the operational memory without sacrificing quality.
Vowpal Wabbit requires a special input data format , but it is easy to understand. It is naturally sparse and takes up little space. Only one observation (or several, for LDA) is loaded into RAM at any time. Learning is easiest to run through the console.
Those interested can read the tutorial and other examples and articles in their repositories, as well as the presentation . About the insides of Vowpal Wabbit can be read in detail in the publications of John Langford and in his blog . Habré also has a suitable post . The list of arguments can be obtained through
vw --help or read a detailed description . As can be seen from the description, there are dozens of arguments, and many of them can be considered as hyper-parameters that can be optimized.In Vowpal Wabbit, there is a vw-hypersearch module , which can pick up one hyperparameter using the golden section method . However, if there are several local minima, this method is likely to find a far from the best option. In addition, it is often necessary to optimize many hyperparameters at once, and this is not in vw-hypersearch. A couple of months ago I tried to write a multidimensional method of the golden section, but the number of steps that he needed for convergence exceeded any grid search, so this option was dropped. It was decided to use Hyperopt.
Hyperopt
This library, written in python, implements the Tree-Structured Parzen Estimators (TPE) optimization algorithm. Its advantage is that it can work with very “awkward” spaces: when one hyperparameter is continuous, the other is categorical; the third is discrete, but its neighboring values are correlated with each other; Finally, some combinations of parameter values may simply not make sense. TPE takes as input a hierarchical search space with a priori probabilities, and at each step mixes them with a Gaussian distribution with a center at a new point. Its author, James Bergster, claims that this algorithm solves the problem of explore-exploit quite well and works better both on grid search and expert busting, at least for deep learning tasks, where there are especially many hyperparameters. Read more about it here and here . About the TPE algorithm itself can be read here . Perhaps in the future it will be possible to write a detailed post about him.
Although Hyperopt was not built into the source code of known machine learning libraries, many use it. For example, here is a great tutorial on hyperopt + sklearn . Here is the application of hyperopt + xgboost . All my input is a similar wrapper for Vowpal Wabbit, a more or less tolerable syntax for defining the search space and running it all from the command line. Since Vowpal Wabbit did not yet have this functionality, Langford liked my module, and it was poured into it. In fact, anyone can try Hyperopt for their favorite machine learning tool: this is easy to do, and everything you need is in this tutorial .
vw-hyperopt
We now turn to using the
vw-hyperopt . First you need to install the latest version of Vowpal Wabbit from the github. The module is located in the utl folder.Attention! The latest changes (in particular, the new command syntax) so far (as of December 15) are not merged into the main repository. In the coming days, I hope the problem will be solved, but for now you can use the latest version of the code from my branch . EDIT: On December 22, the changes are merged, now you can use the main repository.
Usage example:
./vw-hyperopt.py --train ./train_set.vw --holdout ./holdout_set.vw --max_evals 200 --outer_loss_function logistic --vw_space '--algorithms=ftrl,sgd --l2=1e-8..1e-1~LO --l1=1e-8..1e-1~LO -l=0.01..10~L --power_t=0.01..1 --ftrl_alpha=5e-5..8e-1~L --ftrl_beta=0.01..1 --passes=1..10~I --loss_function=logistic -q=SE+SZ+DR,SE~O --ignore=T~O' --plot The input module requires training and validation samples, as well as a priori distribution of hyper
--vw_space (quoted inside --vw_space ). You can specify integer, continuous, or categorical hyperparameters. For all but categorical, you can set a uniform or log-uniform distribution. The example search space is converted inside vw-hyperopt approximately into such an object for Hyperopt (if you have completed the Hyperopt tutorial, you will understand this): from hyperopt import hp prior_search_space = hp.choice('algorithm', [ {'type': 'sgd', '--l1': hp.choice('sgd_l1_outer', ['empty', hp.loguniform('sgd_l1', log(1e-8), log(1e-1))]), '--l2': hp.choice('sgd_l2_outer', ['empty', hp.loguniform('sgd_l2', log(1e-8), log(1e-1))]), '-l': hp.loguniform('sgd_l', log(0.01), log(10)), '--power_t': hp.uniform('sgd_power_t', 0.01, 1), '-q': hp.choice('sgd_q_outer', ['emtpy', hp.choice('sgd_q', ['-q SE -q SZ -q DR', '-q SE'])]), '--loss_function': hp.choice('sgd_loss', ['logistic']), '--passes': hp.quniform('sgd_passes', 1, 10, 1), }, {'type': 'ftrl', '--l1': hp.choice('ftrl_l1_outer', ['emtpy', hp.loguniform('ftrl_l1', log(1e-8), log(1e-1))]), '--l2': hp.choice('ftrl_l2_outer', ['emtpy', hp.loguniform('ftrl_l2', log(1e-8), log(1e-1))]), '-l': hp.loguniform('ftrl_l', log(0.01), log(10)), '--power_t': hp.uniform('ftrl_power_t', 0.01, 1), '-q': hp.choice('ftrl_q_outer', ['emtpy', hp.choice('ftrl_q', ['-q SE -q SZ -q DR', '-q SE'])]), '--loss_function': hp.choice('ftrl_loss', ['logistic']), '--passes': hp.quniform('ftrl_passes', 1, 10, 1), '--ftrl_alpha': hp.loguniform('ftrl_alpha', 5e-5, 8e-1), '--ftrl_beta': hp.uniform('ftrl_beta', 0.01, 1.) } ]) Optionally, you can change the loss function on the validation sample and the maximum number of iterations (
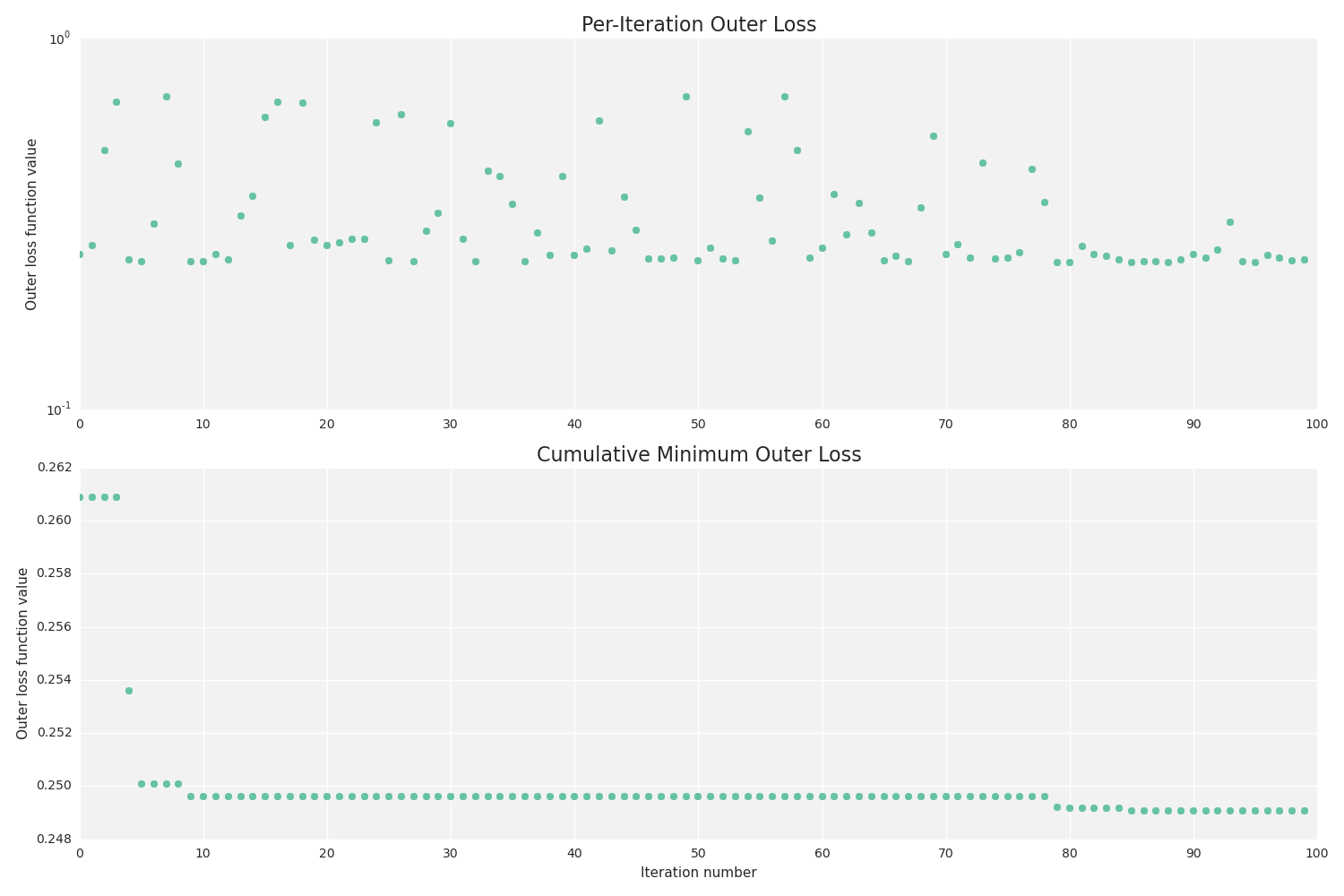
--outer_loss_function , the default is logistic , and --max_evals , the default is 100). You can also save the results of each iteration and build graphs with --plot if matplotlib installed and, preferably, seaborn :Documentation
Since it is not customary to lay out detailed documentation on Habrahabr, I will limit myself to referring to it. You can read about all the semantics in the Russian-language wiki in my fork or wait for the English version in the main Vowpal Wabbit repository.
Plans
In the future, it is planned to add to the module:
- Support regression and multiclass classification tasks.
- Support for a “warm start”: give Hyperopt pre-estimated points, and start optimizing considering the results for them.
- The error estimation option at each step on another test sample (but without optimizing the hyperparameters on it). This is necessary in order to better assess the generalizing ability — have we not retrained?
- Support for binary parameters that do not take any values, such as
--lrqdropout, --normalized, --adaptive, etc. Now you can, in principle, write--adaptive=\ ~O, but this is not intuitive at all. You can do something like--adaptive=~Bor--adaptive=~BO.
I would be very happy if someone uses the module and it will help someone. I will welcome any suggestions, ideas or bugs found. You can write them here or create an issue on the githaba .
Update 12/22/2015
Pull request with the latest changes in the main repository Vowpal Wabbit, so that you can now use it, not a branch.
Source: https://habr.com/ru/post/272697/
All Articles