Calibrate Kinect v2 with OpenCV in Python
Not so long ago, we started a couple of projects that require an optical system with a range channel, and decided to use Kinect v2 for this. Since the projects are implemented in Python, you first had to get Kinect to work from Python, and then calibrate it, since Kinect out of the box introduces some geometric distortion in the frames and gives centimeter errors in determining the depth.
Before that, I have never dealt with computer vision, or with OpenCV, or with Kinect. I did not manage to find an exhaustive instruction on how to work with all this farming, so I had to tinker with it in the end. And I decided that it would not be superfluous to systematize the experience gained in this article. Perhaps, it will be useful for some suffering,and we also need a popular article for a tick in the reporting .
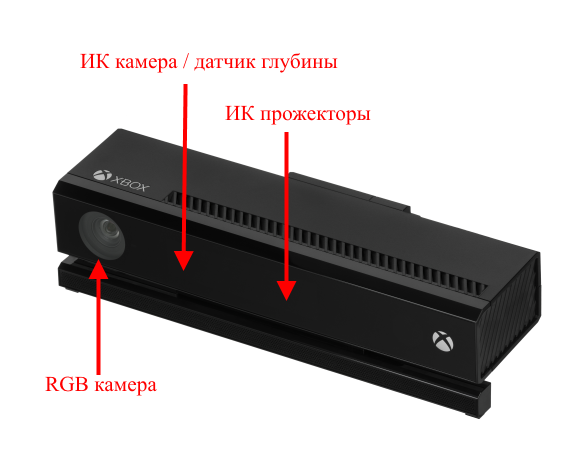
Minimum system requirements : Windows 8 and higher, Kinect SDK 2.0, USB 3.0.
')
Table I. Kinect v2 features:
Thus, I had the following tasks:
And now we will dwell on each item.
As I have already said, I hadn’t done anything with computer vision before, but I heard rumors that without the OpenCV library there is nowhere. And since it has a whole camera calibration module , the first thing I did was assemble OpenCV with Python 3 support under Windows 8.1. It was not without some trouble, usually accompanying the assembly of open-source projects on Windows, but everything went without any surprises and in general as part of the instructions from the developers.
I had to tinker a bit longer with Kinect. The official SDK only supports interfaces for C #, C ++ and JavaScript. If you go to the other side, you can see that OpenCV supports input from 3D cameras, but the camera should be compatible with the OpenNI library. OpenNI supports Kinect, but the relatively recent Kinect v2 does not. However, good people wrote a driver for Kinect v2 under OpenNI. It even works and allows you to admire the video from the device channels in NiViewer, but when used with OpenCV crashes. However, other good people wrote a Python wrapper over the official SDK. I stopped at it.
The cameras are not perfect, they distort the image and need to be calibrated. To use Kinect for measurements, it would be nice to eliminate these geometric distortions on both the RGB camera and the depth sensor. Since the IR camera is also the receiver of the depth sensor, we can use IR frames for calibration, and then use the calibration results to eliminate distortions from the depth frames.
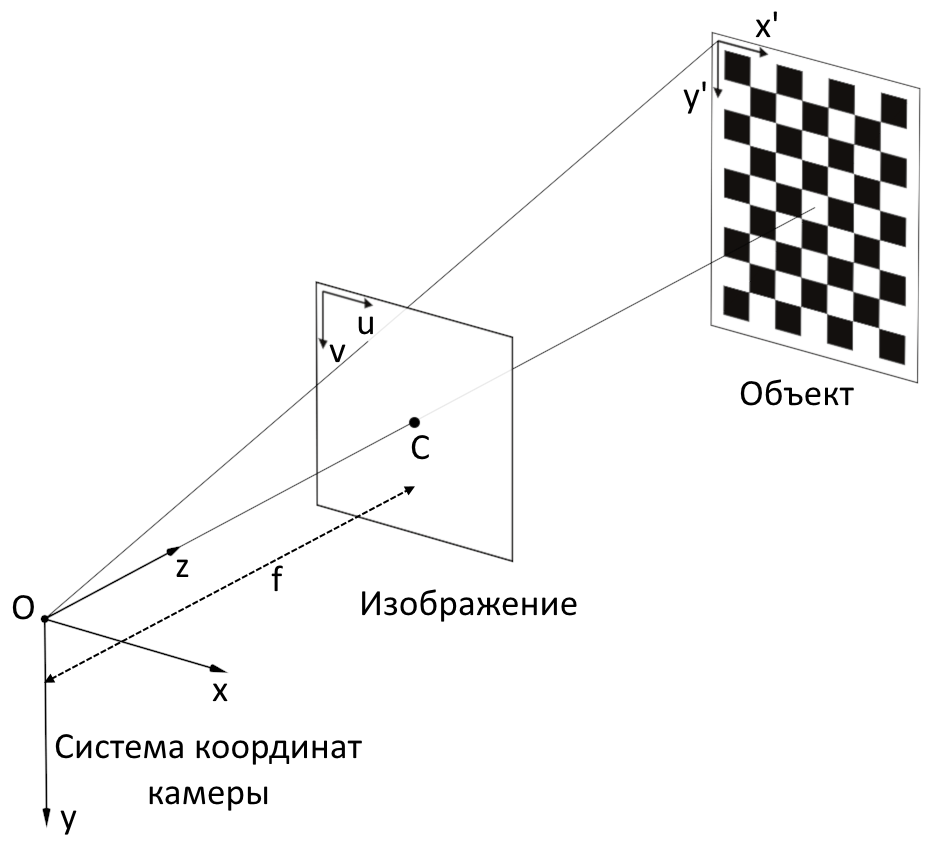
Calibration of the camera is carried out in order to find out the internal parameters of the camera, namely, the camera matrix and the distortion coefficients.
The matrix of the camera is called the matrix of the form:
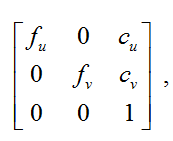 Where
Where
( u , c v ) - coordinates of the principal point (the point of intersection of the optical axis with the image plane, in the ideal camera to be exactly in the center of the image, in real ones it is slightly offset from the center);
f u , f v is the focal length f measured in width and height of a pixel.
There are two main types of distortion: radial distortion and tangential distortion.
Radial distortion - image distortion as a result of the non-ideality of the parabolic lens shape. Distortions caused by radial distortion are 0 in the optical center of the sensor and increase towards the edges. As a rule, radial distortion makes the greatest contribution to image distortion.
Tangential distortion - image distortion caused by errors in the installation of the lens parallel to the image plane.
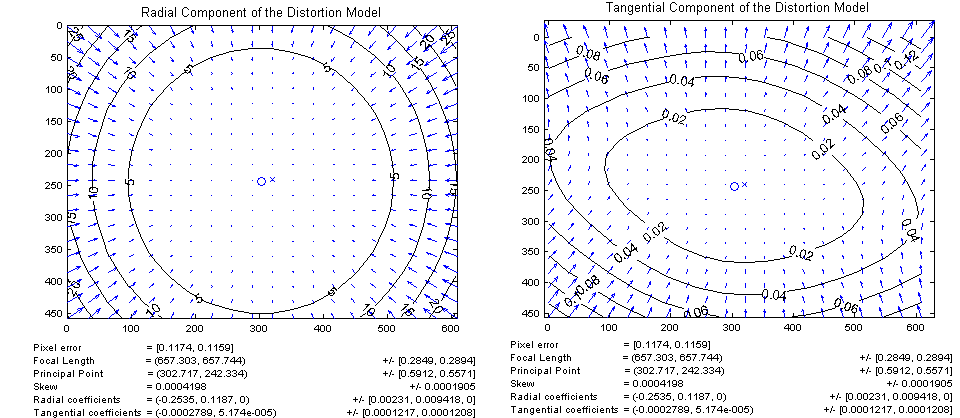
To eliminate distortion pixel coordinates can be recalculated using the following equation :
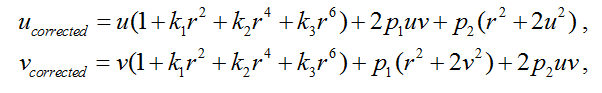
where ( u, v ) is the initial location of the pixel,
( u corrected , v corrected ) - the location of the pixel after removing geometric distortions,
k 1 , k 2 , k 3 - the coefficients of radial distortion,
p 1 p 2 - the coefficients of tangential distortion,
r 2 = u 2 + v 2 .
The accuracy of the measurement of camera parameters (distortion coefficients, camera matrix) is determined by the average value of the reprojection error ( ReEr, Reprojection Error ). ReEr is the distance (in pixels) between the projection P ' on the image plane of the point P on the object's surface, and the projection P' 'of the same point P , constructed after eliminating distortion using camera parameters.
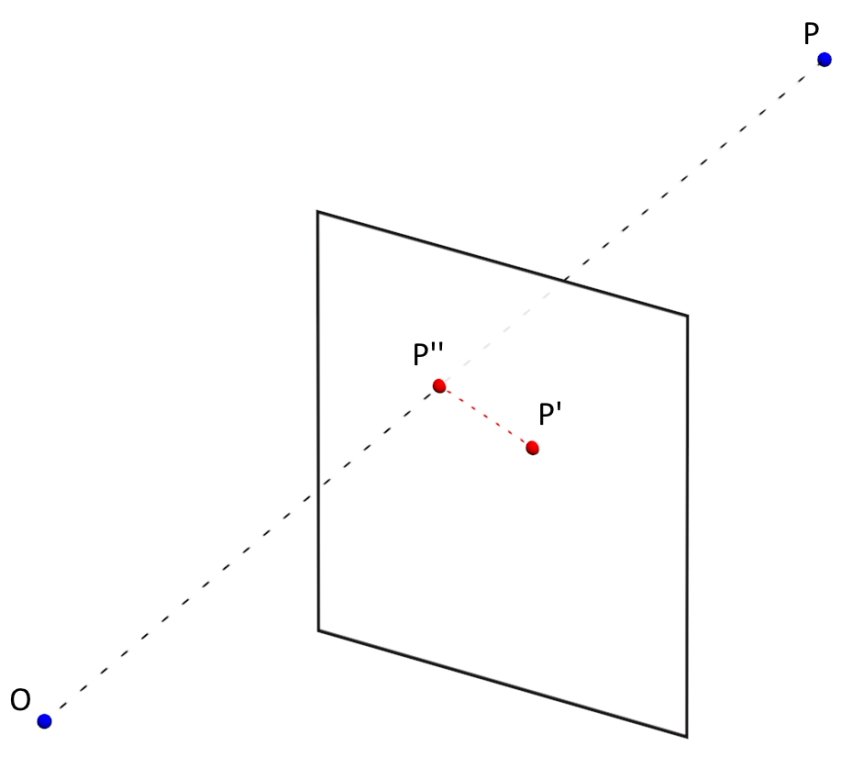
The standard camera calibration procedure consists of the following steps:
1) make 20-30 photographs with different positions of theobject with the known geometry of a chessboard;

2) identify the key points of the object in the image;

3) find the distortion coefficients that minimize ReEr .
In our case, the average ReEr value for the RGB camera was 0.3 pixels, and for the IR camera - 0.15. The results of the elimination of distortion:

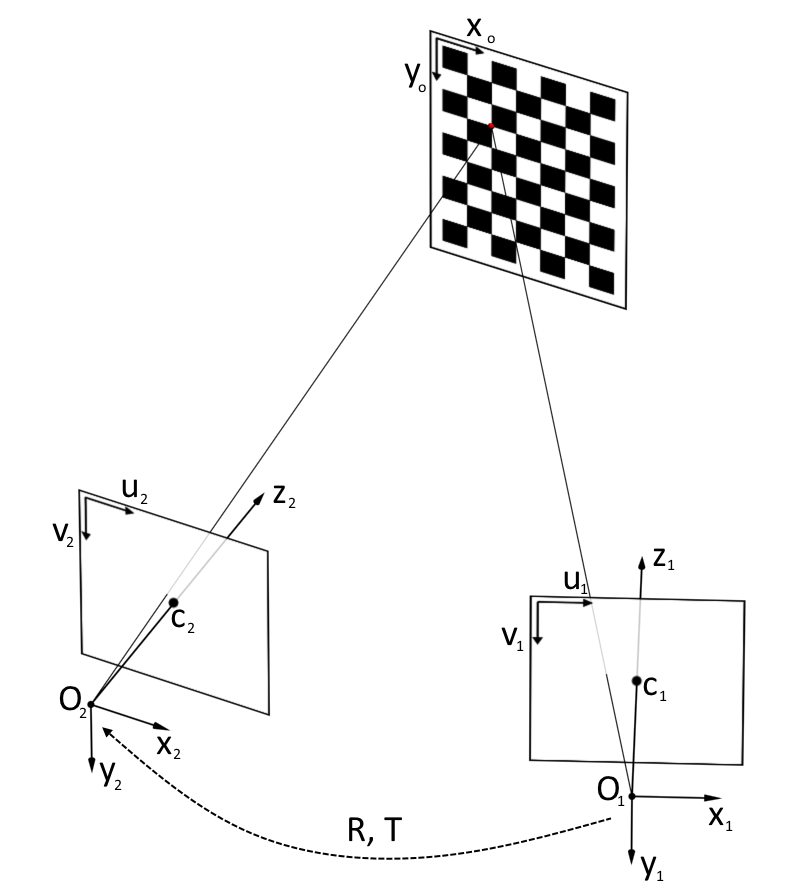
In order to get both a depth (Z coordinate) for a pixel and a color, first you need to go from pixel coordinates on a depth frame to three-dimensional coordinates of an IR camera [2]:
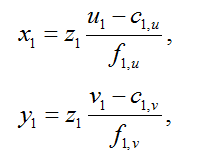
where ( x 1 , y 1 , z 1 ) are the coordinates of a point in the coordinate system of the IR camera,
z 1 is the result returned by the depth sensor,
( u 1 , v 1 ) - coordinates of the pixel in the depth frame,
c 1, u , c 1, v - coordinates of the optical center of the IR camera,
f 1, u , f 1, v are the projections of the focal length of the IR camera.
Then you need to go from the coordinate system of the IR camera to the coordinate system of the RGB camera. To do this, you need to move the origin using the transfer vector T and rotate the coordinate system using the rotation matrix R :
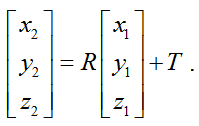
Then you need to go from the three-dimensional coordinate system of the RGB camera to the pixel coordinates of the RGB frame:
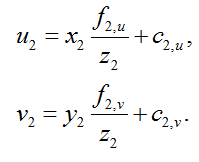
Thus, after all these transformations, we can get for the pixel ( u 1 , v 1 ) of the depth frame the color value of the corresponding pixel of the RGB frame ( u 2 , v 2 ).

As seen in the resulting image, the image is twofold. The same effect can be observed when using the CoordinateMapper class from the official SDK. However, if only a person is interested in the image, then you can use bodyIndexFrame (the Kinect stream, which allows you to find out which pixels belong to a person and which ones to the background) to highlight the region of interest and eliminate ghosting.

To determine the rotation matrix R and the transfer vector T, it is necessary to carry out a joint calibration of the two cameras. To do this, you need to take 20-30 photographs of an object with known geometries in different positions with both RGB and IR cameras, it is better not to hold the object in your hands, in order to exclude the possibility of its displacement between taking pictures with different cameras. Then you need to use the stereoCalibrate function from the OpenCV library. This function determines the position of each camera relative to the calibration object, and then finds such a transformation from the coordinate system of the first camera to the coordinate system of the second camera, which minimizes ReEr.
And in the end we got ReEr = 0.23.
The Kinect depth sensor returns the depth (namely, depth, i.e., Z-coordinate, not distance) in mm. But how accurate are these values? Judging by the publication [2], the error may be 0.5–3 cm depending on the distance, so it makes sense to calibrate the depth channel.
This procedure is to find the Kinect systematic error (the difference between the reference depth and the depth given by the sensor) depending on the distance to the object. And for this you need to know the reference depth. The most obvious way is to position the flat object parallel to the camera plane and measure the distance to it with a ruler. By gradually moving the object and making a series of measurements at each distance, one can find the average error for each of the distances. But, firstly, it is not very convenient, and secondly, to find a perfectly flat object of relatively large dimensions and to ensure parallelism of its location relative to the plane of the camera is more difficult than it might seem at first glance. Therefore, as a reference against which the error will be calculated, we decided to take the depth, which is determined by the known geometry of the object.
Knowing the geometry of the object (for example, the size of the cells of a chessboard) and placing it strictly parallel to the plane of the chamber, you can determine the depth to it as follows:
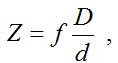
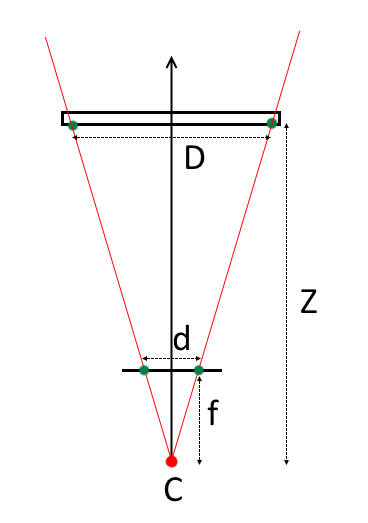
where f is the focal length,
d is the distance between the projections of the key points on the camera matrix,
D is the distance between the key points of the object,
Z is the distance from the center of the camera projection to the object.
If the object is located not strictly parallel, but at a certain angle to the camera plane, the depth can be determined based on the solution of the Perspective-n-Point (PnP) problem [3]. A number of algorithms implemented in the OpenCV library that allow you to find the transformation | R, T | between the coordinate system of the calibration object and the coordinate system of the camera, and therefore, determine the depth to the accuracy of the camera parameters.
To calibrate the depth channel, we made a series of surveys of the calibration object at distances of ~ 0.7-2.6 m with a step of ~ 7 cm. The calibration object was located in the center of the frame parallel to the plane of the camera, as far as it is possible to do "by eye". At each distance, one RGB image was taken with a camera and 100 images with a depth sensor. The data from the sensor were averaged, and the distance determined by the geometry of the object based on the RGB frame was taken as the standard. The average error in determining the depth of the Kinect sensor at this distance was determined as follows:
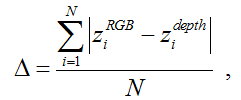
where z i RGB - the distance to the i-th key point in geometry,
z i depth - the distance averaged over 100 frames to the i-th key point according to the depth sensor,
N - the number of key points on the object (in our case 48).
Then we obtained the error function of distance by interpolating the results obtained.
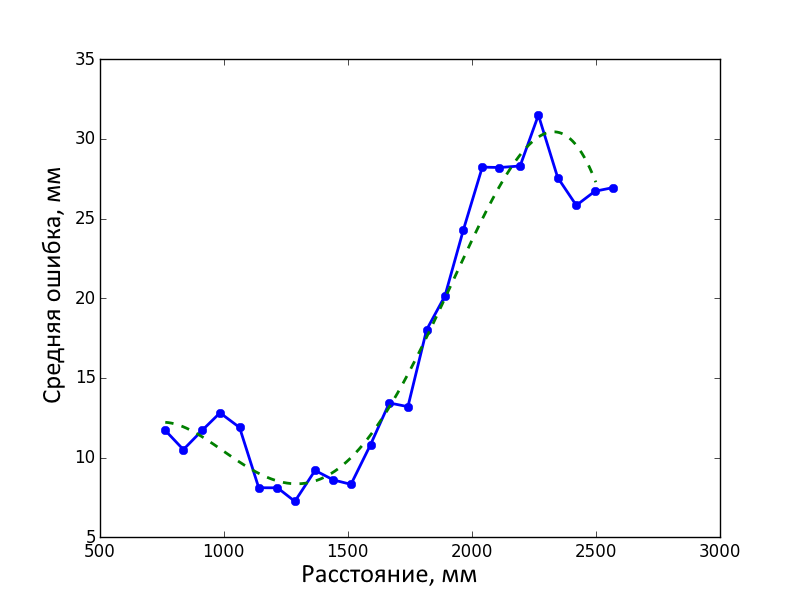
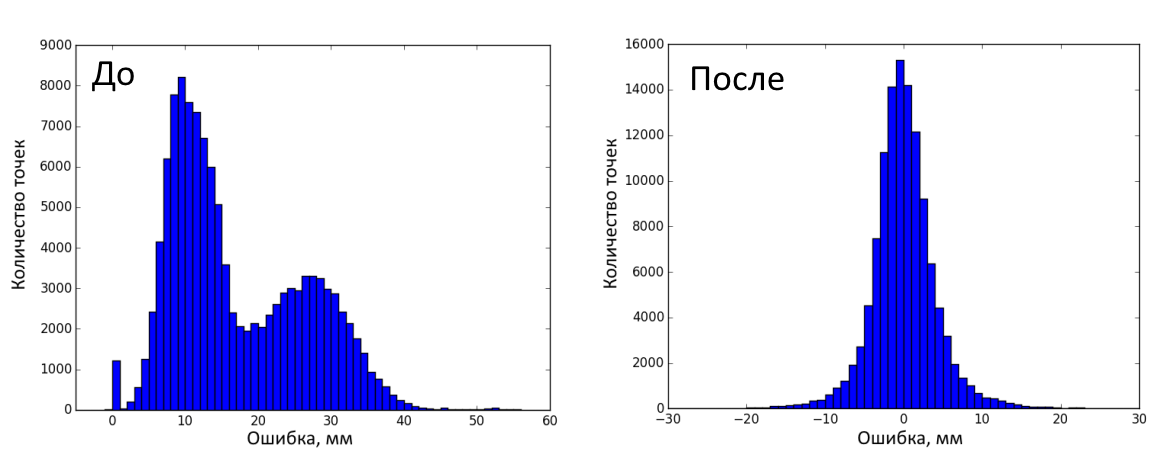
The figure below shows the distribution of errors before and after the correction on the calibration frames. A total of 120,000 measurements were made (25 distances, 100 depth frames at each, 48 key points on the object). The error before correction was 17 ± 9.95 mm (mean ± standard deviation), after - 0.45 ± 8.16 mm.
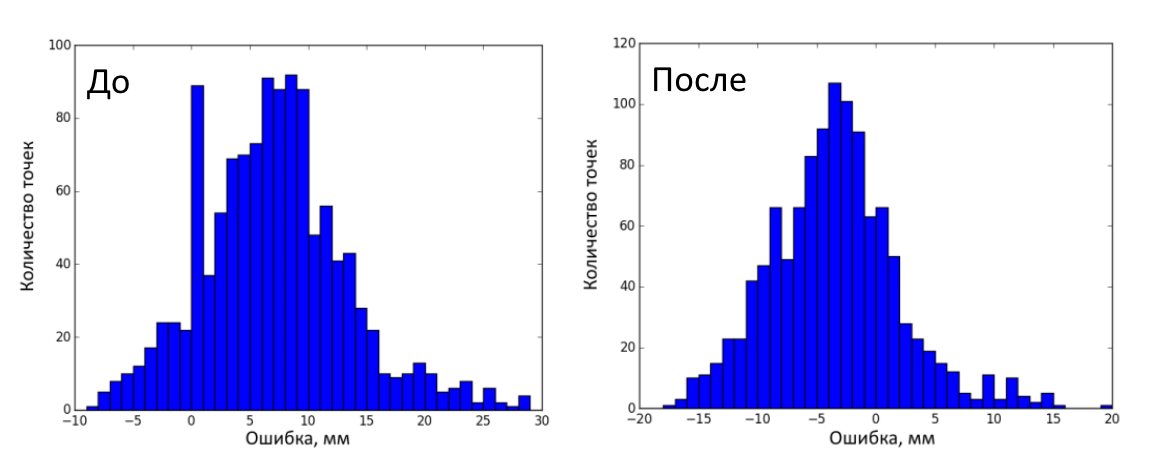
Then 25 test frames (RGB and depth) of the calibration object were made in different positions. Total 1200 measurements (25 frames, 48 key points on each). The error before correction was 7.41 ± 6.32 mm (mean ± standard deviation), after - 3.12 ± 5.50 mm. The figure below shows the distribution of errors before and after correction on test frames.
Thus, we have eliminated the geometric distortions of the RGB camera and the depth sensor, learned how to combine frames, and improved the accuracy of determining the depth. The code for this project can be found here . I hope it will be useful.
The study was carried out by a grant from the Russian Science Foundation (project No. 15-19-30012)
1. Kramer J. Hacking the Kinect / Apress. 2012. P. 130
2. Lachat E. et al. Close Range 3D Modeling, International Remote Sensing and Spatial Information Sciences. 2015
3. Gao XS et al. IEEE Transactions for Analysis and Machine Intelligence. Vol. 25. N 8. 2003. P. 930-943.
Before that, I have never dealt with computer vision, or with OpenCV, or with Kinect. I did not manage to find an exhaustive instruction on how to work with all this farming, so I had to tinker with it in the end. And I decided that it would not be superfluous to systematize the experience gained in this article. Perhaps, it will be useful for some suffering,
Minimum system requirements : Windows 8 and higher, Kinect SDK 2.0, USB 3.0.
')
Table I. Kinect v2 features:
| RGB camera resolution, pix. | 1920 x 1080 |
| Infrared (IR) camera resolution, pix. | 512 x 424 |
| RGB camera viewing angles, º | 84.1 x 53.8 |
| IR camera viewing angles, º | 70.6 x 60.0 |
| Range of measurement range, m | 0.6 - 8.0 1 |
| RGB camera shooting frequency, Hz | thirty |
| IR shooting frequency, Hz | thirty |
one
Information varies from source to source. They say about 0.5–4.5 m., In fact I received ~ 0.6-8.0 m.
Thus, I had the following tasks:
- get Kinect on Python;
- calibrate RGB and IR cameras;
- to realize the possibility of combining RGB and IR frames;
- calibrate the depth channel.
And now we will dwell on each item.
1. Kinect v2 and Python
As I have already said, I hadn’t done anything with computer vision before, but I heard rumors that without the OpenCV library there is nowhere. And since it has a whole camera calibration module , the first thing I did was assemble OpenCV with Python 3 support under Windows 8.1. It was not without some trouble, usually accompanying the assembly of open-source projects on Windows, but everything went without any surprises and in general as part of the instructions from the developers.
I had to tinker a bit longer with Kinect. The official SDK only supports interfaces for C #, C ++ and JavaScript. If you go to the other side, you can see that OpenCV supports input from 3D cameras, but the camera should be compatible with the OpenNI library. OpenNI supports Kinect, but the relatively recent Kinect v2 does not. However, good people wrote a driver for Kinect v2 under OpenNI. It even works and allows you to admire the video from the device channels in NiViewer, but when used with OpenCV crashes. However, other good people wrote a Python wrapper over the official SDK. I stopped at it.
2. Camera Calibration
The cameras are not perfect, they distort the image and need to be calibrated. To use Kinect for measurements, it would be nice to eliminate these geometric distortions on both the RGB camera and the depth sensor. Since the IR camera is also the receiver of the depth sensor, we can use IR frames for calibration, and then use the calibration results to eliminate distortions from the depth frames.
Calibration of the camera is carried out in order to find out the internal parameters of the camera, namely, the camera matrix and the distortion coefficients.
The matrix of the camera is called the matrix of the form:
Where( u , c v ) - coordinates of the principal point (the point of intersection of the optical axis with the image plane, in the ideal camera to be exactly in the center of the image, in real ones it is slightly offset from the center);
f u , f v is the focal length f measured in width and height of a pixel.
There are two main types of distortion: radial distortion and tangential distortion.
Radial distortion - image distortion as a result of the non-ideality of the parabolic lens shape. Distortions caused by radial distortion are 0 in the optical center of the sensor and increase towards the edges. As a rule, radial distortion makes the greatest contribution to image distortion.
Tangential distortion - image distortion caused by errors in the installation of the lens parallel to the image plane.
To eliminate distortion pixel coordinates can be recalculated using the following equation :
where ( u, v ) is the initial location of the pixel,
( u corrected , v corrected ) - the location of the pixel after removing geometric distortions,
k 1 , k 2 , k 3 - the coefficients of radial distortion,
p 1 p 2 - the coefficients of tangential distortion,
r 2 = u 2 + v 2 .
The accuracy of the measurement of camera parameters (distortion coefficients, camera matrix) is determined by the average value of the reprojection error ( ReEr, Reprojection Error ). ReEr is the distance (in pixels) between the projection P ' on the image plane of the point P on the object's surface, and the projection P' 'of the same point P , constructed after eliminating distortion using camera parameters.
The standard camera calibration procedure consists of the following steps:
1) make 20-30 photographs with different positions of the
2) identify the key points of the object in the image;
found, corners = cv2.findChessboardCorners(img, # PATTERN_SIZE,# , 6x8 flags)# 3) find the distortion coefficients that minimize ReEr .
ReEr, camera_matrix, dist_coefs, rvecs, tvecs = cv2.calibrateCamera(obj_points,# #(', y', z'=0) img_points,# (u,v) (w, h),# None,# None, # criteria = criteria,# ReEr flags = flags)# In our case, the average ReEr value for the RGB camera was 0.3 pixels, and for the IR camera - 0.15. The results of the elimination of distortion:
img = cv2.undistort(img, camera_matrix, dist_coefs) 3. Combining frames from two cameras
In order to get both a depth (Z coordinate) for a pixel and a color, first you need to go from pixel coordinates on a depth frame to three-dimensional coordinates of an IR camera [2]:
where ( x 1 , y 1 , z 1 ) are the coordinates of a point in the coordinate system of the IR camera,
z 1 is the result returned by the depth sensor,
( u 1 , v 1 ) - coordinates of the pixel in the depth frame,
c 1, u , c 1, v - coordinates of the optical center of the IR camera,
f 1, u , f 1, v are the projections of the focal length of the IR camera.
Then you need to go from the coordinate system of the IR camera to the coordinate system of the RGB camera. To do this, you need to move the origin using the transfer vector T and rotate the coordinate system using the rotation matrix R :
Then you need to go from the three-dimensional coordinate system of the RGB camera to the pixel coordinates of the RGB frame:
Thus, after all these transformations, we can get for the pixel ( u 1 , v 1 ) of the depth frame the color value of the corresponding pixel of the RGB frame ( u 2 , v 2 ).
As seen in the resulting image, the image is twofold. The same effect can be observed when using the CoordinateMapper class from the official SDK. However, if only a person is interested in the image, then you can use bodyIndexFrame (the Kinect stream, which allows you to find out which pixels belong to a person and which ones to the background) to highlight the region of interest and eliminate ghosting.
To determine the rotation matrix R and the transfer vector T, it is necessary to carry out a joint calibration of the two cameras. To do this, you need to take 20-30 photographs of an object with known geometries in different positions with both RGB and IR cameras, it is better not to hold the object in your hands, in order to exclude the possibility of its displacement between taking pictures with different cameras. Then you need to use the stereoCalibrate function from the OpenCV library. This function determines the position of each camera relative to the calibration object, and then finds such a transformation from the coordinate system of the first camera to the coordinate system of the second camera, which minimizes ReEr.
retval, cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, R, T, E, F = cv2.stereoCalibrate(pattern_points, # # (', y', z'=0) ir_img_points,# (u1, v1) rgb_img_points, # RGB (u2, v2) irCamera['camera_matrix'],# ( calibrateCamera), irCamera['dist_coefs'], #. . ( calibrateCamera) rgbCamera['camera_matrix'], # RGB ( calibrateCamera) rgbCamera['dist_coefs'], #. . RGB ( calibrateCamera) image_size) # ( ) And in the end we got ReEr = 0.23.
4. Channel depth calibration
The Kinect depth sensor returns the depth (namely, depth, i.e., Z-coordinate, not distance) in mm. But how accurate are these values? Judging by the publication [2], the error may be 0.5–3 cm depending on the distance, so it makes sense to calibrate the depth channel.
This procedure is to find the Kinect systematic error (the difference between the reference depth and the depth given by the sensor) depending on the distance to the object. And for this you need to know the reference depth. The most obvious way is to position the flat object parallel to the camera plane and measure the distance to it with a ruler. By gradually moving the object and making a series of measurements at each distance, one can find the average error for each of the distances. But, firstly, it is not very convenient, and secondly, to find a perfectly flat object of relatively large dimensions and to ensure parallelism of its location relative to the plane of the camera is more difficult than it might seem at first glance. Therefore, as a reference against which the error will be calculated, we decided to take the depth, which is determined by the known geometry of the object.
Knowing the geometry of the object (for example, the size of the cells of a chessboard) and placing it strictly parallel to the plane of the chamber, you can determine the depth to it as follows:
where f is the focal length,
d is the distance between the projections of the key points on the camera matrix,
D is the distance between the key points of the object,
Z is the distance from the center of the camera projection to the object.
If the object is located not strictly parallel, but at a certain angle to the camera plane, the depth can be determined based on the solution of the Perspective-n-Point (PnP) problem [3]. A number of algorithms implemented in the OpenCV library that allow you to find the transformation | R, T | between the coordinate system of the calibration object and the coordinate system of the camera, and therefore, determine the depth to the accuracy of the camera parameters.
retval, R, T = cv2.solvePnP(obj_points[:, [0, 5, 42, 47]],# img_points[:, [0, 5, 42, 47]], # rgbCameraMatrix,# rgbDistortion,# flags= cv2.SOLVEPNP_UPNP)# PnP R, jacobian = cv2.Rodrigues(R)# for j in range(0, numberOfPoints): # point = numpy.dot(rgb_obj_points[j], RT) + TT # ! , # , , computedDistance[j] = point[0][2] * 1000 # Z- To calibrate the depth channel, we made a series of surveys of the calibration object at distances of ~ 0.7-2.6 m with a step of ~ 7 cm. The calibration object was located in the center of the frame parallel to the plane of the camera, as far as it is possible to do "by eye". At each distance, one RGB image was taken with a camera and 100 images with a depth sensor. The data from the sensor were averaged, and the distance determined by the geometry of the object based on the RGB frame was taken as the standard. The average error in determining the depth of the Kinect sensor at this distance was determined as follows:
where z i RGB - the distance to the i-th key point in geometry,
z i depth - the distance averaged over 100 frames to the i-th key point according to the depth sensor,
N - the number of key points on the object (in our case 48).
Then we obtained the error function of distance by interpolating the results obtained.
The figure below shows the distribution of errors before and after the correction on the calibration frames. A total of 120,000 measurements were made (25 distances, 100 depth frames at each, 48 key points on the object). The error before correction was 17 ± 9.95 mm (mean ± standard deviation), after - 0.45 ± 8.16 mm.
Then 25 test frames (RGB and depth) of the calibration object were made in different positions. Total 1200 measurements (25 frames, 48 key points on each). The error before correction was 7.41 ± 6.32 mm (mean ± standard deviation), after - 3.12 ± 5.50 mm. The figure below shows the distribution of errors before and after correction on test frames.
Conclusion
Thus, we have eliminated the geometric distortions of the RGB camera and the depth sensor, learned how to combine frames, and improved the accuracy of determining the depth. The code for this project can be found here . I hope it will be useful.
The study was carried out by a grant from the Russian Science Foundation (project No. 15-19-30012)
List of sources
1. Kramer J. Hacking the Kinect / Apress. 2012. P. 130
2. Lachat E. et al. Close Range 3D Modeling, International Remote Sensing and Spatial Information Sciences. 2015
3. Gao XS et al. IEEE Transactions for Analysis and Machine Intelligence. Vol. 25. N 8. 2003. P. 930-943.
Source: https://habr.com/ru/post/272629/
All Articles