Best Pull Request
Relatively recently, I was lucky to join the Atlassian Bitbucket Server development team (until September it was known as Stash ). At some point, I was curious how this product was illuminated on Habré, and to my surprise, there were only a few notes about it, the vast majority of which are now outdated.
In this regard, I decided to try myself as a storyteller and touch on the technical side of Bitbucket. Please do not consider my intention as an attempt to advertise, because I absolutely do not pursue this goal. If this article finds interest from readers, I will be happy to develop the topic and try to answer any questions that may arise.
Let me start by translating Tim Pettersen’s “A better pull request” article on how a pull request should look like in order to most effectively accomplish the task entrusted to it.
If you use Git, then you probably use pull requests. They have existed in one form or another since the advent of distributed version control systems. Before Bitbucket and GitHub offered a convenient web interface, a pull request could be a simple email from Alice asking her to pick up some changes from her repository. If they were worthwhile, you could execute several commands to inject these changes into your master master branch:
Of course, to include changes from Alice in master without looking is not a good idea: after all, master contains the code that you are going to deliver to your customers, and therefore you probably want to carefully monitor what gets into it. A better way than simply incorporating changes into master is to first merge them into a separate branch and analyze before merging into master :
The given git diff command with the syntax of three points (hereinafter referred to as “triple dot” git diff ) will show the changes between the top of the alice / branch and its merge base — a common ancestor with the local master branch, in other words, with a point of divergence in the history of commits of these branches. In essence, these will be exactly the changes that Alice asks us to include in the main branch.

git diff master ... alice / master is equivalent to git diff AB
At first glance, this seems like a reasonable way to check for changes in the pull request. Indeed, at the time of writing, it is this comparison algorithm that is used in the implementation of pull request-s in most tools that provide hosting of git-repositories.
Despite this, there are several problems with using triple dot git diff to analyze changes to the pull request. In a real project, the main branch is likely to be very different from any branch of functionality (hereinafter, the feature branch ). Work on the tasks is carried out in separate branches, which at the end merge into the master . When the master moves forward, a simple git diff from the top of the feature branch to its merge base is not enough to display the real difference between these branches: it will show the difference of the top of the feature branch with only one of the previous master states.

The master branch is promoted through the infusion of new changes. The git diff master ... alice / master result does not reflect these master changes.
Why the impossibility to see these changes during the analysis pull request request is a problem? There are two reasons for this.
The first problem you probably come across regularly is merge conflicts. If in your feature branch you change the file that was at the same time changed in the master , git diff will still only display the changes you made in the feature branch . However, when you try to execute git merge, you will encounter an error: git will place conflict markers in your working copy files, because the merged branches have conflicting changes - such that git cannot resolve even with advanced merge strategies.

Merge conflict
Hardly anyone likes resolving merge conflicts, but they are a given of any version control system, at least one of those that do not support blocking at the file level (which, in turn, has a number of its own problems).
However, merge conflicts are less of a nuisance you may encounter when using the “triple dot” git diff for pull requests, as compared to another problem: a special type of logical conflict will be successfully merged, but it can introduce a cunning error into the code base.
If developers modify different parts of the same file in different branches, there is a possibility that they will create such a conflict. In some cases, various changes that work properly separately and perfectly merge without any conflicts from the point of view of the version control system can introduce a logical error into the code, when applied together.
This can happen in different ways, but the most common option is when two developers accidentally notice and correct the same error in two different branches. Imagine that the following javascript code calculates the cost of an air ticket:
It contains an obvious mistake: the author forgot to include in the calculation of the customs fee!
Now imagine two developers, Alice and Bob, each of whom noticed this error and fixed it independently of the other in its branch.
Alice added a line to register customsFee before immigrationFee :
Bob made a similar edit, but put it after immigrationFee :
Since different lines of code were changed in each of these branches, the merging of both with the master will succeed one after the other. However, now the master will contain both lines added, which means that customers will pay the customs duty twice:
(This is, of course, a far-fetched example, but duplicate code or logic can cause very serious problems: for example, a hole in the implementation of SSL / TLS in iOS .)
Suppose that you first merged the changes to Alice's pull request into the master . This is what Bob’s pull request would show if you used git diff “triple dot” :
Since you are analyzing changes compared to a common ancestor, there is no warning about the threat of an error that happens when you click on the merge button.
In fact, when analyzing the pull request, you would like to see how master changes after merging changes from the Bob branch:
The problem is clearly indicated here. The pull reviewer of the request, hopefully, notices the duplicate line and notifies Bob that the code needs to be refined, and thus prevents a serious error in the master and, ultimately, in the finished product.
Thus, we decided to implement a display of changes in the pull request Bitx into the Bitbucket. When viewing the pull request, you see how the result of the merge will actually look like (that is, in fact, the resulting commit). To accomplish this, we make a real merge of the branches and show the difference between the resulting commit and the top of the target branch of the pull request:

git diff CD , where D is a commit resulting from a merge, shows all the differences between the two branches
If you are interested, I posted the same repository on several hosts, so that you yourself could see the described difference between the comparison algorithms:
The comparison based on the merge commit used in Bitbucket shows the actual changes that will be applied when you perform the merge. The catch is that this algorithm is more difficult to implement and requires significantly more resources to execute.
First, the merge D commit does not actually exist yet, and its creation is a relatively expensive process. Secondly, it is not enough just to create commit D and end there: B and C , parent commits for our merge commit, can change at any time. We call the change of any of the parent commits a revision (rescope) of the pull request, since it essentially modifies the set of changes that will be applied as a result of the merging of the pull request. If your pull request is aimed at a loaded branch like master , it will most likely be reviewed very often.

Merge commits are created each time any of the request request's pull branches changes
In fact, every time someone commits or merges a pull request into a master or feature branch , Bitbucket must create a new merge commit to show the actual difference between the branches in the pull request.
Another problem with merging to display the difference between branches in the pull request is that from time to time you will have to deal with merge conflicts. Since the git server is running in non-interactive mode, there will be no one to resolve such conflicts. This further complicates the task, but in reality it turns out to be an advantage. In Bitbucket, we actually include conflict markers in commit merge D , and then mark them when displaying the difference between branches to explicitly tell you that pull request contains conflicts:
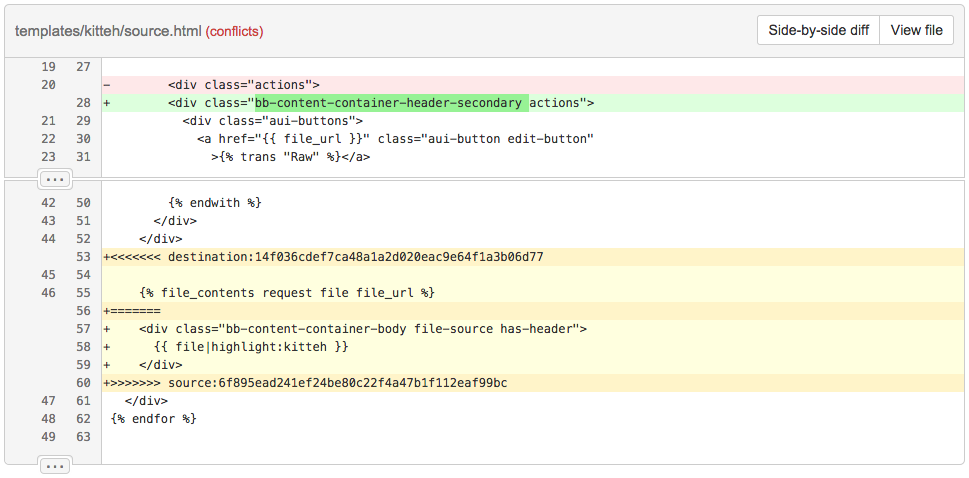
Green lines are added, red lines are deleted, and yellow lines mean conflict.
Thus, we not only reveal in advance that the pull request contains a conflict, but also allow reviewers to discuss exactly how it should be resolved. Since conflict always affects at least two parties, we believe that pull request is the best place to find a suitable way to resolve it.
Despite the added complexity of implementation and the resource-intensiveness of the approach used, I believe that the approach we chose in Bitbucket provides the most accurate and practical difference between the pull request request branches.
The author of the original article, Tim Pettersen, participated in the development of JIRA, FishEye / Crucible and Stash. From the beginning of 2013, he talks about development processes, git, continuous integration and continuous integration / deployment, and Atlassian tools for developers, especially Bitbucket. Tim regularly posts notes about these and other things on Twitter under the pseudonym @kannonboy .
I hope this article was interesting. I will be glad to answer questions and comments.
In this regard, I decided to try myself as a storyteller and touch on the technical side of Bitbucket. Please do not consider my intention as an attempt to advertise, because I absolutely do not pursue this goal. If this article finds interest from readers, I will be happy to develop the topic and try to answer any questions that may arise.
Let me start by translating Tim Pettersen’s “A better pull request” article on how a pull request should look like in order to most effectively accomplish the task entrusted to it.
A small digression about terms
In any Russian-language technical article on version control systems (as, indeed, the majority of any topics related to IT), the author is faced with the need to use specific terms that may or may not be translated into Russian. In life, most of these terms are not translated and are used in verbal communication "as is", that is, in fact, it is transliterated. Strictly speaking, they should be translated in written form, but in this case the terms often completely cease to be consonant with the English-language versions, which greatly complicates their perception by the readers.
')
I would like to use the usual names in writing, but some terms I will not even transliterate, because, in my opinion, they become too clumsy, and therefore leave them in English writing, please understand and forgive. On the other hand, I am open to criticism and suggestions, so if you think that there is a better way to express a particular term, please share these thoughts. Thank.
')
I would like to use the usual names in writing, but some terms I will not even transliterate, because, in my opinion, they become too clumsy, and therefore leave them in English writing, please understand and forgive. On the other hand, I am open to criticism and suggestions, so if you think that there is a better way to express a particular term, please share these thoughts. Thank.
If you use Git, then you probably use pull requests. They have existed in one form or another since the advent of distributed version control systems. Before Bitbucket and GitHub offered a convenient web interface, a pull request could be a simple email from Alice asking her to pick up some changes from her repository. If they were worthwhile, you could execute several commands to inject these changes into your master master branch:
$ git remote add alice git://bitbucket.org/alice/bleak.git $ git checkout master $ git pull alice master Of course, to include changes from Alice in master without looking is not a good idea: after all, master contains the code that you are going to deliver to your customers, and therefore you probably want to carefully monitor what gets into it. A better way than simply incorporating changes into master is to first merge them into a separate branch and analyze before merging into master :
$ git fetch alice $ git diff master...alice/master The given git diff command with the syntax of three points (hereinafter referred to as “triple dot” git diff ) will show the changes between the top of the alice / branch and its merge base — a common ancestor with the local master branch, in other words, with a point of divergence in the history of commits of these branches. In essence, these will be exactly the changes that Alice asks us to include in the main branch.
git diff master ... alice / master is equivalent to git diff AB
At first glance, this seems like a reasonable way to check for changes in the pull request. Indeed, at the time of writing, it is this comparison algorithm that is used in the implementation of pull request-s in most tools that provide hosting of git-repositories.
Despite this, there are several problems with using triple dot git diff to analyze changes to the pull request. In a real project, the main branch is likely to be very different from any branch of functionality (hereinafter, the feature branch ). Work on the tasks is carried out in separate branches, which at the end merge into the master . When the master moves forward, a simple git diff from the top of the feature branch to its merge base is not enough to display the real difference between these branches: it will show the difference of the top of the feature branch with only one of the previous master states.
The master branch is promoted through the infusion of new changes. The git diff master ... alice / master result does not reflect these master changes.
Why the impossibility to see these changes during the analysis pull request request is a problem? There are two reasons for this.
Merge conflicts
The first problem you probably come across regularly is merge conflicts. If in your feature branch you change the file that was at the same time changed in the master , git diff will still only display the changes you made in the feature branch . However, when you try to execute git merge, you will encounter an error: git will place conflict markers in your working copy files, because the merged branches have conflicting changes - such that git cannot resolve even with advanced merge strategies.
Merge conflict
Hardly anyone likes resolving merge conflicts, but they are a given of any version control system, at least one of those that do not support blocking at the file level (which, in turn, has a number of its own problems).
However, merge conflicts are less of a nuisance you may encounter when using the “triple dot” git diff for pull requests, as compared to another problem: a special type of logical conflict will be successfully merged, but it can introduce a cunning error into the code base.
Logical conflicts that go unnoticed during a merge
If developers modify different parts of the same file in different branches, there is a possibility that they will create such a conflict. In some cases, various changes that work properly separately and perfectly merge without any conflicts from the point of view of the version control system can introduce a logical error into the code, when applied together.
This can happen in different ways, but the most common option is when two developers accidentally notice and correct the same error in two different branches. Imagine that the following javascript code calculates the cost of an air ticket:
// flat fees and taxes var customsFee = 5.5; var immigrationFee = 7; var federalTransportTax = .025; function calculateAirfare(baseFare) { var fare = baseFare; fare += immigrationFee; fare *= (1 + federalTransportTax); return fare; } It contains an obvious mistake: the author forgot to include in the calculation of the customs fee!
Now imagine two developers, Alice and Bob, each of whom noticed this error and fixed it independently of the other in its branch.
Alice added a line to register customsFee before immigrationFee :
function calculateAirfare(baseFare) { var fare = baseFare; +++ fare += customsFee; // Fixed it! Phew. Glad we didn't ship that! - Alice fare += immigrationFee; fare *= (1 + federalTransportTax); return fare; } Bob made a similar edit, but put it after immigrationFee :
function calculateAirfare(baseFare) { var fare = baseFare; fare += immigrationFee; +++ fare += customsFee; // Fixed it! Gee, lucky I caught that one. - Bob fare *= (1 + federalTransportTax); return fare; } Since different lines of code were changed in each of these branches, the merging of both with the master will succeed one after the other. However, now the master will contain both lines added, which means that customers will pay the customs duty twice:
function calculateAirfare(baseFare) { var fare = baseFare; fare += customsFee; // Fixed it! Phew. Glad we didn't ship that! - Alice fare += immigrationFee; fare += customsFee; // Fixed it! Gee, lucky I caught that one. - Bob fare *= (1 + federalTransportTax); return fare; } (This is, of course, a far-fetched example, but duplicate code or logic can cause very serious problems: for example, a hole in the implementation of SSL / TLS in iOS .)
Suppose that you first merged the changes to Alice's pull request into the master . This is what Bob’s pull request would show if you used git diff “triple dot” :
function calculateAirfare(baseFare) { var fare = baseFare; fare += immigrationFee; +++ fare += customsFee; // Fixed it! Gee, lucky I caught that one. - Bob fare *= (1 + federalTransportTax); return fare; } Since you are analyzing changes compared to a common ancestor, there is no warning about the threat of an error that happens when you click on the merge button.
In fact, when analyzing the pull request, you would like to see how master changes after merging changes from the Bob branch:
function calculateAirfare(baseFare) { var fare = baseFare; fare += customsFee; // Fixed it! Phew. Glad we didn't ship that! - Alice fare += immigrationFee; +++ fare += customsFee; // Fixed it! Gee, lucky I caught that one. - Bob fare *= (1 + federalTransportTax); return fare; } The problem is clearly indicated here. The pull reviewer of the request, hopefully, notices the duplicate line and notifies Bob that the code needs to be refined, and thus prevents a serious error in the master and, ultimately, in the finished product.
Thus, we decided to implement a display of changes in the pull request Bitx into the Bitbucket. When viewing the pull request, you see how the result of the merge will actually look like (that is, in fact, the resulting commit). To accomplish this, we make a real merge of the branches and show the difference between the resulting commit and the top of the target branch of the pull request:
git diff CD , where D is a commit resulting from a merge, shows all the differences between the two branches
If you are interested, I posted the same repository on several hosts, so that you yourself could see the described difference between the comparison algorithms:
- Pull GitHub request with a "triple dot" comparison git diff
- GitLab pull request with triple dot git diff
- Bitbucket pull request with comparison using merge commit
The comparison based on the merge commit used in Bitbucket shows the actual changes that will be applied when you perform the merge. The catch is that this algorithm is more difficult to implement and requires significantly more resources to execute.
Promotion of branches
First, the merge D commit does not actually exist yet, and its creation is a relatively expensive process. Secondly, it is not enough just to create commit D and end there: B and C , parent commits for our merge commit, can change at any time. We call the change of any of the parent commits a revision (rescope) of the pull request, since it essentially modifies the set of changes that will be applied as a result of the merging of the pull request. If your pull request is aimed at a loaded branch like master , it will most likely be reviewed very often.
Merge commits are created each time any of the request request's pull branches changes
In fact, every time someone commits or merges a pull request into a master or feature branch , Bitbucket must create a new merge commit to show the actual difference between the branches in the pull request.
Handling merge conflicts
Another problem with merging to display the difference between branches in the pull request is that from time to time you will have to deal with merge conflicts. Since the git server is running in non-interactive mode, there will be no one to resolve such conflicts. This further complicates the task, but in reality it turns out to be an advantage. In Bitbucket, we actually include conflict markers in commit merge D , and then mark them when displaying the difference between branches to explicitly tell you that pull request contains conflicts:
Green lines are added, red lines are deleted, and yellow lines mean conflict.
Thus, we not only reveal in advance that the pull request contains a conflict, but also allow reviewers to discuss exactly how it should be resolved. Since conflict always affects at least two parties, we believe that pull request is the best place to find a suitable way to resolve it.
Despite the added complexity of implementation and the resource-intensiveness of the approach used, I believe that the approach we chose in Bitbucket provides the most accurate and practical difference between the pull request request branches.
The author of the original article, Tim Pettersen, participated in the development of JIRA, FishEye / Crucible and Stash. From the beginning of 2013, he talks about development processes, git, continuous integration and continuous integration / deployment, and Atlassian tools for developers, especially Bitbucket. Tim regularly posts notes about these and other things on Twitter under the pseudonym @kannonboy .
I hope this article was interesting. I will be glad to answer questions and comments.
Source: https://habr.com/ru/post/272531/
All Articles