Tale about how we were friends with the billing card
Habr, and hello again! Last year I already wrote one article , after that there were several attempts to write a new one, but everything did not work out. Finally, a more or less formed thought emerged, which I will try to form in the form of a full-fledged article. It will be about working with devices, more precisely about how we were able to connect the database of the equipment used, their geographical location with the billing used. Interested in - under cat.
Unfortunately, I can not remember how it all began. At the time of joining the company, Quantum GIS was already used, and partly the network was mapped. I had to get acquainted with Kugis in connection with the task - to put all the equipment used in the purchased provider (just in the provider I got settled into). I must say, at that time I didn’t understand at all what cards could be used for - well, nothing; my opinion soon changed to the opposite.
In principle, everything is simple, 4 layers:
')
2 tables in Postgre SQL, the first for storing points, the second for lines.
Coupling is a switch, or an important client - defined by the type field. At that time there were several types, and no one thought about possible problems in the future.
Some time passed, the devices were applied. I will not be able to pass on the chronology of events, as they returned to each task several times, each time tightening the nuts. In any case, the applied devices did not give any particularly useful information. Devices continued to roam, port numbers change (I mean installers, who connect a switch to the 25th or 28th port). By and large, at that time we were able to see some problem areas - using utp as highways and overgrown segments (there were also that up to 40 others were connected from one switch, and when the electricity was lost in this house, up to 30 houses). Already at this stage the tasks were set for the heads of the branches to eliminate these jambs.
As for working with the card, we could only use Zabbix, which stupidly pinged the device and tinted those that are not available in red.
As I wrote in the last article, in parallel there was work on the creation of a new shell with increasing functionality for UTM. Breaking the addresses of subscribers by a comma with a space, we obtained a list of settlements, streets and houses. After working with this list we got our own database of addresses. And to the standard UTM table - users added the house_id field, by which we could get the correct address of the subscriber without abbreviations and typos right up to the house. In the new shell, the subscriber's address became a set of selects instead of a single text input. Yes, by the way, KLADR does not coincide with what is written in the passports of subscribers, so we did not use it.
Having received a list of used addresses, we put in order the addresses of the devices on the map. Thus, we received a certain number of subscribers and devices, which coincided house_id. Already something. After analyzing this information, we received a list of houses in which no device is listed, and several subscribers are connected there.
I completely forgot to say that in our case, access to the Internet was provided via a vpn connection, so there are gaps in the equipment used, especially if one provider absorbs another, when part of the state of the purchased provider goes overboard.
So, there is a list of houses without devices and with subscribers. Each case is unique, somewhere a copper transfer to a neighboring house, where an unmanaged switch is connected, etc., etc. All problem areas identified and eliminated. The newly found copper perekidki - a replacement for optics. Next, I will move on to another topic, and summing up the above, I repeat - we returned to these tasks several times and eventually managed to achieve 100% knowledge of the state of the network.
Next, I think it is worth talking about the logical component of the process. In general, it’s probably a good idea to write a separate post about setting up switches, but you can’t show some aspects in this topic - I’lln’t open the topic differently.
Speaking of the fact that we were able to identify overgrown segments, I assume that we have already defined some standards. Yes, they are. I will try to list them briefly, but if something is unclear - ask in the comments, I will answer with pleasure.
Thus, in each segment we can theoretically connect up to 240 subscribers, in practice there are no such numbers (the maximum numbers fluctuate around 50-60 subscribers).
Now the network meets the requirements that have been listed. Yes, these requirements are not without drawbacks, but nevertheless we get a fully managed and structured network. In connection with the introduction of gpon, some adjustments are made, but I will not dwell on them.
At the time when these postulates were formed, the addresses of the switches were assigned by the command of a switch. At the very beginning there was a case when one administrator set up a switch in one locality, I was in another, eventually occupied the same ip-address. We had to do something about it.
But besides the separation by segments, we must define a uniform model of iron operation globally, throughout the network. Distinctly deposited in memory, as I was taught to configure switches. There were several text files with examples of configs for different hardware, and there were several configs for each specific device and, in principle, identical hardware (for example, DES 3028 and 3200-28) was configured differently. There is a time setting here, not here; there is an ACL, and there is, but different.
In 2011, there were severe thunderstorms in the Tver region, part of the switch ports throughout the network was stalled, the network fell by 30-40 percent. It went down because at least the brains of the switches did not suffer, the looping ports did their job - 100% load on the processor and the switch no longer wants to communicate with us. 2 weeks of sleepless nights (without exaggeration) - installers did not have time to transport switches to the office, so we had to wait for those moments when the switch at the installation site still came to life for some moments, running into it and setting the storm control just from the buffer. This and other examples have done their job - other standards have been formed. Scripts filled the necessary configs throughout the network, the problems have disappeared. Yes, last year the UPS was installed on all transit switches; the difference before and after cannot be described. Zabbix began to call many times less. In addition to solving the problem of power outages, they also solved the problem with thunderstorms - it is cheaper to change Rapan than a switchboard.
With this sorted out. The next logical step is to remove the mac-addresses on the switch ports. Knowing the mac-addresses of subscribers, they were able to determine who is on which port. The shoals resurfaced. It turns out that there is a managed 24-port switch, 7 subscribers, the 2nd on the 1st port, the 3rd on the 7th, and several ports are scattered. Yeah, again, five-port hubs. Well, yes, the installers in the panel set, so that the second utp subscriber should not be dragged to the floor. We liquidate. Put things in order. Subscribers peretyavali. Observe, or rather go ahead. Wham! Go back. It turns out that in one of the cities installers who are on a deal are those that are only on connections, when a new subscriber is turned on, so that they take less time to spend and pull out an already working subscriber from the port (visually it can be seen - it works) and this port includes a new, and working anywhere. They are not responsible for this. At another installer a request pops up - the subscriber has lost the Internet. The reason, I think, is clear. They inserted such lyuley to the head of the branch and his mutt that some of these workers had gone. Good lesson to the rest. I saved a screenshot somewhere (looking for laziness), for about ten days - 7 subscribers in one port visited (the new house was included). Looking ahead, I will say - at that time we had already tested the system - when choosing the address of the subscriber, only certain switches were offered. And when choosing a switch, ports with marks were suggested (free / burned / busy / hub) —that is, You can select any port, but there will be a warning. As soon as the port is selected and if it is not marked in the system as burned out, the command to enable the port is sent to the switch. There are many aspects, I will not pay attention to them. In general, in this city, with the permission of the founders, we included this system. Installers ran in the soap - checked all subscribers who have lost the Internet. Yes, it was, let's say, rude in relation to subscribers, and I am usually an ardent opponent of experiments with subscribers, who, for their part, fulfill their monthly payment obligations, but everything was done for them. So, within a few days, we got a tough binding of subscribers by ports and forced the installers to work according to the regulations. Summarizing the topic of binding to ports, I can say that throughout the entire network, the impb bindings have been created, all unused ports are turned off. For each subscriber, we can tell the migration to the ports.
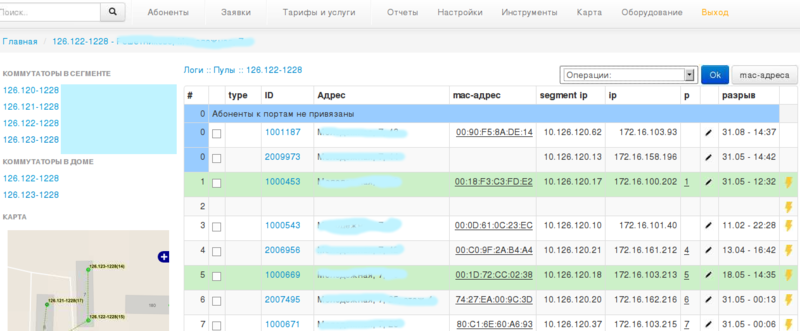
Before proceeding further, I want to return to what has already been said, mark what has been achieved and reveal what remains to be decided.
We have:
From the above postulates, we determine that the ip-address of the iron determines the ip-address of the subscriber. From this it follows that in the table of subscribers we store the device as an ip-address. But the ip-address is just one of the device parameters stored in the devices table. The main identifier in it has always been gid. But gid implies a change - the device can be removed, and a new one is installed instead, with the same ip address assigned to it. By the way, I'm working on this task now.
We mark the ports as burned out and they will never be turned on, more precisely, until the device is returned for repair and it comes back with the note “restored”. But sending the device for repair, it can be removed from the card (could), and all information will be lost. Today, now, we do not know which field and where is more important. Unfortunately, not all devices have a serial number (in my opinion, even devices returned from repair with an erased sn, I mean, not a piece of paper, of course), but we all have the necessary devices. Therefore, with PostgreSQL triggers, I write all events to the log with indication of all the fields (both gid, and ip, and sn, and mac). Marks about the burned ports are stored in a table with reference to the mac-address.
Now about the map. Initially, any person could put a point in a kugis. Today this operation is prohibited by triggers in the database. All work with iron moved to the web interface. There is the concept of “warehouse” (there are several of them, according to the number of branch offices), adding devices is allowed to certain individuals, indicating the mac-address, serial number and model of the device. Any sneeze, as I said, is written to the log. Moreover, Zabbix regularly removes all parameters from the hardware, so unauthorized replacement of the switch leads to the fact that the subscribers will not be able to work, and the manager will insert a piston. In the comments to the last article, as far as I remember, there was a comment that it is impossible to build such a system. Maybe. Tighten the screws, punish the perpetrators, and everything.
Further, the device ip-address is generally a magic variable. It is tracked in several systems, including when forming the configuration file. Yes, we have shifted this work to the script. The script for the ip-address creates a config and it only remains to fill in for a while, and in the future it will be automatically poured so that you don’t see anything extra. So, if preliminary preparation with the device transfer to the desired point (the place of future deployment) was not made on the map, the config will not be generated. So I went to the next item.
The fact is that initially, all these lines, polygons and points on the map were not connected in any way. There was an OSM substrate, there were 4 layers, about which I wrote above and that's it. Sketching a couple of triggers to change the geometry of the point (read the device) and adjusting the snapping when drawing, we were able to glue the lines of connections to the devices. Thus, when moving on the device map, the contact point of the “link” with the device also changes. The so-called links are tied to the equipment (exactly like the optics to the couplings) by several parameters. First, geometrically, the starting or ending point of the line must coincide with the coordinates of the device point. Secondly, there are fields dstart, dstartport, dend, dendport, which determine from which device and port to which device and port this link goes. I had to tinker with this task - check all the drawn lines, all the devices, check the geometries, the entered values, then hang the triggers and enjoy the result.
Picture before changing device coordinates:
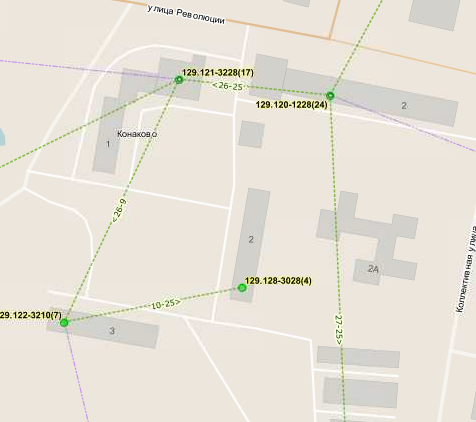
and after:
Now, analyzing the mac-addresses on the switch ports and knowing the mac-addresses of devices and subscribers, we can see which information in these links is not reliable. Thanks to this system, you can visually see which traffic flows between the switches, which ports are used for highways, which wilan are forwarded, etc. etc. All this information is also used when creating a device config. Now, in order to bind the second subscriber to the port of the managed switch, you need to indicate on the card the device from which the connection will be made and put a link from the managed switch to this stupid piece of iron. What to do, there are such situations - the 25th subscriber, and 24 ports, but we need to know about it. Otherwise, the subscriber will not be able to bind to the port, and therefore the impb record will not be created and this subscriber will not be able to work.
Actually, this cannot be called the end of the article, but what to do is to go for a daughter (today is a short day in the kindergarten), and if I save it in the draft in the half-word, then I’ll go back once again to delete what I wrote.
I have already brought several sub-results, so I will not repeat on the details. We were able to connect 2 completely unrelated systems into one and as a result we received automatic equipment configuration (we have three different types of configurations for each switch). Of course, this is not all:
and many, many other things.
I understand that the article, like the last time, turned out to be somewhat blurred, but I cannot clearly describe all the processes that occur within the company. If any topic requires more detailed consideration, please contact - I will answer.
Unfortunately, I can not remember how it all began. At the time of joining the company, Quantum GIS was already used, and partly the network was mapped. I had to get acquainted with Kugis in connection with the task - to put all the equipment used in the purchased provider (just in the provider I got settled into). I must say, at that time I didn’t understand at all what cards could be used for - well, nothing; my opinion soon changed to the opposite.
In principle, everything is simple, 4 layers:
')
- Devices (switches, media converters, servers, etc.);
- Logical connections (where the signal is coming from);
- Couplings, splice cassettes;
- Cable: optics and copper (if used as highways).
2 tables in Postgre SQL, the first for storing points, the second for lines.
Coupling is a switch, or an important client - defined by the type field. At that time there were several types, and no one thought about possible problems in the future.
Some time passed, the devices were applied. I will not be able to pass on the chronology of events, as they returned to each task several times, each time tightening the nuts. In any case, the applied devices did not give any particularly useful information. Devices continued to roam, port numbers change (I mean installers, who connect a switch to the 25th or 28th port). By and large, at that time we were able to see some problem areas - using utp as highways and overgrown segments (there were also that up to 40 others were connected from one switch, and when the electricity was lost in this house, up to 30 houses). Already at this stage the tasks were set for the heads of the branches to eliminate these jambs.
As for working with the card, we could only use Zabbix, which stupidly pinged the device and tinted those that are not available in red.
As I wrote in the last article, in parallel there was work on the creation of a new shell with increasing functionality for UTM. Breaking the addresses of subscribers by a comma with a space, we obtained a list of settlements, streets and houses. After working with this list we got our own database of addresses. And to the standard UTM table - users added the house_id field, by which we could get the correct address of the subscriber without abbreviations and typos right up to the house. In the new shell, the subscriber's address became a set of selects instead of a single text input. Yes, by the way, KLADR does not coincide with what is written in the passports of subscribers, so we did not use it.
Having received a list of used addresses, we put in order the addresses of the devices on the map. Thus, we received a certain number of subscribers and devices, which coincided house_id. Already something. After analyzing this information, we received a list of houses in which no device is listed, and several subscribers are connected there.
I completely forgot to say that in our case, access to the Internet was provided via a vpn connection, so there are gaps in the equipment used, especially if one provider absorbs another, when part of the state of the purchased provider goes overboard.
So, there is a list of houses without devices and with subscribers. Each case is unique, somewhere a copper transfer to a neighboring house, where an unmanaged switch is connected, etc., etc. All problem areas identified and eliminated. The newly found copper perekidki - a replacement for optics. Next, I will move on to another topic, and summing up the above, I repeat - we returned to these tasks several times and eventually managed to achieve 100% knowledge of the state of the network.
Next, I think it is worth talking about the logical component of the process. In general, it’s probably a good idea to write a separate post about setting up switches, but you can’t show some aspects in this topic - I’lln’t open the topic differently.
Speaking of the fact that we were able to identify overgrown segments, I assume that we have already defined some standards. Yes, they are. I will try to list them briefly, but if something is unclear - ask in the comments, I will answer with pleasure.
- The equipment is in networks 192.168.x.0 / 24;
- Each switch 192.168.x.1 sets as many segments as gigabit ports it has (no more than 24). For example, D-Link DGS 3627G - 24 segments. x - let's say, network number (grows with each L3);
- Each segment consists of no more than 10 devices with no more than 240 subscriber ports;
- Each segment begins with a switch, whose ip-address is formed according to the principle: 192.168.x.y0, where y is the port number of the L3 from which the segment is connected. For example, for the L3 switch with the IP address 192.168.37.1, the hive on port 19 will start with the switch 192.168.37.190 (that is, the last number in the address of the first device will always be a multiple of 10);
- The remaining switches in the segment (no more than the remaining 9 out of 10 managed) receive the addresses 192.168.x.y1-192.168.x.y9;
- The first switch in the segment specifies the ip-addresses of subscribers connected in this segment as follows: 10.x.y0.n, where n is the subscriber's sequence number, grows with the number of subscribers in the segment. We added some restriction, n cannot be less than 10 (one is the gateway, the rest are kept in reserve just in case), i.e. subscribers connected from the switches 192.168.37.190-192.168.37.199 - get the address 10.137.190.10-10.137.190.249;
- The entire control network is rendered into a separate vlan, vlan is also allocated to each subscriber segment (they have no relation to this article, therefore I will not dwell on them).
Thus, in each segment we can theoretically connect up to 240 subscribers, in practice there are no such numbers (the maximum numbers fluctuate around 50-60 subscribers).
Now the network meets the requirements that have been listed. Yes, these requirements are not without drawbacks, but nevertheless we get a fully managed and structured network. In connection with the introduction of gpon, some adjustments are made, but I will not dwell on them.
At the time when these postulates were formed, the addresses of the switches were assigned by the command of a switch. At the very beginning there was a case when one administrator set up a switch in one locality, I was in another, eventually occupied the same ip-address. We had to do something about it.
But besides the separation by segments, we must define a uniform model of iron operation globally, throughout the network. Distinctly deposited in memory, as I was taught to configure switches. There were several text files with examples of configs for different hardware, and there were several configs for each specific device and, in principle, identical hardware (for example, DES 3028 and 3200-28) was configured differently. There is a time setting here, not here; there is an ACL, and there is, but different.
In 2011, there were severe thunderstorms in the Tver region, part of the switch ports throughout the network was stalled, the network fell by 30-40 percent. It went down because at least the brains of the switches did not suffer, the looping ports did their job - 100% load on the processor and the switch no longer wants to communicate with us. 2 weeks of sleepless nights (without exaggeration) - installers did not have time to transport switches to the office, so we had to wait for those moments when the switch at the installation site still came to life for some moments, running into it and setting the storm control just from the buffer. This and other examples have done their job - other standards have been formed. Scripts filled the necessary configs throughout the network, the problems have disappeared. Yes, last year the UPS was installed on all transit switches; the difference before and after cannot be described. Zabbix began to call many times less. In addition to solving the problem of power outages, they also solved the problem with thunderstorms - it is cheaper to change Rapan than a switchboard.
With this sorted out. The next logical step is to remove the mac-addresses on the switch ports. Knowing the mac-addresses of subscribers, they were able to determine who is on which port. The shoals resurfaced. It turns out that there is a managed 24-port switch, 7 subscribers, the 2nd on the 1st port, the 3rd on the 7th, and several ports are scattered. Yeah, again, five-port hubs. Well, yes, the installers in the panel set, so that the second utp subscriber should not be dragged to the floor. We liquidate. Put things in order. Subscribers peretyavali. Observe, or rather go ahead. Wham! Go back. It turns out that in one of the cities installers who are on a deal are those that are only on connections, when a new subscriber is turned on, so that they take less time to spend and pull out an already working subscriber from the port (visually it can be seen - it works) and this port includes a new, and working anywhere. They are not responsible for this. At another installer a request pops up - the subscriber has lost the Internet. The reason, I think, is clear. They inserted such lyuley to the head of the branch and his mutt that some of these workers had gone. Good lesson to the rest. I saved a screenshot somewhere (looking for laziness), for about ten days - 7 subscribers in one port visited (the new house was included). Looking ahead, I will say - at that time we had already tested the system - when choosing the address of the subscriber, only certain switches were offered. And when choosing a switch, ports with marks were suggested (free / burned / busy / hub) —that is, You can select any port, but there will be a warning. As soon as the port is selected and if it is not marked in the system as burned out, the command to enable the port is sent to the switch. There are many aspects, I will not pay attention to them. In general, in this city, with the permission of the founders, we included this system. Installers ran in the soap - checked all subscribers who have lost the Internet. Yes, it was, let's say, rude in relation to subscribers, and I am usually an ardent opponent of experiments with subscribers, who, for their part, fulfill their monthly payment obligations, but everything was done for them. So, within a few days, we got a tough binding of subscribers by ports and forced the installers to work according to the regulations. Summarizing the topic of binding to ports, I can say that throughout the entire network, the impb bindings have been created, all unused ports are turned off. For each subscriber, we can tell the migration to the ports.
Before proceeding further, I want to return to what has already been said, mark what has been achieved and reveal what remains to be decided.
We have:
- Device table;
- 3 tables with settlements (here and there areas and districts), streets and houses (or other objects);
- Table subscribers.
From the above postulates, we determine that the ip-address of the iron determines the ip-address of the subscriber. From this it follows that in the table of subscribers we store the device as an ip-address. But the ip-address is just one of the device parameters stored in the devices table. The main identifier in it has always been gid. But gid implies a change - the device can be removed, and a new one is installed instead, with the same ip address assigned to it. By the way, I'm working on this task now.
We mark the ports as burned out and they will never be turned on, more precisely, until the device is returned for repair and it comes back with the note “restored”. But sending the device for repair, it can be removed from the card (could), and all information will be lost. Today, now, we do not know which field and where is more important. Unfortunately, not all devices have a serial number (in my opinion, even devices returned from repair with an erased sn, I mean, not a piece of paper, of course), but we all have the necessary devices. Therefore, with PostgreSQL triggers, I write all events to the log with indication of all the fields (both gid, and ip, and sn, and mac). Marks about the burned ports are stored in a table with reference to the mac-address.
Now about the map. Initially, any person could put a point in a kugis. Today this operation is prohibited by triggers in the database. All work with iron moved to the web interface. There is the concept of “warehouse” (there are several of them, according to the number of branch offices), adding devices is allowed to certain individuals, indicating the mac-address, serial number and model of the device. Any sneeze, as I said, is written to the log. Moreover, Zabbix regularly removes all parameters from the hardware, so unauthorized replacement of the switch leads to the fact that the subscribers will not be able to work, and the manager will insert a piston. In the comments to the last article, as far as I remember, there was a comment that it is impossible to build such a system. Maybe. Tighten the screws, punish the perpetrators, and everything.
Further, the device ip-address is generally a magic variable. It is tracked in several systems, including when forming the configuration file. Yes, we have shifted this work to the script. The script for the ip-address creates a config and it only remains to fill in for a while, and in the future it will be automatically poured so that you don’t see anything extra. So, if preliminary preparation with the device transfer to the desired point (the place of future deployment) was not made on the map, the config will not be generated. So I went to the next item.
The fact is that initially, all these lines, polygons and points on the map were not connected in any way. There was an OSM substrate, there were 4 layers, about which I wrote above and that's it. Sketching a couple of triggers to change the geometry of the point (read the device) and adjusting the snapping when drawing, we were able to glue the lines of connections to the devices. Thus, when moving on the device map, the contact point of the “link” with the device also changes. The so-called links are tied to the equipment (exactly like the optics to the couplings) by several parameters. First, geometrically, the starting or ending point of the line must coincide with the coordinates of the device point. Secondly, there are fields dstart, dstartport, dend, dendport, which determine from which device and port to which device and port this link goes. I had to tinker with this task - check all the drawn lines, all the devices, check the geometries, the entered values, then hang the triggers and enjoy the result.
Picture before changing device coordinates:
and after:
Now, analyzing the mac-addresses on the switch ports and knowing the mac-addresses of devices and subscribers, we can see which information in these links is not reliable. Thanks to this system, you can visually see which traffic flows between the switches, which ports are used for highways, which wilan are forwarded, etc. etc. All this information is also used when creating a device config. Now, in order to bind the second subscriber to the port of the managed switch, you need to indicate on the card the device from which the connection will be made and put a link from the managed switch to this stupid piece of iron. What to do, there are such situations - the 25th subscriber, and 24 ports, but we need to know about it. Otherwise, the subscriber will not be able to bind to the port, and therefore the impb record will not be created and this subscriber will not be able to work.
Actually, this cannot be called the end of the article, but what to do is to go for a daughter (today is a short day in the kindergarten), and if I save it in the draft in the half-word, then I’ll go back once again to delete what I wrote.
I have already brought several sub-results, so I will not repeat on the details. We were able to connect 2 completely unrelated systems into one and as a result we received automatic equipment configuration (we have three different types of configurations for each switch). Of course, this is not all:
- The types of objects used (couplings, switches, etc.) were divided twice (base classes, and more detailed implementations of each class);
- The devices on the map calculated the id of houses from OSM, expanded their own table of houses, adding osm_id and osm_geometry there (and thus we know the edits of the houses of interest to us);
- Part of the houses not existing in the OSM project;
- Added the ability for one switch to participate in several segments (this is when 2 providers use one switch);
- Transferred subscribers from vpn to ipoe (only with a link to mac-address).
and many, many other things.
I understand that the article, like the last time, turned out to be somewhat blurred, but I cannot clearly describe all the processes that occur within the company. If any topic requires more detailed consideration, please contact - I will answer.
Source: https://habr.com/ru/post/272349/
All Articles