Kudu - a new data storage engine in the Hadoop ecosystem

Kudu was one of the new products presented by Cloudera at the “Strata + Hadoop World 2015” conference. This is a new big data storage engine created to cover a niche between two existing engines: the HDFS distributed file system and the Hbase column database.
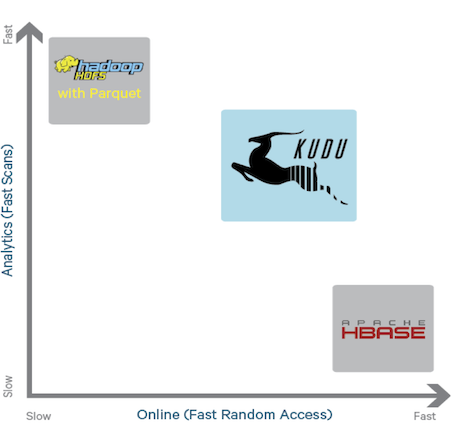
Currently existing engines are not without flaws. HDFS, coping well with large data scanning operations, shows poor results in search operations. C Hbase everything is exactly the opposite. In addition, HDFS has an additional limitation, namely, it does not allow to modify the already recorded data. The new engine, according to the developers, has the advantages of both existing systems:
- quick response search operations
- possibility of modification
- high performance when scanning large amounts of data
Some variants of using Kudu can be time series analysis, analysis of logs and sensory data. Currently, systems that use Hadoop for such things have a rather complex architecture. As a rule, data are in several repositories simultaneously (the so-called “Lambda architecture”). It is necessary to solve a number of tasks on data synchronization between storages (inevitably there is a lag with which, as a rule, they simply accept and live). It is also necessary to configure data access security policies for each storage separately. And the rule “the simpler - the more reliable” has not been canceled. Using Kudu instead of several simultaneous repositories, you can significantly simplify the architecture of such systems.
')
Kudu features:
- High performance when scanning large amounts of data
- Fast response time in search operations
- Column DB, type CP in the CAP theorem, supports several levels of data consistency
- Support “update”
- Record level transactions
- Fault tolerance
- Adjustable level of data redundancy (for data safety in case of failure of one of the nodes)
- API for C ++, Java and Python. Access from Impala, Map / Reduce, Spark is supported.
- Open source. Apache License
SOME INFORMATION ABOUT ARCHITECTURE
Kudu cluster consists of two types of services: master - a service responsible for managing metadata and coordination between nodes; tablet is a service installed on each node for data storage. There can be only one active master in a cluster. For fault tolerance, several more master services can be run in standby mode. Tablet servers break down data into logical partitions (called “tablets”).

From the user's point of view, data in Kudu is stored in tables. For each table, it is necessary to determine the structure (rather unusual approach for NoSQL databases). In addition to columns and their types, the user must define a primary key and partitioning policy.
Unlike other components of the ecosystem, Hadoop Kudu does not use HDFS for data storage. The OS file system is used (ext4 or XFS is recommended). In order to guarantee the safety of data in case of failure of single nodes, Kudu replicates data between servers. Typically, each tablet is stored on three servers (however, only one of the three servers accepts write operations, the rest accept read-only operations). Synchronization between tablet-a replicas is implemented using the raft protocol.
THE FIRST STEPS
Let's try to work with Kudu from the user's point of view. Create a table and try to access it using SQL and Java API.
To fill the table with data, use this open dataset:
https://raw.githubusercontent.com/datacharmer/test_db/master/load_employees.dump
Currently, Kudu does not have its client console. To create the table, we will use the Impala console (impala-shell).
First of all, let's create the “employees” table with data storage in HDFS:
CREATE TABLE employees ( emp_no INT, birth_date STRING, first_name STRING, last_name STRING, gender STRING, hire_date STRING ); We load dataset on the machine with the impala-shell client and import the data into the table:
impala-shell -f load_employees.dump After the command completes execution, run the impala-shell again and run the following query:
create TABLE employees_kudu TBLPROPERTIES( 'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler', 'kudu.table_name' = 'employees_kudu', 'kudu.master_addresses' = '127.0.0.1', 'kudu.key_columns' = 'emp_no' ) AS SELECT * FROM employees; This query will create a table with similar fields, but with Kudu as storage. Using the “AS SELECT” in the last line, copy the data from HDFS to Kudu.
Without exiting the impala-shell, run several SQL queries to the newly created table:
[vm.local:21000] > select gender, count(gender) as amount from employees_kudu group by gender; +--------+--------+ | gender | amount | +--------+--------+ | M | 179973 | | F | 120051 | +--------+--------+ It is possible to make requests to both storages (Kudu and HDFS) at the same time:
[vm.local:21000] > select employees_kudu.* from employees_kudu inner join employees on employees.emp_no=employees_kudu.emp_no limit 2; +--------+------------+------------+-----------+--------+------------+ | emp_no | birth_date | first_name | last_name | gender | hire_date | +--------+------------+------------+-----------+--------+------------+ | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | +--------+------------+------------+-----------+--------+------------+ Now we will try to reproduce the results of the first request (counting male and female employees) using the Java API. Here is the code:
import org.kududb.ColumnSchema; import org.kududb.Schema; import org.kududb.Type; import org.kududb.client.*; import java.util.ArrayList; import java.util.List; public class KuduApiTest { public static void main(String[] args) { String tableName = "employees_kudu"; Integer male = 0; Integer female = 0; KuduClient client = new KuduClient.KuduClientBuilder("localhost").build(); try { KuduTable table = client.openTable(tableName); List<String> projectColumns = new ArrayList<>(1); projectColumns.add("gender"); KuduScanner scanner = client.newScannerBuilder(table) .setProjectedColumnNames(projectColumns) .build(); while (scanner.hasMoreRows()) { RowResultIterator results = scanner.nextRows(); while (results.hasNext()) { RowResult result = results.next(); if (result.getString(0).equals("M")) { male += 1; } if (result.getString(0).equals("F")) { female += 1; } } } System.out.println("Male: " + male); System.out.println("Female: " + female); } catch (Exception e) { e.printStackTrace(); } finally { try { client.shutdown(); } catch (Exception e) { e.printStackTrace(); } } } } After compiling and running, we get the following result:
java -jar kudu-api-test-1.0.jar [New I/O worker #1] INFO org.kududb.client.AsyncKuduClient - Discovered tablet Kudu Master for table Kudu Master with partition ["", "") [New I/O worker #1] INFO org.kududb.client.AsyncKuduClient - Discovered tablet f98e05a4bbbe49528f38b5a46ef3a7a4 for table employees_kudu with partition ["", "") Male: 179973 Female: 120051 As you can see, the result is the same as the one that issued the SQL query.
CONCLUSION
For big data systems, in which both analytical operations on the entire volume of stored data and the search operation with fast response time are performed, Kudu seems to be a natural candidate as a data storage engine. Thanks to its numerous APIs, it is well integrated into the Hadoop ecosystem. In conclusion, it should be said that at the moment Kudu is under active development and is not ready for use in production.
Source: https://habr.com/ru/post/272267/
All Articles