Haskell "terrible" abstractions without mathematics and without code (almost). Part I
- What are monads for?
- To separate clean calculations from side effects.
(from online discussions about Haskell)
Sherlock Holmes and Dr. Watson are flying in a balloon. Fall into thick fog and lose orientation. There is a small gap - and they see a person on earth.
- Dear, would you tell me where we are?
- In the balloon basket, sir.
Then they are carried further and again they see nothing.
“It was a mathematician,” says Holmes.
- But why?
- His answer is completely accurate, but absolutely useless.
(joke)
When the ancient Egyptians wanted to write that they counted 5 fish, they drew 5 fish figures. When they wanted to write that they counted 70 people, they painted 70 figures of people. When they wanted to write that they counted 300 sheep in a herd, they ... - well, in general, you understood. So the ancient Egyptians suffered, until the cleverest and lazy of them saw something in common in all these records, and separated the concept of the quantity of what we count from the properties of what we count. And then another smart lazy Egyptian replaced a lot of sticks, which people used to designate a quantity, with a significantly smaller number of signs, a short combination of which could replace a huge amount of sticks.
What these clever lazy Egyptians have done is called abstraction. They noticed something in common, which is characteristic of all records about the amount of something, and separated this general from the particular properties of the counted objects. If you understand the meaning of this abstraction, which we call numbers today, and how much it has made life easier for people, then it will not be difficult for you to understand the Haskell abstractions - all these seemingly incomprehensible functors, monoids, applicative functors and monads. Despite their frightening names, which came to us from the mathematical theory of categories, it is no more difficult to understand them than the abstraction called “numbers”. To understand them, it is absolutely not necessary to know either the theory of categories, or even mathematics in the volume of high school (arithmetic is quite enough). And they can also be explained without resorting to frightening many mathematical concepts. And the meaning of Haskell language abstractions is exactly the same as that of numbers - they make life much easier for programmers (and you can’t even imagine how much!).
Differences of functional and imperative programs
Discover the benefits of pure features.
Calculations and “something else”
Something else encapsulation
The functor is not easy, but very simple!
Applicative functors are also very simple!
You will laugh, but monads are also simple!
And let's define a couple more monads
We use monads
We define the Writer monad and get acquainted with monoids.
Monoids and laws of functors, applicative functors and monads
Classes of types: dozens of functions for free!
Input-output: IO monad
In order to understand (and accept) abstractions, people usually need to look at them from several sides:
')
First, they need to understand that the introduction of an additional level of complexity in the form of the proposed abstraction eliminates a much greater level of complexity with which they constantly encounter. Therefore, I will describe the huge number of problems that programmers will no longer face using pure functions (do not worry, I will explain below what it is) and the described abstractions.
Secondly, people need to understand how the proposed abstraction was implemented, and how this implementation allows it to be used not in a particular case, but in a huge variety of different situations. Therefore, I will describe to you the logic behind the implementation of Haskell language abstractions, and show that they are not only applicable, but also provide significant advantages in an incredible number of situations.
And, thirdly, people need to understand not only how abstractions are implemented, but how to apply them in their daily lives. Therefore, I will describe in the article and this. Moreover, it is not easy, but very simple - even easier than to understand how these abstractions are implemented (and you yourself will see that it is quite easy to understand the implementation of the described abstractions).
However, the introduction was somewhat delayed, so, perhaps, let's start. I’ll just add that there’s very little code in the article, so you don’t have to be familiar with the Haskell syntax to understand and appreciate the beauty and power of its abstractions.
Disclaimer
I am not an experienced Haskell programmer. I really like this language, and at the moment I am still in the process of learning it (this is not the fastest process, because it requires not only mastery of knowledge, but also a restructuring of thinking). Recently, I have several times had to talk about functional programming and about Haskell programmers who are familiar only with imperative programming languages. In the process, I realized that I should work on a clearer and more structured explanation of the basic abstractions of Haskell, which usually cause awe of those who are not familiar with them. This material is just an attempt at such structuring. I will be glad if you, the readers, point out to me both the possible inaccuracies of my presentation, and those moments that you did not understand well enough.
Differences of functional and imperative programs
If you look at programs written in functional and imperative languages, from a bird's-eye view, they are no different. And those and other programs are some kind of black box, which takes the original data and outputs other data converted from the original. The differences we will see when we want to look inside the black boxes, to understand exactly how the data conversion takes place in them.
Looking into the imperative black box, we see that the data included in it is assigned to variables, and then these variables are repeatedly sequentially changed, until we get the data we need, which we issue from the black box.
In a functional black box, this transformation of incoming data into outgoing data occurs by applying to them a certain formula in which the final result is expressed in terms of dependence on the incoming data. Remember from the school curriculum, what determines the average speed of movement? That's right: from the distance traveled and the time for which it is covered. Knowing the original data (path S and time t ), as well as the formula for calculating the average speed ( S / t ), we can calculate the final result - the average motion speed. By the same principle of dependence of the final result on the initial data, the final result of the program written in the functional style is also calculated. At the same time, in contrast to imperative programming, in the process of computing we do not have any change in the variables, either local or global.
In fact, in the previous paragraph, it would be more correct to use the word function instead of the word formula . I did not do this due to the fact that the word function in imperative programming languages is most often called not at all what is meant by this term in mathematics, physics, and functional programming languages. In imperative languages, a function is often referred to as what is more correctly called a procedure — that is, a named part of a program (subroutine), which is used to avoid repeating repeated pieces of code. A little later you will understand how functions in functional programming languages (so-called pure functions , or pure functions ) differ from what is called functions in imperative programming languages.
Note: The division of programming languages into imperative and functional is rather arbitrary. You can program in a functional style in languages that are considered imperative, and in an imperative style in languages that are considered functional ( here is an example of a factorial calculating program, in an imperative style in Haskell and comparing it with the same C program ) - it will just be inconvenient . Therefore, let us consider imperative languages as those that encourage programming in an imperative style, and functional languages as those that encourage programming in a functional style.
Discover the benefits of pure features.
Most of the time, a Haskell programmer has to deal with the so-called pure functions (everything, of course, depends on the programmer, but we are talking about how it should be). In fact, these functions are called “pure” in order not to be confused with what they mean by the term “function” in imperative programming. In fact, these are the most common functions in the mathematical understanding of this term. Here is the simplest example of such a function that adds three numbers:
addThreeNumbers xyz = x + y + z Explanation for those not familiar with Haskell syntax
In the part of the function that is to the left of the = sign, the name of the function always comes first, and then, separated by spaces, the arguments of this function. In this case, the function name is addThreeNumbers , and x , y, and z are its arguments.
The right of the = sign indicates how the result of the function is calculated in terms of its arguments.
The right of the = sign indicates how the result of the function is calculated in terms of its arguments.
Notice the = ( equals ) sign. Unlike imperative programming, it does not mean an assignment operation. The equal sign means that what is to the left of it is the same as the expression to the right of it. Just like in mathematics: 6 + 4 is the same as 10 , so we write 6 + 4 = 10 . In any calculation, we can substitute the expression (6 + 4) instead of the ten, and we get the same result as if we had substituted the ten. The same is true in Haskell: instead of
addThreeNumbers xyz we can substitute the expression x + y + z , and we get the same result. The compiler, by the way, does just that - when it encounters a function name, it substitutes an expression defined in its body instead.What is the "purity" of this function?
The result of a function depends only on its arguments. No matter how many times we call this function with the same arguments, it will always return the same result to us, because the function does not refer to any external state. She is completely isolated from the outside world and takes into account only what we explicitly passed on to her as her arguments. Unlike such a science as history, the result of mathematical calculations does not depend on whether the Communists are in power, the Democrats or Putin. Our function comes from mathematics - it depends only on the arguments passed to it and nothing more.
You can check it yourself: no matter how many times you pass this function 1, 2 or 4 as arguments, you will always get 7 as a result. You can even "(2 +1)" instead of "3", and instead "4" - "(2 * 2)". There is no other way to get other results with these arguments.
TheaddThreeNumbersfunction isaddThreeNumberscalled pure because it is not only independent of the external state, but also not capable of changing it. It cannot even change the local variables passed to it as arguments. All she can (and should) do is calculate the result based on the values of the arguments passed to her. In other words, this feature has no side effects.
What does this give us? Why do haskellists cling to this “purity” of their functions so much, contemptuously kryvat, looking at the traditional functions of imperative programming languages, built on mutations of local and global variables?
Since the result of calculating pure functions does not depend on the external state and does not change the external state, we can calculate such functions in parallel, without worrying about data race , which compete with each other for common resources. Side effects are the destruction of parallel computing, and since our pure functions do not have them, we have nothing to worry about. We simply write pure functions, not caring about the order in which the functions are calculated, or how to parallelize the calculations. Paralleling we get out of the box, simply because we write in Haskell.
In addition, since calling a pure function several times with the same arguments, we are always guaranteed to get the same result, Haskell remembers the result that was calculated once, and doesn’t calculate it again when calling a function with the same arguments, but instead substitutes the previously calculated . This is called memoization . It is a very powerful optimization tool. Why count again if we know that the result will always be the same?
If the essence of imperative programming is in the mutation (change) of variables in a strictly defined sequence, then the essence of functional programming is in the immunity of data and in the composition of functions.
If we have a function
g :: a -> b (read as “a function g that takes an argument of type a and returns values of type b”) and a function f :: b -> c , then we can compose it to get a function h :: a -> c . Applying the value of type a to the input of the function g, we obtain the value of the type b at the output - and the values of this type are taken by the function f. Therefore, we can immediately transfer the result of calculating the function g to the function f, the result of which will be a value of type c. This is written like this: h :: a -> c h = f . g 
The point between the functions f and g is the composition operator, which has the following type:
(.) :: (b -> c) -> (a -> b) -> (a -> c) The composition operator here is taken in parentheses because it is in this way (in parentheses) that it is used in the prefix style as a normal function. When we use it in infix style - between its two arguments - it is used without brackets.
We see that the composition operator takes the function
b -> c as the first argument (the arrow also indicates the type - the type of the function), which corresponds to our function f. With the second argument, it also accepts a function - but already with the type a -> b , which corresponds to our function g. And it returns the composition operator a new function — with the type a -> c , which corresponds to our function h :: a -> c . Since the functional arrow has the right associativity, we can omit the last parentheses: (.) :: (b -> c) -> (a -> b) -> a -> c Now we see that the composition operator needs to pass two functions - with types
b -> c and a -> b , as well as an argument of type a, which is passed to the input of the second function, and at the output we get a value of type c , which the first one returns function.Why is the composition operator denoted by a dot
In mathematics,
f ∘ g used to denote a composition of functions, which means “f after g”. The point is similar to this symbol, and therefore it was chosen as the composition operator.Composition of functions
f . g f . g means the same as f (gx) - i.e. the function f applied to the result of applying the function g to the argument x .Wait a minute And where is the argument of type a in the definition of the function h = f lost. g? I see two functions as arguments of the composition operator, and I don’t see the value passed to the input of the g function!
When the last argument in the definition of the function to the left and right of the "=" sign is the same argument, and this argument is not used anywhere else, it can be omitted (but necessarily from both sides!). In mathematics, the argument is called the “point of use of the function”, so this writing style is called “pointless” (although usually with such recording of points as the composition operators, there are quite a few :)).
Why is the composition of functions the essence of functional programming languages? Yes, because any program written in a functional language is nothing but a composition of functions! Functions are the building blocks of our program. Compositing them, we get other functions that, in our own, we compose to obtain new functions - etc. The data flows from one function to another, transforming, and the only condition for the composition of functions is that the data returned by one function have the same type that the next function accepts.
Since the functions in Haskell are clean and depend only on the arguments clearly passed to them, we can easily “pull” a “brick” out of the function composition chain in order to refactor or even completely replace it. All we need to take care of is that our new brick function accepts input values and outputs values of the same type as the old brick function. And that's it! Pure functions do not depend on the external state, so we can test functions without looking at it. Instead of testing the entire program, we test individual functions. The situation described in this very vital story, in our case, becomes simply impossible:
A marketer asks a programmer:
- What is the difficulty of supporting a large project?
- Well, imagine that you are a writer, and support the project "War and Peace", - the programmer answers. - You have TK - write a chapter about how Natasha Rostova walked in the rain in the park. You write “it was raining”, you remain - and the error message flies to you: “Natasha Rostova died, the continuation is impossible.” How did she die, why did she die? You start to understand. It turns out that Pierre Bezukhov has slippery shoes, he fell, his gun hit the ground, and the bullet from the post ricocheted into Natasha. What to do? To charge the gun with idle? Change shoes? We decided to remove the post. Removed, save and get the message: "Lieutenant Rzhevsky died." Again you sit down, understand, and it turns out that in the next chapter he leans on a pole that is no longer there ...
I hope you now understand why haskellists appreciate pure functions. First, they allow them to write parallelized code without any effort, without worrying about the data race. Secondly, it allows the compiler to effectively optimize the calculations. And, thirdly, the absence of side effects and the independence of the work of pure functions from the external state allows the programmer to easily maintain, test and refactor even very large projects.
In other words, the creators of Haskell invented for themselves (and for us) such worlds, such a spherical horse in a vacuum, in which all functions are clean, completely stateless, there is no state, everything is optimized to the impossibility and everything is parallelized with us parties. Not a language, but a dream! It remains only to understand what to do with the "mere trifles", which, in their scientific work on the concept of monads , listed Eugenio Moggi:
How in this very spherical horse in vacuum to get the initial data for our programs, which come just from the outside world, from which we isolated? You can, of course, use the result of user input as an argument to our clean function (for example, thegetCharfunction that accepts character input from the keyboard), but, first, in this way we will let in our cozy clean world a “dirty” function that we it will break there, and, secondly, such a function will always have the same argument (thegetCharfunction), but the calculated value will always be different, because the user (this is an ambush!) will always press different keys.
How to produce the result in the external world isolated by us from our cozy purely functional world, the result of the program? After all, a function in the mathematical sense of this word must always return a result, and functions that send some data to the outside world do not return anything to us, and therefore they are not functions!
What to do with the so-called partially defined functions - that is, with functions that are not defined for all arguments? For example, the well-known division function is not defined for division by zero. Such functions are also not full-fledged functions in the mathematical sense of the term. You can, of course, throw an exception for such arguments, but ...
... but what do we do with the exceptions? Exceptions are not the result that we expect from pure functions!
And what to do with non-deterministic calculations? That is, with those where the correct result of the calculations is not one, but many of them. For example, we want to get a translation of a word, and the program gives us several of its meanings at once, each of which is the correct result. A pure function should always produce only one result.
And what to do with the continuations? Continuation is when we make some calculations, and then, without waiting for them to finish, we save the current state and switch to perform some other task, so that after its execution we return to the incomplete calculations and continue from where we left off. What state are we talking about in our purely functional world, where there is no state and cannot be?
And what, finally, should we do when we need not only to somehow consider the external state, but also to somehow change it?
Let's think together how we can keep our calculations clean and solve the problems that have been voiced. And see if you can find a common solution for all these problems.
Calculations and “something else”
So, we got acquainted with pure functions and realized that their cleanliness allows us to get rid of the most difficult problems that programmers face. But we also described a number of problems that we have to solve in order to retain the ability to enjoy the benefits of pure functions. I will bring them again (excluding the problems related to input-output, which we will discuss a little later), slightly reformulating them so that we can see in them a common pattern:
Sometimes we have functions that are not defined for all arguments. When we pass this function the arguments on which the function is defined, we want it to calculate the result. But when passing its arguments on which it is not defined, we want the function to return something else to us (exception, error message, or an analogue of imperative null ).Sometimes functions can give us not one result, but something else (for example, a whole list of results, or no result at all (an empty list of results)).
Sometimes, to calculate the value of a function, we want to receive not only arguments, but also something else (for example, some data from an external environment, or some settings from a configuration file).
Sometimes we want not only to get the result of the calculation to pass the next function, but also to apply it as an argument to something else (getting some state to which we can then return to continue the calculation, which is the meaning of continuations).
Sometimes we want not only to make calculations, but also to do something else (for example, write something to the log).
Sometimes, by compositing functions, we want to transfer to the next function not only the result of our calculation, but also something else (for example, some state that we first considered from somewhere, and then somehow changed in a controlled manner).
Noticed the general pattern? On pseudocode, it can be written like this:
( / - ) { // / // - return ( / - ) } You can, of course, pass this “something else” as an additional argument to our functions (this approach is used in imperative programming, and is called “state threading”), but you can mix pure calculations with “something else” in one pile - not the best idea. In addition, it will not allow us to get a single solution for all the situations described.
Let us recall the ancient Egyptians, who were discussed at the beginning, and who invented numbers. Instead of drawing a number of sheep figures, they separated the calculation from its context . In modern terms, they encapsulated calculations and their context. And if before them the concept of calculating the quantity was inextricably linked to what we believe, then their innovation divided it into two parallel “execution threads” - into the flow associated directly with the calculations, and into the flow in which something is stored or processed. something else - namely, the context of the calculation (because during the calculation the context can not only be stored, but also be changed, if we, for example, calculate how many kebabs come from the sheep in the herd).
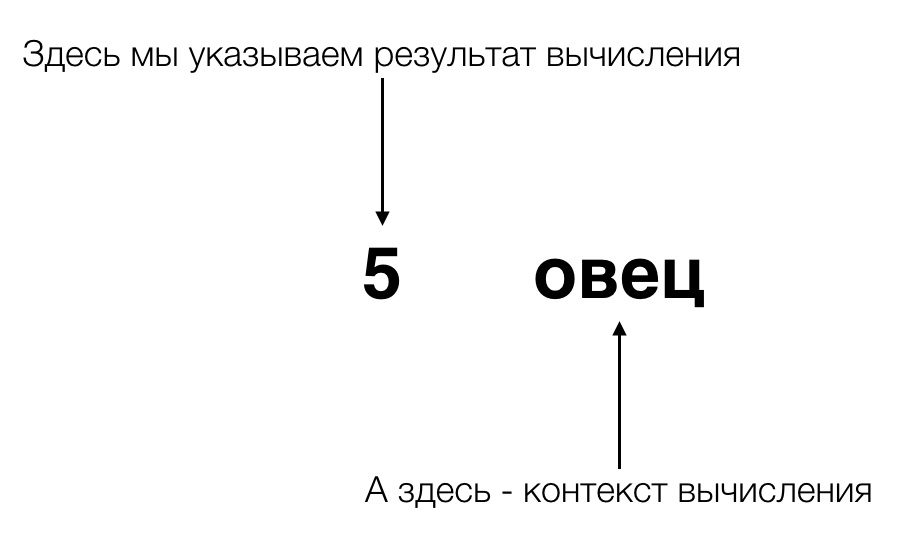
When we want to express “something else” in Haskell and at the same time get the most generalized solution, we express this “something else” as an additional type. But not of a simple type, but of a type function, which takes other types as an argument. Sounds difficult and incomprehensible? Do not worry, it is very simple, and after a few minutes you will see for yourself.
Something else encapsulation
On December 11, 1998, the Mars Climate Orbiter spacecraft was launched to explore Mars. After the unit reached Mars, it was lost. After the investigation, it became clear that in the control program some distances were counted in inches, and others - in meters. Both in one and in the other case these values were represented by the type
Double . As a result of the function that counts in inches, the arguments expressed in meters were passed, which naturally led to an error in the calculations.If we want to avoid such errors, then we need the values expressed in meters to be different from the values expressed in inches, and so that when we try to pass a value to a function that is not expressed in those units, the compiler will tell us about the error. In Haskell this is very easy to do. Let's announce two new types:
data DistanceInMeters = Meter Double data DistanceInInches = Inch Double DistanceInMeters and DistanceInInches are called type constructors, and Meter and Inch are data constructors (type constructors and data constructors inhabit different scopes, so they could be made the same).Take a closer look at these type declarations. Do you think that data constructors behave like functions, taking as a argument a value of type
Double and returning a result of calculating a value of type DistanceInMeters or DistanceInInches ? So it is - the data constructors are also functions! And if earlier we could accidentally pass to a function that takes a Double , any value that has a Double , then now in this function we can specify that its argument should contain not only the value of the Double type, but also something else , namely «» Meter Inch .. -_
Meter Inch Double . , — «- » — , «», «- », . Haskell. Haskell: data Maybe a = Nothing | Just a , ,
,
Maybe , a . « » , — Double , Bool , DistanceInMeters , . , Maybe a 2 — Nothing Just ( a ). «»: Nothing , Just - (, Just True ) — Maybe a ( Just True , Maybe Bool ).,
Maybe , . - ( Just ), ( Nothing ). , , - Maybe , . : , , — .Maybe Haskell — , . , lookup , (, ), , . , . Nothing , — , Just . Those. , , ( Just ), , — «- » ( Nothing ).,
Nothing , , «- » ? : , , , — , . , : data Either ab = Left a | Right b We see that the type constructor
Eithertakes 2 type variables - aand b(which can be different types, but can be of the same type - as we like). If the result of the calculations was successful, we get them in a wrapper Right(the result of the calculations will be of type b), and if the calculations failed, then we get an error message of type a in the wrapper of the data designer Left.Well, what about working with the external environment? What if the value of our calculation depends on some external environment, which we must read and pass as an argument to the function that calculates the value we need? As stated, we write:
data Reader ea = Reader (e -> a) (Environment), ,
e (, ), a . e -> a , .. ., - ( ): , «- ». —
[a] ( : [] a , [] «- », a — ).«- » — , , , . «- » , «» , «- » , .
, :
, , , .
, , , «- ». , , «- », «- ».
«- », . «- » .
«- » «» , «» .
:a -> mbm— « »,b.
, . , - :
a -> b, .. .ma.ma -> mb, , «»a -> bm,a -> b,mb.
, , first class citizens. Those. , — , .. , , , «»m.f,a, ,mfma, « »:mf ` ` ma => m (f ` ` a).
, , , , , , .f :: b -> cg :: a -> b,f . g,g,f.f :: b -> mcg :: a -> mb?mbb— , ,b«»m.
«»bm, . «» «- », . , ,a -> mbb -> mc,a -> mc, , «- ». , , , , .
— , !
, :
, , , .
, , , .
, , — , , , «- », .
, ,
isChar :: a -> Bool , , Char , , . , Maybe a 2 — Just Nothing : maybeIsChar :: Maybe Char -> Maybe Char -> Maybe Bool maybeIsChar (Just x) = Just (isChar x) maybeIsChar Nothing = Nothing And so we can, without bothering (although this is how to look), determine the analogue of each pure function for working with wrapped data. And we will need to write the corresponding analog not only for each function, but also for each wrapper!
But it can be done differently. You can define a new function that takes as its first argument a pure function that we already have and applies it to the value contained within the wrapper, returning us the new value wrapped in the same wrapper. Let's call this function
fmap: fmap :: (a -> b) -> ma -> mb , , ,
fmap . fmap Maybe a : fmap f (Just x) = Just (fx) fmap _ Nothing = Nothing fmap ?
fmap a -> b . , , , , . - , . , .Maybe a a -> b . , fmap . -: Maybe a , .-! ,
fmap , «» , , . , — ! , .. , .— !
, , , . , ? ?
, . , , — , , .
<*> ( apply; , , , , ; , , ): (<*>) :: m (a -> b) -> ma -> mb Maybe a . , 2 , , , , ( Just ), Nothing : (Just f) <*> Nothing = Nothing Nothing <*> _ = Nothing (Just f) <*> (Just x) = Just (fx) , , , — ,
Maybe . , , — (<*>) . , , , (<*>) pure .pure ? , , ! pure . : pure :: a -> ma pure Maybe , : pure x = Just x , ? ( «!»)
, , , , ( ). , ,
Just 2 Just 3 : pure (+) <*> Just 2 <*> Just 3 > Just 5 ?
pure
Maybe (+) , . 2 (<*>) .? !
, , .
, :
liftAN , A Applicative (functor), N , , . (+), : liftA2 (+) (Just 3) (Just 2) > Just 5 , :
( | a + b | ) ( | (Just 3) + (Just 2) | ) > Just 5 , !
, , ( ) .
fmap . , , , , ., . —
pure <*>- and this also allowed us to apply ordinary functions to the wrapped values, taking any number of arguments. And as soon as we defined these functions for the wrapper type, he immediately earned the right to be called an applicative functor. By the way, in order to make a wrapper type an applicative functor, you must first make it an ordinary functor (and it’s not possible to cheat - the compiler will follow this). This is a logical (and, as usual, simple) explanation, which I will leave to you for self-study, because the article has already become swollen.It remains for us to understand how we can compose a composition of two functions
a -> mbandb -> mc , , «- », . , , , . , , , .—
return . return , . return , : return :: a -> ma pure , ? , . , , , ( — ), , pure, return : return = pure , , ,
(>>=) ( bind). : (>>=) :: mb -> (b -> mc) -> mc … - . :
(>>=) a -> mb , , , -, «- » ( «- », ), . Those. a -> mb , mb , , - . , , (>>=) . .(>>=) Maybe . 2 , 2 . , b -> mc k , « » ( , , , « », return « »): — Nothing, Nothing Nothing >>= _ = Nothing — , "" k (Just x) >>= k = kx That's all.
Maybe — ! , — return (>>=) .( , , )? , . ,
Maybe Just , Nothing . , - Nothing , . ? if then else , Nothing ?,
if then else . (>>=) , . : - Nothing , (>>=) «» , . , Nothing . , .Let's maybe define another monad? Take the wrapper type
Either ab, which allows us to more clearly work with errors and exceptions than the type Maybe. Let's recall the definition of this type: data Either ab = Left a | Right b 2 , —
Left — a — , , «- », — Right — b — «» . «» , , Right . — , Left .return : return x = Right x .
return , - b , -_ Right Either ab .(>>=) . , Maybe : , Either ab , , -_ Left — . (.. , -_ Right ), : (Left x) >>= _ = Left x (Right x) >>= k = kx Maybe Either . 2 , (, , , «» ). , ., — .
a -> [b] . (>>=) ma — , [a] ( a ). , a ., , ? , . — , . ,
fmap ( , , — ?). fmap , m : fmap :: (a -> b) -> [a] -> [b] ,
fmap , : fmap :: (a -> [b]) -> [a] -> [[b]] ,
fmap mb , mmb , .. . (>>=) , «». concat , , , . (>>=) : [] >>= _ = [] xs >>= k = (concat . fmap k) xs You see that the logic of defining an operator
(>>=)is the same in all cases. In each wrapped value, we have the result of calculations and “something else”, and we think that we need to do it with calculations and with this “something else” when transferring to another function. “Something else” can be a marker of successful or unsuccessful calculations, it can be a marker of successful calculations or an error message, it can be a marker that our calculations can return from zero to infinity of results. “Something else” can be a log entry, a state that we read and pass as an argument for our “basic” calculations. Or the state that we read, change and transfer to another function, where it changes again - in parallel with our “basic” calculations., ( , ). — , —
return (>>=) .,
(>>=) , , . , Haskell, , . . -, Haskell , , . -, ( ) , , .: «» «- », . «» « »,
(>>=) . , - (>>=) , , , , ., ,
(>>=) — , . Haskell, (>=>) , «» («fish operator»): (>=>) :: (a -> mb) -> (b -> mc) -> a -> mc (f >=> g) x = fx >>= g The value
xwe have is type a, fand gis Kleisley's arrows. Applying the Klaisley arrow fto the value x, we get the wrapped value. And how to transfer the wrapped value to the next Klaisley arrow, as you remember, the operator knows (>>=).In the next part we will see how to work with the monads defined in Haskell (and others are not required by the overwhelming majority of programmers), we will implement another standard monad called
Writer («- » ), , . Haskell « », , , , , , , . -, (, , , ).Source: https://habr.com/ru/post/272115/
All Articles