Under the hood Redis: Hash table (part 2) and List
In the first part, I said that the hash table is a bit of a LIST , SET, and SORTED SET . Judge for yourself - LIST consists of ziplist / linkedlist, SET consists of dict / intset, and SORTED SET is ziplist / skiplist. We have already reviewed the dictionary (dict), and in the second part of the article we will consider the structure of the ziplist - the second most frequently applicable structure under the hood of Redis. Let's look at LIST - the second part of its “kitchen” is a simple implementation of a linked list. This is useful to us to carefully consider the frequently mentioned advice on optimizing hash tables through their replacement with lists. Calculate how much memory is required for overhead when using these structures, what price you pay for saving memory. Let's summarize when working with hash tables, when using encoding in a ziplist.
Last time we ended up with the fact that 1,000,000 keys saved using ziplist occupied 16 MB of RAM, while in dict the same data required 104 MB (ziplist is 6 times less!). Let's figure out what price:

So a ziplist is a doubly linked list. Unlike a regular linked list, here the links in each node point to the previous one and to the next node in the list. With a doubly linked list, you can efficiently move in any direction, either towards the beginning or towards the end. In this list, it is easier to remove and rearrange elements, since the addresses of those elements of the list whose pointer points to the variable element are easily accessible. The Redis developers are positioning their implementation as efficient in terms of memory. The list is able to store strings and integers, while the numbers are stored in the form of numbers, and not redisObject with a value. And if you want to save the string “123,” it will save as the number 123, and not the sequence of characters `1`,` 2`, `3`.
The key and values are stored as one after the other in the list. Operations on the list is a search for a key, through enumeration and work with the value that is located in the next element of the list. Theoretically, insert and change operations are performed in constant O (1) . In fact, any such operation in the implementation of Redis requires the allocation and redistribution of memory and the real complexity directly depends on the amount of memory already used. In this case, we remember about O (1) as an ideal case and O (n) - as the worst.
Let's calculate its size.
Everything is simple with the header - this is ZIPLIST_HEADER_SIZE (constant, defined in ziplist.c and equal to sizeof (uint32_t) * 2 + sizeof (uint16_t) + 1 ). The element size is 5 * size_of (unsigned int) + 1 + 1 at least 1 byte per value . Total overhead for storing data in this encoding for n elements (not including the value):
Each element begins with a fixed header consisting of several pieces of information. The first is the size of the previous item and is used to go back through the doubly linked list. The second is the encoding with the optional length of the structure itself in bytes. The length of the previous element works as follows: if the length does not exceed 254 bytes (it is the constant ZIP_BIGLEN ), then 1 byte will be used to store the length of the value. If the length is greater than or equal to 254, 5 bytes will be used. In this case, the first byte will be set to the constant value ZIP_BIGLEN, so that we understand that we have a long value. The remaining 4 bytes store the length of the previous value. The third is the header, which depends on the value contained in the node. If the value is a string - the first 2 bits of the header field of the header will store the type of encoding for the length of the string, followed by a number with the length of the string. If the values are integer, the first 2 bits will be set to one. For numbers, another 2 bits are used, which determine what dimension the integer is stored in it.
Check and look at the reverse side of the coin. We will use LUA, so you do not need anything other than Redis to repeat this test yourself. At first we look that turns out when using dict.
Will execute
and
In the case of encoding: hashtable (dict) spent ~ 516 kb of memory and 18.9 ms to save 10,000 values, 7.5 ms to read them. With encoding: ziplist we get ~ 81 kb of memory and 710 ms to save, 705 ms to read. For the test of 10,000 records received:
It is important to understand that the drop in performance is not linear, and already for 1,000,000 you risk simply not waiting for the results. Who will add 10,000 items to the ziplist? This, unfortunately, is one of the first recommendations from most consultants. When is the game worth the candle? I would say that while the number of elements is in the range of 1 - 3500 elements you can choose, remembering that ziplist always wins 6 times or more from memory. Anything more is measured on your real data, but it will have nothing to do with loaded real-time systems. Here is what happens with the read / write performance depending on the size of the hash on dict and ziplist ( gist per test ):
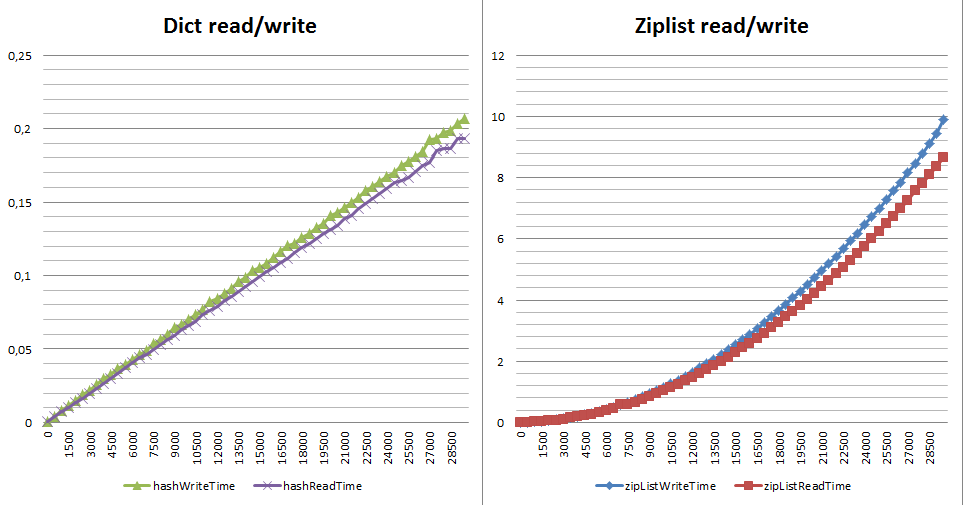
Why is that? The price of insertion, changing the length of elements and deleting a ziplist is monstrous - this is either realloc (all work falls on the allocator's shoulders) or a complete rebuilding of the list from n + 1 from the modified element to the end of the list. Rebuilding is a lot of small realloc, memmove, memcpy (see __ziplistCascadeUpdate in ziplist.c).
Why is it important to talk about LIST in an article about HASH? The point is one very important advice about optimizing structured data. Went it seems from DataDog , I find it difficult to say exactly. Translated as follows (original) :
And this is a very useful tip. Obviously, the list (LIST) will help you save a lot - at least 2 times.
We have already figured out the ziplist , let's watch REDIS_ENCODING_LINKEDLIST . In the implementation of Redis, this is a very simple (~ 270 lines of code) not sorted singly-linked list ( just like in wikipedia ). With all its advantages and disadvantages:
Nothing complicated - each LIST in this encoding is 5 pointers and 1 unsigned long. So the overhead is 5 * size_of (pointer) + 8 bytes . And each node is 3 pointers. The overhead for storing data in this encoding for n elements is:
There is no realloc in the linkedlist implementation - only memory allocation for the fragment you need, in the meanings - redisObect without any tricks or optimizations. According to the memory overhead, the difference in service costs between the ziplist and the linkedlist is about 15%. If we consider the service data plus values - at times (from 2 and above), depending on the type of value. So for a list of 10,000 items, consisting only of numbers in a ziplist, you will spend about 41 kb of memory; the linkedlist contains 360 kb of real memory:
Let's look at the difference in performance when writing and receiving an item through LPOP (read and delete). Why not LRANGE - its complexity is designated as O (S + N) and for both implementations of the list this time is constant. With LPOP , everything is not quite as written in the documentation - complexity is indicated as O (1). But what happens if I need sequential reading to read everything:
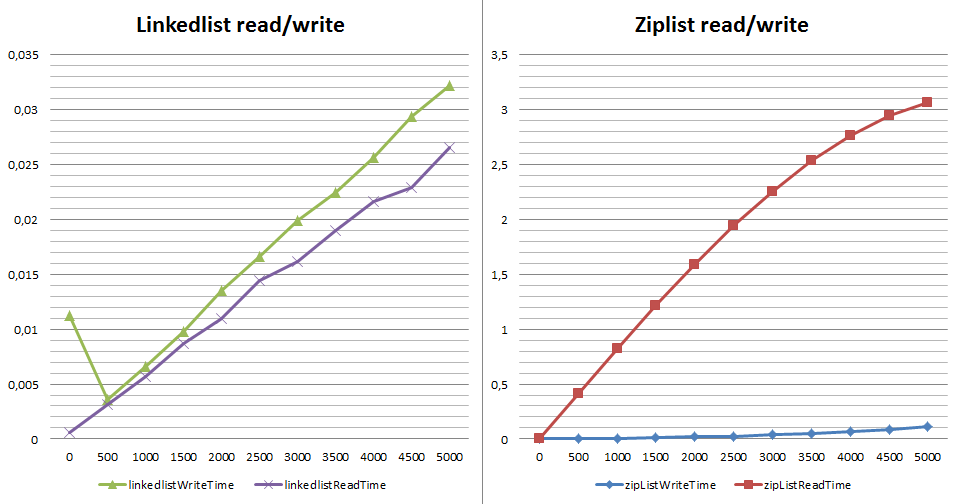
What is wrong with reading speed when using ziplist? Each `LPOP` is an extraction of the element c at the beginning of the list with its complete rebuilding. By the way, if we use RPOP in reading, instead of LPOP, the situation will not change much (hello to realloc from the list refresh function in ziplist.c). Why is it important? The RPOPLPUSH / BRPOPLPUSH commands are a popular solution for queuing based on Redis (for example, Sidekiq, Resque). When in such a queue with a ziplist encoding, a large number of values (from several thousand) is provided - the receipt of one element is no longer constant and the system begins to “fever”.
At the end it is time to formulate several conclusions:
Table of contents:
The materials used in writing the article:
Last time we ended up with the fact that 1,000,000 keys saved using ziplist occupied 16 MB of RAM, while in dict the same data required 104 MB (ziplist is 6 times less!). Let's figure out what price:
So a ziplist is a doubly linked list. Unlike a regular linked list, here the links in each node point to the previous one and to the next node in the list. With a doubly linked list, you can efficiently move in any direction, either towards the beginning or towards the end. In this list, it is easier to remove and rearrange elements, since the addresses of those elements of the list whose pointer points to the variable element are easily accessible. The Redis developers are positioning their implementation as efficient in terms of memory. The list is able to store strings and integers, while the numbers are stored in the form of numbers, and not redisObject with a value. And if you want to save the string “123,” it will save as the number 123, and not the sequence of characters `1`,` 2`, `3`.
In the 1.x Redis branch, instead of dict, a zipmap was used in the dictionary - a straightforward (~ 140 lines) implementation of a linked list, optimized for memory savings, where all operations occupy O (n). This structure is not used in Redis (although it is in its source code and is maintained up to date), while some of the zipmap ideas formed the basis of the ziplist.
The key and values are stored as one after the other in the list. Operations on the list is a search for a key, through enumeration and work with the value that is located in the next element of the list. Theoretically, insert and change operations are performed in constant O (1) . In fact, any such operation in the implementation of Redis requires the allocation and redistribution of memory and the real complexity directly depends on the amount of memory already used. In this case, we remember about O (1) as an ideal case and O (n) - as the worst.
+-------------+------+-----+-------+-----+-------+-----+ | Total Bytes | Tail | Len | Entry | ... | Entry | End | +-------------+------+-----+-------+-----+-------+-----+ ^ | +-------------------+--------------+----------+------+-------------+----------+-------+ | Prev raw len size | Prev raw len | Len size | Len | Header size | Encoding | Value | +-------------------+--------------+----------+------+-------------+----------+-------+ Look at this structure in the source code.
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) typedef struct zlentry { unsigned int prevrawlensize, prevrawlen; unsigned int lensize, len; unsigned int headersize; unsigned char encoding; unsigned char *p; } zlentry; Let's calculate its size.
The answer to the question how much memory will actually be used depends on the operating system, the compiler, the type of your process and the allocator used (in redis, by default, jemalloc). All further calculations I cite for redis 3.0.5 compiled on a 64 bit server running centos 7.
Everything is simple with the header - this is ZIPLIST_HEADER_SIZE (constant, defined in ziplist.c and equal to sizeof (uint32_t) * 2 + sizeof (uint16_t) + 1 ). The element size is 5 * size_of (unsigned int) + 1 + 1 at least 1 byte per value . Total overhead for storing data in this encoding for n elements (not including the value):
12 + 21 * n
Each element begins with a fixed header consisting of several pieces of information. The first is the size of the previous item and is used to go back through the doubly linked list. The second is the encoding with the optional length of the structure itself in bytes. The length of the previous element works as follows: if the length does not exceed 254 bytes (it is the constant ZIP_BIGLEN ), then 1 byte will be used to store the length of the value. If the length is greater than or equal to 254, 5 bytes will be used. In this case, the first byte will be set to the constant value ZIP_BIGLEN, so that we understand that we have a long value. The remaining 4 bytes store the length of the previous value. The third is the header, which depends on the value contained in the node. If the value is a string - the first 2 bits of the header field of the header will store the type of encoding for the length of the string, followed by a number with the length of the string. If the values are integer, the first 2 bits will be set to one. For numbers, another 2 bits are used, which determine what dimension the integer is stored in it.
Decryption of the title, for those who want to be confused
| How lies | What lies | |
|---|---|---|
| | 00pppppp | | one | A string that is less than or equal to 63 bytes (i.e., sds with REDIS_ENCODING_EMBSTR , see the first part of the series ) |
| | 01pppppp | B 1 byte | | 2 | A string that is less than or equal to 16383 bytes (14 bits) |
| five | A string whose value is greater than or equal to 16384 bytes | |
| | 11000000 | | one | Integer, int16_t ( 2 bytes ) |
| | 11010000 | | one | Integer, int32_t ( 4 bytes ) |
| | 11100000 | | one | Integer, int64_t ( 8 bytes ) |
| | 11110000 | | one | Integer with a sign that will fit in 24 bits ( 3 bytes ) |
| | 11111110 | | one | An integer with a sign that “fits” into 8 bits ( 1 byte ) |
| | 1111xxxx | | one | Where xxxx is between 0000 and 1101, it means an integer that “fits” into 4 bits. Without a signed integer from 0 to 12. The decoded value is in fact from 1 to 13, because 0000 and 1111 are already occupied and we always subtract 1 from the decoded value to get the desired value. |
| | 11111111 | | one | End of list marker |
Check and look at the reverse side of the coin. We will use LUA, so you do not need anything other than Redis to repeat this test yourself. At first we look that turns out when using dict.
Will execute
multi time eval "for i=0,10000,1 do redis.call('hset', 'test', i, i) end" 0 time and
multi time eval "for i=0,10000,1 do redis.call('hget', 'test', i) end" 0 time Output from redis = cli
config set hash-max-ziplist-entries 1 +OK config set hash-max-ziplist-value 1000000 +OK flushall +OK info memory $225 # Memory used_memory:508536 multi +OK time +QUEUED eval "for i=0,10000,1 do redis.call('hset', 'test', i, i) end" 0 +QUEUED time +QUEUED exec *3 *2 $10 1449161639 $6 948389 $-1 *2 $10 1449161639 $6 967383 debug object test +Value at:0x7fd9864d6470 refcount:1 encoding:hashtable serializedlength:59752 lru:6321063 lru_seconds_idle:23 info memory $226 # Memory used_memory:1025432 multi +OK time +QUEUED eval "for i=0,10000,1 do redis.call('hget', 'test', i) end" 0 +QUEUED time +QUEUED exec *3 *2 $10 1449161872 $6 834303 $-1 *2 $10 1449161872 $6 841819 flushall +OK info memory $226 # Memory used_memory:510152 config set hash-max-ziplist-entries 100000 +OK multi +OK time +QUEUED eval "for i=0,10000,1 do redis.call('hset', 'test', i, i) end" 0 +QUEUED time +QUEUED exec *3 *2 $10 1449162574 $6 501852 $-1 *2 $10 1449162575 $6 212671 debug object test +Value at:0x7fd9864d6510 refcount:1 encoding:ziplist serializedlength:59730 lru:6322040 lru_seconds_idle:19 info memory $226 # Memory used_memory:592440 multi +OK time +QUEUED eval "for i=0,10000,1 do redis.call('hget', 'test', i) end" 0 +QUEUED time +QUEUED exec *3 *2 $10 1449162616 $6 269561 $-1 *2 $10 1449162616 $6 975149 In the case of encoding: hashtable (dict) spent ~ 516 kb of memory and 18.9 ms to save 10,000 values, 7.5 ms to read them. With encoding: ziplist we get ~ 81 kb of memory and 710 ms to save, 705 ms to read. For the test of 10,000 records received:
The memory gain is 6 times the cost of a write speed of 37.5 times and 94 times of reading.
It is important to understand that the drop in performance is not linear, and already for 1,000,000 you risk simply not waiting for the results. Who will add 10,000 items to the ziplist? This, unfortunately, is one of the first recommendations from most consultants. When is the game worth the candle? I would say that while the number of elements is in the range of 1 - 3500 elements you can choose, remembering that ziplist always wins 6 times or more from memory. Anything more is measured on your real data, but it will have nothing to do with loaded real-time systems. Here is what happens with the read / write performance depending on the size of the hash on dict and ziplist ( gist per test ):
Why is that? The price of insertion, changing the length of elements and deleting a ziplist is monstrous - this is either realloc (all work falls on the allocator's shoulders) or a complete rebuilding of the list from n + 1 from the modified element to the end of the list. Rebuilding is a lot of small realloc, memmove, memcpy (see __ziplistCascadeUpdate in ziplist.c).
Why is it important to talk about LIST in an article about HASH? The point is one very important advice about optimizing structured data. Went it seems from DataDog , I find it difficult to say exactly. Translated as follows (original) :
You store your users' data in Redis, for example, `hmset user: 123 id 123 firstname Ivan lastname Ivanov location Tomsk twitter ivashka`. Now, if you create another user, you will spend empty memory on the field names - id, firstname, lastname, etc. If there are many such users, this is a lot of memory that has been dropped (we already have to count how many - for this set of fields, 384 bytes per user).
')
So if you have
- You have a lot of objects, say 50,000 or more.
- Your objects have a regular structure (in fact, always all the fields)
You can use the concept of named python tuples - a linear list with read-only access, around which you can build a hash table with your hands. Roughly speaking “fisrtname” is the value of the 0 index of the list, “lastname” of the first, and so on. Then the creation of the user will look like `lpush user: 123 Ivan Ivanov Tomsk ivashka`.
And this is a very useful tip. Obviously, the list (LIST) will help you save a lot - at least 2 times.
As in HASH, with the help of list-max-ziplist-entries / list-max-ziplist-val you control which internal data type the specific list key will be represented. For example, if list-max-ziplist-entries = 100, your LIST will be represented as REDIS_ENCODING_ZIPLIST , as long as it contains less than 100 items. As soon as there are more items, it will be converted to REDIS_ENCODING_LINKEDLIST . The list-max-ziplist-val setting works in the same way as hash-max-ziplist-val (see the first part ).
We have already figured out the ziplist , let's watch REDIS_ENCODING_LINKEDLIST . In the implementation of Redis, this is a very simple (~ 270 lines of code) not sorted singly-linked list ( just like in wikipedia ). With all its advantages and disadvantages:
typedef struct listNode { struct listNode *prev; struct listNode *next; void *value; } listNode; typedef struct list { listNode *head; listNode *tail; void *(*dup)(void *ptr); void (*free)(void *ptr); int (*match)(void *ptr, void *key); unsigned long len; } list; Nothing complicated - each LIST in this encoding is 5 pointers and 1 unsigned long. So the overhead is 5 * size_of (pointer) + 8 bytes . And each node is 3 pointers. The overhead for storing data in this encoding for n elements is:
5 * size_of (pointer) + 8 + n * 3 * size_of (pointer)
There is no realloc in the linkedlist implementation - only memory allocation for the fragment you need, in the meanings - redisObect without any tricks or optimizations. According to the memory overhead, the difference in service costs between the ziplist and the linkedlist is about 15%. If we consider the service data plus values - at times (from 2 and above), depending on the type of value. So for a list of 10,000 items, consisting only of numbers in a ziplist, you will spend about 41 kb of memory; the linkedlist contains 360 kb of real memory:
config set list-max-ziplist-entries 1 +OK flushall +OK info memory $226 # Memory used_memory:511544 eval "for i=0,10000,1 do redis.call('lpush', 'test', i) end" 0 $-1 debug object test +Value at:0x7fd9864d6530 refcount:1 encoding:linkedlist serializedlength:29877 lru:6387397 lru_seconds_idle:5 info memory $226 # Memory used_memory:832024 config set list-max-ziplist-entries 10000000 +OK flushall +OK info memory $226 # Memory used_memory:553144 eval "for i=0,10000,1 do redis.call('lpush', 'test', i) end" 0 $-1 info memory $226 # Memory used_memory:594376 debug object test +Value at:0x7fd9864d65e0 refcount:1 encoding:ziplist serializedlength:79681 lru:6387467 lru_seconds_idle:16 Let's look at the difference in performance when writing and receiving an item through LPOP (read and delete). Why not LRANGE - its complexity is designated as O (S + N) and for both implementations of the list this time is constant. With LPOP , everything is not quite as written in the documentation - complexity is indicated as O (1). But what happens if I need sequential reading to read everything:
What is wrong with reading speed when using ziplist? Each `LPOP` is an extraction of the element c at the beginning of the list with its complete rebuilding. By the way, if we use RPOP in reading, instead of LPOP, the situation will not change much (hello to realloc from the list refresh function in ziplist.c). Why is it important? The RPOPLPUSH / BRPOPLPUSH commands are a popular solution for queuing based on Redis (for example, Sidekiq, Resque). When in such a queue with a ziplist encoding, a large number of values (from several thousand) is provided - the receipt of one element is no longer constant and the system begins to “fever”.
At the end it is time to formulate several conclusions:
- It will not work for you to use ziplist in hash tables with a large number of values (from 1000), if performance is still important for you with a large write volume.
- If the data in your hash table has a regular structure - forget about the hash table and proceed to storing data in lists.
- Whatever type of encoding you use - Redis is ideal for numbers, acceptable for strings with a length of up to 63 bytes and not unique when storing larger strings.
- If there are a lot of lists in your system, remember that while they are small (before list-max-ziplist-entries), you spend little memory and everything is generally acceptable in terms of performance, but as soon as they start to grow, memory can grow dramatically from 2 times and higher jumps, and the process of changing the encoding will take considerable time (re-creation with sequential insertion + deletion).
- Be careful with the list view (list-max- * settings) if you use a list for building queues or active writing / reading and deleting. Or otherwise, if you use Redis to build queues based on lists, set list-max-ziplist-entries = 1 (you will still spend just a little more memory)
- Redis never gives away the memory already allocated by the system. Consider the overhead of service information and strategy for resizing - with active recording, you can greatly increase memory fragmentation due to this feature and spend up to 2 times more RAM than you expect. This is especially important when you run N instances of Redis on the same physical server.
- If it is important for you to store data that is heterogeneous in terms of volume and access speed on one Redis - think about adding a little Redis code and go to setting up list-max- * parameters for each key, instead of a server.
- The encodings of the same type of data on the master / slave may vary, which allows you to be more flexible in meeting the requirements — for example, quickly and with a large memory consumption for reading, slower and more economical in memory on the slave or vice versa.
- Overhead when using a ziplist is minimal, storing lines is cheaper in a ziplist than in any other structure (the top zedry is only 21 bytes per line, while the traditional representation of redisObject + sds line is 56 bytes).
Table of contents:
- Under the hood Redis: Strings
- Under the hood Redis: Hash table (part 1)
- Under the hood Redis: Hash table (part 2) and List
The materials used in writing the article:
Source: https://habr.com/ru/post/272089/
All Articles