NetApp becomes more efficient with inline dedupe
A few days ago the Data ONTAP 8.3.2RC1 version became available. “RC” means Release Candidate, and therefore, in accordance with NetApp’s version naming rules, this release has already passed all internal tests and can be used by customers not only to evaluate new features, but also for production, including the systems that run the business -critical tasks. Vendor support is fully extended to systems running on “RC” versions of Data ONTAP.
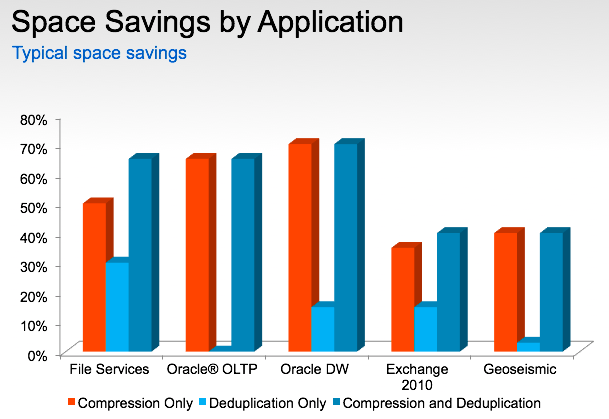
NetApp vendors (yes, this we too;) do not get tired of reminding (and they do it perfectly) that high utilization of disk resources in NetApp systems is achieved through the use of optimization software - deduplication and compression.
The information below is a brief overview of the capabilities of NetApp Data ONTAP 8.3.2RC1, which will be useful for “not bison”.
')
Deduplication has been available to customers for a very long time and, since its inception, has been working exclusively in “offline” mode - a process is started according to a schedule that searches for duplicate data blocks and leaves only one of them on disk. The system at the same time not only compares the hash sums from the blocks, but also the data itself, which guarantees the absence of hash collisions.
This avoids performance issues — turning on deduplication will not lead to any changes in the CPU / memory load on the storage system. However, for a number of tasks such a deduplication mechanism is not optimal. Imagine that you have a farm of multiple virtual desktops (VDI) and you need to update the software on all sites or install a patch for the OS. At this time, many identical data blocks will be written to the disks. Yes, of course, then the process of deduplication will go through and the “extra” disk space will be freed, but the update itself will lead to a huge number of write operations. This means that we will get an overloaded back-end and, as a result, this may affect the performance of other services working with this storage system.
With the advent of cDOT 8.3.2, NetApp storage owners have a solution - inline dedupe (on-the-fly deduplication). For All Flash, the inline dedupe support is enabled out of the box on all newly created volumes, and can also be enabled on already existing data volumes (without recreating the volume). For storage systems using the Flash Pool, online deduplication only works for writing to the SSD and can also be enabled on both new and already created volumes. For systems built on conventional disks, it is necessary to enable the forced mode. Inline deduplication can be controlled by the command
volume efficiency through the option -inline-deduplication (true / false):
volume efficiency modify -vserver SVM_test -volume / vol / volume-001 -inline-deduplication true
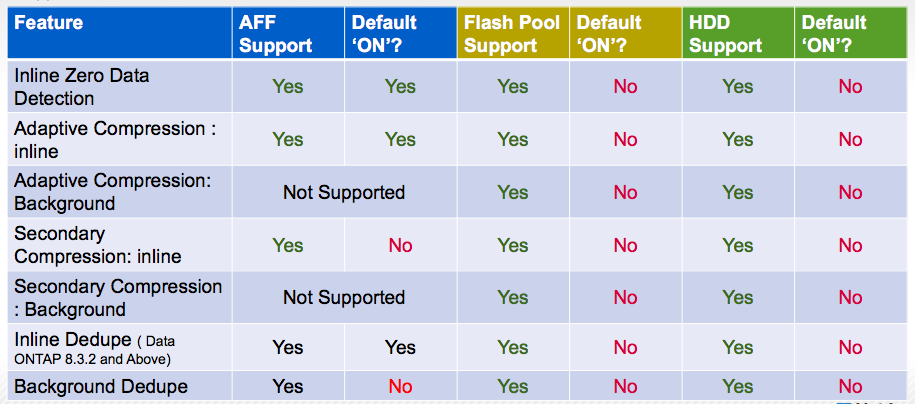
Below is a table of supported optimization modes for AFF and other NetApp FAS systems:
Dtata ONTAP allocates approximately 1% of the total RAM to store the hashes of recorded blocks. To maintain high performance, developers had to abandon global deduplication - it would require too much memory and processor resources to implement. Only the hash of recently recorded blocks is stored in memory — upon reboot, the storage will be cleared and statistics will be accumulated again.
Another important feature is that data migration (Data Motion) will cause all the benefits of deduplication to disappear until postprocessing is completed. This should be considered when planning the transfer of deduplicated data within the system.
To increase the efficiency of inline dedupe, it is possible to use it with the “classical” post-processing scheme. For All Flash, storage postprocessing is initially disabled (to minimize the total number of write operations), so it will need to be turned on forcibly.
The use of inline deduplication does not negate other possibilities for increasing the efficiency of data storage in NetApp storage systems. When simultaneously enabling online compression and deduplication, the order of operation will be as follows:
Due to the rejection of global deduplication, Data ONTAP developers managed to implement a rather interesting write optimization mechanism that works well for a number of types of workload and has a minimal impact on system performance. And by reducing the load on the back-end, in some cases we can talk about an increase in the integrated performance of the system. Anyone with a NetApp system (supporting cDOT 8.3) can test the effectiveness of inline deduplication by upgrading to version 8.3.2RC1. Of course, it is desirable to conduct experiments on test systems or as part of the pilots - we will not advise anyone to reconfigure the working production before the New Year :)
In our work, we had to deal with a variety of situations, to the extent that during the post-process deduplication operation, the system performance was not enough for the main load. All this can and should be assessed at the project development stage, laying the necessary power reserve when choosing a data storage system. Trinity specialists have extensive knowledge and extensive experience in conducting pre-project research and storage sizing for a variety of customer requirements.
Read more reviews on Trinity's blog .
And also take advantage of the Trinity practices:
NetApp vendors (yes, this we too;) do not get tired of reminding (and they do it perfectly) that high utilization of disk resources in NetApp systems is achieved through the use of optimization software - deduplication and compression.
The information below is a brief overview of the capabilities of NetApp Data ONTAP 8.3.2RC1, which will be useful for “not bison”.
')
Deduplication has been available to customers for a very long time and, since its inception, has been working exclusively in “offline” mode - a process is started according to a schedule that searches for duplicate data blocks and leaves only one of them on disk. The system at the same time not only compares the hash sums from the blocks, but also the data itself, which guarantees the absence of hash collisions.
This avoids performance issues — turning on deduplication will not lead to any changes in the CPU / memory load on the storage system. However, for a number of tasks such a deduplication mechanism is not optimal. Imagine that you have a farm of multiple virtual desktops (VDI) and you need to update the software on all sites or install a patch for the OS. At this time, many identical data blocks will be written to the disks. Yes, of course, then the process of deduplication will go through and the “extra” disk space will be freed, but the update itself will lead to a huge number of write operations. This means that we will get an overloaded back-end and, as a result, this may affect the performance of other services working with this storage system.
With the advent of cDOT 8.3.2, NetApp storage owners have a solution - inline dedupe (on-the-fly deduplication). For All Flash, the inline dedupe support is enabled out of the box on all newly created volumes, and can also be enabled on already existing data volumes (without recreating the volume). For storage systems using the Flash Pool, online deduplication only works for writing to the SSD and can also be enabled on both new and already created volumes. For systems built on conventional disks, it is necessary to enable the forced mode. Inline deduplication can be controlled by the command
volume efficiency through the option -inline-deduplication (true / false):
volume efficiency modify -vserver SVM_test -volume / vol / volume-001 -inline-deduplication true
Below is a table of supported optimization modes for AFF and other NetApp FAS systems:
Dtata ONTAP allocates approximately 1% of the total RAM to store the hashes of recorded blocks. To maintain high performance, developers had to abandon global deduplication - it would require too much memory and processor resources to implement. Only the hash of recently recorded blocks is stored in memory — upon reboot, the storage will be cleared and statistics will be accumulated again.
Another important feature is that data migration (Data Motion) will cause all the benefits of deduplication to disappear until postprocessing is completed. This should be considered when planning the transfer of deduplicated data within the system.
To increase the efficiency of inline dedupe, it is possible to use it with the “classical” post-processing scheme. For All Flash, storage postprocessing is initially disabled (to minimize the total number of write operations), so it will need to be turned on forcibly.
The use of inline deduplication does not negate other possibilities for increasing the efficiency of data storage in NetApp storage systems. When simultaneously enabling online compression and deduplication, the order of operation will be as follows:
- inline zero-block reduplication - empty (filled with zero) blocks are excluded
- inline compression - data is compressed
- inline deduplication - compressed blocks are checked for hash identity; if the hashes match, they are compared entirely if the hashes match and duplicate blocks are excluded from writing to disks
Due to the rejection of global deduplication, Data ONTAP developers managed to implement a rather interesting write optimization mechanism that works well for a number of types of workload and has a minimal impact on system performance. And by reducing the load on the back-end, in some cases we can talk about an increase in the integrated performance of the system. Anyone with a NetApp system (supporting cDOT 8.3) can test the effectiveness of inline deduplication by upgrading to version 8.3.2RC1. Of course, it is desirable to conduct experiments on test systems or as part of the pilots - we will not advise anyone to reconfigure the working production before the New Year :)
In our work, we had to deal with a variety of situations, to the extent that during the post-process deduplication operation, the system performance was not enough for the main load. All this can and should be assessed at the project development stage, laying the necessary power reserve when choosing a data storage system. Trinity specialists have extensive knowledge and extensive experience in conducting pre-project research and storage sizing for a variety of customer requirements.
Read more reviews on Trinity's blog .
And also take advantage of the Trinity practices:
- Server configurator - convenient for any level of IT specialist training
- Storage Configurator - you can quickly pick up the storage or talk with the manager
- Recovered RS Trinity servers are super affordable. Telecom and SMB love them :)
Source: https://habr.com/ru/post/272083/
All Articles