Architecture and technological approaches to processing BigData on the example of "1C-Bitrix BigData: Personalization"
In September of this year, a conference devoted to big data, BigData Conference , was held in Kiev. According to the old tradition, we publish in our blog some of the materials presented at the conference. And we begin with the report of Alexander Demidov .
Now many online stores have realized that one of the main tasks for them is to increase their own efficiency. Take two stores, each of which attracted 10 thousand visitors, but one made 100 sales, and the other 200. It seems that the audience is the same, but the second store works twice as efficiently.
The topic of data processing, processing models of visitors to stores is relevant and important. How do traditional models work in which all connections are established manually? We make up the correspondence of the goods in the catalog, make up bundles with accessories, and so on. But, as an ordinary joke says:
')

It is impossible to foresee such a connection and sell something completely unrelated to the buyer to the buyer. But the next woman, who is looking for a green coat, we can recommend the very red bag on the basis of a similar pattern of behavior of the previous visitor.
Such an approach very vividly illustrates the case associated with the Target retail chain. One day an angry visitor came to them and called the manager. It turned out that the online store in its mailing list of the minor daughter of this very visitor sent an offer for pregnant women. The father was extremely indignant at this fact: “What are you doing? Is she a minor, how pregnant is she? ” He quarreled and left. After a couple of weeks, it turned out that the girl was actually pregnant. Moreover, the online store found out about this before her on the basis of an analysis of her preferences: the products she ordered were compared with the models of other visitors who acted roughly according to the same scenarios.
The result of the work of analytical algorithms for many looks like magic. Naturally, many projects want to implement such analytics. But there are few players on the market with a large enough audience so that you can really count and predict something. These are mainly search engines, social networks, large portals and online stores.
When we thought about introducing the analysis of big data into our products, we asked ourselves three key questions:
There are very few large online stores with millions of audiences, including on our platform. However, the total number of stores using “1C-Bitrix: Site Management” is very large, and all together they cover an impressive audience in various segments of the market.
As a result, we organized an internal startup within the project. Since we did not know which end to take, we decided to start by solving a small problem: how to collect and store data. This small prototype was drawn in 30-40 minutes:
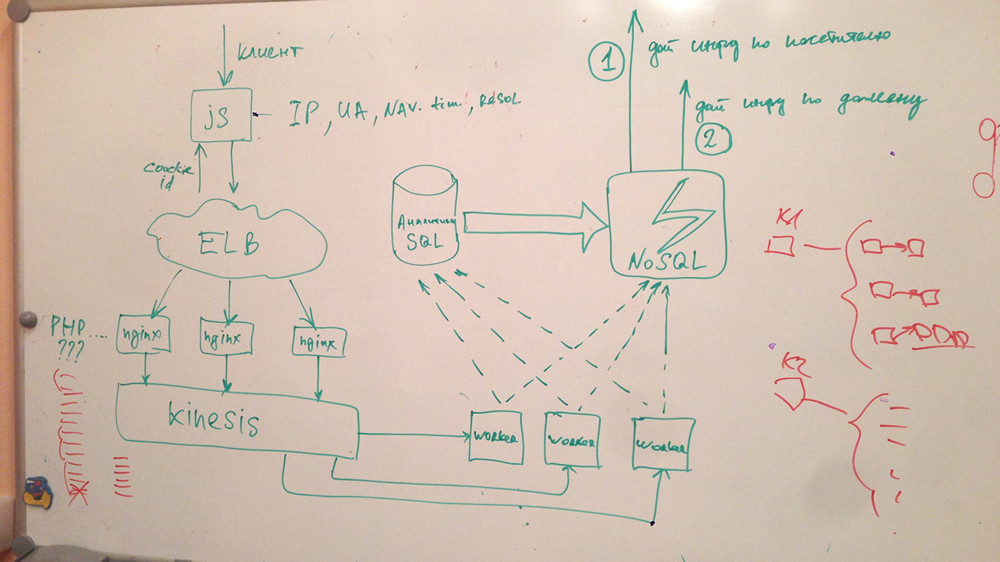
There is a term MVP - minimum viable product, a product with minimal functionality. We decided to start collecting technical metrics, page loading speed from visitors, and provide users with analytics on the speed of their project. This had nothing to do with personalization or BigData, but it did allow us to learn how to handle the entire audience of all visitors.
In JavaScript, there is a tool called the Navigation Timing API, which allows you to collect data on page speed, DNS resolve, network transfer, Backend work, page rendering on the client side. All this can be broken down into various metrics and then issued to the analyst.

We figured out how much approximately the stores are working on our platform, how much data we need to collect. There are potentially tens of thousands of sites, tens of millions of hits per day, 1000-1500 requests for recording data per second. There is a lot of information, where to save it in order to work with it later? And how to ensure for the user the maximum speed of the analytical service? That is, our JS counter is not only obliged to respond very quickly, but it should not slow down the page loading speed.
Our products are mainly built on PHP and MySQL. The first desire was to simply save all the statistics in MySQL or in any other relational database. But even without tests and experiments, we realized that this is a dead end option. At some point, we simply do not have enough performance either when writing or when retrieving data. And any failure on the side of this base will lead to the fact that either the service will work extremely slowly, or it will be out of order at all.

Considered different NoSQL solutions. Since we have a large infrastructure deployed in Amazon, we first paid attention to DynamoDB. This product has a number of advantages and disadvantages compared to relational databases. When recording and scaling, DynamoDB works better and faster, but it will be much more difficult to make some complex samples. There are also issues with data consistency. Yes, it is provided, but when you need to constantly select some data, it’s not a fact that you always select the actual ones.
As a result, we began to use DynamoDB for aggregation and subsequent release of information to users, but not as a repository for raw data.
We considered column databases that work no longer with strings, but with columns. But due to poor performance, the recording had to be rejected.
Choosing an appropriate solution, we discussed a variety of approaches, starting with writing a text log :) and ending with the services of the ZeroMQ, Rabbit MQ, etc. queues. However, in the end, they chose a completely different option.
Coincidentally, by that time, Amazon had developed the Kinesis service, which was perfectly suited for the primary data collection. It is a kind of large high-performance buffer, where you can write anything. He very quickly receives the data and reports on the successful recording. Then you can quietly work with information in the background: make selections, filter, aggregate, etc.
Judging from the data provided by Amazon, Kinesis should have been able to easily handle our workload. But a number of questions remained. For example, the end user - the site visitor - could not write data directly to Kinesis; To work with the service, you need to "sign" requests using a relatively complex authorization mechanism in Amazon Web Services v. 4. Therefore, it was necessary to decide how to make Frontend send data to Kinesis.
Considered the following options:
As a result, we decided to bet on Lua.
The language is very flexible, it allows processing both the request and the response. It can be embedded in all phases of request processing in nginx at the level of rewriting, logging. It is possible to write any subqueries, and non-blocking, with the help of some methods. There is a bunch of additional modules for working with MySQL, with cryptographic libraries, and so on.
For two or three days we studied the functions of Lua, found the necessary libraries and wrote a prototype.
On the first load test, of course ... everything fell. I had to configure Linux for heavy loads - to optimize the network stack. This procedure is described in many documents, but for some reason it is not done by default. The main problem was the lack of ports for outgoing connections to Kinesis.
We expanded the range, set up timeouts. If you use a built-in firewall, such as Iptables, then you need to increase the size of the tables for it, otherwise they will overflow with very many requests. At the same time it is necessary to adjust the size of any backlog for the network interface and for the TCP stack in the system itself.
After that, everything worked successfully. The system began to properly process 1000 requests per second, and for this we had one virtual machine.
At some point, we still rested against the ceiling and began to receive errors “
It was possible to solve the problem by setting up keepalive connections in nginx.
A machine with two virtual cores and four gigabytes of memory easily processes 1000 requests per second. If we need more, then either we add resources to this machine, or we scale it horizontally and place 2, 3, 5 such machines behind any balancer. The solution is simple and cheap. But the main thing is that we can collect and save any data in any quantity.
It took about a week to create a prototype collecting up to 70 million hits per day. Ready service "Speed sites" for all customers "1C-Bitrix: Site Management" was created in one month by the efforts of three people. The system does not affect the speed of display sites, has internal administration. The cost of Kinesis services is $ 250 per month. If we did everything on our own hardware, wrote our entire solution on any storage, it would have been much more expensive in terms of maintenance and administration. And much less reliable.

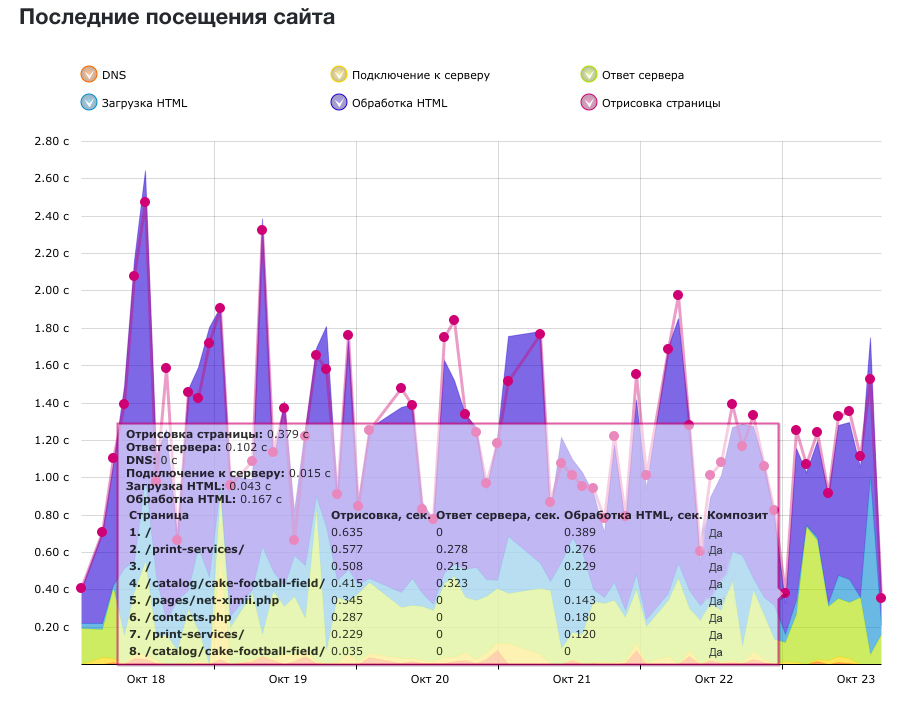
The general scheme of the system can be represented as follows:
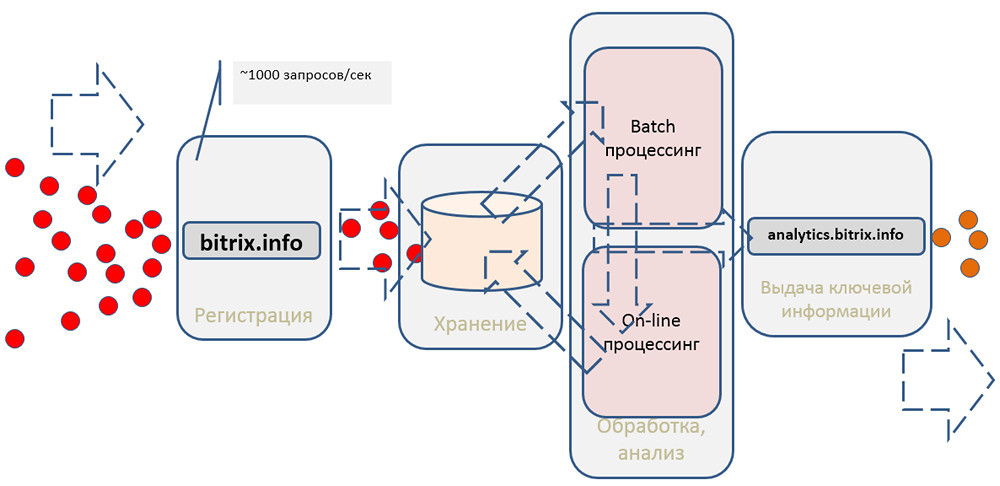
It should register events, save, perform some processing and give something to clients.
We created a prototype, now we need to move from technical metrics to the assessment of business processes. In fact, we do not care what we collect. You can send anything:
and so on.
Hits can be categorized by event type. What we are interested in from the point of view of the store?
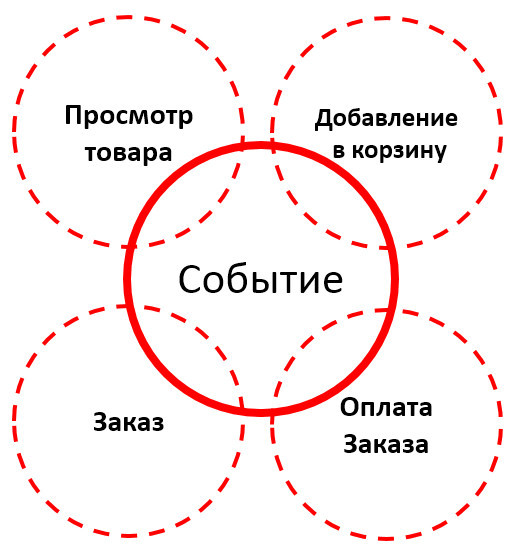
We can collect and link all technical metrics to business metrics and subsequent analytics that we need. But what to do with this data, how to process them?
A few words about how the recommendation systems work.
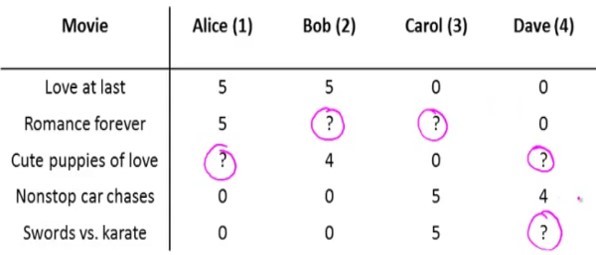
The key mechanism that allows visitors to recommend some products is the collaborative filtering mechanism. There are several algorithms. The simplest is user-user matching. We compare the profiles of two users, and based on the actions of the first of them, we can predict for another user who performs similar actions, that the next moment he will need the same product that the first user ordered. This is the most simple and logical model. But she has some cons.
Amazon has invented another algorithm for its online store - item-item: matches are established not by users, but by specific products, including those that are bought along with the “main” ones. This is most relevant to increase sales of accessories: a person who has bought a phone can be recommended a case, charging, or something else. This model is much more stable, because goods conformity rarely changes. The algorithm itself is much faster.
There is one more approach - content based-recommendations. Sections and products that the user was interested in and his search queries are analyzed, after which the user’s vector is drawn up. And as prompts are those products whose vectors are closest to the vector of the user.

You can not choose any one algorithm, and use them all, combining with each other. What are the tools for this:
In our project we made a choice in favor of Spark.
We read data from Kinesis using simple PHP workers written in PHP. Why PHP? Just because it is familiar to us, and so it is more convenient for us. Although Amazon has an SDK to work with their services for almost all popular languages. Then we do the primary filtering of hits: we remove the numerous hits of search bots, etc. Next, send the statistics, which we can immediately give online, to Dynamo DB.
The main data array for further processing, for building models in Spark, etc. we save to S3 (instead of traditional HDFS, we use Amazon’s storage). Subsequent math, algorithms for collaborative filtering and machine learning is handled by our cluster of recommendations, built on the basis of Apache Mahout.
Using cloud infrastructure and off-the-shelf Amazon AWS services saves us a lot of effort, resources, and time. We do not need a large staff of administrators to maintain this system, we do not need a large team of developers. Using all of the above components allows you to get along with a very small number of specialists.
In addition, the entire system is much cheaper. It is more profitable to put all our terabytes of data in S3 than to raise separate servers with disk storages, to take care of backup, etc. It is much easier and cheaper to raise Kinesis as a ready-made service, start using it literally in a matter of minutes or hours, than setting up the infrastructure, administering it, and solving some low-level maintenance tasks.
For the developer of an online store that works on our platform, it all looks like a kind of service. To work with this service, a set of API is used, with which you can get useful statistics and personal recommendations for each visitor.
We can help to recommend similar products, which is convenient for the sales of accessories and some additional components:
Another useful mechanism is top products in terms of sales. You can argue that all this can be done without fiddling with big data. In the store itself - yes, you can. But the use of our statistics allows you to remove a considerable share of the load from the base of the store.
The client can use all these tools in any combination. The cloud service of personal recommendations is most fully integrated with the “1C-Bitrix: Site Management” platform itself, the store developer can very flexibly manage the block of recommendations issued: “mix in” the necessary items of products that you should always show; use sorting by price or by some other criteria, etc.
When building a user model, all statistics on his views are taken into account, and not just the current session. Moreover, all models are depersonalized, that is, each visitor exists in the system only in the form of a faceless ID. This allows you to keep your privacy.
We do not divide visitors depending on the stores that they visit. We have a single database, and each visitor is assigned a single identifier, no matter what shop he goes. This is one of the main advantages of our service, because small stores do not have a sufficiently large statistics, allowing reliably predict the behavior of users. And thanks to our single database, even a store with 10 visits per day can, with a high probability of success, recommend products that are of interest to this particular visitor.
The data may become outdated, so when building a user model, we will not take into account statistics a year ago, for example. Only data for the last month are taken into account.
What do the tools we offer look like on the site?
Block of personal recommendations, which can be on the main page. It is individual for each site visitor.
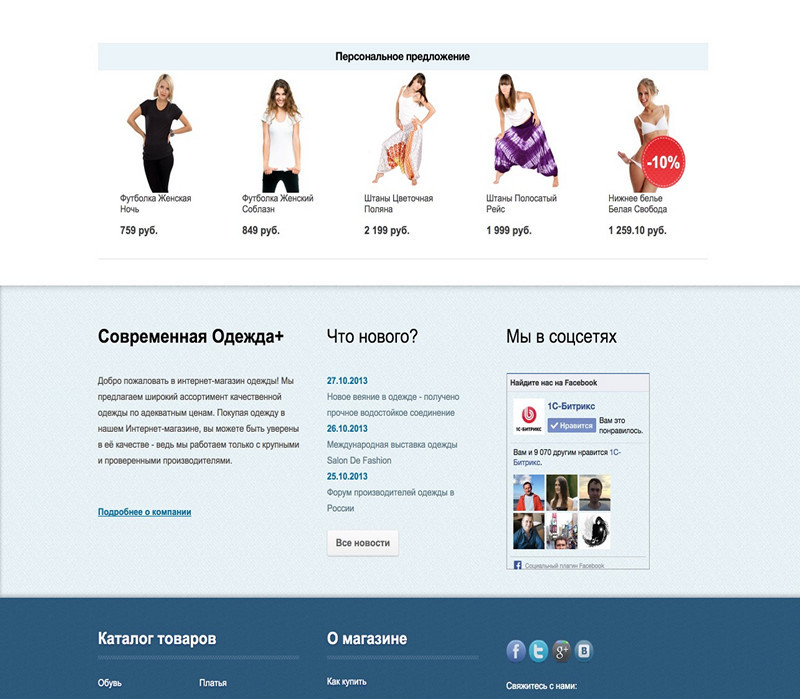
It can be displayed in the card of a specific product:
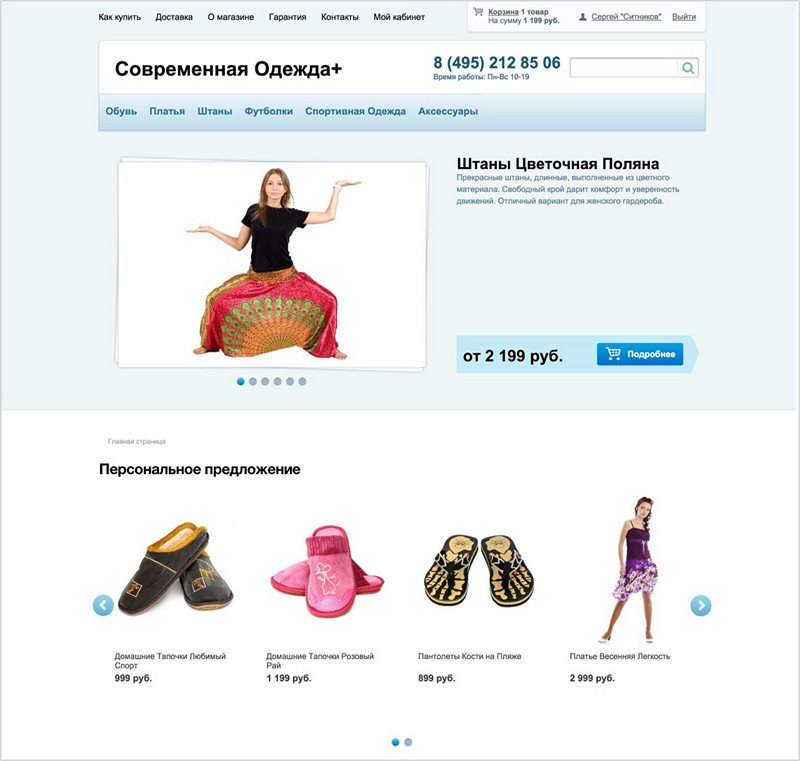
Example block of recommended products:
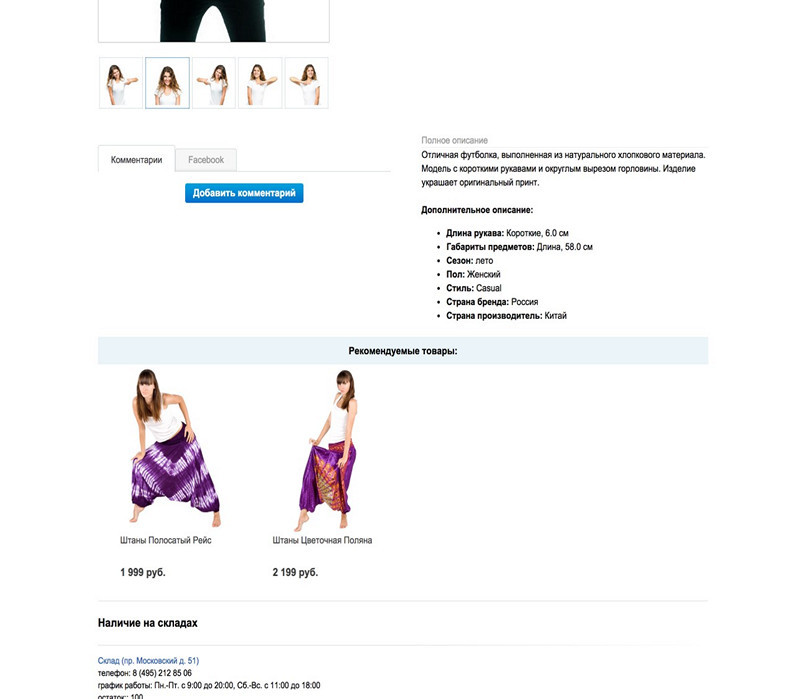
Blocks can be combined, looking for the most efficient combination.
Orders sold by personal recommendation are noted in the admin panel.
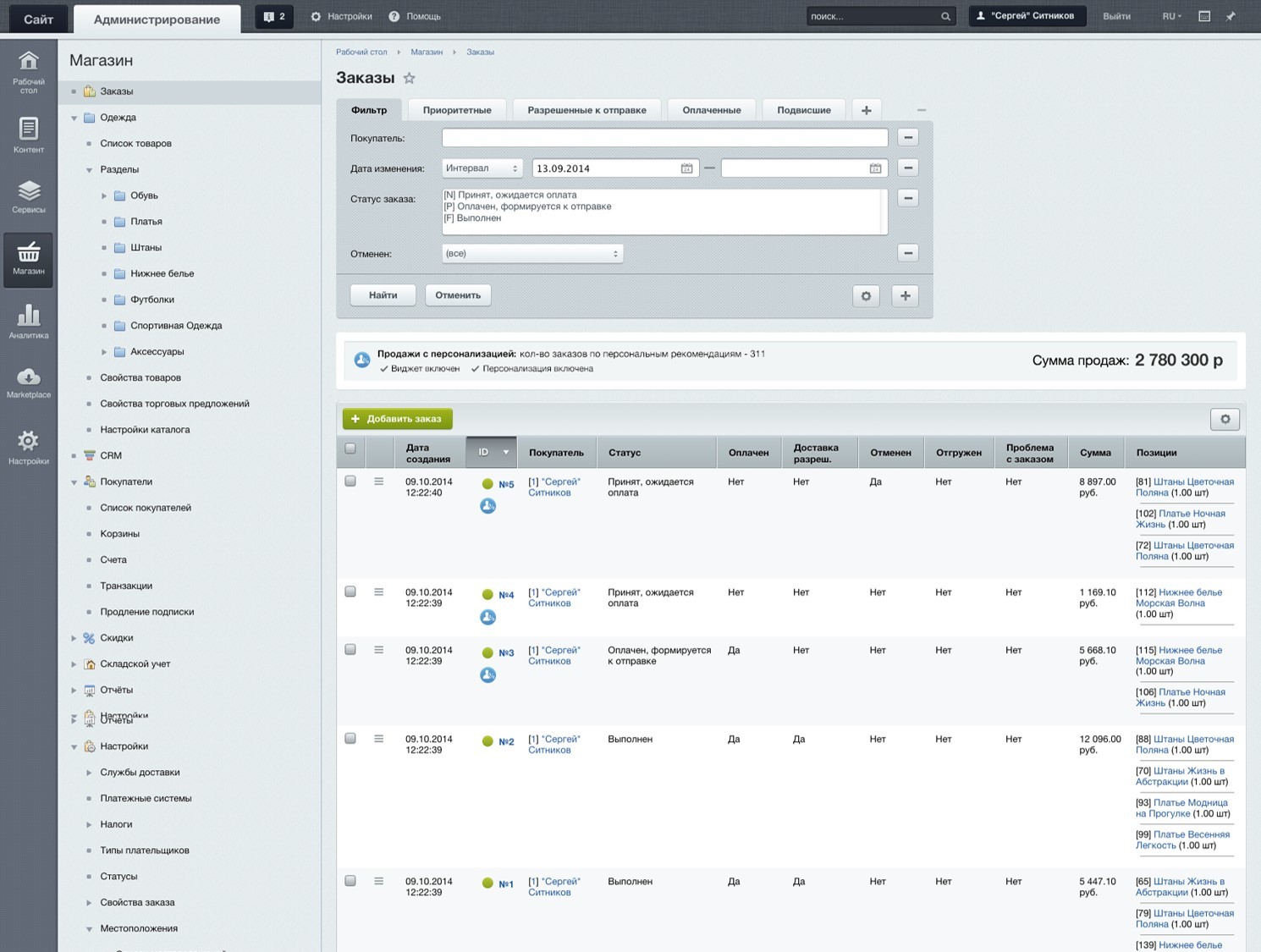
Employee processing orders, you can in the admin panel immediately display a list of goods that can be recommended to the buyer at check-in.
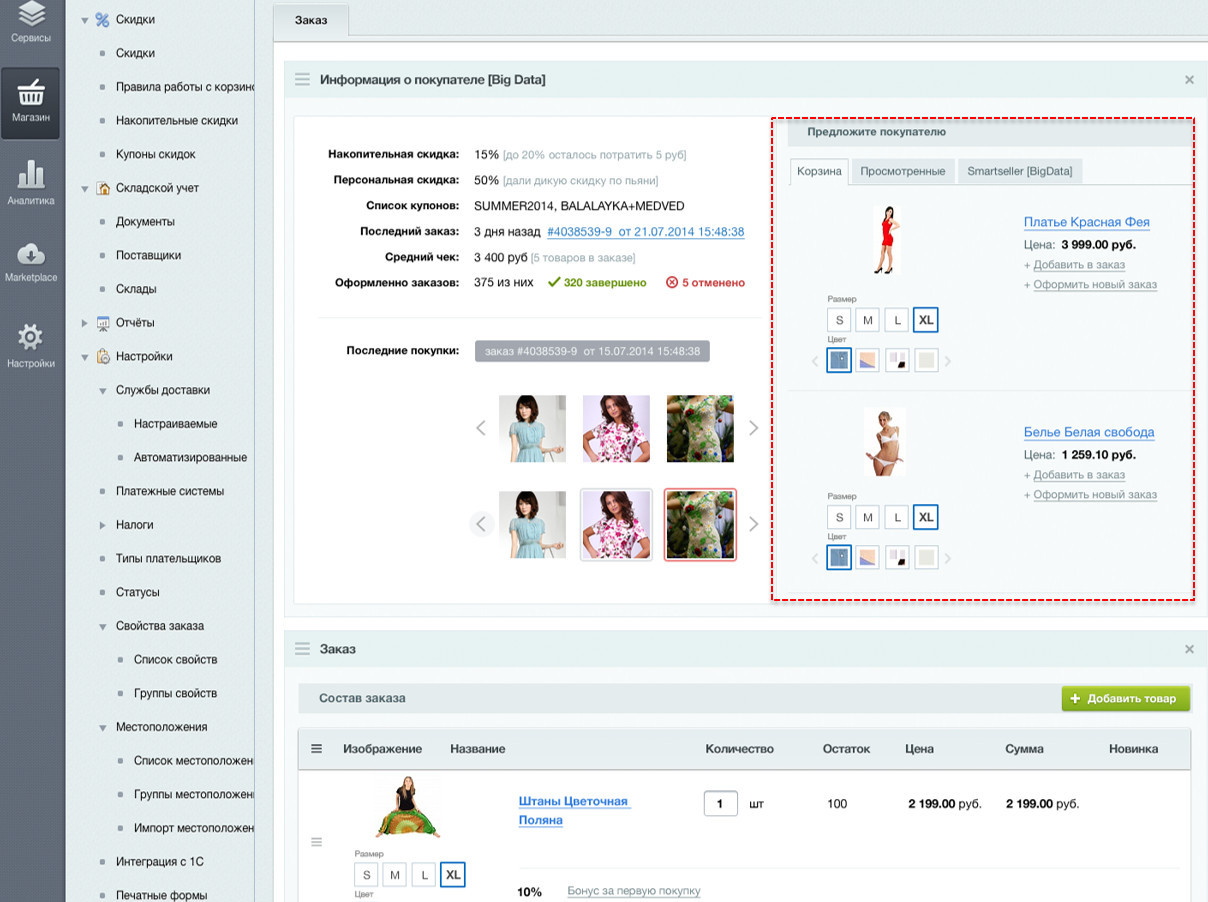
Unlike our tools, third-party recommendation services have an important drawback — a rather small audience. To use these services, you need to insert a counter and a widget to display recommendations. While our toolkit is very closely integrated with the platform, and allows us to refine the recommendations given to visitors. For example, a store owner can sort recommendations by price or availability; mix in the issuance of other products.
The main question arises: how effectively does all of the above work? How to measure efficiency in general?
Using A / B tests for working with personal recommendations in the near future will be available to online store owners, you can select and configure the necessary metrics directly in the admin panel, collect data for some time and evaluate the difference by comparing conversions from different audiences.
According to our data, our conversion growth is from 10 to 35%. Even 10% is a huge indicator for an online store in terms of investment. Instead of putting in more money in advertising and attraction, users work more efficiently with their audience.
But why such a large variation in the growth of conversion? It depends on the:
In the catalog, where there are few positions and few accessories, the growth will be less. In stores offering many additional positions, growth will be higher.
Where else can you use similar tools, in addition to online stores? Virtually any online project that wants to increase the audience. After all, a commodity unit can be not only something material. A product can be an article, any textual material, a digital product, a service, whatever.
The same models can be used to evaluate the audience and its willingness to move, for example, from free to paid tariffs, and vice versa. Or you can estimate the likelihood of users leaving to competitors. This can be prevented by some additional discount marketing action. Or if a client is about to buy a product or service, then you can make some interesting offer, thereby increasing the loyalty of the audience. Naturally, as much as possible all this can be used with trigger links. For example, the user who looked at some product, put it in the basket, but did not place an order, you can make a personal offer.
At the moment, 17 thousand stores operate on our platform, the system cheats up about 440 million events per month. The general product catalog contains about 18 million items. The proportion of orders on the recommendation of the total number of orders: 9–37%.
As you can see, there is a lot of data, and they are not a dead weight, but work and benefit. For the stores working on our platform, this service is now free. We have an open API that can be modified on the Backend side and provide more flexible recommendations to specific visitors.
Now many online stores have realized that one of the main tasks for them is to increase their own efficiency. Take two stores, each of which attracted 10 thousand visitors, but one made 100 sales, and the other 200. It seems that the audience is the same, but the second store works twice as efficiently.
The topic of data processing, processing models of visitors to stores is relevant and important. How do traditional models work in which all connections are established manually? We make up the correspondence of the goods in the catalog, make up bundles with accessories, and so on. But, as an ordinary joke says:
')
It is impossible to foresee such a connection and sell something completely unrelated to the buyer to the buyer. But the next woman, who is looking for a green coat, we can recommend the very red bag on the basis of a similar pattern of behavior of the previous visitor.
Such an approach very vividly illustrates the case associated with the Target retail chain. One day an angry visitor came to them and called the manager. It turned out that the online store in its mailing list of the minor daughter of this very visitor sent an offer for pregnant women. The father was extremely indignant at this fact: “What are you doing? Is she a minor, how pregnant is she? ” He quarreled and left. After a couple of weeks, it turned out that the girl was actually pregnant. Moreover, the online store found out about this before her on the basis of an analysis of her preferences: the products she ordered were compared with the models of other visitors who acted roughly according to the same scenarios.
The result of the work of analytical algorithms for many looks like magic. Naturally, many projects want to implement such analytics. But there are few players on the market with a large enough audience so that you can really count and predict something. These are mainly search engines, social networks, large portals and online stores.
Our first steps in using big data
When we thought about introducing the analysis of big data into our products, we asked ourselves three key questions:
- Do we have enough data?
- How will we process them? We do not have mathematicians in our staff, we do not have sufficient competence in working with “big data”.
- How to integrate all this into existing products?
There are very few large online stores with millions of audiences, including on our platform. However, the total number of stores using “1C-Bitrix: Site Management” is very large, and all together they cover an impressive audience in various segments of the market.
As a result, we organized an internal startup within the project. Since we did not know which end to take, we decided to start by solving a small problem: how to collect and store data. This small prototype was drawn in 30-40 minutes:
There is a term MVP - minimum viable product, a product with minimal functionality. We decided to start collecting technical metrics, page loading speed from visitors, and provide users with analytics on the speed of their project. This had nothing to do with personalization or BigData, but it did allow us to learn how to handle the entire audience of all visitors.
In JavaScript, there is a tool called the Navigation Timing API, which allows you to collect data on page speed, DNS resolve, network transfer, Backend work, page rendering on the client side. All this can be broken down into various metrics and then issued to the analyst.
We figured out how much approximately the stores are working on our platform, how much data we need to collect. There are potentially tens of thousands of sites, tens of millions of hits per day, 1000-1500 requests for recording data per second. There is a lot of information, where to save it in order to work with it later? And how to ensure for the user the maximum speed of the analytical service? That is, our JS counter is not only obliged to respond very quickly, but it should not slow down the page loading speed.
Data recording and storage
Our products are mainly built on PHP and MySQL. The first desire was to simply save all the statistics in MySQL or in any other relational database. But even without tests and experiments, we realized that this is a dead end option. At some point, we simply do not have enough performance either when writing or when retrieving data. And any failure on the side of this base will lead to the fact that either the service will work extremely slowly, or it will be out of order at all.
Considered different NoSQL solutions. Since we have a large infrastructure deployed in Amazon, we first paid attention to DynamoDB. This product has a number of advantages and disadvantages compared to relational databases. When recording and scaling, DynamoDB works better and faster, but it will be much more difficult to make some complex samples. There are also issues with data consistency. Yes, it is provided, but when you need to constantly select some data, it’s not a fact that you always select the actual ones.
As a result, we began to use DynamoDB for aggregation and subsequent release of information to users, but not as a repository for raw data.
We considered column databases that work no longer with strings, but with columns. But due to poor performance, the recording had to be rejected.
Choosing an appropriate solution, we discussed a variety of approaches, starting with writing a text log :) and ending with the services of the ZeroMQ, Rabbit MQ, etc. queues. However, in the end, they chose a completely different option.
Kinesis
Coincidentally, by that time, Amazon had developed the Kinesis service, which was perfectly suited for the primary data collection. It is a kind of large high-performance buffer, where you can write anything. He very quickly receives the data and reports on the successful recording. Then you can quietly work with information in the background: make selections, filter, aggregate, etc.
Judging from the data provided by Amazon, Kinesis should have been able to easily handle our workload. But a number of questions remained. For example, the end user - the site visitor - could not write data directly to Kinesis; To work with the service, you need to "sign" requests using a relatively complex authorization mechanism in Amazon Web Services v. 4. Therefore, it was necessary to decide how to make Frontend send data to Kinesis.
Considered the following options:
- Write a configuration on pure nginx that will be proxied to Kinesis. It did not work, the logic is too complicated.
- Nginx in the form of Frontend + PHP-Backend. It turned out difficult and expensive in terms of resources, because with so many requests, any Backend will sooner or later fail to cope, it will have to be horizontally scaled. And we still do not know whether the project will take off.
- Nginx + its own module in C / C ++. Long and difficult in terms of development.
- Nginx + ngx_http_perl_module. Option with the module blocking requests. That is, the request that came in this thread blocks the processing of other requests. Here are the same drawbacks as with the use of any Backend. In addition, the documentation for nginx explicitly stated: "The module is experimental, so anything is possible."
- Nginx + ngx_lua. At that time, we had not yet encountered Lua, but this module seemed curious. The piece of code you need is written directly to the nginx config in a language that is somewhat similar to JavaScript, or placed in a separate file. Thus you can implement the strangest, extraordinary logic that you need.
As a result, we decided to bet on Lua.
Lua
The language is very flexible, it allows processing both the request and the response. It can be embedded in all phases of request processing in nginx at the level of rewriting, logging. It is possible to write any subqueries, and non-blocking, with the help of some methods. There is a bunch of additional modules for working with MySQL, with cryptographic libraries, and so on.
For two or three days we studied the functions of Lua, found the necessary libraries and wrote a prototype.
On the first load test, of course ... everything fell. I had to configure Linux for heavy loads - to optimize the network stack. This procedure is described in many documents, but for some reason it is not done by default. The main problem was the lack of ports for outgoing connections to Kinesis.
/etc/sysctl.conf (man sysctl) # net.ipv4.ip_local_port_range=1024 65535 # TIME_WAIT net.ipv4.tcp_tw_reuse=1 # FIN_WAIT_2 net.ipv4.tcp_fin_timeout=15 # net.netfilter.nf_conntrack_max=1048576 # net.core.netdev_max_backlog=50000 # net.core.somaxconn=81920 # syncookies SYN net.ipv4.tcp_syncookies=0 We expanded the range, set up timeouts. If you use a built-in firewall, such as Iptables, then you need to increase the size of the tables for it, otherwise they will overflow with very many requests. At the same time it is necessary to adjust the size of any backlog for the network interface and for the TCP stack in the system itself.
After that, everything worked successfully. The system began to properly process 1000 requests per second, and for this we had one virtual machine.
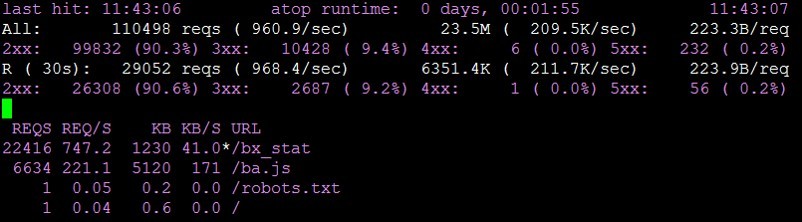
At some point, we still rested against the ceiling and began to receive errors “
connect() to [...] failed (99: Cannot assign requested address) while connecting to upstream ”, although the resources of the system have not yet been exhausted. According to LA, the load was close to zero, there is enough memory, the processor is far from overload, but it rested on something.It was possible to solve the problem by setting up keepalive connections in nginx.
upstream kinesis { server kinesis.eu-west-1.amazonaws.com:443; keepalive 1024; } proxy_pass https://kinesis/; proxy_http_version 1.1; proxy_set_header Connection ""; A machine with two virtual cores and four gigabytes of memory easily processes 1000 requests per second. If we need more, then either we add resources to this machine, or we scale it horizontally and place 2, 3, 5 such machines behind any balancer. The solution is simple and cheap. But the main thing is that we can collect and save any data in any quantity.
It took about a week to create a prototype collecting up to 70 million hits per day. Ready service "Speed sites" for all customers "1C-Bitrix: Site Management" was created in one month by the efforts of three people. The system does not affect the speed of display sites, has internal administration. The cost of Kinesis services is $ 250 per month. If we did everything on our own hardware, wrote our entire solution on any storage, it would have been much more expensive in terms of maintenance and administration. And much less reliable.
Recommendations and personalizations
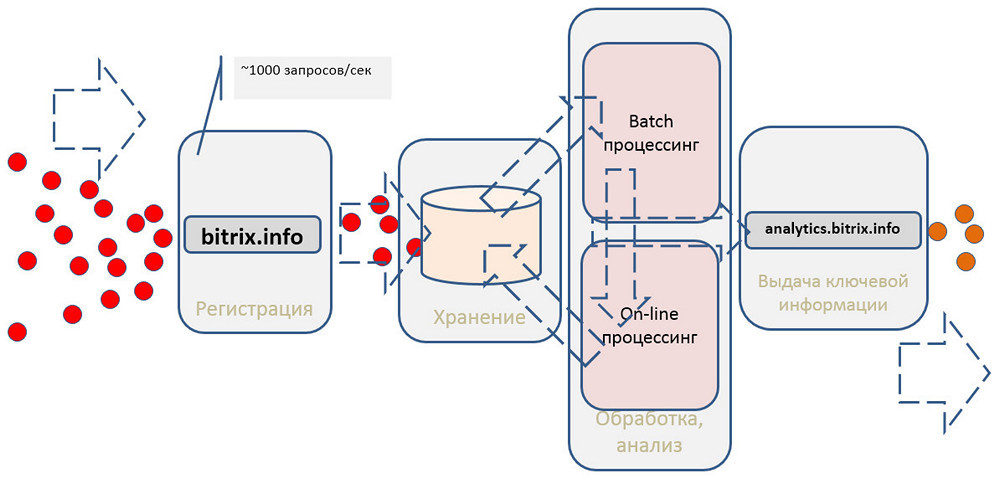
The general scheme of the system can be represented as follows:
It should register events, save, perform some processing and give something to clients.
We created a prototype, now we need to move from technical metrics to the assessment of business processes. In fact, we do not care what we collect. You can send anything:
- Cookies
- Hash license
- Domain
- Category, ID and product name
- ID recommendations
and so on.
Hits can be categorized by event type. What we are interested in from the point of view of the store?
We can collect and link all technical metrics to business metrics and subsequent analytics that we need. But what to do with this data, how to process them?
A few words about how the recommendation systems work.
The key mechanism that allows visitors to recommend some products is the collaborative filtering mechanism. There are several algorithms. The simplest is user-user matching. We compare the profiles of two users, and based on the actions of the first of them, we can predict for another user who performs similar actions, that the next moment he will need the same product that the first user ordered. This is the most simple and logical model. But she has some cons.
- First, there are very few users with the same profiles.
- Secondly, the model is not very stable. Users look at a variety of products, the matrix of conformity is constantly changing.
- If we cover the entire audience of our online stores, then there are tens of millions of visitors. And in order to find matches for all users, we need to multiply this matrix by itself. And the multiplication of such millions of matrices is a nontrivial task from the point of view of the algorithms and tools that we will use.
Amazon has invented another algorithm for its online store - item-item: matches are established not by users, but by specific products, including those that are bought along with the “main” ones. This is most relevant to increase sales of accessories: a person who has bought a phone can be recommended a case, charging, or something else. This model is much more stable, because goods conformity rarely changes. The algorithm itself is much faster.
There is one more approach - content based-recommendations. Sections and products that the user was interested in and his search queries are analyzed, after which the user’s vector is drawn up. And as prompts are those products whose vectors are closest to the vector of the user.
You can not choose any one algorithm, and use them all, combining with each other. What are the tools for this:
- • MapReduce. If you fully understand it, the use will not cause difficulties. But if you “float” in theory, the difficulties are guaranteed.

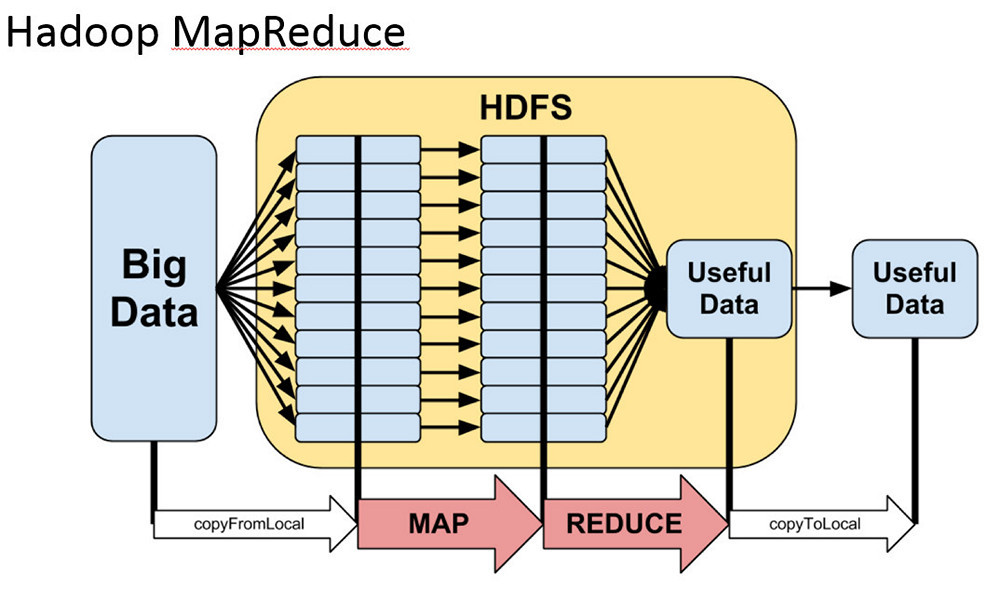
- • Spark. It works much faster than traditional MapReduce, because it stores all structures in memory and can reuse them. It is also much more flexible, it is more convenient to do complex samples and aggregations.

If you are programming in Java, then working with Spark will not cause much difficulty. It uses relational algebra, distributed collections, processing chains.
In our project we made a choice in favor of Spark.
The architecture of our project
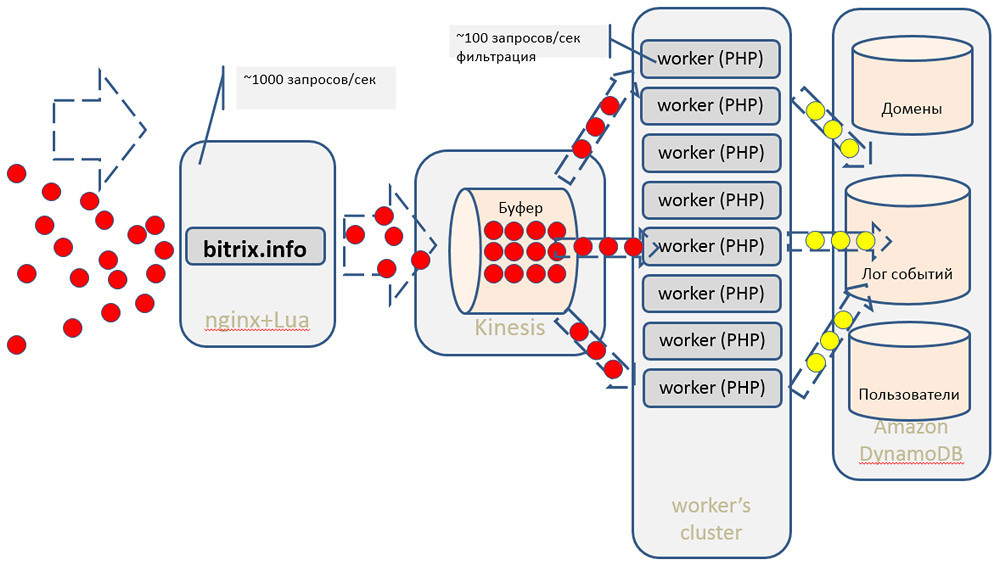
We read data from Kinesis using simple PHP workers written in PHP. Why PHP? Just because it is familiar to us, and so it is more convenient for us. Although Amazon has an SDK to work with their services for almost all popular languages. Then we do the primary filtering of hits: we remove the numerous hits of search bots, etc. Next, send the statistics, which we can immediately give online, to Dynamo DB.
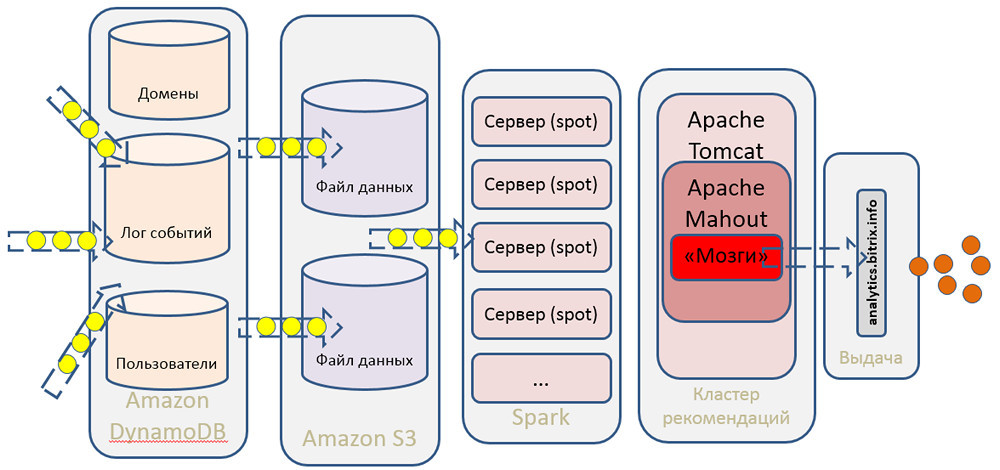
The main data array for further processing, for building models in Spark, etc. we save to S3 (instead of traditional HDFS, we use Amazon’s storage). Subsequent math, algorithms for collaborative filtering and machine learning is handled by our cluster of recommendations, built on the basis of Apache Mahout.
- For data processing, we use Apache Hadoop / MapReduce, Apache Spark, Dynamo DB (NoSQL).
- Apache Mahout is used for mathematical calculations, and large-scale processing of matrix multiplication is done using the MapReduce paradigm.
- Data is processed on dynamic computing clusters in the Amazon cloud.
- Storage is performed in an object Amazon S3 and partially in NoSQL DynamoDB.
Using cloud infrastructure and off-the-shelf Amazon AWS services saves us a lot of effort, resources, and time. We do not need a large staff of administrators to maintain this system, we do not need a large team of developers. Using all of the above components allows you to get along with a very small number of specialists.
In addition, the entire system is much cheaper. It is more profitable to put all our terabytes of data in S3 than to raise separate servers with disk storages, to take care of backup, etc. It is much easier and cheaper to raise Kinesis as a ready-made service, start using it literally in a matter of minutes or hours, than setting up the infrastructure, administering it, and solving some low-level maintenance tasks.
For the developer of an online store that works on our platform, it all looks like a kind of service. To work with this service, a set of API is used, with which you can get useful statistics and personal recommendations for each visitor.
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=recommend&uid=##&count=3&aid=#_#- uid - user cookie.
- aid - license hash.
- count - the number of recommendations.
{ "id":"24aace52dc0284950bcff7b7f1b7a7f0de66aca9", "items":["1651384","1652041","1651556"] } We can help to recommend similar products, which is convenient for the sales of accessories and some additional components:
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=simitems&aid=#_#&eid=#id_#&count=3&type=combined&uid=##- uid - user cookie.
- aid - license hash.
- eid Item ID
- type - view | order | combined
- ount - size of issue.
Another useful mechanism is top products in terms of sales. You can argue that all this can be done without fiddling with big data. In the store itself - yes, you can. But the use of our statistics allows you to remove a considerable share of the load from the base of the store.
analytics.bitrix.info/crecoms/v1_0/recoms.php?op=sim_domain_items&aid=#_#&domain=##&count=50&type=combined&uid=##- uid - user cookie.
- aid - license hash.
- domain - the domain of the site.
- type - view | order | combined
- ount - size of issue.
The client can use all these tools in any combination. The cloud service of personal recommendations is most fully integrated with the “1C-Bitrix: Site Management” platform itself, the store developer can very flexibly manage the block of recommendations issued: “mix in” the necessary items of products that you should always show; use sorting by price or by some other criteria, etc.
When building a user model, all statistics on his views are taken into account, and not just the current session. Moreover, all models are depersonalized, that is, each visitor exists in the system only in the form of a faceless ID. This allows you to keep your privacy.
We do not divide visitors depending on the stores that they visit. We have a single database, and each visitor is assigned a single identifier, no matter what shop he goes. This is one of the main advantages of our service, because small stores do not have a sufficiently large statistics, allowing reliably predict the behavior of users. And thanks to our single database, even a store with 10 visits per day can, with a high probability of success, recommend products that are of interest to this particular visitor.
The data may become outdated, so when building a user model, we will not take into account statistics a year ago, for example. Only data for the last month are taken into account.
Practical examples
What do the tools we offer look like on the site?
Block of personal recommendations, which can be on the main page. It is individual for each site visitor.
It can be displayed in the card of a specific product:
Example block of recommended products:
Blocks can be combined, looking for the most efficient combination.
Orders sold by personal recommendation are noted in the admin panel.
Employee processing orders, you can in the admin panel immediately display a list of goods that can be recommended to the buyer at check-in.
Unlike our tools, third-party recommendation services have an important drawback — a rather small audience. To use these services, you need to insert a counter and a widget to display recommendations. While our toolkit is very closely integrated with the platform, and allows us to refine the recommendations given to visitors. For example, a store owner can sort recommendations by price or availability; mix in the issuance of other products.
Quality metrics
The main question arises: how effectively does all of the above work? How to measure efficiency in general?
- We calculate the ratio of views on the recommendations to the total number of views.
- We also measure the number of orders made on the recommendation, and the total number of orders.
- We carry out measurements on the state-machines of users. We have a matrix with behavior models for a period of three weeks, we give some recommendations for them. Then we assess the state, for example, in a week, and compare the placed orders with the recommendations that we could give in the future. If they match, then we recommend correctly. If they do not match, it is necessary to twist or completely change the algorithms.
- A / B tests. You can simply divide the visitors of the online store into groups: one to show products without personal recommendations, the other with recommendations, and evaluate the difference in sales.
Using A / B tests for working with personal recommendations in the near future will be available to online store owners, you can select and configure the necessary metrics directly in the admin panel, collect data for some time and evaluate the difference by comparing conversions from different audiences.
According to our data, our conversion growth is from 10 to 35%. Even 10% is a huge indicator for an online store in terms of investment. Instead of putting in more money in advertising and attraction, users work more efficiently with their audience.
But why such a large variation in the growth of conversion? It depends on the:
- variety of assortment,
- themes,
- the total amount of goods on the site,
- the specifics of the audience
- bundles of goods.
In the catalog, where there are few positions and few accessories, the growth will be less. In stores offering many additional positions, growth will be higher.
Other uses
Where else can you use similar tools, in addition to online stores? Virtually any online project that wants to increase the audience. After all, a commodity unit can be not only something material. A product can be an article, any textual material, a digital product, a service, whatever.
- Mobile operators, service providers: identifying customers who are ready to leave.
- Banking sector: sale of additional services.
- Content projects.
- CRM.
- Trigger mailing.
The same models can be used to evaluate the audience and its willingness to move, for example, from free to paid tariffs, and vice versa. Or you can estimate the likelihood of users leaving to competitors. This can be prevented by some additional discount marketing action. Or if a client is about to buy a product or service, then you can make some interesting offer, thereby increasing the loyalty of the audience. Naturally, as much as possible all this can be used with trigger links. For example, the user who looked at some product, put it in the basket, but did not place an order, you can make a personal offer.
BigData project statistics: Personalization
At the moment, 17 thousand stores operate on our platform, the system cheats up about 440 million events per month. The general product catalog contains about 18 million items. The proportion of orders on the recommendation of the total number of orders: 9–37%.
As you can see, there is a lot of data, and they are not a dead weight, but work and benefit. For the stores working on our platform, this service is now free. We have an open API that can be modified on the Backend side and provide more flexible recommendations to specific visitors.
Source: https://habr.com/ru/post/272041/
All Articles