Paranoid job: disaster recovery / continuity plans, meteorite, zombie apocalypse, 1000 cleaners, portal to hell
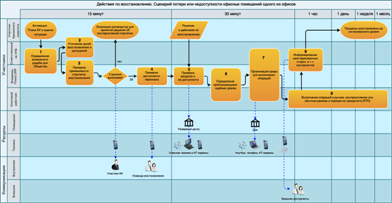
The scheme of working out the first level of the accident in the "Multicard"
There is such a myth that large companies did not have fault-tolerant infrastructures until around 2007. Like, it was then that the DRP (disaster recovery) documents began to appear, risk management departments stood out, and so on.
It is not true. Just before that there was no methodology and the English name, but the systems themselves were. The first project, which became “called by the rules”, was the infrastructure of “Alpha”. In Sberbank and Transneft, as far as I know, the fault-tolerant infrastructure has also been from time immemorial, but only called a “backup data center”. And so on.
')
And now we went to dispel other myths about DRP and continuity. Well, at the same time I will tell you about our last project - the emergency plans of Multicard, that is, the system through which all your payments by cards in Russia go.
And, of course, the stories of epic failures.
- Risk management is done after the first serious rake.
This is partly a myth, but precedents, of course, happen. Someone's data center burned down, someone got acquainted with an excavator on an optical line closer than he wanted, and so on. And does not want to repeat. But where more often the development of possible options for the problem is simply evaluated, and each option has a cost and probability. We multiply the probability by the cost and from the virtual event we get quite specific physical damage. Next is simple: if this damage is more than the cost of maintaining emergency procedures within the company, they will simply be a good investment.
Although historically in Moscow most of the serious plans began to be written in 2005. Then a lot of things back. Until 2005, it was possible to simply take the equipment to the next building, and this was considered the norm. When the substation fell and the power supply network half the city simply collapsed, many immediately received a new vision. Somewhere in the solar jams did not get to the data center. Somewhere, the diesel engine was not tested for two years, the diesel fuel was decomposed into fractions, and as a result, the diesel generator set was seized on a piece of water. I remember when VTB chose a place for a new data center (we helped a little), looked at the map of Moscow’s energy zones not the least.
- Estimation of the cost of damage is done on all the influencing factors.
Often not. In my memory, the direct damage from the accident was many times more than the amount that the company saw virtually.
An example of this: a fire in a data center building is two scenarios. The first is, in fact, the story of the "minus a million" to trigger the fire extinguishing and switch services to the backup data center. Direct technological costs. Then - non-operating ATMs (if it is a bank), customers leaving for other banks, scolding from the regulator and many more things that are difficult to assess.
Or the office is on fire. I know a case when a cigarette butt was thrown into an urn in an office in one of the banks. The urn began to fester, someone pressed the fire extinguishing start button. Firefighters arrived. At the entrance they were met by the chief IT specialist and a security man. They were upset, they held their hands and closed the entrance with their bodies, they said that it was not necessary to do anything, it was a cigarette butt. But the fire instruction. They took and poured the entire office foam half a meter from the floor. Directly on top of the included equipment and all papers. Then the standard procedure in banks is to seal the building for an investigation for a month. From an IT point of view, everything has to be transferred. This bank had jobs in reserve, since they have been writing plans for such situations for 30 years. Opened up, launched.
- This level of paranoia to write plans for continuity, is only in banks.
It is not, of course. For the last 7–8 years, four sectors are engaged in continuity: banks, insurance companies, telecom and retail. The first three are clear: in terms of the actual structure, they are banks, and the differences at the infrastructure level between the same mobile operator and large bank are often much less than between two Internet providers. Because they are engaged, in fact, the same. The myth is connected with the fact that only financial institutions have a regulatory base in the form of control at the level of the standards of the Central Bank and international things in the form of audits from parent organizations. All banks and most operators are checked once a year. In case of problems may revoke the license. Nobody wants to explain on TV why grandmothers could not get a pension.
There is a separate retail - as a rule, it focuses only on itself (on its profit) and understands perfectly well that simple is unacceptable. If you stand for a day, you lose your daily turnover plus a bunch of clients for the future.
And the sphere will grow, because the maturity of companies is increasing. And everyone understands what and why. In retail - competitiveness. And abroad, moreover, the insurance rate is also lower. The operator and the bank all the more important questions of public relations and so on. From the last major area, the auto industry began to bother strongly at DRP, but here the Western owner is squeezing, as a rule, considering continuity just a basic business standard.
- Disaster recovery - the work of the IT department.
Despite the fact that the main risks most often lie in the area of failure of IT infrastructure nodes, this is not what the IT department does. And not safe. And, of course, not the financial department. However, risk management initiatives usually come from these three points, so at first the company highlights the main IT risk, and it is IT professionals who begin to solve it (these are the stories of 2000–2005). As a rule, then a sober financial assessment of each stage of the business begins and an understanding emerges that there are other risks - a PR department, a support service (for example, for deploying a temporary office), personnel officers and others, others, and others are included in the process. As a result, there is a separate team or even a department that is concerned with risk minimization.
It usually happens like this: begin surveys of infrastructure and management processes. Methodologies are used very different - from ISO to ITIL. Perform a collection of threat options and analysis of their impact. Then policy making, the emergence of a continuity clause, emergency plans. When the base part is finished, there is a detalization on all processes: management of specific incidents, “emergency envelopes”, maintenance plans, elaboration of paranoid scenarios. There is a process of building continuity management. Then testing, teaching, working with personnel like "what to do", consultations.
Alas, there are not very many professionals on the market who can deliver DRP from start to finish in a large company. Financial qualifications, management and IT are required. Therefore, people can actually be counted on the fingers. As a rule, there is one bright personality in each bank and telecom, or according to a team that is tied specifically to a specific business and not very prepared for the specifics of the other.
From examples - we conducted consulting on the continuity of RosEurobank. The main part concerned management (risk management) - but yes, the result included work on both hardware and IT processes.
- Developing disaster recovery plans is very, very expensive.
Yes and no. The fact is that usually such work (it is about risk management in general, not only in IT) is entrusted to audit and consulting companies with a big name and a large portfolio of projects. I do not want to boast. But, actually, our similar services are banal cheaper, and at the same time we know business better, because at least a third of the large IT infrastructures in Russia we built with our own hands. Of course, we do not sell our name, but it is business continuity that we do well.
It should be noted that on the side of the "big four" - ideally licked on the western market methodology and good automated products (that is, they are a kind of "McDonalds" of the market). Quickly, predictably. But the student fries potatoes. Actually, this creates another consequence, which allows us to compete with these cool guys in Russia: they work exactly in the process, step to the left or to the right - shooting. And in the real business is not always suitable. The situation is even more fun (let's say, based on empirical experience and real events), when such a player enters our market, puts a huge price list, gets paid, and then hires someone from the local to subcontract. Naturally, they came to us with such offers.
“We must make a willpower DRP plan and not worry.”
Unfortunately, this will not work. It’s like security: you can't set the rules once and train everyone. When any new project appears in the company, it is immediately necessary to lay down requirements for both security and disaster recovery. For example, a service was made - it is necessary immediately at the level of internal standards to require that he be able to migrate to the second site in the data center, describe what and how to do in the event of an accident with him (extinguish or not during channel degradation), assign a recovery priority, update a set of documents for technical services, security personnel, IT department. Prescribe what preventive work is needed and when. And this is only the simplest.
External risks are constantly changing. For example, geopolitical risks after 2011 received priority. This means a change in all plans, sometimes even a change in the management processes themselves (for those with DRP at this level). Again, an example is when meetings were held in Moscow with the participation of 100 thousand people near the main office of a large Russian bank, he took and threw everything into a backup data center. Because riot policemen began to run around, but there is a sign that if riot policemen are running nearby, they can cut out the light.
Or a single large cellular operator was audited from the West . Under them made plans for continuity with a brick thickness. Nobody updated these plans. Several years have passed. New regions have appeared, the very structure of the operator has changed. And then in a distant galaxy began bespereboyniki began to fall in the data center. The engineer turns off the servers, and they turn back on. And such a carousel for about half an hour. A disaster recovery plan was included, and all IP addressing is new. Hey.
By the way, the on-off guessing was not related to DRP, but it was very funny. UPSs flew out - as a result, the servers began to warm up. The engineer extinguished them. At this time, the thermal shotdown turned off the battery. The load fell, it all cooled down, and then everything turned on automatically. The heating started again. As a result, the jumps went for another hour and a half after switching, while they were looking for a problem.
- A disaster recovery plan should take into account all situations.
Not usually. First, the essence of the plan is that problems do not happen (prevention). Secondly, as a rule, the introductory one - did not “turn off the power”, but “such a service does not work”. Why it does not work is not very important: a failed storage system, a destroyed data center, or actually food is a second time. Initially, you need to run this service on another site. SLA is not always prescribed for incidents, because there are internal standards or there are none at all for many situations.
Documents are needed such:

- Making active-active and not steaming!
In practice, experienced CIOs do not like balancing between data centers. The fact is that in my memory not a single story with active-active has passed the test of time. At first, everything looks perfect. The team comes in, does the balancing, the process begins. And then it stretches, stretches ...
In one system, 200–300 integration points — it’s impossible to monitor. Scenarios should be realistic. Even if the customer speaks about constantly updated plans and infrastructure, it is worth making trial testing. We do this for symbolic money, just for educational purposes. In my memory, no one passed. Customers themselves see where the real world begins.
I remember there were large-scale exercises with testing - they disconnected one of the active data centers in the active-active-backup scheme. This happened about a year after the balancing was done. The test plan was minutely, very detailed. Everything went well, but only when VMware switched, it suddenly became clear that there is a place where the difference of virtual loops rolls. Only the golden image itself in the second data center was a little behind the version. Literally a little bit. And now, when trying to hook the updated machines, the Linux cluster fell, like winter crops, into kernel panic. Instead of half an hour of downtime, it was 5 hours. Then scary words: "Do not hit the window."
This test was mild - it was not the switch that was jerked off, but just correctly isolated the main data center. On the other hand, I remember a completely different testing of office services. There, when the sites were switched to check the script, they did not plug all the holes in sync. And part of the call center calls and office traffic crawled in the wrong direction. The data are corrupted. And there are customer cards with transactions. Associated with approximately two hundred subsystems.
For example, the harmonization of contracts. The easiest process from negotiating a payment order to payment is 14 logical steps. In one of the stages, for example, the base recovered with a spread of 10 seconds. And that's it, hello documents. Oracle has risen? Yes. Is the base good? Yes. Documents can be used? Not. With accounting order? Well, almost - 40 kopecks balance does not converge. And the chief accountant of something, seeing it, rolls in hysterics.
Logically, you have to either pick your hands for a couple of months after a half-hour fall, or check the wiring logic automatically. That is why there are two consequences:
- Either tricky real-time monitoring systems are made when the passage is completed (ticked). And a request is made on all subsystems, whether it has passed. A bank from the top 5, for example, is clearly interested in such monitoring the integrity of all processes. They can have a translation there with 9 zeros in total. If you handle such a transaction, well, it will be a little sad.
- Or backup data center - this is exactly the reserve. No partial use, idle capacity utilization. If anything, we will reenergize and live up to six months in it, with the power of iron being sufficient.
- With DRP change processes.
No, only company management can change processes. During the work on the continuity of the processes, nobody touches the processes themselves. It is a question of how they work in terms of continuity. This may not be right or wrong - but this is a business point of view, not continuity. Business is more important. Our task is to characterize its risks and threats.
- Ok, let's do an emergency plan for the whole company next year and ...
Will not work. Probably. It works in small and medium businesses, but not in large ones. You cannot transfer the data center to DRP at a time when there are 270 subsystems. It is necessary to break into blocks and there is an elephant in pieces, slowly implement block switching.
Another feature is that many things with this approach will not in fact be accepted into pro-exploitation. Will work, but according to the documents - in test mode. The story is that escorts do not want to be taken raw (they do not sign papers without exact emergency plans).
Sometimes it saves people, I must say. I know a case when they mounted new equipment, "heavy" racks. The first feature of the room is the huge door through the entrance to the main hall. The second one was very thick tiles of the raised floor, and it was necessary to make cable entries in them. Began to drill. Upstairs is a dual sensor - temperature and smoke. Smoke draw. Would do in the west, the door would close and go gas. We, fortunately, were not put into operation, and therefore the door was locked by a block.
Or another question. How will DRP work if everything is in the head of the administrator? Favorite phrase from the tests: "Hmmmm ... How is it resolved?" Well, sort of, by DNS records ... Where are the IP addresses? Well, somewhere were recorded ... ".
- Stop scaring! Data centers are made by adults, and ...
... and they still fall, even in very adult and collected people. Examples:
- The largest in Russia independent payment processing system United Card Service failed for 5 hours and 20 minutes. Clients of 140 banks - UCS partners - could not use their cards, withdraw cash from ATMs. Thousands of transactions of Russians were stuck then. Full recovery of problems was complicated by the fact that it could not be performed remotely, without direct access to the servers in the data centers. In addition, for the restoration required a comprehensive diagnosis of the entire infrastructure. The use of backup systems was extremely risky and could lead to big data loss, since the reasons for the failure at the time of the accident were unclear.
- The failure of UCS on August 21 exceeded the scale of the failure of the NPCS, which occurred on April 29, 2015. Then, due to a failure in the securities system, operations with MasterCard and Visa cards were not served for more than four hours, approximately from 2:30 to 7:15 Moscow time. The failure was not of a system or programmatic nature.
- In September 2008, for several hours, 5% of Beeline subscribers were without communication. HLR for an hour raised their hands.
- On July 27, due to an accident at one of the VKontakte data centers, several services of the site were unavailable for several hours: photos, messages, posts on the walls. An hour after the problems had arisen, the company's specialists decided to completely shut down the site. According to unverified data - problems with cooling.
- The official website of the Institute of Scientific Information in Social Sciences (INION) of the Russian Academy of Sciences stopped working when a fire started in the library building. .
- , - «» « », . . , -9 ( 70 , , 6 ). .
- Sabre , . «». - , 15 .
- , - . . 4 — .
- D, - , 2 2013 . .
...
- , , :
- - - Samsung SDS Samsung (, ) .
- Facebook , , - . 1,3 Facebook . Forbes Magazine, 20- Facebook , - .
- 40% - , Google . Google, Gmail, YouTube Google Drive, . 5- 2012 Google $545,000 .
- 10 Blackberry EMEA (, ) . — Research In Motion .
- Amazon - Instagram, Netflix, Vine, Airbnb ( 26 2013 ).
- 5- - .
- - 2014-.
- 2010- Virgin Blue 11 . 15 20 . 50 .
- M1 — 1,2 — 2013 . 3 .
— . , , .
, , . . , .
— .
— .
— / / .
— , .
— .
— .
— .
— .
— .
— .
— - ( ).
— .
— .
— .
— .
— .
— .
— .
— .
— . (. . , ).
— -. .
— .
— .
— / .
— -.
— , .
— , . . . . . .
— , , ( ).
Links
Source: https://habr.com/ru/post/272015/
All Articles