Recognition of the Burmese language: now we can even

Maybe some of you will find this surprising, but a text similar to what you see in the picture (which is Burmese language) can also be recognized. Some time ago, there was an amusing comic strip on the Internet about the distinction of Asian languages, but it is too indecent to publish it in a corporate blog :) About why we needed to recognize Burmese and what problems we had to face at the same time - under the cut.
The Republic of Myanmar (formerly Burma) is a state in Southeast Asia. In 1962-2010 a military dictatorship operated in the country, and in the last 5 years Myanmar began to open up to the outside world — trade and cultural cooperation intensified.

')
It is clear that in such conditions, the neighbors have many opportunities to monitor the situation in the country - you never know.
At some point, one of our partners (and we work in Southeast Asia a lot and actively - and mainly through partners) brought us a project - we were required to do the character recognition (OCR) of the Burmese language. The final customer planned to do monitoring of Burmese print media - first recognize, and then translate by an automatic translator into English.
There are many dialects in Burmese, and there is a certain set of letters that is used in official communications, in the press, etc. It is approximately 30% of all letters used in the regions, it includes 33 consonants and 12 additional characters. We had to recognize the pictures on which were texts printed with this particular set of letters in the most popular typeface (Myanmar 3 font), font size - not less than 10. Images could be gray, black and white or color, resolution - not less than 300 dpi. For example, such:

At the first stage, we needed to show recognition accuracy of 75%, at the second - at least 94%.
There were no people owning Burmese in our motley linguistic company, so the developers who got the project had to learn the language from scratch.
The Burmese letter is a syllable, based on a syllabic alphabet - each consonant letter “by default” is pronounced along with a vowel sound [a]. Other vowel sounds are indicated by separate letters or auxiliary signs above, below, before, after, or even around the consonant letter (see examples in the table below).
By the way, it turned out that the Burmese letters are so round, which is why - when the Burmese letter originated, they wrote on palm leaves, and the inscription of straight lines would damage the leaves.
Burmese - tone. A tone is a sign that indicates how to pronounce a syllable — and the meaning of the syllable depends on it. There are three basic tones (high, low and creaky), as well as two other tones (explosive and lowered). The tone is indicated on the letter using special combinations of characters. The table shows how consonant letter combinations are written.
 with some vowels in each of the three basic tones.
with some vowels in each of the three basic tones.
That is, the Burmese language is a language with double diacritics (additional symbols can be located simultaneously under and above the main one). This, as we shall see, is of great importance in recognition.
In addition, some consonants in certain combinations can form ligatures.

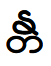
Those wishing to delve into the intricacies of Burmese recommend rather detailed Wikipedia articles about the Burmese language and the Burmese letter , and we will stop there and show how these features created additional difficulties for us in “connecting” the Burmese to our OCR technology.
Recall in brief how discrimination occurs at all. We get a picture with the text, process it (correct distortions, translate into b / w), then the blocks are defined on the page (titles, text, footnotes, pictures, tables, etc.), then the text blocks are parsed into separate lines, lines - for words, words - for letters, letters we recognize, then we collect everything back to the text of the page further along the chain. Since there was nothing special about image processing and blocking in the case of the Burmese language, we’ll start by telling immediately by dividing into lines.
Because of the double diacritics, short lines were poorly distinguished in our texts - and here's why. In our algorithms there are additional characteristics of the lines, one of them is the base line, on which the main characters are located. The baseline should be selected to correctly build hypotheses about certain characters and, accordingly, it is better to recognize them.
To highlight the baseline, we use statistics: we analyze histograms (projections of black points on the vertical), looking for peaks. On the histograms of European languages are clearly visible 3 pronounced peaks, which form the basis of the line (the baseline and the height of lowercase letters):

In Burmese language, a large number of characters that go beyond the boundaries of the main part of the line add additional significant peaks to the histogram. Therefore, the algorithms that are configured to recognize European languages did not quite correctly determine the main parameters of the string.
In the first two lines, the baseline was found correctly, in the third - incorrectly:

In order to correctly identify strings in the Burmese language, we had to additionally adjust the algorithm.
Once the lines are highlighted, we begin to look for spaces between words and signs in these lines. A histogram is also constructed, only horizontal, spaces are searched for and it is determined which of them are spaces and what is the distance between characters. There were practically no problems with the definition of gaps in Burmese - there are few of them in this writing, but there are (unlike the Thai, where there are almost no gaps - yes, we can recognize Thai, as well as about 200 other languages ).
After determining the spaces, we start working with text fragments (“words” - although this word is not very applicable to Burmese, parts of the sentence are separated by spaces in it), we begin to recognize each fragment separately. Fragments must be divided into characters. On the histogram, we again look for peaks and valleys (valleys are possible points of division). Some division points are more or less obvious, and special heuristics are used to test others. In European languages, the histogram looks like this:

Due to the fact that there are a lot of semicircular symbols in Burmese, we get a lot of “extra” peaks and valleys, this makes it difficult to select gaps, but we have coped with this problem.

In more detail the general theory of the selection of strings and characters is described in this post .
After determining the division points, we begin to recognize each character separately. In the article we use the word "symbols" because it is understood and known by everyone. But this is done only to simplify the text, in fact, we recognize not symbols, but graphemes. Grapheme is a specific way to graphically represent a symbol. The relationship between symbols and graphemes is quite complicated - in European languages, a single grapheme can correspond to several symbols (a small "c" and a large "C" in Latin and Cyrillic are all one grapheme), and a single symbol can correspond to several graphemes (the letter "a" in different fonts may be indicated by different graphemes).

A standard list of graphemes does not exist, we compile it ourselves and for each grapheme a list of characters is given that it can correspond to. Conversion from graphemes into symbols occurs after recognition of symbols at the stage of generating word recognition variants.
In Burmese, as we have already mentioned, there are a lot of diacritics, and most of the auxiliary characters, when written, merge with the main symbol, forming ligatures:

In general cases, if we recognize a character with a diacritic, and the diacritic in the image is separated from the main symbol, the following algorithm works for us: we recognize the main symbol first, then the diacritic, then we connect and get one grapheme. If we are dealing with a ligature, then we immediately try to recognize it entirely. Recognition occurs by comparing the symbol with the standards and selecting the most appropriate (similar options) - we wrote about it in more detail here . Since there are a lot of ligatures in Burmese, we had to train our algorithms for a much larger (than the average for the new language) number of new graphemes (about 3500 graphemes were added).
When we recognize a grapheme (that is, we understand that our combination of characters is it), we must translate it as Unicode characters (so that we can then assemble characters into words, words into text, and so on). In European languages, everything is simple here - we recognize the characters in order, one after the other, and in the same order we “give” back. With ligatures in the Burmese language, the situation is much more complicated.
There is a certain order of writing letters that must be followed when working with text editors so that Windows correctly converts into ligatures (and simply into complex “words”) what the user typed. Some characters must be typed (printed) at the end of a syllable - then Windows will put them at the beginning of the syllable and the syllable will be written correctly.
For example, to get this word in a text editor:

need to type the following sequence of characters

then Windows correctly displays the word. If you manually write this symbol

first, we get an error (errors are indicated by a dotted line):
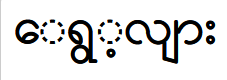
To collect just such a ligature
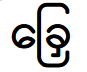
Be sure to observe the following character order:
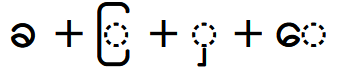
In the Burmese language, for the words that came from the Pali language, a two-level writing of consonants was adopted.
And there are a lot of such cases in Burmese.
Accordingly, the same rules should be observed when translating recognized characters, so that Windows will understand them correctly and automatically assemble them - and we should have taught our rules to these rules.
To check the observance of these rules, our technology has post-correction. It works like this: after we have recognized everything, we go through the text and check the order of characters in accordance with the rules of the language. As we wrote above, Burmese is a very well-structured language, and there are enough rules in it.
Here, in fact, all the surprises that the Burmese language gave us. We did all the work in 4 months and eventually achieved recognition accuracy of 97% (against the 94% that we promised the customer). In the future, most likely, add a description of other fonts.
Source: https://habr.com/ru/post/271977/
All Articles