Practical aspects of automatic generation of unique texts for SEO
The most terrible horror story for those who want to place computer-written content on their websites is search engine sanctions. We, too, at one time were frightened that the site with non-unique and / or generated texts would be poorly indexed or that it would fall under the ban. At the same time, no one could tell us the exact requirements for the texts. In general, the topic of unique content and its role in promoting websites is more similar to occult knowledge. Each next “expert” promises to open the horrible truth on his page, but the truth never opens, and the essence of many discussions on the forums comes down to what, say, Yandex recognizes the generated content using magic. Not in these words, but the point is this.
Since customers have recently turned to us with the task of creating descriptions for products on the site, we decided to study this issue in more detail. What algorithms exist for determining automatically written texts, what properties should the text have in order not to be recognized as web spam, and what tools can generate it?
In recent years, unique text (and generally text) has become a common tool that SEO experts recommend for promoting websites in search engines. In recent years, site owners realized that it was quite expensive to order text writing to people, because the prices for author texts were at all times in the range of $ 1- $ 3 per 1000 characters. It is clear that the owner of an online store, even with a modest assortment of 3-4 thousand items, must pay for texts from 300,000 rubles, and the waste is not one-time, since the assortment tends to be updated. Naturally, automatically generated product descriptions appeared on the site pages.
As a matter of fact, the search engine recognizes automatically generated content ...
... Of course, we do not know. But, the general principle of the method of secrecy does not constitute, and by turning to primary sources one can draw some reasonable conclusions about the limits of the possible. To begin with, there is an article with the promising title “Search for unnatural texts” [1] on the website of scientific publications of Yandex. It says about the following “in the unnatural text the distribution of pairs [words] should be disturbed ... the number of rare pairs that are uncharacteristic for the language should be overestimated compared to the standard, and the number of frequent pairs should be underestimated”. Thus, we are confronted with the first group of methods. That is, one way or another, this is about comparing the statistical parameters of a given text with the parameters of “natural” texts. In addition to the distribution of pairs, frequencies of n-grams of larger size can be used. In the more recent works [2], the frequencies of n-grams are not applied to the words themselves, but to parts of speech, when each part of speech is first defined (SUSCH-PRIL-SUSCH-GLAG), and then the frequencies of the received n-gram are counted, and so on .
')
It is clear that the most primitive descriptions generated by the substitution of the parameters of goods in the template text avoid this filter due to the fact that the original template is man-made and, accordingly, has natural characteristics. This is of course, provided that the pattern is smoothed by the correspondences of the kinds and cases so that nothing like “Buy a washing machine for 10399 rubles.”
Generators based on modern language models, such as neural network language models, are also very likely to avoid this filter, since the general rule says "to catch text generated by some language model, you must use a more advanced language model." A more advanced language model may be in short supply, and besides, it will require huge computational costs, so using it to define automatic texts on the Internet scale will simply be irrational.
But generators based on a language model, applied directly, generate texts that are devoid of meaning. For example, such “Reliability of water heaters“ ariston ”wins the rating of boilers”.
Since online store owners usually don’t want water heaters to win boiler ratings, they prefer simple template texts. But there is some potential difficulty here.
Template text is not distinguishable from natural as long as it is available in a single copy. Replicated, they become the subject of a second class of methods for defining machine texts. The essence of the method is that all texts written on the basis of the template are similar to each other with the exception of the parts where the parameters of a particular product are inserted. It turns out what is called in English literature "near dublicates" - almost duplicates. Search engines are able to determine them [3], using the well-known method of shingles and its improved versions. If an additional synonymizer is used, the number of unlikely language constructs will increase and the text will become identifiable for the first group of algorithms [1]. In addition, there are algorithms specifically directed against synonymizers - they remove from the text all words for which there are synonyms in the dictionary, and compare texts with the remaining words [4].
Thus, algorithms for recognition of computer-generated texts, being on the one hand rather complicated, still do not contain any magic and superintelligence. If desired, they can be reproduced for the purpose of testing texts, which is time consuming, but in general is not difficult.
Philosophical retreat
We are faced with the fact that there are people who consider computer texts to be evil, littering the Internet and intended to deceive users. But we believe that it can hardly be attributed to meaningful texts describing specific products by parameters. After all, these texts contain actually correct information about the product. Placing on the page such a text, we designate its contents for the search engine, so this is not a hoax of search engines or buyers.
Practice: How good are machine texts?
Taking into account the above, we stopped at a hybrid method of generating texts. In it, first the basic frame of the text is generated using a manually defined grammar (in more detail in the previous article ), and then a neural network analyzer is used above, which is trained to identify places where you can insert or delete certain classes of words without losing meaning. The need to create a generating grammar manually increases the cost of the solution, of course, but it still remains an order of magnitude smaller than ordering texts to a copywriter. Now the actual quality.
Readability :
“ Grohe Allure faucet Allure 19386000 from the new Allure collection, worth only 5800 rubles. Hidden installation provides increased convenience of operation and, of course, installation. The GROHE SilkMove system allows for extremely easy movement of the lever. The special coating produced by StarLight technology creates durability and maintains a good appearance of the product for many years. Vertical installation with two mounting holes is very convenient and should not cause difficulties. The amount of outflow spout here is 220 mm. A larger takeaway size makes it much easier to use the product. The entire product generally has a weight of 1.955 kg. The minimum pressure for this model is 1 bar. Electricity is not necessary. Free delivery and reliable, proven over the years, the quality of the well-known German brand are the main reasons to buy a Grohe Allure 19386000 mixer . ”
Of course, this is not a great literary work, but there are no obvious flaws. It is difficult to determine that the text is automatically generated, even for a person.
Uniqueness:
a) Global uniqueness. The essence of global uniqueness is that the text is unique relative to all other texts available on the Internet at the time of publication.
To test the global uniqueness, we used the well-known text.ru service (for the purposes of objectivity, in this article we present the results of the analysis from third-party services, and not the data of our algorithms).
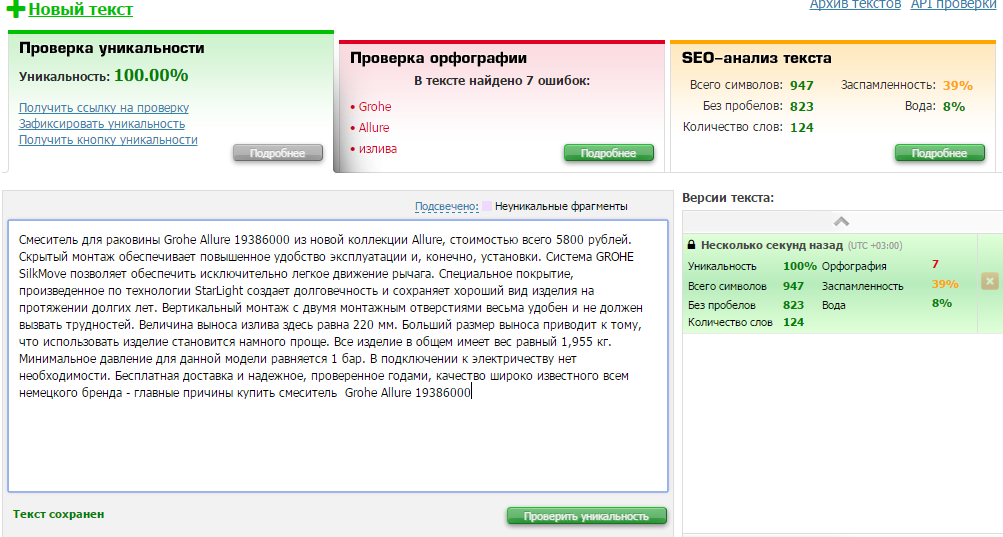
As you can see, there is no problem with global uniqueness. The service complains about spelling, but when considering errors, they are associated with the use of the words “Allure”, “StarLight” and other specific terms that the service does not know. Note: this is data before placing texts on the customer's site. Now, naturally, these texts can be found there.
b) Local uniqueness. As we have already said, too similar texts can be considered by the search engine as duplicates of each other, which can reveal their artificial origin. To do this, we used the service hosted on the site backlinkmanager (other implementations of comparison using the shingle algorithm give similar results)

Two texts about very similar models with the same parameters are similar by only 5%, and the similarity is largely due to the mention of the product name “Grohe Alira washbasin mixer”. We will consider this a good result, because there are not many ways to describe the same set of product parameters in different ways.
Indexing by search engines
The indexation of computer-generated texts was checked by us earlier on the example of the site reviewdot.ru. Pages on this site do not have unique content. Therefore, at first, this site did not want to get into the Yandex index (out of more than one hundred thousand pages in the index there were about 1,300 pieces). We struggled stubbornly with this by placing template texts first (the number of pages in the index grew to 5000), then using more complex generation algorithms like those discussed above. Today, the Yandex index has about 70,000 pages. Although what specifically influenced the situation - our efforts or changes in the algorithms of Yandex, we do not know. Nevertheless, the fact remains a fact - the pages containing automatically generated texts successfully fall into the index of search engines. Despite all the fears of SEO experts, themonsters did not appear that the site did not go under the sanctions of search engines, although there were theoretical grounds for that.
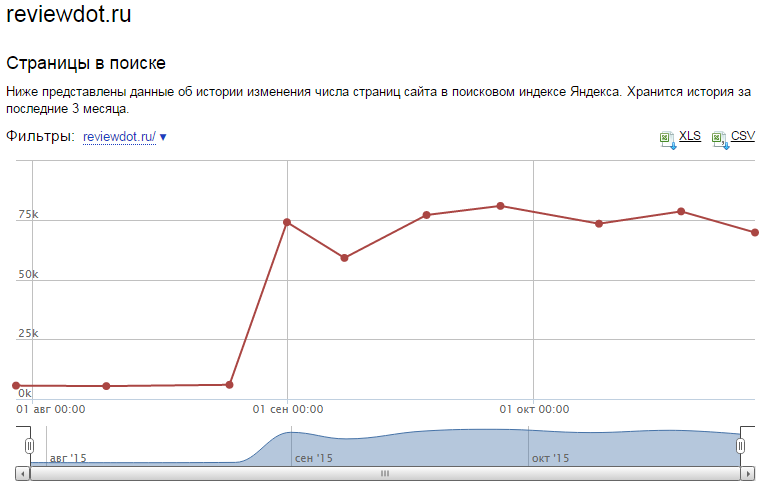
Moreover, the index contains not only pages, but also specifically automatically generated texts, as can be seen by entering fragments of these texts into the search string:
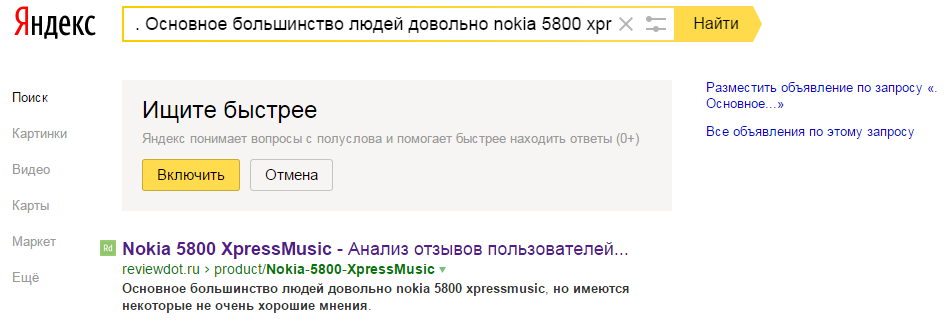
So, at a minimum, machine-generated content can be used to make the page relevant to certain requests.
Of course, it should be noted that we did not post meaningless texts, but texts containing useful information to the user (reviewdot analyzes reviews of products left on different sites and presents the user with a brief annotation about the pros and cons.)
We also made a comparison of the time the user spent on pages with text. As a result, it was found that the texts had a positive effect on such a parameter as the time the user spent on the page. Apparently the reason for this is that if a person sees a coherent text on a page containing the information he needs, he begins to read it, and reading the text takes some time.
Concluding remarks
As of today, the texts have been handed over to the customer and posted on the site ( online plumbing store g-online.ru ), anyone can get acquainted with them too. So far we can conclude that the generated texts can be made quite similar to the "natural", and with the right approach to business, they do not affect the site negatively. Generated texts can improve the indexing of the site pages, and make the pages relevant to specific queries. You can program the generator to mention the specified keywords or phrases in exactly specified percentages of the text size.
Literature
1. E.A. Grechnikov, G.G. Gusev, A.A. Kustarev, A.M. Raygorodsky. Search for unnatural texts // Proceedings of the 11th All-Russian Scientific Conference "Digital Libraries: Advanced Methods and Technologies, Digital Collections" - RCDL'2009, Petrozavodsk, Russia, 2009.
2. Aharoni, Roee, Moshe Koppel, and Yoav Goldberg. Automatic Detection of the Translated Text and Translation Quality Estimation // Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 289–295, Baltimore, Maryland, USA, June 23-25 2014.
3. GS Manku, A. Jain, and A. Das Sarma. Detecting Near-duplicates for Web Crawling. In Proceedings of the 16th WWW Conference, May 2007
4. Zhang, Qing, David Y. Wang, and Geoffrey M. Voelker. "Dspin: Detecting automatically spun content on the web." NDSS, 2014.
Since customers have recently turned to us with the task of creating descriptions for products on the site, we decided to study this issue in more detail. What algorithms exist for determining automatically written texts, what properties should the text have in order not to be recognized as web spam, and what tools can generate it?
In recent years, unique text (and generally text) has become a common tool that SEO experts recommend for promoting websites in search engines. In recent years, site owners realized that it was quite expensive to order text writing to people, because the prices for author texts were at all times in the range of $ 1- $ 3 per 1000 characters. It is clear that the owner of an online store, even with a modest assortment of 3-4 thousand items, must pay for texts from 300,000 rubles, and the waste is not one-time, since the assortment tends to be updated. Naturally, automatically generated product descriptions appeared on the site pages.
As a matter of fact, the search engine recognizes automatically generated content ...
... Of course, we do not know. But, the general principle of the method of secrecy does not constitute, and by turning to primary sources one can draw some reasonable conclusions about the limits of the possible. To begin with, there is an article with the promising title “Search for unnatural texts” [1] on the website of scientific publications of Yandex. It says about the following “in the unnatural text the distribution of pairs [words] should be disturbed ... the number of rare pairs that are uncharacteristic for the language should be overestimated compared to the standard, and the number of frequent pairs should be underestimated”. Thus, we are confronted with the first group of methods. That is, one way or another, this is about comparing the statistical parameters of a given text with the parameters of “natural” texts. In addition to the distribution of pairs, frequencies of n-grams of larger size can be used. In the more recent works [2], the frequencies of n-grams are not applied to the words themselves, but to parts of speech, when each part of speech is first defined (SUSCH-PRIL-SUSCH-GLAG), and then the frequencies of the received n-gram are counted, and so on .
')
It is clear that the most primitive descriptions generated by the substitution of the parameters of goods in the template text avoid this filter due to the fact that the original template is man-made and, accordingly, has natural characteristics. This is of course, provided that the pattern is smoothed by the correspondences of the kinds and cases so that nothing like “Buy a washing machine for 10399 rubles.”
Generators based on modern language models, such as neural network language models, are also very likely to avoid this filter, since the general rule says "to catch text generated by some language model, you must use a more advanced language model." A more advanced language model may be in short supply, and besides, it will require huge computational costs, so using it to define automatic texts on the Internet scale will simply be irrational.
But generators based on a language model, applied directly, generate texts that are devoid of meaning. For example, such “Reliability of water heaters“ ariston ”wins the rating of boilers”.
Since online store owners usually don’t want water heaters to win boiler ratings, they prefer simple template texts. But there is some potential difficulty here.
Template text is not distinguishable from natural as long as it is available in a single copy. Replicated, they become the subject of a second class of methods for defining machine texts. The essence of the method is that all texts written on the basis of the template are similar to each other with the exception of the parts where the parameters of a particular product are inserted. It turns out what is called in English literature "near dublicates" - almost duplicates. Search engines are able to determine them [3], using the well-known method of shingles and its improved versions. If an additional synonymizer is used, the number of unlikely language constructs will increase and the text will become identifiable for the first group of algorithms [1]. In addition, there are algorithms specifically directed against synonymizers - they remove from the text all words for which there are synonyms in the dictionary, and compare texts with the remaining words [4].
Thus, algorithms for recognition of computer-generated texts, being on the one hand rather complicated, still do not contain any magic and superintelligence. If desired, they can be reproduced for the purpose of testing texts, which is time consuming, but in general is not difficult.
Philosophical retreat
We are faced with the fact that there are people who consider computer texts to be evil, littering the Internet and intended to deceive users. But we believe that it can hardly be attributed to meaningful texts describing specific products by parameters. After all, these texts contain actually correct information about the product. Placing on the page such a text, we designate its contents for the search engine, so this is not a hoax of search engines or buyers.
Practice: How good are machine texts?
Taking into account the above, we stopped at a hybrid method of generating texts. In it, first the basic frame of the text is generated using a manually defined grammar (in more detail in the previous article ), and then a neural network analyzer is used above, which is trained to identify places where you can insert or delete certain classes of words without losing meaning. The need to create a generating grammar manually increases the cost of the solution, of course, but it still remains an order of magnitude smaller than ordering texts to a copywriter. Now the actual quality.
Readability :
“ Grohe Allure faucet Allure 19386000 from the new Allure collection, worth only 5800 rubles. Hidden installation provides increased convenience of operation and, of course, installation. The GROHE SilkMove system allows for extremely easy movement of the lever. The special coating produced by StarLight technology creates durability and maintains a good appearance of the product for many years. Vertical installation with two mounting holes is very convenient and should not cause difficulties. The amount of outflow spout here is 220 mm. A larger takeaway size makes it much easier to use the product. The entire product generally has a weight of 1.955 kg. The minimum pressure for this model is 1 bar. Electricity is not necessary. Free delivery and reliable, proven over the years, the quality of the well-known German brand are the main reasons to buy a Grohe Allure 19386000 mixer . ”
Of course, this is not a great literary work, but there are no obvious flaws. It is difficult to determine that the text is automatically generated, even for a person.
Uniqueness:
a) Global uniqueness. The essence of global uniqueness is that the text is unique relative to all other texts available on the Internet at the time of publication.
To test the global uniqueness, we used the well-known text.ru service (for the purposes of objectivity, in this article we present the results of the analysis from third-party services, and not the data of our algorithms).
As you can see, there is no problem with global uniqueness. The service complains about spelling, but when considering errors, they are associated with the use of the words “Allure”, “StarLight” and other specific terms that the service does not know. Note: this is data before placing texts on the customer's site. Now, naturally, these texts can be found there.
b) Local uniqueness. As we have already said, too similar texts can be considered by the search engine as duplicates of each other, which can reveal their artificial origin. To do this, we used the service hosted on the site backlinkmanager (other implementations of comparison using the shingle algorithm give similar results)
Two texts about very similar models with the same parameters are similar by only 5%, and the similarity is largely due to the mention of the product name “Grohe Alira washbasin mixer”. We will consider this a good result, because there are not many ways to describe the same set of product parameters in different ways.
Indexing by search engines
The indexation of computer-generated texts was checked by us earlier on the example of the site reviewdot.ru. Pages on this site do not have unique content. Therefore, at first, this site did not want to get into the Yandex index (out of more than one hundred thousand pages in the index there were about 1,300 pieces). We struggled stubbornly with this by placing template texts first (the number of pages in the index grew to 5000), then using more complex generation algorithms like those discussed above. Today, the Yandex index has about 70,000 pages. Although what specifically influenced the situation - our efforts or changes in the algorithms of Yandex, we do not know. Nevertheless, the fact remains a fact - the pages containing automatically generated texts successfully fall into the index of search engines. Despite all the fears of SEO experts, the
Moreover, the index contains not only pages, but also specifically automatically generated texts, as can be seen by entering fragments of these texts into the search string:
So, at a minimum, machine-generated content can be used to make the page relevant to certain requests.
Of course, it should be noted that we did not post meaningless texts, but texts containing useful information to the user (reviewdot analyzes reviews of products left on different sites and presents the user with a brief annotation about the pros and cons.)
We also made a comparison of the time the user spent on pages with text. As a result, it was found that the texts had a positive effect on such a parameter as the time the user spent on the page. Apparently the reason for this is that if a person sees a coherent text on a page containing the information he needs, he begins to read it, and reading the text takes some time.
Concluding remarks
As of today, the texts have been handed over to the customer and posted on the site ( online plumbing store g-online.ru ), anyone can get acquainted with them too. So far we can conclude that the generated texts can be made quite similar to the "natural", and with the right approach to business, they do not affect the site negatively. Generated texts can improve the indexing of the site pages, and make the pages relevant to specific queries. You can program the generator to mention the specified keywords or phrases in exactly specified percentages of the text size.
Literature
1. E.A. Grechnikov, G.G. Gusev, A.A. Kustarev, A.M. Raygorodsky. Search for unnatural texts // Proceedings of the 11th All-Russian Scientific Conference "Digital Libraries: Advanced Methods and Technologies, Digital Collections" - RCDL'2009, Petrozavodsk, Russia, 2009.
2. Aharoni, Roee, Moshe Koppel, and Yoav Goldberg. Automatic Detection of the Translated Text and Translation Quality Estimation // Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers), pages 289–295, Baltimore, Maryland, USA, June 23-25 2014.
3. GS Manku, A. Jain, and A. Das Sarma. Detecting Near-duplicates for Web Crawling. In Proceedings of the 16th WWW Conference, May 2007
4. Zhang, Qing, David Y. Wang, and Geoffrey M. Voelker. "Dspin: Detecting automatically spun content on the web." NDSS, 2014.
Source: https://habr.com/ru/post/271965/
All Articles