Development of a parser, code generator and SQL editor using EMFText

This is the 6th article of the model-driven development cycle. In the last article, you got a general idea about developing domain-specific languages using EMFText. It is time to move from a toy language to a more serious one. There will be a lot of pictures, code and text. If you are planning to use EMFText or a similar tool, then this article should save you a lot of time. You may learn something new about EMF (delegates to change).
Like a brave hobbit, we will begin our journey with SQL BNF grammar, get to the creepy dragon (metamodel) and go back to grammar, but another one ...
Introduction
Today we will develop a parser, code generator and SQL editor. Kodogenerator will be required in the following article.
')
Generally, SQL is a very complex language. Much more complicated than, for example, Java. To verify this, compare Java and SQL grammars. It's just hard. Therefore, in the article we will implement a small fragment of SQL - expression to create tables (CREATE TABLE), and, moreover, not completely.
1 setting
As usual, you will need Eclipse Modeling Tools . Install the latest version of EMFText from here http://emftext.org/update_trunk .
2 Creating a project
You can either take the finished project or create a new one (File -> New -> Other ... -> EMFText Project).
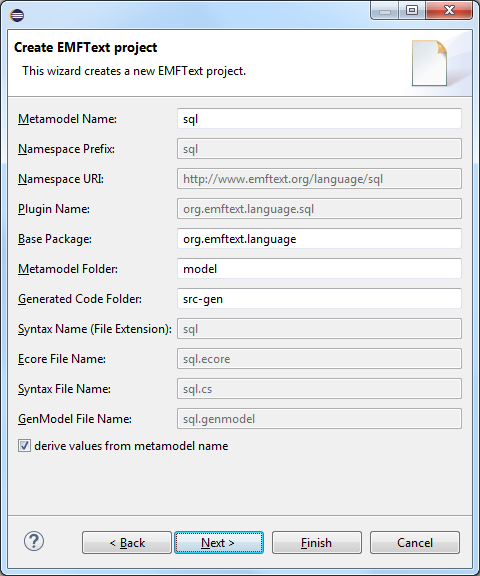
In the new project, in the model folder, blanks have already been created for the metamodel (sql.ecore) and grammar (sql.cs) of the developed language, which you met in the last article . These two files completely describe the language. Almost everything else is generated from them.
Remove all classes and types from the metamodel, we will not need them. You can edit the metamodel either in the tree editor or in the diagram editor. To create a diagram for a metamodel, select File -> New -> Other ... -> Sirius -> Representations File. Select chart initialization from existing model (sql.ecore). Select the “Design” point of view. Switch to the Sirius perspective (Window -> Perspective -> Open Perspective -> Other ...). Open the created aird file. Create a class diagram for the sql package.
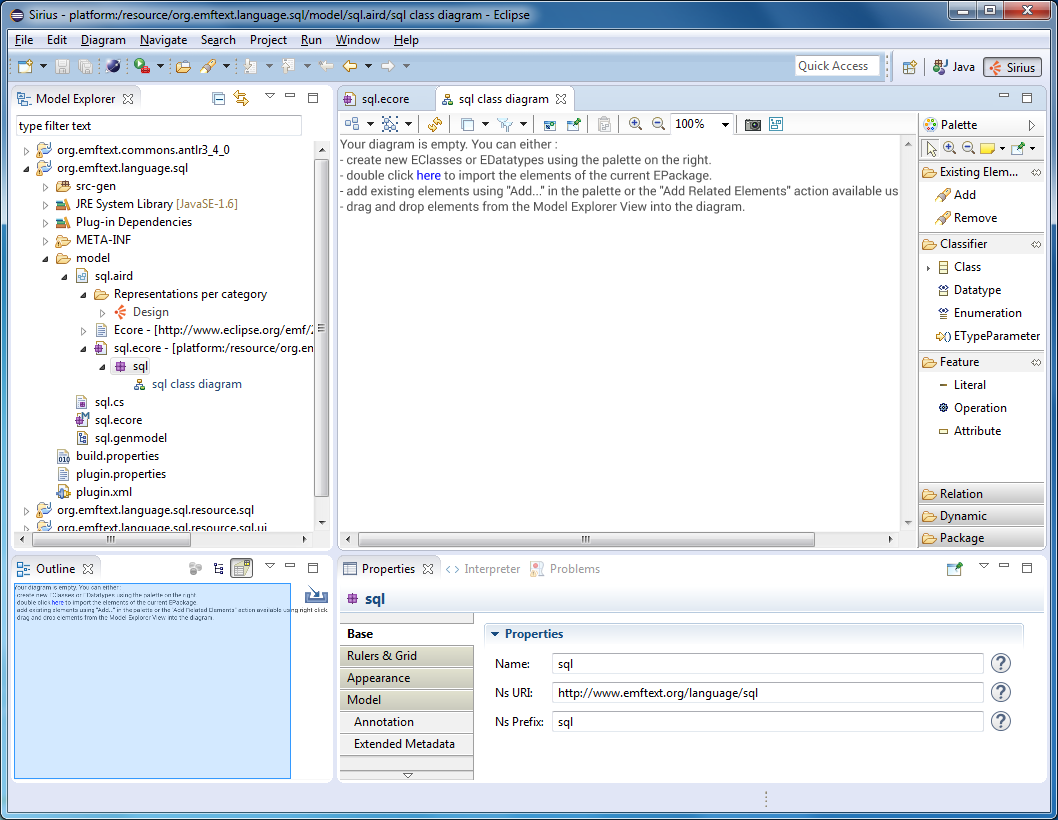
Note
We discussed the tree editor and chart editor in detail in previous articles. If you do not like to create a model with the mouse, but prefer a textual representation, you can try using Xcore . I have never used it in conjunction with EMFText, but in principle, there should be no problems.
You can also open the Ecore model using the OCLinEcore editor. It is a text, like Xcore, only OCL is used instead of Java. By the way, in a metamodel, one computed property and one control rule are written using OCLinEcore, but this is a topic for a separate article.
In a word, you have 4 editors to choose from to work with the metamodel :) Tree, diagram, text-based Java-oriented, text-based OCL-oriented.
3 Approaches to the development of language metamodel
There are two ways to create a metamodel of a domain-specific language: 1) from the domain or 2) from syntax.
In the first case, you are trying to imagine what should describe the language. For example, the language from the previous article describes entities, data types, properties. And the language from this article describes anchors, connections, nodes, attributes. For each type of object, you create a corresponding class in the metamodel. And then describe textual notation for these classes. In other words, this is the path from semantics to syntax.
In the second case, you analyze the grammar of the language, see how the subject area is described in this language. For each non-terminal character, create a class in the metamodel. Metamodel turns out very big, redundant and complex. You drop everything superfluous from it, optimize it and as a result get a more or less adequate metamodel. In other words, this is the path from syntax to semantics.
The first way looks more correct, but it is dangerous in that the metamodel may turn out too detached from the language. For example, what does SQL describe? Personally, I was convinced that this is a language about tables, columns, views, constraints, keys, ... - about objects, which are described at the end of the SQL specification in the sections Information Schema and Definition Schema. It would be logical to create corresponding classes in the language meta-model: table, column, etc. But this is wrong, because in the end we will get the metadata structure of the relational DBMS, and not the structure of the operators of the SQL language.
There are no tables, columns, restrictions as such in SQL. Instead, there are operators to create, delete, modify these objects. Accordingly, in the metamodel instead of the “Table” class, there should be the classes “Table creation operator”, “Table deletion operator”, “Table modification operator”, ...
This SQL is fundamentally different from the simple declarative language from the previous article . It is customary to consider SQL as a declarative language, unlike, for example, Java. But damn, in Java I can write:
public class User { public int id; public String name; } And in SQL I cannot describe the table declaratively, but I can only call the table creation operator:
CREATE TABLE "user" ( id INT CONSTRAINT user_pk PRIMARY KEY, name VARCHAR(50) NOT NULL ); Or several operators:
CREATE TABLE "user" ( id INT CONSTRAINT user_pk PRIMARY KEY ); ALTER TABLE "user" ADD COLUMN name VARCHAR(50) NOT NULL; Because of this, validation of SQL scripts is complicated. We can first create a table, then delete it, then create another table with the same name. Imagine if in Java you could unzip variables, change their data type or add / remove class properties! How generally to validate such code?
Note
Probably, this does not make SQL a language with dynamic typing. I already feel like tomatoes are flying into me for “imperative and dynamically typed” SQL :) But try implementing a parser or editor of SQL scripts and you will come to the conclusion that this is equivalent to the implementation of an imperative and dynamically typed language. To determine the valid table or column names, the parser has to actually interpret the code, but without changing the real database. In this article, this interpretation is implemented as simply as possible (in the classes responsible for resolving the links described below), in reality, everything is more complicated. Some ideas on the mechanism for resolving links can be drawn from JaMoPP .
4 Development of SQL metamodel
So, the first path to the metamodel is good for declarative languages like EntityModel or Anchor . And to come to the SQL metamodel is easier for us the second way. We will analyze a small fragment of the SQL grammar and create the necessary classes for it.
The BNF grammar of a language consists of rules, in the left part of which there is one non-terminal character, and in the right part there are several terminal or non-terminal characters. Without thinking, we could create a class for each non-terminal symbol from the left side, and an attribute or a link to the corresponding class for each non-terminal symbol from the right side. But, believe me, the metamodel will turn out very complicated, it will not be convenient to work with it. Therefore, I have formulated for myself a few recommendations that allow you to immediately build a more or less simplified metamodel.
- If on the right side of the rule there is a “complex” sequence of characters, then for a non-terminal symbol from the left side of the rule we create a class .
- If on the right side of the rule there is a choice of several “complex” sequences of symbols, then for a non-terminal symbol from the left side of the rule we create an abstract class , and for each alternative we create a concrete subclass that we inherit from the abstract one.
- If in the right part of the rule there is a choice of several “simple” sequences of characters, then for a non-terminal character from the left part of the rule we create an enumeration .
- If the right part of the rule is relatively “simple”, but it is impossible to list all possible options, then either use one of the primitive data types Ecore for a non-terminal character from the left part or (if there is no suitable one) create a new data type .
- For each “simple” non-terminal symbol from the right side, which is not a link by name to some object of the domain, we create an attribute in the class from the left side of the rule.
- For each “simple” non-terminal character from the right side, which is not a link by name to some object of the domain, create a non-containment link in the class from the left side of the rule to the class of the named object.
- For each “complex” non-terminal character from the right side, create a containment reference in the class from the left side of the rule to the class corresponding to the given non-terminal character from the right side.
All these recommendations sound like some kind of kindergarten :) What do “simple” and “complex” mean? There are also some exceptions to these rules. For example, if characters are reused in different rules.
I began to describe all this formally, with clear definitions. But on the second page I realized that this is a topic for a separate scientific work that simply does not fit in this already gigantic article. Therefore, I propose to do so by such intuitive recommendations.
4.1 Rule analysis for <table definition>
So, the first rule that interests us, describes the expression definitions of tables.
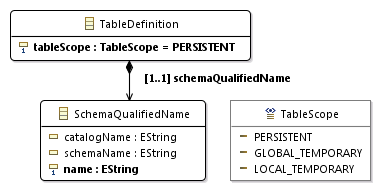
<table definition> ::= CREATE [ <table scope> ] TABLE <table name> <table contents source> [ ON COMMIT <table commit action> ROWS ] It looks quite “complex”: in the right part there is the scope of the table being created, the name of the table, the source of the content and the action at the commit. The rule falls under recommendation 1, which means we create the class TableDefinition.

Now we will analyze non-terminal symbols from the right side. For each of them, in accordance with recommendations 5-7, we must create an attribute or reference in the TableDefinition class.
4.2 Rule analysis for <table scope>
<table scope> ::= <global or local> TEMPORARY <global or local> ::= GLOBAL | LOCAL It can be seen that the right parts of the rules are quite “simple”. For greater simplicity, they can be combined into one rule and, in accordance with recommendation 3, create a TableScope enumeration with three values in the metamodel:
- PERSISTENT
- GLOBAL_TEMPORARY
- LOCAL_TEMPORARY
The first enumeration option is not explicitly stated in the grammar. But from the rule for <table definition> it can be seen that the table scope is optional, and by default, permanent tables are created.
Note
You may get the impression that all my arguments are completely non-trivial - it all looks crazy and complicated. But everything is simpler than it seems, just try it yourself to implement some language.
The nonterminal symbol <table scope> is used in the rule for <table definition>. Therefore, in accordance with recommendation 5, in the class TableDefinition, we create the attribute tableScope with the type TableScope.

4.3 Rule analysis for <table name>
Now we try to analyze the rule for the name of the table and suddenly we come across a hefty chain of rules, some of which are not even described in the grammar, but described in words in the SQL specification!
<table name> ::= <local or schema qualified name> <local or schema qualified name> ::= [ <local or schema qualifier> <period> ] <qualified identifier> <local or schema qualifier> ::= <schema name> | MODULE <qualified identifier> ::= <identifier> <schema name> ::= [ <catalog name> <period> ] <unqualified schema name> <unqualified schema name> ::= <identifier> <catalog name> ::= <identifier> <identifier> ::= <actual identifier> <actual identifier> ::= <regular identifier> | <delimited identifier> <regular identifier> ::= <identifier body> <identifier body> ::= <identifier start> [ <identifier part> ... ] <identifier part> ::= <identifier start> | <identifier extend> <identifier start> ::= !! See the Syntax Rules. <identifier extend> ::= !! See the Syntax Rules. <delimited identifier> ::= <double quote> <delimited identifier body> <double quote> <delimited identifier body> ::= <delimited identifier part> ... <delimited identifier part> ::= <nondoublequote character> | <doublequote symbol> <nondoublequote character> ::= !! See the Syntax Rules. <doublequote symbol> ::= <double quote> <double quote> <double quote> ::= " Most of the rules describe the format of identifiers and names and should be implemented at the data type level, and not in the metamodel. The only question is where exactly to draw the line between the details of the implementation of data types and the math model. There are such options for the representation of table names:
- Use the existing EString data type in the metamodel, which in Java corresponds to java.lang.String.
- Create a new data type with three attributes (directory name, schema name and object name) that will not be visible at the metamodel level.
- Use existing java.lang.String data type for attributes
- Use for attributes a new data type "Identifier"
- Create a class with the same three attributes that are already described at the metamodel level.
- Use existing EString data type for attributes
- Use for attributes a new data type "Identifier"
After several sleepless nights and smoking JaMoPP sources , I came to the conclusion that version 3.1 is best. In options 1 and 2, you will have to create two overlapping types of tokens: an identifier and a qualified name. It is easier to define one type of token for identifiers. Anything more complex than identifiers (including qualified names) is implemented at the metamodel level, and everything that is simpler at the data type level.
4.4 Rule Analysis for <table contents source>
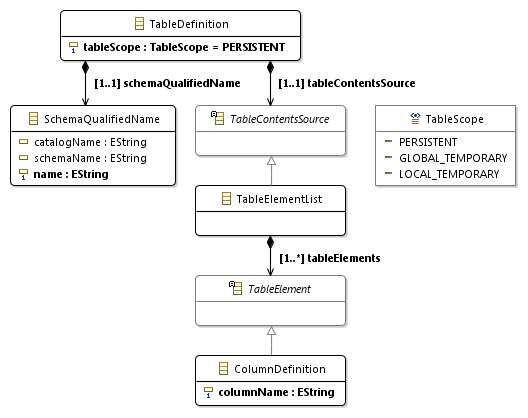
<table contents source> ::= <table element list> | OF <path-resolved user-defined type name> [ <subtable clause> ] [ <table element list> ] | <as subquery clause> <table element list> ::= <left paren> <table element> [ { <comma> <table element> }... ] <right paren> <left paren> ::= ( <right paren> ::= ) <comma> ::= , The rule for the source of the table content falls under recommendation 2, therefore we create the abstract class TableContentsSource, from which we derive the concrete class TableElementList. And we will not implement the other two options yet.
In accordance with recommendation 7, we create a link from the TableDefinition class to the TableContentsSource class. For the link, you must set the containment property to true.

For parentheses and commas, classes are obviously not needed, they are implemented at the lexer level.
4.5 Rule Analysis for <table element>
<table element> ::= <column definition> | <table constraint definition> | <like clause> | <self-referencing column specification> | <column options> In accordance with recommendation 2, we create the abstract class TableElement and the class ColumnDefinition inherited from it. We will not implement other options yet.
In accordance with recommendation 7, we create a link from the TableElementList class to the TableElement class. For the link, you must set the containment property to true.

4.6 Rule Analysis for <column definition>
<column definition> ::= <column name> [ <data type> | <domain name> ] [ <reference scope check> ] [ <default clause> | <identity column specification> | <generation clause> ] [ <column constraint definition> ... ] [ <collate clause> ] <column name> ::= <identifier> In accordance with Recommendation 5, we create the columnName attribute with the EString data type in the ColumnDefinition class. The remaining column properties will not be implemented yet.
5 More complete SQL metamodel
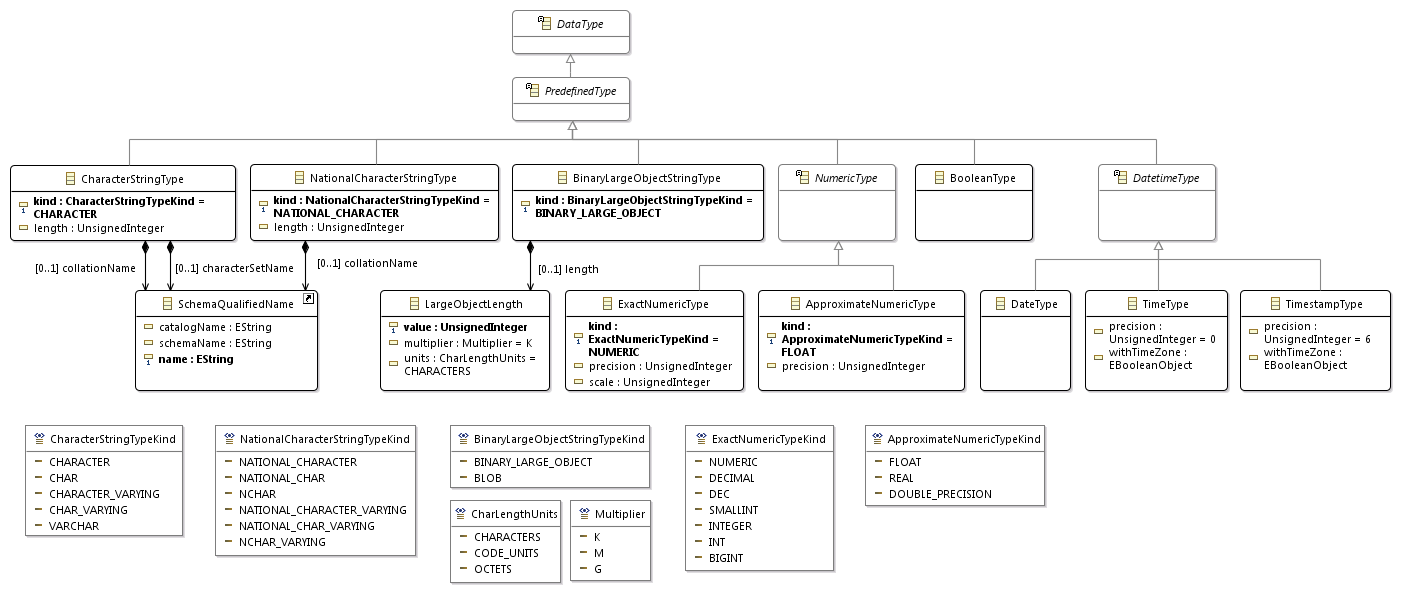
If you finish a few more rules from the SQL grammar, then get this metamodel .
The root object of the model is SQLScript, which can contain several expressions (Statement) of two types: meaningful expressions and separators. Separators can also be of two types: whitespace and comments. We do not need the first in the meta model. Comments can also be of two types: single-line and multi-line.
In general, comments are often not included in the metamodel of the language, because they have no effect on the semantics of the code. But then we will do not only the parser, but also the code generator. I wish the latter could generate comments.

Notice the data types on the right. UnsignedInteger maps to a Java class, which we will implement later. And the types for representing the date and time are mapped onto existing Java classes.
The following figure shows the main part of the metamodel. Notice that the restrictions (bottom right) indicate not just the names of the columns and tables involved in the restriction, but references to them. The parser will form a graph from the source code, not a tree.

When defining columns, you need to specify their data type:
You may need to specify a default value for the column, this requires literals:

Also, the default value can be the current date or time:

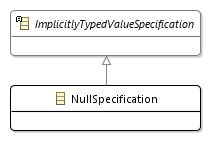
Or NULL:
6 SQL syntax description
So, we finally reached Erebor, saw the terrible dragon Smaug (metamodel). It is time to come back.

Now we will again describe the SQL syntax, but no longer in BNF, but in a BNF-like language in the sql.cs file.
Specify a) file extension, b) metamodel namespace, and c) root object class of the syntax tree (the initial grammar symbol):
SYNTAXDEF sql FOR <http://www.emftext.org/language/sql> START Common.SQLScript Few settings are described in the EMFText manual :
OPTIONS { reloadGeneratorModel = "true"; usePredefinedTokens = "false"; caseInsensitiveKeywords = "true"; disableBuilder = "true"; disableDebugSupport = "true"; disableLaunchSupport = "true"; disableTokenSorting = "true"; overrideProposalPostProcessor = "false"; overrideManifest = "false"; overrideUIManifest = "false"; } The last two options disable the regeneration of the MANIFEST.MF files in the org.emftext.language.sql.resource.sql and org.emftext.language.sql.resource.sql.ui plugins, respectively. In these files, you need to install the minimum required version of Java in JavaSE-1.8, because we will use the stream API. And the version of the plugin will be changed from “1.0.0” to “1.0.0.qualifier” otherwise there will be inexplicable problems.
Note that the regular expressions for the UNSIGNED_INTEGER and EXACT_NUMERIC_LITERAL tokens overlap. Because of this, we will have to further complicate the grammar.
TOKENS { // Default DEFINE WHITESPACE $('\u0009'|'\u000A'|'\u000B'|'\u000C'|'\u000D'|'\u0020'|'\u00A0'|'\u2000'|'\u2001'$ + $|'\u2002'|'\u2003'|'\u2004'|'\u2005'|'\u2006'|'\u2007'|'\u2008'|'\u2009'|'\u200A'$ + $|'\u200B'|'\u200C'|'\u200D'|'\u200E'|'\u200F'|'\u2028'|'\u2029'|'\u3000'|'\uFEFF')$; // Single characters DEFINE FRAGMENT SIMPLE_LATIN_LETTER $($ + SIMPLE_LATIN_UPPER_CASE_LETTER + $|$ + SIMPLE_LATIN_LOWER_CASE_LETTER + $)$; DEFINE FRAGMENT SIMPLE_LATIN_UPPER_CASE_LETTER $'A'..'Z'$; DEFINE FRAGMENT SIMPLE_LATIN_LOWER_CASE_LETTER $'a'..'z'$; DEFINE FRAGMENT DIGIT $('0'..'9')$; DEFINE FRAGMENT PLUS_SIGN $'+'$; DEFINE FRAGMENT MINUS_SIGN $'-'$; DEFINE FRAGMENT SIGN $($ + PLUS_SIGN + $|$ + MINUS_SIGN + $)$; DEFINE FRAGMENT COLON $':'$; DEFINE FRAGMENT PERIOD $'.'$; DEFINE FRAGMENT SPACE $' '$; DEFINE FRAGMENT UNDERSCORE $'_'$; DEFINE FRAGMENT SLASH $'/'$; DEFINE FRAGMENT ASTERISK $'*'$; DEFINE FRAGMENT QUOTE $'\''$; DEFINE FRAGMENT QUOTE_SYMBOL $($ + QUOTE + QUOTE + $)$; DEFINE FRAGMENT NONQUOTE_CHARACTER $~($ + QUOTE + $|$ + NEWLINE + $)$; DEFINE FRAGMENT DOUBLE_QUOTE $'"'$; DEFINE FRAGMENT DOUBLEQUOTE_SYMBOL $($ + DOUBLE_QUOTE + DOUBLE_QUOTE + $)$; DEFINE FRAGMENT NONDOUBLEQUOTE_CHARACTER $~($ + DOUBLE_QUOTE + $|$ + NEWLINE + $)$; DEFINE FRAGMENT NEWLINE $('\r\n'|'\r'|'\n')$; // Comments DEFINE SIMPLE_COMMENT SIMPLE_COMMENT_INTRODUCER + $($ + COMMENT_CHARACTER + $)*$; DEFINE FRAGMENT SIMPLE_COMMENT_INTRODUCER MINUS_SIGN + MINUS_SIGN; DEFINE FRAGMENT COMMENT_CHARACTER $~('\n'|'\r'|'\uffff')$; DEFINE BRACKETED_COMMENT BRACKETED_COMMENT_INTRODUCER + BRACKETED_COMMENT_CONTENTS + BRACKETED_COMMENT_TERMINATOR; DEFINE FRAGMENT BRACKETED_COMMENT_INTRODUCER SLASH + ASTERISK; DEFINE FRAGMENT BRACKETED_COMMENT_TERMINATOR ASTERISK + SLASH; DEFINE FRAGMENT BRACKETED_COMMENT_CONTENTS $.*$; // TODO: Nested comments // Literals DEFINE UNSIGNED_INTEGER $($ + DIGIT + $)+$; DEFINE EXACT_NUMERIC_LITERAL $($ + UNSIGNED_INTEGER + $($ + PERIOD + $($ + UNSIGNED_INTEGER + $)?)?|$ + PERIOD + UNSIGNED_INTEGER + $)$; DEFINE APPROXIMATE_NUMERIC_LITERAL MANTISSA + $'E'$ + EXPONENT; DEFINE FRAGMENT MANTISSA EXACT_NUMERIC_LITERAL; DEFINE FRAGMENT EXPONENT SIGNED_INTEGER; DEFINE FRAGMENT SIGNED_INTEGER SIGN + $?$ + UNSIGNED_INTEGER; DEFINE QUOTED_STRING QUOTE + CHARACTER_REPRESENTATION + $*$ + QUOTE; DEFINE FRAGMENT CHARACTER_REPRESENTATION $($ + NONQUOTE_CHARACTER + $|$ + QUOTE_SYMBOL + $)$; // Names and identifiers DEFINE IDENTIFIER ACTUAL_IDENTIFIER; DEFINE FRAGMENT ACTUAL_IDENTIFIER $($ + REGULAR_IDENTIFIER + $|$ + DELIMITED_IDENTIFIER + $)$; DEFINE FRAGMENT REGULAR_IDENTIFIER IDENTIFIER_BODY; DEFINE FRAGMENT IDENTIFIER_BODY IDENTIFIER_START + IDENTIFIER_PART + $*$; DEFINE FRAGMENT IDENTIFIER_PART $($ + IDENTIFIER_START + $|$ + IDENTIFIER_EXTEND + $)$; DEFINE FRAGMENT IDENTIFIER_START $('A'..'Z'|'a'..'z')$; // TODO: \p{L} - \p{M} DEFINE FRAGMENT IDENTIFIER_EXTEND $($ + DIGIT + $|$ + UNDERSCORE + $)$; // TODO: Support more characters DEFINE FRAGMENT DELIMITED_IDENTIFIER DOUBLE_QUOTE + DELIMITED_IDENTIFIER_BODY + DOUBLE_QUOTE; DEFINE FRAGMENT DELIMITED_IDENTIFIER_BODY DELIMITED_IDENTIFIER_PART + $+$; DEFINE FRAGMENT DELIMITED_IDENTIFIER_PART $($ + NONDOUBLEQUOTE_CHARACTER + $|$ + DOUBLEQUOTE_SYMBOL + $)$; } Let's color tokens:
TOKENSTYLES { "SIMPLE_COMMENT", "BRACKETED_COMMENT" COLOR #999999, ITALIC; "QUOTED_STRING" COLOR #000099, ITALIC; "EXACT_NUMERIC_LITERAL", "APPROXIMATE_NUMERIC_LITERAL", "UNSIGNED_INTEGER" COLOR #009900; } And, finally, in the section RULES {} we will describe the syntax for the classes from the metamodel.
6.1 Syntax description for the script as a whole, comments and names
If you read the previous article , then the meaning of these rules should be obvious to you:
Common.SQLScript ::= (statements !0)*; Common.SimpleComment ::= value[SIMPLE_COMMENT]; Common.BracketedComment ::= value[BRACKETED_COMMENT]; Common.SchemaQualifiedName ::= ((catalogName[IDENTIFIER] ".")? schemaName[IDENTIFIER] ".")? name[IDENTIFIER]; 6.2 Syntax Description for Literals
@SuppressWarnings(explicitSyntaxChoice) Literal.ExactNumericLiteral ::= value[EXACT_NUMERIC_LITERAL] | value[UNSIGNED_INTEGER]; Literal.ApproximateNumericLiteral ::= value[APPROXIMATE_NUMERIC_LITERAL]; Literal.CharacterStringLiteral ::= ("_" characterSetName)? values[QUOTED_STRING] (separators values[QUOTED_STRING])*; Literal.NationalCharacterStringLiteral ::= "N" values[QUOTED_STRING] (separators values[QUOTED_STRING])*; Literal.DateLiteral ::= "DATE" value[QUOTED_STRING]; Literal.TimeLiteral ::= "TIME" value[QUOTED_STRING]; Literal.TimestampLiteral ::= "TIMESTAMP" value[QUOTED_STRING]; Literal.BooleanLiteral ::= value[ "TRUE" : "FALSE" ]?; It is necessary to elaborate on the first rule. The regular expressions for the EXACT_NUMERIC_LITERAL and UNSIGNED_INTEGER tokens intersect. For example, if you write a number in the SQL script in decimal notation without the “.” Character, it will be interpreted by the lexer as UNSIGNED_INTEGER. Then the parser, seeing in the sequence of tokens UNSIGNED_INTEGER instead of EXACT_NUMERIC_LITERAL, will generate an error that another token was expected at this place. Therefore, when crossing tokens it is necessary to complicate the grammar in a similar way.
And here, APPROXIMATE_NUMERIC_LITERAL cannot be confused with other tokens, because it always contains the symbol "E".
If you carefully looked at the BNF grammar of SQL , you probably noticed that it describes the date and time format in sufficient detail, and we limited ourselves to simple QUOTED_STRING. This is due to the fact that if we described the tokens for the date and time, they would intersect with the QUOTED_STRING token and we would have to complicate the grammar very much (wherever the QUOTED_STRING token is also specified to be valid). Or it would be necessary to describe the component parts of literals (up to individual characters) in a metamodel, which would make it incredibly complicated.
It is easier to implement parsing of the date and time in the code, and not at the lexer level. Next, I will describe how to do this.
6.3
. , SQL . , «DATE» , . , , , , , , , EMFText , «DATE».
«» «DOUBLE» «PRECISION». "_" ?.. , «» , , , .. EMFText, , . , . , , .
«» 6.5. , , , SQL- «GLOBAL» «TEMPORARY» «LOCAL» «TEMPORARY».
Datatype.ExactNumericType ::= kind[ NUMERIC : "NUMERIC", DECIMAL : "DECIMAL", DEC : "DEC", SMALLINT : "SMALLINT", INTEGER : "INTEGER", INT : "INT", BIGINT : "BIGINT" ] ("(" precision[UNSIGNED_INTEGER] ("," scale[UNSIGNED_INTEGER])? ")")?; Datatype.ApproximateNumericType ::= kind[ FLOAT : "FLOAT", REAL : "REAL", DOUBLE_PRECISION : "DOUBLE PRECISION" ] ("(" precision[UNSIGNED_INTEGER] ")")?; Datatype.CharacterStringType ::= kind[ CHARACTER : "CHARACTER", CHAR : "CHAR", VARCHAR : "VARCHAR", CHARACTER_VARYING : "CHARACTER VARYING", CHAR_VARYING : "CHAR VARYING" ] ("(" length[UNSIGNED_INTEGER] ")")? ("CHARACTER" "SET" characterSetName)? ("COLLATE" collationName)?; Datatype.NationalCharacterStringType ::= kind[ NATIONAL_CHARACTER : "NATIONAL CHARACTER", NATIONAL_CHAR : "NATIONAL CHAR", NATIONAL_CHARACTER_VARYING : "NATIONAL CHARACTER VARYING", NATIONAL_CHAR_VARYING : "NATIONAL CHAR VARYING", NCHAR : "NCHAR", NCHAR_VARYING : "NCHAR VARYING" ] ("(" length[UNSIGNED_INTEGER] ")")? ("COLLATE" collationName)?; Datatype.BinaryLargeObjectStringType ::= kind[ BINARY_LARGE_OBJECT : "BINARY LARGE OBJECT", BLOB : "BLOB" ] ("(" length ")")?; Datatype.LargeObjectLength ::= value[UNSIGNED_INTEGER] multiplier[ K : "K", M : "M", G : "G" ]? units[ CHARACTERS : "CHARACTERS", CODE_UNITS : "CODE_UNITS", OCTETS : "OCTETS" ]?; Datatype.DateType ::= "DATE"; Datatype.TimeType ::= "TIME" ("(" precision[UNSIGNED_INTEGER] ")")? (withTimeZone["WITH" : "WITHOUT"] "TIME" "ZONE")?; Datatype.TimestampType ::= "TIMESTAMP" ("(" precision[UNSIGNED_INTEGER] ")")? (withTimeZone["WITH" : "WITHOUT"] "TIME" "ZONE")?; Datatype.BooleanType ::= "BOOLEAN"; 6.4
:
Function.DatetimeValueFunction ::= kind[ CURRENT_DATE : "CURRENT_DATE", CURRENT_TIME : "CURRENT_TIME", LOCALTIME : "LOCALTIME", CURRENT_TIMESTAMP : "CURRENT_TIMESTAMP", LOCALTIMESTAMP : "LOCALTIMESTAMP" ] ("(" precision[UNSIGNED_INTEGER] ")")?; Expression.NullSpecification ::= "NULL"; 6.5
, . , . , , , .
Schema.TableReference ::= ((catalogName[IDENTIFIER] ".")? schemaName[IDENTIFIER] ".")? target[IDENTIFIER]; @SuppressWarnings(explicitSyntaxChoice) Schema.TableDefinition ::= "CREATE" ( scope[ PERSISTENT : "" ] | scope[ GLOBAL_TEMPORARY : "GLOBAL", LOCAL_TEMPORARY : "LOCAL" ] "TEMPORARY" ) "TABLE" schemaQualifiedName !0 contentsSource ";" !0; Schema.TableElementList ::= "(" !1 elements ("," !1 elements)* !0 ")"; Schema.Column ::= name[IDENTIFIER] dataType ("DEFAULT" defaultOption)? constraintDefinition? ("COLLATE" collationName)?; Schema.LiteralDefaultOption ::= literal; Schema.DatetimeValueFunctionDefaultOption ::= function; Schema.ImplicitlyTypedValueSpecificationDefaultOption ::= specification; Schema.NotNullColumnConstraint ::= ("CONSTRAINT" schemaQualifiedName)? "NOT" "NULL"; Schema.UniqueColumnConstraint ::= ("CONSTRAINT" schemaQualifiedName)? kind[ UNIQUE : "UNIQUE" , PRIMARY_KEY : "PRIMARY KEY" ]; Schema.ReferentialColumnConstraint ::= ("CONSTRAINT" schemaQualifiedName)? "REFERENCES" referencedTable ("(" referencedColumns[IDENTIFIER] ("," referencedColumns[IDENTIFIER])* ")")?; Schema.UniqueTableConstraint ::= ("CONSTRAINT" schemaQualifiedName)? kind[ UNIQUE : "UNIQUE" , PRIMARY_KEY : "PRIMARY KEY" ] "(" columns[IDENTIFIER] ("," columns[IDENTIFIER])* ")"; Schema.ReferentialTableConstraint ::= ("CONSTRAINT" schemaQualifiedName)? "FOREIGN" "KEY" "(" columns[IDENTIFIER] ("," columns[IDENTIFIER])* ")" "REFERENCES" referencedTable ("(" referencedColumns[IDENTIFIER] ("," referencedColumns[IDENTIFIER])* ")")?; 7
. (, , ), , (, ).
EMFText . SQL , .
7.1
– .
"-". – :
package org.emftext.language.sql.resource.sql.analysis; import java.util.Map; import org.eclipse.emf.ecore.EObject; import org.eclipse.emf.ecore.EStructuralFeature; import org.emftext.language.sql.resource.sql.ISqlTokenResolveResult; import org.emftext.language.sql.resource.sql.ISqlTokenResolver; public class SqlSIMPLE_COMMENTTokenResolver implements ISqlTokenResolver { public String deResolve(Object value, EStructuralFeature feature, EObject container) { return "--" + ((String) value); } public void resolve(String lexem, EStructuralFeature feature, ISqlTokenResolveResult result) { result.setResolvedToken(lexem.substring(2)); } public void setOptions(Map<?, ?> options) { } } 7.2
. , . .
package org.emftext.language.sql.resource.sql.analysis; import java.util.Map; import org.eclipse.emf.ecore.EObject; import org.eclipse.emf.ecore.EStructuralFeature; import org.emftext.language.sql.resource.sql.ISqlTokenResolveResult; import org.emftext.language.sql.resource.sql.ISqlTokenResolver; public class SqlIDENTIFIERTokenResolver implements ISqlTokenResolver { public String deResolve(Object value, EStructuralFeature feature, EObject container) { return Helper.formatIdentifier((String) value); } public void resolve(String lexem, EStructuralFeature feature, ISqlTokenResolveResult result) { try { result.setResolvedToken(Helper.parseIdentifier(lexem)); } catch (Exception e) { result.setErrorMessage(e.getMessage()); } } public void setOptions(Map<?, ?> options) { } } SQL, ( ):
public class Helper
package org.emftext.language.sql.resource.sql.analysis; import java.util.Arrays; import java.util.HashSet; import java.util.Set; public class Helper { private static final String DOUBLE_QUOTE = "\""; private static final String DOUBLE_QUOTE_SYMBOL = "\"\""; private static final Set<String> RESERVED_WORDS = new HashSet<String>(Arrays.asList(new String[] { "ADD", "ALL", "ALLOCATE", "ALTER", "AND", "ANY", "ARE", "ARRAY", "AS", "ASENSITIVE", "ASYMMETRIC", "AT", "ATOMIC", "AUTHORIZATION", "BEGIN", "BETWEEN", "BIGINT", "BINARY", "BLOB", "BOOLEAN", "BOTH", "BY", "CALL", "CALLED", "CASCADED", "CASE", "CAST", "CHAR", "CHARACTER", "CHECK", "CLOB", "CLOSE", "COLLATE", "COLUMN", "COMMIT", "CONNECT", "CONSTRAINT", "CONTINUE", "CORRESPONDING", "CREATE", "CROSS", "CUBE", "CURRENT", "CURRENT_DATE", "CURRENT_DEFAULT_TRANSFORM_GROUP", "CURRENT_PATH", "CURRENT_ROLE", "CURRENT_TIME", "CURRENT_TIMESTAMP", "CURRENT_TRANSFORM_GROUP_FOR_TYPE", "CURRENT_USER", "CURSOR", "CYCLE", "DATE", "DAY", "DEALLOCATE", "DEC", "DECIMAL", "DECLARE", "DEFAULT", "DELETE", "DEREF", "DESCRIBE", "DETERMINISTIC", "DISCONNECT", "DISTINCT", "DOUBLE", "DROP", "DYNAMIC", "EACH", "ELEMENT", "ELSE", "END", "END-EXEC", "ESCAPE", "EXCEPT", "EXEC", "EXECUTE", "EXISTS", "EXTERNAL", "FALSE", "FETCH", "FILTER", "FLOAT", "FOR", "FOREIGN", "FREE", "FROM", "FULL", "FUNCTION", "GET", "GLOBAL", "GRANT", "GROUP", "GROUPING", "HAVING", "HOLD", "HOUR", "IDENTITY", "IMMEDIATE", "IN", "INDICATOR", "INNER", "INOUT", "INPUT", "INSENSITIVE", "INSERT", "INT", "INTEGER", "INTERSECT", "INTERVAL", "INTO", "IS", "ISOLATION", "JOIN", "LANGUAGE", "LARGE", "LATERAL", "LEADING", "LEFT", "LIKE", "LOCAL", "LOCALTIME", "LOCALTIMESTAMP", "MATCH", "MEMBER", "MERGE", "METHOD", "MINUTE", "MODIFIES", "MODULE", "MONTH", "MULTISET", "NATIONAL", "NATURAL", "NCHAR", "NCLOB", "NEW", "NO", "NONE", "NOT", "NULL", "NUMERIC", "OF", "OLD", "ON", "ONLY", "OPEN", "OR", "ORDER", "OUT", "OUTER", "OUTPUT", "OVER", "OVERLAPS", "PARAMETER", "PARTITION", "PRECISION", "PREPARE", "PRIMARY", "PROCEDURE", "RANGE", "READS", "REAL", "RECURSIVE", "REF", "REFERENCES", "REFERENCING", "REGR_AVGX", "REGR_AVGY", "REGR_COUNT", "REGR_INTERCEPT", "REGR_R2", "REGR_SLOPE", "REGR_SXX", "REGR_SXY", "REGR_SYY", "RELEASE", "RESULT", "RETURN", "RETURNS", "REVOKE", "RIGHT", "ROLLBACK", "ROLLUP", "ROW", "ROWS", "SAVEPOINT", "SCROLL", "SEARCH", "SECOND", "SELECT", "SENSITIVE", "SESSION_USER", "SET", "SIMILAR", "SMALLINT", "SOME", "SPECIFIC", "SPECIFICTYPE", "SQL", "SQLEXCEPTION", "SQLSTATE", "SQLWARNING", "START", "STATIC", "SUBMULTISET", "SYMMETRIC", "SYSTEM", "SYSTEM_USER", "TABLE", "THEN", "TIME", "TIMESTAMP", "TIMEZONE_HOUR", "TIMEZONE_MINUTE", "TO", "TRAILING", "TRANSLATION", "TREAT", "TRIGGER", "TRUE", "UESCAPE", "UNION", "UNIQUE", "UNKNOWN", "UNNEST", "UPDATE", "UPPER", "USER", "USING", "VALUE", "VALUES", "VAR_POP", "VAR_SAMP", "VARCHAR", "VARYING", "WHEN", "WHENEVER", "WHERE", "WIDTH_BUCKET", "WINDOW", "WITH", "WITHIN", "WITHOUT", "YEAR" })); private static boolean isReservedWord(String str) { return RESERVED_WORDS.contains(str.toUpperCase()); } public static boolean isEmpty(String str) { return str == null || str.length() == 0; } public static String formatIdentifier(String str) { if (!str.matches("[AZ][A-Z0-9_]*") || isReservedWord(str)) { return DOUBLE_QUOTE + str.replace(DOUBLE_QUOTE, DOUBLE_QUOTE_SYMBOL) + DOUBLE_QUOTE; } else { return str; } } public static String parseIdentifier(String str) { if (str.startsWith(DOUBLE_QUOTE) && str.endsWith(DOUBLE_QUOTE) && str.length() >= 2) { return str.substring(1, str.length() - 1) .replace(DOUBLE_QUOTE_SYMBOL, DOUBLE_QUOTE); } else if (isReservedWord(str)) { throw new IllegalArgumentException( String.format("Reserved word %s must be quoted when used as identifier", str.toUpperCase())); } else { return str.toUpperCase(); } } } 7.3
(UNSIGNED_INTEGER) EInt, Java- int. , :
package org.emftext.language.sql; public class UnsignedInteger { private int value; private UnsignedInteger(int value) { this.value = value; } public static UnsignedInteger valueOf(String str) { return new UnsignedInteger(Integer.parseUnsignedInt(str)); } @Override public String toString() { return String.format("%d", value); } } , , valueOf toString. , EMFText, EMF . , () XMI- SQL- .
, . , ? , () , , , XMI.
. () - , . / SQL- .
7.4
, – . , Ecore – EDate, java.util.Date. SQL , . SQL , EDate .
Java : java.time.LocalDate, java.time.LocalTime java.time.ZonedDateTime. 2-, , , .
, valueOf, toString . , () XMI- . EMF – (conversion delegates).
plugin.xml «» (Extensions) org.eclipse.emf.ecore.conversion_delegate. :
- URI – org.emftext.language.sql.conversionDelegateFactory
- Class – org.emftext.language.sql.ConversionDelegateFactory

Note
Eclipse, . plugin.xml , :EDataType.Internal.ConversionDelegate.Factory.Registry.INSTANCE.put( "org.emftext.language.sql.conversionDelegateFactory", new ConversionDelegateFactory());
( common) (EAnnotation) (Source) http://www.eclipse.org/emf/2002/Ecore . conversionDelegates org.emftext.language.sql.conversionDelegateFactory.
Note
OCLinEcore , - . . , .
, (), (EAnnotation) (Source) org.emftext.language.sql.conversionDelegateFactory:
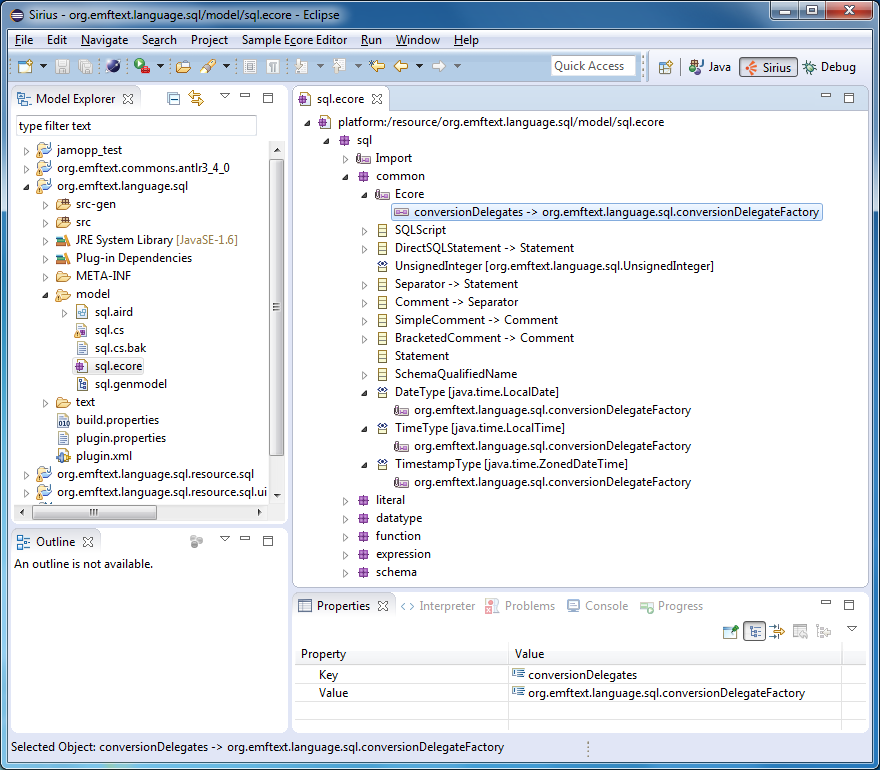
:
package org.emftext.language.sql; import org.eclipse.emf.ecore.EDataType; import org.eclipse.emf.ecore.EDataType.Internal.ConversionDelegate; import org.eclipse.emf.ecore.EDataType.Internal.ConversionDelegate.Factory; import org.emftext.language.sql.common.CommonPackage; public class ConversionDelegateFactory implements Factory { public ConversionDelegateFactory() { } @Override public ConversionDelegate createConversionDelegate(EDataType eDataType) { if (eDataType.equals(CommonPackage.eINSTANCE.getDateType())) { return new DateConversionDelegate(); } else if (eDataType.equals(CommonPackage.eINSTANCE.getTimeType())) { return new TimeConversionDelegate(); } else if (eDataType.equals(CommonPackage.eINSTANCE.getTimestampType())) { return new TimestampConversionDelegate(); } return null; } } :
package org.emftext.language.sql; import java.time.ZonedDateTime; import java.time.format.DateTimeFormatter; import java.time.format.DateTimeFormatterBuilder; import org.eclipse.emf.ecore.EDataType.Internal.ConversionDelegate; public class TimestampConversionDelegate implements ConversionDelegate { private static final DateTimeFormatter FORMATTER = new DateTimeFormatterBuilder() .append(DateTimeFormatter.ISO_LOCAL_DATE) .appendLiteral(" ") .append(DateTimeFormatter.ISO_TIME) .toFormatter(); @Override public String convertToString(Object value) { ZonedDateTime timestamp = (ZonedDateTime) value; return timestamp.format(FORMATTER); } @Override public Object createFromString(String literal) { return ZonedDateTime.parse(literal, FORMATTER); } } , :
- TimestampType
- , Java java.time.ZonedDateTime
- ()
Note
EMF : invocationDelegates, settingDelegates, validationDelegates.
QUOTED_STRING, , :
package org.emftext.language.sql.resource.sql.analysis; import java.util.Map; import org.eclipse.emf.ecore.EDataType; import org.eclipse.emf.ecore.EObject; import org.eclipse.emf.ecore.EStructuralFeature; import org.eclipse.emf.ecore.util.EcoreUtil; import org.emftext.language.sql.resource.sql.ISqlTokenResolveResult; import org.emftext.language.sql.resource.sql.ISqlTokenResolver; public class SqlQUOTED_STRINGTokenResolver implements ISqlTokenResolver { private static final String QUOTE = "'"; private static final String QUOTE_SYMBOL = "''"; public String deResolve(Object value, EStructuralFeature feature, EObject container) { String result = EcoreUtil.convertToString((EDataType) feature.getEType(), value); return QUOTE + result.replace(QUOTE, QUOTE_SYMBOL) + QUOTE; } public void resolve(String lexem, EStructuralFeature feature, ISqlTokenResolveResult result) { lexem = lexem.substring(1, lexem.length() - 1); lexem = lexem.replace(QUOTE_SYMBOL, QUOTE); try { result.setResolvedToken(EcoreUtil.createFromString((EDataType) feature.getEType(), lexem)); } catch (Exception e) { result.setErrorMessage(e.getMessage()); } } public void setOptions(Map<?, ?> options) { } } 8
SQL . , . , non-containment (columns, referencedColumns, referencedTable).
EMFText , , .
8.1
EMFText.
resolve resolveFuzzy (, ), , , , .
resolve resolveFuzzy, .
public class TableColumnsConstraintColumnsReferenceResolver
package org.emftext.language.sql.resource.sql.analysis; import java.util.Map; import java.util.function.Consumer; import java.util.stream.Stream; import org.eclipse.emf.ecore.EReference; import org.emftext.language.sql.resource.sql.ISqlReferenceResolveResult; import org.emftext.language.sql.resource.sql.ISqlReferenceResolver; import org.emftext.language.sql.schema.Column; import org.emftext.language.sql.schema.TableColumnsConstraint; public class TableColumnsConstraintColumnsReferenceResolver implements ISqlReferenceResolver<TableColumnsConstraint, Column> { public void resolve(String identifier, TableColumnsConstraint container, EReference reference, int position, boolean resolveFuzzy, final ISqlReferenceResolveResult<Column> result) { Stream<Column> columns = container.getOwner().getElements().stream() .filter(element -> element instanceof Column) .map(col -> (Column) col); Consumer<Column> addMapping = col -> result.addMapping(col.getName(), col); if (resolveFuzzy) { columns .filter(col -> !container.getColumns().contains(col)) .filter(col -> col.getName().startsWith(identifier)) .forEach(addMapping); } else { columns .filter(col -> col.getName().equals(identifier)) .findFirst() .ifPresent(addMapping); } } public String deResolve(Column element, TableColumnsConstraint container, EReference reference) { return element.getName(); } public void setOptions(Map<?, ?> options) { } } 8.2
, ( ) SQL-. , , .
public class TableReferenceTargetReferenceResolver
package org.emftext.language.sql.resource.sql.analysis; import java.util.Map; import java.util.function.Consumer; import java.util.function.Predicate; import java.util.stream.Stream; import org.eclipse.emf.ecore.EReference; import org.eclipse.emf.ecore.util.EcoreUtil; import org.emftext.language.sql.common.SQLScript; import org.emftext.language.sql.resource.sql.ISqlReferenceResolveResult; import org.emftext.language.sql.resource.sql.ISqlReferenceResolver; import org.emftext.language.sql.schema.TableDefinition; import org.emftext.language.sql.schema.TableReference; public class TableReferenceTargetReferenceResolver implements ISqlReferenceResolver<TableReference, TableDefinition> { public void resolve(String identifier, TableReference container, EReference reference, int position, boolean resolveFuzzy, final ISqlReferenceResolveResult<TableDefinition> result) { SQLScript sqlScript = (SQLScript) EcoreUtil.getRootContainer(container); String catalogName = container.getCatalogName(); Predicate<TableDefinition> filter = !Helper.isEmpty(catalogName) ? table -> catalogName.equals(table.getSchemaQualifiedName().getCatalogName()) : table -> true; String schemaName = container.getSchemaName(); Predicate<TableDefinition> filter2 = !Helper.isEmpty(schemaName) ? table -> schemaName.equals(table.getSchemaQualifiedName().getSchemaName()) : table -> true; Stream<TableDefinition> tables = sqlScript.getStatements().stream() .filter(stmt -> stmt instanceof TableDefinition) .map(table -> (TableDefinition) table) .filter(filter.and(filter2)); Consumer<TableDefinition> addMapping = table -> result.addMapping(table.getSchemaQualifiedName().getName(), table); if (resolveFuzzy) { tables.filter(table -> table.getSchemaQualifiedName() != null && table.getSchemaQualifiedName().getName() != null && table.getSchemaQualifiedName().getName().toUpperCase().startsWith(identifier.toUpperCase())) .forEach(addMapping); } else { tables.filter(table -> table.getSchemaQualifiedName() != null && table.getSchemaQualifiedName().getName() != null && table.getSchemaQualifiedName().getName().equals(identifier)) .findFirst() .ifPresent(addMapping); } } public String deResolve(TableDefinition element, TableReference container, EReference reference) { return element.getSchemaQualifiedName().getName(); } public void setOptions(Map<?, ?> options) { } } 8.3
, , . .
public class ReferentialConstraintReferencedColumnsReferenceResolver
package org.emftext.language.sql.resource.sql.analysis; import java.util.Map; import java.util.function.Consumer; import java.util.stream.Stream; import org.eclipse.emf.ecore.EReference; import org.emftext.language.sql.resource.sql.ISqlReferenceResolveResult; import org.emftext.language.sql.resource.sql.ISqlReferenceResolver; import org.emftext.language.sql.schema.Column; import org.emftext.language.sql.schema.ReferentialConstraint; import org.emftext.language.sql.schema.TableElementList; public class ReferentialConstraintReferencedColumnsReferenceResolver implements ISqlReferenceResolver<ReferentialConstraint, Column> { public void resolve(String identifier, ReferentialConstraint container, EReference reference, int position, boolean resolveFuzzy, final ISqlReferenceResolveResult<Column> result) { Stream<Column> columns = Stream.of(container.getReferencedTable().getTarget()) .filter(table -> table != null) .map(table -> table.getContentsSource()) .filter(src -> src instanceof TableElementList) .flatMap(list -> ((TableElementList) list).getElements().stream()) .filter(element -> element instanceof Column) .map(col -> (Column) col); Consumer<Column> addMapping = col -> result.addMapping(col.getName(), col); if (resolveFuzzy) { columns .filter(col -> !container.getReferencedColumns().contains(col)) .filter(col -> col.getName().startsWith(identifier)) .forEach(addMapping); } else { columns .filter(col -> col.getName().equals(identifier)) .findFirst() .ifPresent(addMapping); } } public String deResolve(Column element, ReferentialConstraint container, EReference reference) { return element.getName(); } public void setOptions(Map<?, ?> options) { } } 9
, , . , , . EMFText , . , SQL- :
public class SqlProposalPostProcessor
package org.emftext.language.sql.resource.sql.ui; import java.util.ArrayList; import java.util.List; import java.util.function.Function; import org.eclipse.emf.ecore.EAttribute; import org.emftext.language.sql.common.SQLScript; import org.emftext.language.sql.resource.sql.analysis.Helper; import org.emftext.language.sql.schema.SchemaPackage; import org.emftext.language.sql.schema.TableDefinition; public class SqlProposalPostProcessor { public List<SqlCompletionProposal> process(List<SqlCompletionProposal> proposals) { List<SqlCompletionProposal> newProposals = new ArrayList<SqlCompletionProposal>(); EAttribute catalogNameFeature = SchemaPackage.eINSTANCE.getTableReference_CatalogName(); EAttribute schemaNameFeature = SchemaPackage.eINSTANCE.getTableReference_SchemaName(); for (SqlCompletionProposal proposal : proposals) { if (catalogNameFeature.equals(proposal.getStructuralFeature())) { addTableReferenceProposal(newProposals, proposal, table -> table.getSchemaQualifiedName().getCatalogName()); } else if (schemaNameFeature.equals(proposal.getStructuralFeature())) { addTableReferenceProposal(newProposals, proposal, table -> table.getSchemaQualifiedName().getSchemaName()); } else { newProposals.add(proposal); } } return newProposals; } private static void addTableReferenceProposal(List<SqlCompletionProposal> proposals, SqlCompletionProposal oldProposal, Function<TableDefinition, String> nameGetter) { SQLScript sqlScript = (SQLScript) oldProposal.getRoot(); String prefix = oldProposal.getPrefix().toUpperCase(); sqlScript.getStatements().stream() .filter(stmt -> stmt instanceof TableDefinition) .map(table -> (TableDefinition) table) .map(nameGetter) .filter(name -> name != null && name.length() > 0) .filter(name -> name.toUpperCase().startsWith(prefix)) .forEach(name -> proposals.add(new SqlCompletionProposal( oldProposal.getExpectedTerminal(), Helper.formatIdentifier(name), oldProposal.getPrefix(), true, oldProposal.getStructuralFeature(), oldProposal.getContainer()))); } } , , , . catalogName schemaName (TableReference) , EMFText , , .
EMFText overrideCompletionProposal, , , , , .
10 SQL
, Eclipse SQL-.
, : , .

, , :

11 SQL
SQL- XMI-. , :

«user» «person» «NAME» «FullName».
SQL- , :

- , - . , , , , .
Conclusion
, EMFText.
, SQL Eclipse, Eclipse. Eclipse IDE, EMFText, , Eclipse. .
, , , GitHub .
:)
Source: https://habr.com/ru/post/271945/
All Articles