How is the rendering frame in GTA V
The Grand Theft Auto series has come a long way since its first release in 1997. About 2 years ago, Rockstar released GTA V. It's an incredible success: in 24 hours, the game was bought by 11 million users, 7 world records were broken in a row. After testing the new PS3, I was very impressed with both the overall picture and, in fact, the technical characteristics of the game.
Nothing spoils the impression of the process like a loading screen, but in GTA V you can play for hours, overcoming endless hundreds of kilometers without interruption. Considering the transfer of a solid stream of information and PS3 properties (256 Mb of RAM and a 256 Mb video card), I was completely surprised at how I was not thrown out of the game at the 20th minute. This is where the wonders of technology.
In this article I will talk about the analysis of the frame in the version for the PC in the environment of DirectX 11, which eats a couple of gigs of both the RAM and the graphics processor. Despite the fact that my review comes with reference to the PC, I am sure that most of the points apply to the PS4 and to a certain extent to the PS3.
')
So, consider the following frame: Michael on the background of his beloved Rapid GT, in the background is the beautiful Los Santos.

Caution! Traffic!
GTA V uses a deferred rendering system that works with multiple HDR buffers. On the monitor, such buffers are not displayed correctly, and therefore I used the Reinhard method to bring everything back to the 8-bit per channel format.
First of all, visualize the cubic texture of the environment. This texture is generated in real time for each individual frame, which subsequently allows you to create realistic reflections. It is brought to the fore.
How is a cubic texture created? For those who are not familiar with the technique, I will explain. This is how to take panoramic pictures: putting the camera on a tripod, imagine that you are standing right in the center of a large cube and photograph all 6 of its faces one by one, turning 90 ° each time.
The game uses the same principle: each face becomes a 128x128 HDR texture. The first face is as follows:

The same scheme is repeated for the 5 remaining faces, and as a result we get a cubic texture (cubemap):

So the cube looks outside

So it looks from the inside (unfortunately, it was not possible to insert the panoramic image presented in the original source in the form of a js-script on Habr)
For each facet, there are more than 30 calls to the drawing procedure, the cells of the graphic grid are very low polygonal, and therefore only the “landscape” (terrain, sky, some buildings) is drawn, the characters and cars remain intact.
That is why in the game, if you look out of the car, the panorama looks great, but other cars and characters do not.
The resulting cubic environment texture is subsequently converted into a double paraboloid.
Simply put, a cube is simply projected in a different space. The projection is similar to spherical modeling, however, here we have 2 "hemispheres".

Cube in "turn" and the resulting "hemispheres"
What are such transformations for? I think the whole thing (as always) is in optimization: in a cubic texture, fragment shaders, theoretically, have access to 6 faces of 128x128 in size, while in the case of the double paraboloid texture everything comes down to 2 “hemispheres” 128x128. In addition, since the camera is located on the roof of the car most of the time, most requests go to the upper hemisphere.
The projection of the double paraboloid preserves the details of the reflection of the upper and lower parts of the object due to some errors of the sides. For GTA, this is fine: the roofs and hoods of cars, as a rule, are shown from above, and therefore it is important that this reflection be of high quality.
Plus, the edges of cubic maps often leave much to be desired: if the accuracy of the display of textures depends on the distance to the object, then individual seams can be found within the edges, especially along the contours, and no older face filters are provided in older graphic processors. For double paraboloids, this problem is irrelevant, since textures remain clear, regardless of distance, and no seams interfere with the perception of the picture as a whole.
Addition: I noted in the comments that, in all likelihood, GTA IV also used a double paraboloid map, although not in the process of post-processing a cubic texture. Graphic grid cells are directly transformed using a vertex shader.
Since the shader is responsible for this stage, I will not have an illustration for it.
Depending on the distance to the camera, the object will be high or low poly or will not be drawn at all. This happens, for example, with grass or flowers in the distance. So, at this stage, the necessity of drawing the object is determined and, if it exists, with what level of detail.
This is where the differences between running the game on PS3 (not enough computational support for shaders) and PC or PS4 are found.
The "main" share of rendering takes place right here. All visible cells of the graphic grid are drawn one by one, but instead of immediately calculating the degree of shading, the draw calls only capture the necessary information in separate buffers, called G-Buffer. GTA V uses MRT technology, which allows each draw call to capture up to 5 special commands.
During the subsequent compilation of buffers, it is possible to calculate the total shading indicators for each pixel. Hence the name “deferred” as opposed to “direct” shading, in which each draw call is responsible for self-calculation of the final shielding shadow indicator.
At this stage, only opaque objects are drawn, since transparent parts, like glass, require additional pending processing, which is performed later.
G-Buffer Generation

15% generation

30% generation

50% generation

75% generation

100% generation
For the reproduction of all these effects are responsible for the purpose of rendering - LDR-buffers (RGBA with 8 bits per channel), which store various information, which later will be needed to calculate the total shading indicators:
• Diffuse map: retains the “original color” of the cell. In fact, it is a property of the material and, in fact, does not change with different lighting. But see the white highlights on the hood of the car? It is noteworthy that in GTA V shading is calculated on the basis of incoming sunlight before the formation of a diffuse map itself. The necessary information about “mixing” is stored in the alpha channel (more on this later).
• Normal Map: Saves normal vectors for each pixel (R, G, B). The alpha channel is also used here, although I'm not sure how: it looks like it performs the function of a binary mask for individual plants located near the camera;
• Glare map. The information related to highlights and reflections is stored here:
• Illumination map: apparently, the red channel stores the data on the illumination of each pixel due to sunlight (based on the normal pixel data, their position and direction of incoming sunlight). I'm not quite sure about the green channel, but it seems that he is responsible for the illumination due to additional light sources. Blue channel - data on the emission properties of pixels (non-zero value for neon lamps). A significant part of the alpha channel is not involved, except for marking the pixels corresponding to the character's skin or image of vegetation.
So, earlier I mentioned creating teams at the same time for 5 rendering targets, but I only talked about 4 of them.
An overlooked visualization is a special buffer that combines depth and pattern indicators. Here is what we get as a result:

Depth on the left and pattern on the right respectively
Depth map : it records information about the distance of each pixel to the camera.
Intuitively, one would expect distant pixels to be white (depth 1), and those that are closer would be darker. But this is not the case: apparently, in GTA V they used a logarithmic Z-buffer, changing Z. But why? It seems to be a matter of floating-point numbers, which are much more accurate in the encoding process, if their value is close to 0. So, by changing Z, you can enter much more accurate data on the depth of distant objects, which, in turn, eliminate Z-errors. Given the length of the gaming session, it was simply impossible not to use such a technique. Although, GTA V and did not discover America, because a similar technique is found in the same Just Cause 2, for example.
Pattern : Used to identify various rendered cells, assigning a common ID to all the pixels of a specific group of cells. For example, here are some values in the template:
All these buffers were generated thanks to more than 1900 render calls.
Please note that the rendering is performed as if “backwards”, which allows you to optimize all the necessary operations taking into account the fragment depth comparison with the depth buffer value at the rasterization stage: in the process of drawing a scene, many details fail the depth test, since they are overlapped by closely spaced pixels, drawn earlier. If it is obvious that the pixel does not pass the depth test, the graphics processor can automatically skip it, even without starting the shader. If we are dealing with heavy pixel shaders, only the standard direct rendering order is appropriate, while the “reverse” ( artist's algorithm ) will be the most ineffective in this case.
And now I would like to say a few words about the role of the alpha channel in the diffuse map. Look at the screenshot:

Approximate fragment of the diffusion map
See some pixels missing? This is especially noticeable in the example of trees. As if there are no separate texels in the sprites.
I already paid attention to this feature earlier, launching games on PS3, and then I was very puzzled. Maybe the whole thing in the excessive reduction of the sprite texture? But now I know that this is not the case, because the compilation of elements has been carried out correctly.
Such a model really looks strange, almost like a chessboard. Is it possible that ... the game renders only 1 out of 2 pixels?
To clarify, I looked into the D3D bytecode. And here you are:
In fact, we see the condition (X + Y)% 2 == 0, which is observed for only one pixel out of 2 (where x and y are the coordinates of the pixel).
This is only one of the reasons for the sampling of pikels (the second is the alpha value <0.75), although it was quite enough to explain the specifics of the detected phenomenon.
Information about which cells were rendered in the considered “selective” mode is stored on the alpha channel of the diffuse map, as seen in the picture.
 So why are some models rendered this way? Maybe it helped to save the fill or shading options? I didn’t mean to say that the graphics processors do not provide for such detailing: the pixels are painted over not separately, but in groups of 2x2. And it's not about performance, it's a matter of the level of detail: this model makes the filled cells more transparent due to different levels of detail.
So why are some models rendered this way? Maybe it helped to save the fill or shading options? I didn’t mean to say that the graphics processors do not provide for such detailing: the pixels are painted over not separately, but in groups of 2x2. And it's not about performance, it's a matter of the level of detail: this model makes the filled cells more transparent due to different levels of detail.
This method is called alpha stippling .
The game uses CSM (cascading shadow maps): 4 shadow maps form 1024x4096 textures. Each shadow map is designed for different visibility. The more often the actions are repeated, the wider the pyramid of visibility of the camera, the greater the panorama of the frame. Thanks to this approach, the shadows of objects near the game character have a higher resolution than the shadows of distant objects. Here is a brief overview of the depth of 4 maps:

This process may require a lot of energy, since you have to re-render the scene as much as 4 times, but cutting off the visibility pyramid allows you to lower the processing of unnecessary polygons. In this case, the CSM was created as a result of 1000 draw calls.
Having this depth data, you can calculate the shadow for each pixel. Information about shadows is stored in the rendering target: the shadows cast as a result of direct sunlight are recorded in the red channel, the shadows from the clouds in - in red and green.
In the shadow maps, a smoothing pattern is provided (if you look closely at the texture shown below, you will see the previously mentioned chessboard effect in the red channel). This allows you to smooth the edges of the shadows.
Later, these gaps are filled: the shadows from the sun and clouds are combined into one buffer, a certain depth blur is produced, and the result is stored in the alpha channel of the glare map.

Shadows from the sun and clouds (green)

Blurred Shadows
A few words about the blur: the technique is not cheap, because have to deal separately with different textures. Thus, to facilitate the task, just before performing the blur, a “lightweight” texture is created: the shadow buffer scale is reduced to 1: 8 and a light blur is made by the pixel shader by repeating the Grab () command four times. This allows you to roughly estimate the total number of fully lit pixels. Subsequently, when a full blur is needed, first of all, information about the “lightweight” version of the procedure is read: as soon as the shader encounters a fully lit pixel, it automatically gives out units and it does not have to start the laborious process of full-scale blurring.
 I will not go into details, since I highlighted the theme of reflection ( image of the reflection map of the plane on the right ) in the second part and in this scene, the effect is barely noticeable. I can only say that this step generates a reflection map for the ocean surface. The essence of the principle is reduced to redrawing the scene (650 rendering calls) within the framework of a tiny texture of 240x120, but already in the "upside down" mode to create a feeling of reflection in the water.
I will not go into details, since I highlighted the theme of reflection ( image of the reflection map of the plane on the right ) in the second part and in this scene, the effect is barely noticeable. I can only say that this step generates a reflection map for the ocean surface. The essence of the principle is reduced to redrawing the scene (650 rendering calls) within the framework of a tiny texture of 240x120, but already in the "upside down" mode to create a feeling of reflection in the water.
Here we are dealing with the creation of a linear version of the depth buffer, on the basis of which the SSAO map is formed (blocking of ambient light in the screen space).

Sharp image

Blurred image
First, the first version appears with all the noises, after which the depth blur is successively carried out in both horizontal and vertical directions, which noticeably smoothes the image.
All work is done at a resolution of only half of the original, which guarantees higher performance.
So, it is time to combine all the generated buffers!
The pixel shader reads data from various buffers and determines the final pixel shading value in HDR.
In case we work with night scenes, lights and other elements of illumination will gradually, one after another, be superimposed on top of the scene.

And we get the final image:

The picture is becoming more pleasant, although there is still not enough ocean, sky, transparent objects ... But first, the main thing: you need to refine the image of Michael.
There are questions with Michael's skin shading: there are very dark areas on the face and it seems as if it is a dense plastic, and not a human body.
That's what we need SSS for. Dispersion imitates natural skin coverage. Look at your ears or lips: thanks to SSS, they look much more real, a healthy pinkish tinge appears in them.

But how did you manage to run SSS separately for Michael's image?
First, only the silhouette is cut. Here the previously generated template buffer comes to the rescue: all Michael pixels are assigned the value 0x89. Thus, we can concentrate on them, but we need to apply SSS only to the skin, and not to clothes.
In fact, when all the G-buffers were combined, in addition to the shading indicators stored in RGB, some data was recorded in the alpha channel. More specifically, the alpha channels of the irradiance map and the glare map were used to create a binary mask: the pixels corresponding to Michael’s skin and the image of some plants were marked with a unit in the alpha channel. Other pixels, in particular, clothing pixels, were assigned the alpha 0 value.
Thus, it is possible to apply SSS, having as the initial data the combined information from the target of the G-buffer and a buffer comparing the depth and pattern indicators.
Yes, it may seem that such minor local transformations are not worth such serious calculations. And, perhaps, you would be right if it were not for one thing: playing the game, we instinctively look at the face, and therefore the treatment for this part of the body allows us to bring the game as close as possible to reality. In GTA V, the SSS is applied both to the image of the main character and in the case of non-player characters.
In the scene in question, not so much water got into the frame, but still: the ocean in the background, a couple of pools here and there.
The visualization of water in GTA V is concentrated in two directions - reflection and refraction.
The logarithmic Z-buffer created earlier allows to generate the second version, this time linear with the resolution half the size of the original one.
Ocean and pools are rendered in turn in MRT mode. So at the same time achieved several goals:

Left diffusion of water, right opacity
Now we can combine previously created buffers and generate a refraction map:

Water refraction map
On this map of refraction, the pools are filled with water (the deeper the water, the bluer it is), caustics are also added.
It's time to start the final visualization of water: again, one by one, all the cells corresponding to the images of the ocean and pools are drawn, but this time the reflection and refraction are combined, and relief maps are formed, making corrections to the surface normals.

Image before adding water

Refraction on the plane, reflection and relief maps

Image after adding water
Create a map of the so-called volumetric shadows: it helps to darken the atmosphere / fog, which are not directly illuminated by the sun.
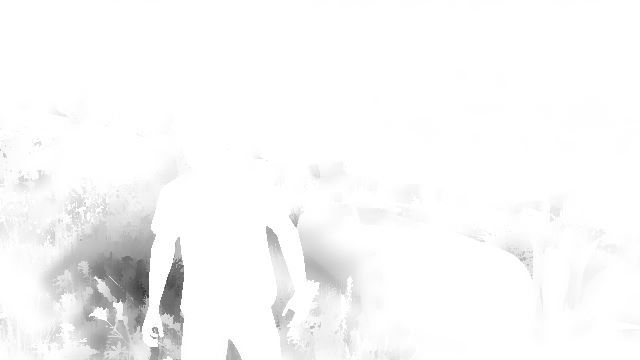
The map is generated at half the resolution by scanning the pixels and comparing the received data with the shadow map from the sun. After receiving the first option with all the noise buffer is blurred.
Base image
Then the fog effect is added to the scene: it perfectly hides the missing details of the low poly buildings that are seen far away. Here data is read from the volume shadow map (does not play a significant role at this stage) and the depth buffer, on the basis of which fog indicators are formed.

Base image with fog
After the sky is visualized.

And at the very end, after him, the clouds are drawn.

Final image
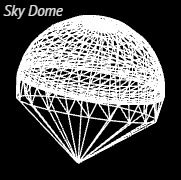 In fact, the sky is rendered by a single draw call: the sky's graphic grid forms a huge dome covering the entire scene (see right).
In fact, the sky is rendered by a single draw call: the sky's graphic grid forms a huge dome covering the entire scene (see right).
At this stage, separate textures are used, resembling the effect of Perlin noise .
Clouds are also visualized: an extensive grid appears on the horizon, this time in the form of a ring. One normal map and one density map allow you to visualize the clouds: these are large seamless textures of 2048x512 (connected in an arc on the left and right sides).

The density of the clouds on the left
Now let's deal with all transparent objects: glasses, windshield, dust particles in the air ...
All in all, 11 draw calls will be required, however, when processing the dust, you will have to repeatedly refer to the instancing.

Final image
Remember the previous brief overview of individual trees smoothed on a diffuse map? This is how the image looks without smoothing:

It's time to fix it: we run a pixel shader for post-processing - and it reads the data of the buffer of the original color and the alpha channel of the diffuse map to find out which pixels are smoothed. Up to 2 neighboring pixels may be required for each pixel to determine the final color of the “smoothed” element.

After smoothing
This is a great trick, because with its help the whole image is “aligned” in one approach: moreover, the variety of geometric shapes in a given scene does not matter.
Note, however, that this filter is not ideal: in some cases, apparently, it failed, I still noticed the effect of a chessboard on the PS3, and on the PC.
Prior to that, the processed image was saved in the HDR format: each RGB channel is stored as a 16-bit floating point index, which made it possible to significantly expand the range of illumination intensity. But monitors are not able to display such different values and reduce everything to RGB colors with 8 bits per channel.
Tonal compression converts these color values from HDR to LDR. There are several functions by which one format is replaced by another. The classic version, widely used - the Reinhard method (I used it when creating screenshots published earlier) - gives results that are close to the final form of the game.
But did GTA V really use the Reinhard method? We'll have to get into the shader bytecode again:
So, so ... what do we have here? It is an equation of the type
It turns out that in GTA V, there is no talk of the Reinhard method, but the principle from Uncharted 2, according to which black areas are not discolored, is also not suitable.
The conversion process to LDR is as follows:
The resolution of the HDR buffer is reduced to ¼ from the original value.
The end result depends on the exposure. Here are literally several examples of the effect of this parameter:

The exposure changes gradually, frame by frame, you will not see drastic changes.
So an attempt was made to imitate the nature of the human eye: did you notice that after a long journey through a dark tunnel and a sudden exit to the sun, the environment is perceived too bright for a while? Then it stops “cutting the eye” and becomes “normal”, and the exposure adapts to the new value. It seems that in GTA V they went even further, bringing the adaptation of exposure along the “Dark → Bright” line to similar properties of the human eye as close as possible.
If the FXAA method is used, then he is definitely paying attention to smoothing out the uneven contours of the cells.
Then, using small pixel shaders to simulate a real camera, the lens distortion effect is triggered. This not only distorts the image, it also initiates minor color changes along the frame contour, where the red channel dominates slightly above the green and blue.

Before distortion

After distortion
And the final touch: the user interface, represented by a mini-map in the lower left corner of the screen. The map is actually divided into several square zones, the engine is responsible only for those that are displayed on the screen. Each square is associated with a draw call. I painted the squares to more clearly demonstrate the structure:
Minimap
The clipping test allows not only to process the area in the lower left corner, but also to delete the contents of the area. There are vectors on all roads (see the screenshot above), they are displayed as graphical grids and look great even with a significant increase.
Image before adding a minimap
At this stage, the minimap is sent to the main image buffer, a couple of small icons and widgets are added on top of it.
Yes, they spent a lot of time, but it was worth it: here is the final shot in all its glory!
A total of 4155 render calls, 1113 textures and 88 rendering targets were required.
Afterword from the translator.
Nothing spoils the impression of the process like a loading screen, but in GTA V you can play for hours, overcoming endless hundreds of kilometers without interruption. Considering the transfer of a solid stream of information and PS3 properties (256 Mb of RAM and a 256 Mb video card), I was completely surprised at how I was not thrown out of the game at the 20th minute. This is where the wonders of technology.
In this article I will talk about the analysis of the frame in the version for the PC in the environment of DirectX 11, which eats a couple of gigs of both the RAM and the graphics processor. Despite the fact that my review comes with reference to the PC, I am sure that most of the points apply to the PS4 and to a certain extent to the PS3.
')
Frame analysis
So, consider the following frame: Michael on the background of his beloved Rapid GT, in the background is the beautiful Los Santos.
Caution! Traffic!
GTA V uses a deferred rendering system that works with multiple HDR buffers. On the monitor, such buffers are not displayed correctly, and therefore I used the Reinhard method to bring everything back to the 8-bit per channel format.
Environment Cubemap
First of all, visualize the cubic texture of the environment. This texture is generated in real time for each individual frame, which subsequently allows you to create realistic reflections. It is brought to the fore.
How is a cubic texture created? For those who are not familiar with the technique, I will explain. This is how to take panoramic pictures: putting the camera on a tripod, imagine that you are standing right in the center of a large cube and photograph all 6 of its faces one by one, turning 90 ° each time.
The game uses the same principle: each face becomes a 128x128 HDR texture. The first face is as follows:
The same scheme is repeated for the 5 remaining faces, and as a result we get a cubic texture (cubemap):
So the cube looks outside
So it looks from the inside (unfortunately, it was not possible to insert the panoramic image presented in the original source in the form of a js-script on Habr)
For each facet, there are more than 30 calls to the drawing procedure, the cells of the graphic grid are very low polygonal, and therefore only the “landscape” (terrain, sky, some buildings) is drawn, the characters and cars remain intact.
That is why in the game, if you look out of the car, the panorama looks great, but other cars and characters do not.
From cubic to double paraboloid texture
The resulting cubic environment texture is subsequently converted into a double paraboloid.
Simply put, a cube is simply projected in a different space. The projection is similar to spherical modeling, however, here we have 2 "hemispheres".
Cube in "turn" and the resulting "hemispheres"
What are such transformations for? I think the whole thing (as always) is in optimization: in a cubic texture, fragment shaders, theoretically, have access to 6 faces of 128x128 in size, while in the case of the double paraboloid texture everything comes down to 2 “hemispheres” 128x128. In addition, since the camera is located on the roof of the car most of the time, most requests go to the upper hemisphere.
The projection of the double paraboloid preserves the details of the reflection of the upper and lower parts of the object due to some errors of the sides. For GTA, this is fine: the roofs and hoods of cars, as a rule, are shown from above, and therefore it is important that this reflection be of high quality.
Plus, the edges of cubic maps often leave much to be desired: if the accuracy of the display of textures depends on the distance to the object, then individual seams can be found within the edges, especially along the contours, and no older face filters are provided in older graphic processors. For double paraboloids, this problem is irrelevant, since textures remain clear, regardless of distance, and no seams interfere with the perception of the picture as a whole.
Addition: I noted in the comments that, in all likelihood, GTA IV also used a double paraboloid map, although not in the process of post-processing a cubic texture. Graphic grid cells are directly transformed using a vertex shader.
Rejection and level of detail
Since the shader is responsible for this stage, I will not have an illustration for it.
Depending on the distance to the camera, the object will be high or low poly or will not be drawn at all. This happens, for example, with grass or flowers in the distance. So, at this stage, the necessity of drawing the object is determined and, if it exists, with what level of detail.
This is where the differences between running the game on PS3 (not enough computational support for shaders) and PC or PS4 are found.
G-Buffer Generation
The "main" share of rendering takes place right here. All visible cells of the graphic grid are drawn one by one, but instead of immediately calculating the degree of shading, the draw calls only capture the necessary information in separate buffers, called G-Buffer. GTA V uses MRT technology, which allows each draw call to capture up to 5 special commands.
During the subsequent compilation of buffers, it is possible to calculate the total shading indicators for each pixel. Hence the name “deferred” as opposed to “direct” shading, in which each draw call is responsible for self-calculation of the final shielding shadow indicator.
At this stage, only opaque objects are drawn, since transparent parts, like glass, require additional pending processing, which is performed later.
G-Buffer Generation
15% generation
30% generation
50% generation
75% generation
100% generation
For the reproduction of all these effects are responsible for the purpose of rendering - LDR-buffers (RGBA with 8 bits per channel), which store various information, which later will be needed to calculate the total shading indicators:
• Diffuse map: retains the “original color” of the cell. In fact, it is a property of the material and, in fact, does not change with different lighting. But see the white highlights on the hood of the car? It is noteworthy that in GTA V shading is calculated on the basis of incoming sunlight before the formation of a diffuse map itself. The necessary information about “mixing” is stored in the alpha channel (more on this later).
• Normal Map: Saves normal vectors for each pixel (R, G, B). The alpha channel is also used here, although I'm not sure how: it looks like it performs the function of a binary mask for individual plants located near the camera;
• Glare map. The information related to highlights and reflections is stored here:
- Red: highlight intensity;
- Green: gloss (smoothness);
- Blue: saturation of intermediate highlights (usually a constant figure for all pixels with an image of the same material).
• Illumination map: apparently, the red channel stores the data on the illumination of each pixel due to sunlight (based on the normal pixel data, their position and direction of incoming sunlight). I'm not quite sure about the green channel, but it seems that he is responsible for the illumination due to additional light sources. Blue channel - data on the emission properties of pixels (non-zero value for neon lamps). A significant part of the alpha channel is not involved, except for marking the pixels corresponding to the character's skin or image of vegetation.
So, earlier I mentioned creating teams at the same time for 5 rendering targets, but I only talked about 4 of them.
An overlooked visualization is a special buffer that combines depth and pattern indicators. Here is what we get as a result:
Depth on the left and pattern on the right respectively
Depth map : it records information about the distance of each pixel to the camera.
Intuitively, one would expect distant pixels to be white (depth 1), and those that are closer would be darker. But this is not the case: apparently, in GTA V they used a logarithmic Z-buffer, changing Z. But why? It seems to be a matter of floating-point numbers, which are much more accurate in the encoding process, if their value is close to 0. So, by changing Z, you can enter much more accurate data on the depth of distant objects, which, in turn, eliminate Z-errors. Given the length of the gaming session, it was simply impossible not to use such a technique. Although, GTA V and did not discover America, because a similar technique is found in the same Just Cause 2, for example.
Pattern : Used to identify various rendered cells, assigning a common ID to all the pixels of a specific group of cells. For example, here are some values in the template:
- 0x89: character controlled by the player;
- 0x82: player driven car;
- 0x01: non-player characters;
- 0x02: vehicles, including cars, bicycles, and so on;
- 0x03: vegetation and foliage;
- 0x07: sky
All these buffers were generated thanks to more than 1900 render calls.
Please note that the rendering is performed as if “backwards”, which allows you to optimize all the necessary operations taking into account the fragment depth comparison with the depth buffer value at the rasterization stage: in the process of drawing a scene, many details fail the depth test, since they are overlapped by closely spaced pixels, drawn earlier. If it is obvious that the pixel does not pass the depth test, the graphics processor can automatically skip it, even without starting the shader. If we are dealing with heavy pixel shaders, only the standard direct rendering order is appropriate, while the “reverse” ( artist's algorithm ) will be the most ineffective in this case.
And now I would like to say a few words about the role of the alpha channel in the diffuse map. Look at the screenshot:
Approximate fragment of the diffusion map
See some pixels missing? This is especially noticeable in the example of trees. As if there are no separate texels in the sprites.
I already paid attention to this feature earlier, launching games on PS3, and then I was very puzzled. Maybe the whole thing in the excessive reduction of the sprite texture? But now I know that this is not the case, because the compilation of elements has been carried out correctly.
Such a model really looks strange, almost like a chessboard. Is it possible that ... the game renders only 1 out of 2 pixels?
To clarify, I looked into the D3D bytecode. And here you are:
dp2 r1.y, v0.xyxx, l(0.5, 0.5, 0.0, 0.0) // Dot product of the pixel's (x,y) with (0.5, 0.5) frc r1.y, r1.y // Keeps only the fractional part: always 0.0 or 0.5 lt r1.y, r1.y, l(0.5) // Test if the fractional part is smaller than 0.5 In fact, we see the condition (X + Y)% 2 == 0, which is observed for only one pixel out of 2 (where x and y are the coordinates of the pixel).
This is only one of the reasons for the sampling of pikels (the second is the alpha value <0.75), although it was quite enough to explain the specifics of the detected phenomenon.
Information about which cells were rendered in the considered “selective” mode is stored on the alpha channel of the diffuse map, as seen in the picture.
Diffuse map alpha channel
So why are some models rendered this way? Maybe it helped to save the fill or shading options? I didn’t mean to say that the graphics processors do not provide for such detailing: the pixels are painted over not separately, but in groups of 2x2. And it's not about performance, it's a matter of the level of detail: this model makes the filled cells more transparent due to different levels of detail.This method is called alpha stippling .
Shadows
The game uses CSM (cascading shadow maps): 4 shadow maps form 1024x4096 textures. Each shadow map is designed for different visibility. The more often the actions are repeated, the wider the pyramid of visibility of the camera, the greater the panorama of the frame. Thanks to this approach, the shadows of objects near the game character have a higher resolution than the shadows of distant objects. Here is a brief overview of the depth of 4 maps:
Shadow maps
This process may require a lot of energy, since you have to re-render the scene as much as 4 times, but cutting off the visibility pyramid allows you to lower the processing of unnecessary polygons. In this case, the CSM was created as a result of 1000 draw calls.
Having this depth data, you can calculate the shadow for each pixel. Information about shadows is stored in the rendering target: the shadows cast as a result of direct sunlight are recorded in the red channel, the shadows from the clouds in - in red and green.
In the shadow maps, a smoothing pattern is provided (if you look closely at the texture shown below, you will see the previously mentioned chessboard effect in the red channel). This allows you to smooth the edges of the shadows.
Later, these gaps are filled: the shadows from the sun and clouds are combined into one buffer, a certain depth blur is produced, and the result is stored in the alpha channel of the glare map.
Shadows from the sun and clouds (green)
Blurred Shadows
A few words about the blur: the technique is not cheap, because have to deal separately with different textures. Thus, to facilitate the task, just before performing the blur, a “lightweight” texture is created: the shadow buffer scale is reduced to 1: 8 and a light blur is made by the pixel shader by repeating the Grab () command four times. This allows you to roughly estimate the total number of fully lit pixels. Subsequently, when a full blur is needed, first of all, information about the “lightweight” version of the procedure is read: as soon as the shader encounters a fully lit pixel, it automatically gives out units and it does not have to start the laborious process of full-scale blurring.
I will not go into details, since I highlighted the theme of reflection ( image of the reflection map of the plane on the right ) in the second part and in this scene, the effect is barely noticeable. I can only say that this step generates a reflection map for the ocean surface. The essence of the principle is reduced to redrawing the scene (650 rendering calls) within the framework of a tiny texture of 240x120, but already in the "upside down" mode to create a feeling of reflection in the water.Obstruction of ambient light in screen space
Here we are dealing with the creation of a linear version of the depth buffer, on the basis of which the SSAO map is formed (blocking of ambient light in the screen space).
Sharp image
Blurred image
First, the first version appears with all the noises, after which the depth blur is successively carried out in both horizontal and vertical directions, which noticeably smoothes the image.
All work is done at a resolution of only half of the original, which guarantees higher performance.
G-Buffer Combination
So, it is time to combine all the generated buffers!
The pixel shader reads data from various buffers and determines the final pixel shading value in HDR.
In case we work with night scenes, lights and other elements of illumination will gradually, one after another, be superimposed on top of the scene.
And we get the final image:
The picture is becoming more pleasant, although there is still not enough ocean, sky, transparent objects ... But first, the main thing: you need to refine the image of Michael.
Subsurface Scattering (subsurface scattering)
There are questions with Michael's skin shading: there are very dark areas on the face and it seems as if it is a dense plastic, and not a human body.
That's what we need SSS for. Dispersion imitates natural skin coverage. Look at your ears or lips: thanks to SSS, they look much more real, a healthy pinkish tinge appears in them.
But how did you manage to run SSS separately for Michael's image?
First, only the silhouette is cut. Here the previously generated template buffer comes to the rescue: all Michael pixels are assigned the value 0x89. Thus, we can concentrate on them, but we need to apply SSS only to the skin, and not to clothes.
In fact, when all the G-buffers were combined, in addition to the shading indicators stored in RGB, some data was recorded in the alpha channel. More specifically, the alpha channels of the irradiance map and the glare map were used to create a binary mask: the pixels corresponding to Michael’s skin and the image of some plants were marked with a unit in the alpha channel. Other pixels, in particular, clothing pixels, were assigned the alpha 0 value.
Thus, it is possible to apply SSS, having as the initial data the combined information from the target of the G-buffer and a buffer comparing the depth and pattern indicators.
Yes, it may seem that such minor local transformations are not worth such serious calculations. And, perhaps, you would be right if it were not for one thing: playing the game, we instinctively look at the face, and therefore the treatment for this part of the body allows us to bring the game as close as possible to reality. In GTA V, the SSS is applied both to the image of the main character and in the case of non-player characters.
Water
In the scene in question, not so much water got into the frame, but still: the ocean in the background, a couple of pools here and there.
The visualization of water in GTA V is concentrated in two directions - reflection and refraction.
The logarithmic Z-buffer created earlier allows to generate the second version, this time linear with the resolution half the size of the original one.
Ocean and pools are rendered in turn in MRT mode. So at the same time achieved several goals:
Left diffusion of water, right opacity
- Diffuse water map: captures the original water color.
- Water opacity map: in the red channel, in fact, information is stored about the individual properties of water opacity (for example, for the ocean it is always 0.102, for pools it is 0.129). In the green channel, it is marked how deep the pixel is located relative to the water surface (deep pixels correspond to less transparent water, which requires connecting a diffuse map, while water pixels from the surface are much more transparent).
- Please note: all pools are visualized without reference to the conditions, even if they are practically covered by data from other cells, they are still stored in the red channel. As for the green channel, where only really visible pixels are counted, only “water” pixels fall on the finished image.
Now we can combine previously created buffers and generate a refraction map:
Water refraction map
On this map of refraction, the pools are filled with water (the deeper the water, the bluer it is), caustics are also added.
It's time to start the final visualization of water: again, one by one, all the cells corresponding to the images of the ocean and pools are drawn, but this time the reflection and refraction are combined, and relief maps are formed, making corrections to the surface normals.
Image before adding water
Refraction on the plane, reflection and relief maps
Image after adding water
Atmosphere
Create a map of the so-called volumetric shadows: it helps to darken the atmosphere / fog, which are not directly illuminated by the sun.
The map is generated at half the resolution by scanning the pixels and comparing the received data with the shadow map from the sun. After receiving the first option with all the noise buffer is blurred.
Base image
Then the fog effect is added to the scene: it perfectly hides the missing details of the low poly buildings that are seen far away. Here data is read from the volume shadow map (does not play a significant role at this stage) and the depth buffer, on the basis of which fog indicators are formed.
Base image with fog
After the sky is visualized.
And at the very end, after him, the clouds are drawn.
Final image
In fact, the sky is rendered by a single draw call: the sky's graphic grid forms a huge dome covering the entire scene (see right).At this stage, separate textures are used, resembling the effect of Perlin noise .
Clouds are also visualized: an extensive grid appears on the horizon, this time in the form of a ring. One normal map and one density map allow you to visualize the clouds: these are large seamless textures of 2048x512 (connected in an arc on the left and right sides).
The density of the clouds on the left
Transparent objects
Now let's deal with all transparent objects: glasses, windshield, dust particles in the air ...
All in all, 11 draw calls will be required, however, when processing the dust, you will have to repeatedly refer to the instancing.
Final image
Bit smoothing
Remember the previous brief overview of individual trees smoothed on a diffuse map? This is how the image looks without smoothing:
It's time to fix it: we run a pixel shader for post-processing - and it reads the data of the buffer of the original color and the alpha channel of the diffuse map to find out which pixels are smoothed. Up to 2 neighboring pixels may be required for each pixel to determine the final color of the “smoothed” element.
After smoothing
This is a great trick, because with its help the whole image is “aligned” in one approach: moreover, the variety of geometric shapes in a given scene does not matter.
Note, however, that this filter is not ideal: in some cases, apparently, it failed, I still noticed the effect of a chessboard on the PS3, and on the PC.
Tonal compression and glow
Prior to that, the processed image was saved in the HDR format: each RGB channel is stored as a 16-bit floating point index, which made it possible to significantly expand the range of illumination intensity. But monitors are not able to display such different values and reduce everything to RGB colors with 8 bits per channel.
Tonal compression converts these color values from HDR to LDR. There are several functions by which one format is replaced by another. The classic version, widely used - the Reinhard method (I used it when creating screenshots published earlier) - gives results that are close to the final form of the game.
But did GTA V really use the Reinhard method? We'll have to get into the shader bytecode again:
// Suppose r0 is the HDR color, r1.xyzw is (A, B, C, D) and r2.yz is (E, F) mul r3.xy, r1.wwww, r2.yzyy // (DE, DF) mul r0.w, r1.y, r1.z // BC [...] div r1.w, r2.y, r2.z // E/F [...] mad r2.xyz, r1.xxxx, r0.xyzx, r0.wwww // Ax+BC mad r2.xyz, r0.xyzx, r2.xyzx, r3.xxxx // x(Ax+BC)+DE mad r3.xzw, r1.xxxx, r0.xxyz, r1.yyyy // Ax+B mad r0.xyz, r0.xyzx, r3.xzwx, r3.yyyy // x(Ax+B)+ DF div r0.xyz, r2.xyzx, r0.xyzx // (x(Ax+BC)+DE) / (x(Ax+B)+DF) add r0.xyz, -r1.wwww, r0.xyzx // (x(Ax+BC)+DE) / (x(Ax+B)+DF) - (E/F) So, so ... what do we have here? It is an equation of the type
(x(Ax+BC)+DE) / (x(Ax+B)+DF) - (E/F) marked the breakthrough of John Heble in the film industry in 2009.It turns out that in GTA V, there is no talk of the Reinhard method, but the principle from Uncharted 2, according to which black areas are not discolored, is also not suitable.
The conversion process to LDR is as follows:
The resolution of the HDR buffer is reduced to ¼ from the original value.
- The computational shader determines the average brightness of the buffer, outputting the result as a 1x1 texture.
- A new exposure is calculated, due to which the scene will be bright / dark.
- The brightness filter requests only pixels that have a brightness above a certain value (set by exposure).
- In this scene, only a few pixels were filtered: some illuminated areas on a car with a high reflectivity.
- Indicators of the brightness buffer are repeatedly reduced up to 1/16 of the original, and then increase to 1/2 of the original.
- A glow is added to the original HDR pixels, and then using the converter from Uncharted 2, the color is converted to LDR. At the same time, gamma correction is performed, which allows replacing linear channels with sRGB.
The end result depends on the exposure. Here are literally several examples of the effect of this parameter:
The exposure changes gradually, frame by frame, you will not see drastic changes.
So an attempt was made to imitate the nature of the human eye: did you notice that after a long journey through a dark tunnel and a sudden exit to the sun, the environment is perceived too bright for a while? Then it stops “cutting the eye” and becomes “normal”, and the exposure adapts to the new value. It seems that in GTA V they went even further, bringing the adaptation of exposure along the “Dark → Bright” line to similar properties of the human eye as close as possible.
Smoothing and distorting the lens
If the FXAA method is used, then he is definitely paying attention to smoothing out the uneven contours of the cells.
Then, using small pixel shaders to simulate a real camera, the lens distortion effect is triggered. This not only distorts the image, it also initiates minor color changes along the frame contour, where the red channel dominates slightly above the green and blue.
Before distortion
After distortion
User interface
And the final touch: the user interface, represented by a mini-map in the lower left corner of the screen. The map is actually divided into several square zones, the engine is responsible only for those that are displayed on the screen. Each square is associated with a draw call. I painted the squares to more clearly demonstrate the structure:
Minimap
The clipping test allows not only to process the area in the lower left corner, but also to delete the contents of the area. There are vectors on all roads (see the screenshot above), they are displayed as graphical grids and look great even with a significant increase.
Image before adding a minimap
At this stage, the minimap is sent to the main image buffer, a couple of small icons and widgets are added on top of it.
Yes, they spent a lot of time, but it was worth it: here is the final shot in all its glory!
A total of 4155 render calls, 1113 textures and 88 rendering targets were required.
PART No.2: Detailing, reflections and post effects in GTA V
Afterword from the translator.
Dear readers, I hope you enjoyed this material. If this is the case, then we, in the face of the ua-hosting.company team, will prepare a sequel for you, posted on the original author’s blog.
We are trying to prepare interesting materials for you, in which there is no b-harsh SEO-optimization of the text and at least three references to yourself. Therefore, you can feel free to subscribe to our blogs on Habré and Hiktimes , and we will try so that you do not regret it. I would also like to add that we are well aware that no one likes advertising, especially arrogant, and we in every possible way try to avoid it in our materials. Therefore, we leave a link to the announcement of our regular discount action in honor of Cyber Monday here in the basement, where it will not hurt anyone to enjoy the article above.
Source: https://habr.com/ru/post/271931/
All Articles