Meet loop fracking

The purpose of this work is to designate another cycle optimization technique. At the same time there is no task to focus on any existing architecture, but, on the contrary, we will try to act as abstract as possible, relying mainly on common sense.
The author called this technique “loops fracking” by analogy with, for example, “ loops unrolling ” or “loops nesting ”. Moreover, the term reflects the meaning and is not busy.
Cycles are the main object for optimization; it is in cycles that most programs spend most of their time. There are a sufficient number of optimization techniques, you can read them here .
')
Key resources for optimization
- Savings on the logic of the end of the cycle. Checking the end of cycle criteria leads to branching, branching “breaks the conveyor”, let's check less often. As a result, nice code samples appear, for example, Duf's device .
void send(int *to, int *from, int count) { int n = (count + 7) / 8; switch (count % 8) { case 0: do { *to = *from++; case 7: *to = *from++; case 6: *to = *from++; case 5: *to = *from++; case 4: *to = *from++; case 3: *to = *from++; case 2: *to = *from++; case 1: *to = *from++; } while (--n > 0); } }
At the moment, predictors of transitions (where they are) in processors have made this optimization ineffective. - Carrying out loop invariants for brackets ( hoisting ).
- Optimization of work with memory for more efficient operation of the memory cache. If there are references in the cycle to the amount of memory that is known to exceed the amount of cache memory, it becomes important in what order these calls go. Apart from obvious cases, it is difficult for the compiler to deal with this, sometimes another algorithm is actually written to achieve the effect. Therefore, this optimization falls on the shoulders of application programmers. A compiler / profiler can provide statistics, give hints ... feedback.
- Use of (explicit or implicit) processor parallelism. Modern processors are able to execute code in parallel.
In the case of an explicitly parallel architecture ( EPIC , VLIW ), one instruction may contain several instructions (which will be executed in parallel) affecting different functional blocks.
Superscalar processors independently parse the flow of instructions, seek out concurrency and use it whenever possible.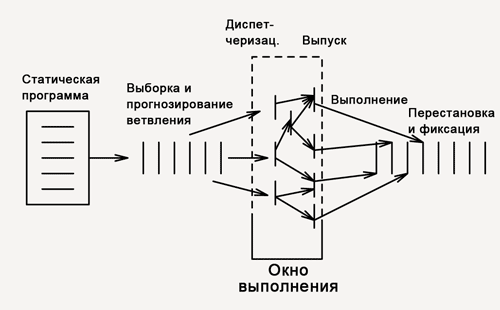
Schematic diagram of superscalar command execution
Another option is vector operations, SIMD .
Now we are just looking for a way to maximize the use of processor parallelism (s).
What we have
To begin with, let's take a look at a few simple examples, using MSVS-2013 (x64) on an Intel Core-i7 2600 processor for the experiments. By the way, GCC is able to do the same and not worse, at least with such simple examples.
The simplest loop is calculating the sum of an integer array.
int64_t data[100000]; … int64_t sum = 0; for (int64_t val : data) { sum += val; } This is what makes the compiler out of it:
lea rsi,[data] mov ebp,186A0h ;100 000 mov r14d,ebp ... xor edi,edi mov edx,edi nop dword ptr [rax+rax] ; loop_start: add rdx,qword ptr [rsi] lea rsi,[rsi+8] dec rbp jne loop_start The same, but with doubles (AVX, / fp: precise & / fp: strict - ANSI compatibility):
vxorps xmm1,xmm1,xmm1 lea rax,[data] mov ecx,186A0h nop dword ptr [rax+rax] loop_start: vaddsd xmm1,xmm1,mmword ptr [rax] lea rax,[rax+8] dec rcx jne loop_start A million times this code is executed in 85 seconds.
No work of the compiler to identify parallelism is visible here, although it would seem that it is evident in the problem. The compiler found a dependency in the data and could not bypass it.
The same, but (AVX, / fp: fast - without ANSI - compatibility):
vxorps ymm2,ymm0,ymm0 lea rax,[data] mov ecx,30D4h ; 12500, 1/8 vmovupd ymm3,ymm2 loop_start: vaddpd ymm1,ymm3,ymmword ptr [rax+20h] ; SIMD vaddpd ymm2,ymm2,ymmword ptr [rax] lea rax,[rax+40h] vmovupd ymm3,ymm1 dec rcx jne loop_start vaddpd ymm0,ymm1,ymm2 vhaddpd ymm2,ymm0,ymm0 vmovupd ymm0,ymm2 vextractf128 xmm4,ymm2,1 vaddpd xmm0,xmm4,xmm0 vzeroupper It takes 26 seconds, using vector operations.
The same cycle, but in the traditional C style:
for (i = 0; i < 100000; i ++) { sum += data[i]; } We get unexpectedly for (/ fp: precise):
vxorps xmm4,xmm4,xmm4 lea rax,[data+8h] lea rcx,[piecewise_construct+2h] vmovups xmm0,xmm4 nop word ptr [rax+rax] loop_start: vaddsd xmm0,xmm0,mmword ptr [rax-8] add rax,50h vaddsd xmm1,xmm0,mmword ptr [rax-50h] vaddsd xmm2,xmm1,mmword ptr [rax-48h] vaddsd xmm3,xmm2,mmword ptr [rax-40h] vaddsd xmm0,xmm3,mmword ptr [rax-38h] vaddsd xmm1,xmm0,mmword ptr [rax-30h] vaddsd xmm2,xmm1,mmword ptr [rax-28h] vaddsd xmm3,xmm2,mmword ptr [rax-20h] vaddsd xmm0,xmm3,mmword ptr [rax-18h] vaddsd xmm0,xmm0,mmword ptr [rax-10h] cmp rax,rcx jl loop_start There is no parallelism, just an attempt to save on maintenance cycle. This code is executed 87 seconds. For / fp: fast, the code has not changed.
Let's tell the compiler using loop nesting .
double data[100000]; … double sum = 0, sum1 = 0, sum2 = 0; for (int ix = 0; i < 100000; i+=2) { sum1 += data[i]; sum2 += data[i+1]; } sum = sum1 + sum2; We get exactly what we asked for, and the code is the same for the / fp: fast & / fp: precise options. Vaddsd operations on some processors (AMD bulldozer) can be performed in parallel.
vxorps xmm0,xmm0,xmm0 vmovups xmm1,xmm0 lea rax,[data+8h] lea rcx,[piecewise_construct+2h] nop dword ptr [rax] nop word ptr [rax+rax] loop_start: vaddsd xmm0,xmm0,mmword ptr [rax-8] vaddsd xmm1,xmm1,mmword ptr [rax] add rax,10h cmp rax,rcx jl loop_start A million times this code is executed in 43 seconds, twice as fast as the “naive and accurate” approach.
At a step of 4 elements, the code looks like this (again, the same for the / fp: fast & / fp: precise compiler options)
vxorps xmm0,xmm0,xmm0 vmovups xmm1,xmm0 vmovups xmm2,xmm0 vmovups xmm3,xmm0 lea rax,[data+8h] lea rcx,[piecewise_construct+2h] nop dword ptr [rax] loop_start: vaddsd xmm0,xmm0,mmword ptr [rax-8] vaddsd xmm1,xmm1,mmword ptr [rax] vaddsd xmm2,xmm2,mmword ptr [rax+8] vaddsd xmm3,xmm3,mmword ptr [rax+10h] add rax,20h cmp rax,rcx jl loop_start vaddsd xmm0,xmm1,xmm0 vaddsd xmm1,xmm0,xmm2 vaddsd xmm1,xmm1,xmm3 This code is executed a million times in 34 seconds. In order to guarantee vector calculations, you will have to resort to different tricks, like this:
- write pragma compiler hints: #pragma ivdep ( #pragma loop (ivdep) , # pragma GCC ivdep ), #pragma vector always, #pragma omp simd ... and hope that the compiler will not ignore them
- use intrinsic 'and - instructions to the compiler, what instructions to use, for example, the summation of two arrays might look like this :
As if all this is not very fit with the bright image of “high-level language”.
On the one hand, if necessary, to obtain a result, the indicated optimization is not at all a burden. On the other hand, the problem of portability arises. Suppose a program was written and debugged for a processor with four adders. Then, when trying to execute it on a processor version with 6 adders, we will not get the expected gain.
And on the version with three - we get a slowdown by 2 times, and not by a quarter, as we would like.
Finally, let's calculate the sum of squares (/ fp: precise):
vxorps xmm2,xmm2,xmm2 lea rax,[data+8h] ; pdata = &data[1] mov ecx,2710h ; 10 000 nop dword ptr [rax+rax] loop_start: vmovsd xmm0,qword ptr [rax-8] ; xmm0 = pdata[-1] vmulsd xmm1,xmm0,xmm0 ; xmm1 = pdata[-1] ** 2 vaddsd xmm3,xmm2,xmm1 ; xmm3 = 0 + pdata[-1] ** 2 ; sum vmovsd xmm2,qword ptr [rax] ; xmm2 = pdata[0] vmulsd xmm0,xmm2,xmm2 ; xmm0 = pdata[0] ** 2 vaddsd xmm4,xmm3,xmm0 ; xmm4 = sum + pdata[0] ** 2 ; sum vmovsd xmm1,qword ptr [rax+8] ; xmm1 = pdata[1] vmulsd xmm2,xmm1,xmm1 ; xmm2 = pdata[1] ** 2 vaddsd xmm3,xmm4,xmm2 ; xmm3 = sum + pdata[1] ** 2 ; sum vmovsd xmm0,qword ptr [rax+10h] ; ... vmulsd xmm1,xmm0,xmm0 vaddsd xmm4,xmm3,xmm1 vmovsd xmm2,qword ptr [rax+18h] vmulsd xmm0,xmm2,xmm2 vaddsd xmm3,xmm4,xmm0 vmovsd xmm1,qword ptr [rax+20h] vmulsd xmm2,xmm1,xmm1 vaddsd xmm4,xmm3,xmm2 vmovsd xmm0,qword ptr [rax+28h] vmulsd xmm1,xmm0,xmm0 vaddsd xmm3,xmm4,xmm1 vmovsd xmm2,qword ptr [rax+30h] vmulsd xmm0,xmm2,xmm2 vaddsd xmm4,xmm3,xmm0 vmovsd xmm1,qword ptr [rax+38h] vmulsd xmm2,xmm1,xmm1 vaddsd xmm3,xmm4,xmm2 vmovsd xmm0,qword ptr [rax+40h] vmulsd xmm1,xmm0,xmm0 vaddsd xmm2,xmm3,xmm1 ; xmm2 = sum; lea rax,[rax+50h] dec rcx jne loop_start The compiler again cuts the cycle into pieces of 10 elements in order to save on the logic of the cycle, while it costs 5 registers - one for the sum and a pair for each of the two parallel branches of multiplications.
Or like this for / fp: fast:
vxorps ymm4,ymm0,ymm0 lea rax,[data] mov ecx,30D4h ;12500 1/8 loop_start: vmovupd ymm0,ymmword ptr [rax] lea rax,[rax+40h] vmulpd ymm2,ymm0,ymm0 ; SIMD vmovupd ymm0,ymmword ptr [rax-20h] vaddpd ymm4,ymm2,ymm4 vmulpd ymm2,ymm0,ymm0 vaddpd ymm3,ymm2,ymm5 vmovupd ymm5,ymm3 dec rcx jne loop_start vaddpd ymm0,ymm3,ymm4 vhaddpd ymm2,ymm0,ymm0 vmovupd ymm0,ymm2 vextractf128 xmm4,ymm2,1 vaddpd xmm0,xmm4,xmm0 vzeroupper Summary table:
| MSVC, / fp: strict, / fp: precise, sec | MSVC, / fp: fast, sec | |
| foreach | 85 | 26 |
| C style cycle | 87 | 26 |
| C style nesting X2 | 43 | 43 |
| C style nesting X4 | 34 | 34 |
How to explain these numbers?
It is worth noting that only the developers of the processor know the true picture of what is happening, we can only make guesses.
The first thought that the acceleration takes place at the expense of several independent adders seems to be wrong. The i7-2600 processor has one vector adder that cannot perform independent scalar operations.
Processor clock frequency - up to 3.8 GHz. 85 sec of a simple cycle gives us (a million times 100,000 additions) ~ 3 clocks per iteration. This is in good agreement with the data ( 1 , 2 ) about 3 cycles for the execution of the vector instruction vaddpd (even if we add scalars). Since there is a data dependency, it is impossible to perform an iteration faster than 3 cycles.
In the case of nesting (X2) there is no dependence on the data inside the iteration and it is possible to load the adder's conveyor with a difference in time. But in the next iteration, data dependencies also arise with a difference in tact, as a result, we have an acceleration of 2 times.
In the case of nesting (X4), the adder's conveyor is also loaded in increments of time, but acceleration 3 times (due to the length of the conveyor) does not occur, an additional factor interferes. For example, the loop iteration no longer fits in the L0m cache line and gets the penalty time (s).
So:
- With the compilation model / fp: fast, the simplest source code gives the fastest version of the code, which is logical because we are dealing with high level language.
- manual optimizations in the spirit of nesting give a good result for the model / fp: precise, but only hinder the compiler when using / fp: fast
- manual optimizations are more portable than vectorized code
A little bit about compilers
Register architectures provide a simple and versatile way to get acceptable code from portable text in high-level languages. Compilation can be divided into several steps:
- Syntax analysis. At this stage, a syntactically controlled translation is performed, static checks are performed. At the output, we have a tree ( DAG ) parsing.
- Generate intermediate code. If desired, the generation of intermediate code can be combined with the syntax analysis.
Moreover, when using three-address instructions as an intermediate code, this step becomes trivial because "the three-address code is a linearized representation of a syntax tree or a dag, in which explicit names correspond to the internal nodes of the graph ".
In essence, the three-address code is intended for a virtual processor with an infinite number of registers. - Code generation The result of this step is a program for the target architecture. Since the real number of registers is limited and small, at this stage we must determine which temporary variables will be in the registers at each moment, and distribute them to specific registers. Even in its pure form, this task is NP-complete; in addition, the matter is complicated by the fact that there are usually various restrictions on the use of registers. However, acceptable heuristics have been developed to solve this problem. In addition, the three-address (or its equivalents) code gives us a formal apparatus for analyzing data flows, optimizing, removing useless code, ...
Problems appear:
- To solve the NP-complete register allocation problem, heuristics are used and this gives an acceptable quality code. These heuristics do not like additional restrictions on the use of memory or registers. For example, split (interlaced) memory, implicit use of registers by instructions, vector operations, register rings ... They do not like the fact that heuristics can stop working and building close to optimal code ceases to be a problem solved in a universal way.
As a result, the (vector?) Capabilities of the processor can only be used when the compiler has recognized a typical situation from the set that it has been taught. - Scaling problem. The allocation of registers is done statically, if we try to execute the compiled code on a processor with the same instruction set, but with a large number of registers, there will be no gain.
This also applies to SPARC with its register window stack, for which a greater number of registers leads only to the fact that a larger number of call frames fit into the register pool, which reduces the frequency of memory accesses.
EPIC - an attempt was made in the direction of scaling - “Each group of several instructions is called a bundle. Each bundle may have a stop bit, indicating that the next group depends on the results of the work of this. Such a bit allows you to create future generations of architecture with the ability to run multiple bundles in parallel. Dependency information is computed by the compiler, and therefore the hardware will not have to perform additional verification of the operand independence. ”It was assumed that independent bundles can be executed in parallel, and the more executing devices in the system, the more extensive the internal program parallelism can be used. On the other hand, such features do not always give a gain, in any case, for the summation of the array, this seems to the author to be useless.
Superscalar processors solve a problem by introducing “registers for us” and “registers in themselves”. The compiler focuses on the number of the first ones when it writes (allocates) registers. The number of the second can be any, usually several times more than the first. In the decoding process, the superscalar processor re-paints the registers based on their actual number within the window in the program body. The window size is determined by the complexity of the logic that the processor can afford. In addition to the number of registers, of course, functional devices are subject to scaling. - Compatibility issue. Of particular note are the X84-64 and the technology line - SSE - SSE2 - SSE3 - SSSE3 - SSE4 - AVX - AVX2 - AVX512 - ...
Compatibility from top to bottom (i.e., the code is compiled for older technology, and I want to execute on lower processors) can be provided in one way - by generating code for each mentioned technology and choosing the right branch for execution in runtime. It does not sound very attractive.
Bottom-up compatibility is provided by the processor. This compatibility ensures that the code is executable, but does not promise its effective execution. For example, if the code is compiled for technology with two independent adders, and is executed on a processor with 4, only two of them will actually be used. Generating several branches of code for different technologies does not solve the problems of future technologies, planned or not.
A look at the cycles
Consider the same task, the summation of the array. Imagine this summation as the calculation of a single expression. Since we use binary addition, the expression can be represented as a binary tree, and due to the associativity of summation, there are many such trees.
The calculation is performed when going around the tree to the left from the left to the right. Normal summation looks like a left-growing tree degenerate to the list:
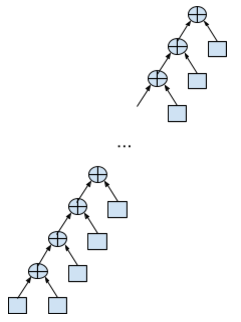
double data[N]; … double sum = 0; for (int i = 0; i < N; i++) { sum += data[i]; } The maximum stack depth (bypassing depth implies postfix summation, i.e. a stack), which can be required here - 2 elements. No parallelism is assumed; each summation (except the first) should wait for the results of the previous summation, i.e. There is a dependency on the data.
But we need only 3 registers (the sum and two for the emulation of the top of the stack) to sum up an array of any size.
Nesting cycle in two streams looks like this:
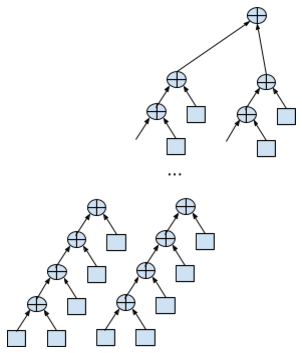
double data[N]; … double sum = 0; double sum1 = 0, sum2 = 0; for (int i = 0; i < N/2; i+=2) { sum1 += data[i]; sum2 += data[i + 1]; } sum = sum1 + sum2; For calculations, you need twice as many resources, 5 registers for everything, but now part of the summations can be done in parallel.
From the computational point of view, the most terrible option is a right-growing tree degenerate to the list, for its calculation an array-size stack is needed in the absence of parallelism.
Which version of the tree will give maximum parallelism? Obviously, a balanced (within the limits of the possible) tree, where the source data can only be accessed in leaf summing nodes.
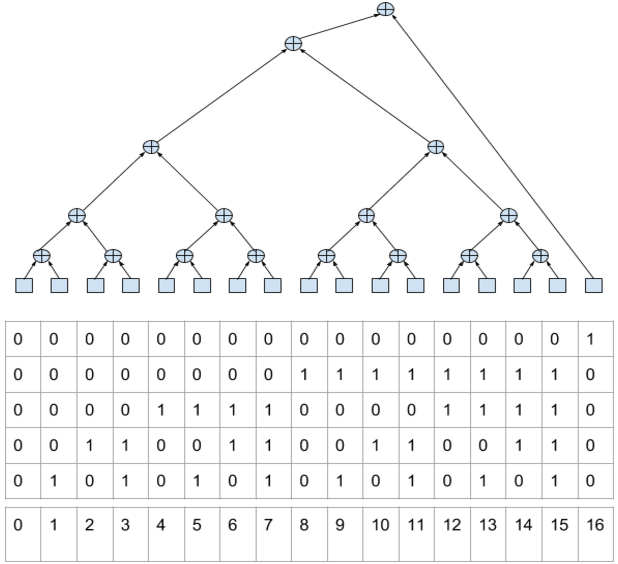
// : double data[N]; for (unsigned ix = 0; ix < N; ix++) { unsigned lix = ix; push(data[ix]); while (lix & 1) { popadd(); lix >>= 1; } } for (unsigned ix = 1; ix < bit_count(N+1); ix++) { popadd(); } This pseudo-code uses the following functions:
- push (val) - pushes the value to the top of the stack, increases the stack. It is assumed that the stack is organized in a register pool.
- popadd () - summarizes the two items at the top of the stack, puts the result in the second one from the top, and deletes the top item.
- bit_count (val) - counts the number of bits in an integer value
How it works? Note that the number of the element in the binary representation encodes the path to it from the top of the expression tree (from the high-order bits to the low-order ones). At the same time 0 means movement to the left, 1 - to the right (similar to the Huffman code ).
Note that the number of continuously running low bits is equal to the number of summations that must be done to process the current element. And the total number of coded bits in the number means the number of items in the stack at the time before working with this item.
What you should pay attention to:
- Stack size ie The required number of registers for it is log2 of the size of the data. On the one hand, this is not very convenient. the size of the data can be calculated, and the size of the stack would be desirable to determine when compiling. On the other hand, no one prevents the compiler from cutting data into tiles, the size of which is determined based on the number of available registers.
- Such an interpretation of the problem is sufficient parallelism to automatically use any number of available independent adders. Loading elements from an array can be done independently and in parallel. Summations of the same level are also performed in parallel.
- There are problems with concurrency. Suppose that at the time of compilation we had N adders. In order to work effectively with a number other than N (for which purpose everything was started), you will have to use hardware support.
- for architectures with explicit parallelism, everything is not easy. It would help the pool of adders and the resolution to execute in parallel several independent “wide” instructions. For summation, not the specific adder is taken, but the first one in the queue. If a wide instruction attempts to perform three summations, three adders will be demanded from the pool. If there is no such number of free adders, the instruction will be blocked until their release.
- superscalar architectures require you to monitor stack status. There are unary (ex: sign changes) and binary operations (Ex: popadd) with a stack. As well as leaf operations without dependencies (Ex: push). With the latter the easiest way, they can be put on execution at any time. But if the operation has an argument (s), it must wait for the readiness of its arguments before executing.
So, both values for the popadd operation should be at the top of the stack. But by the time the turn to sum them up approaches, they may not be at the top of the stack at all. It may happen that they are physically located and not in a row.
The output will be placement (allocation) of the corresponding register from the stack pool at the moment of setting the instruction for execution and not at the moment when the result is ready and must be placed.
push(data[i]) , . . .
popadd , , . , popadd , .
.
. / . .
- ANSI - double' . /fp:fast, . , ( ) , .
- , ? , . , , 64 . 2 64 — . , .
lea rax,[data] vxorps xmm6,xmm6,xmm6 ; 0 vaddsd xmm0,xmm6,mmword ptr [rax] ; 0 vaddsd xmm1,xmm0,mmword ptr [rax+8] ; 1 vaddsd xmm0,xmm6,mmword ptr [rax+10h] ; 1 0 vaddsd xmm2,xmm0,mmword ptr [rax+18h] ; 1 2 vaddsd xmm0,xmm1,xmm2 ; 0 vaddsd xmm1,xmm6,mmword ptr [rax+20h] ; 0 1 vaddsd xmm2,xmm1,mmword ptr [rax+28h] ; 0 2 vaddsd xmm1,xmm6,mmword ptr [rax+30h] ; 0 2 1 vaddsd xmm3,xmm1,mmword ptr [rax+38h] ; 0 2 3 vaddsd xmm1,xmm2,xmm3 ; 0 1 vaddsd xmm0,xmm0,xmm1 ; 0 vaddsd xmm1,xmm6,mmword ptr [rax+40h] ; 0 1 vaddsd xmm2,xmm1,mmword ptr [rax+48] ; 0 2 vaddsd xmm1,xmm6,mmword ptr [rax+50h] ; 0 2 1 vaddsd xmm3,xmm1,mmword ptr [rax+58h] ; 0 2 3 vaddsd xmm1,xmm2,xmm3 ; 0 1 vaddsd xmm2,xmm6,mmword ptr [rax+60h] ; 0 1 2 vaddsd xmm3,xmm2,mmword ptr [rax+68h] ; 0 1 3 vaddsd xmm2,xmm6,mmword ptr [rax+70h] ; 0 1 3 2 vaddsd xmm4,xmm2,mmword ptr [rax+78h] ; 0 1 3 4 vaddsd xmm2,xmm4,xmm3 ; 0 1 2 vaddsd xmm3,xmm1,xmm2 ; 0 3 vaddsd xmm1,xmm0,xmm3 ; 1
16 - .
What's next?
— . - .
- . , , .
- . , .
- . .
- . AB - A - B.
- , . .
- 22, , 7 8. , (< 32 ...128), .
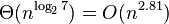 .
. - The best result is achieved -
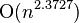 and it is also recursive. However, this is a purely theoretical result without prospects for real use.
and it is also recursive. However, this is a purely theoretical result without prospects for real use.
- , . .
- Naive convolution .
for (int i = 0; i < N; i++) { for (int j = 0; j < M; j++) { result[i + j] += x[i] * h[M - 1 - j]; } }
We are able to work with the internal cycle, it is better to do general optimization through the DFT. - DFT . In the naive form is not used. The FFT algorithm is again based on recursion. For example, the data-flow diagram for the popular Cooley-Tukey algorithm (Cooley – Tukey) with base 2 looks like this (16-point):
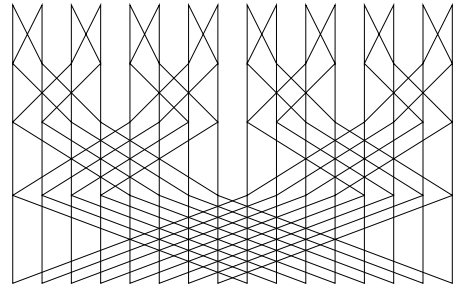
Here there is enough natural parallelism to resort to special efforts.
The last example is quite indicative. In order to optimize, recursion is usually translated into iteration, with the result that a typical text (main loop) looks like this:
nn = N >> 1; ie = N; for (n=1; n<=LogN; n++) { rw = Rcoef[LogN - n]; iw = Icoef[LogN - n]; if(Ft_Flag == FT_INVERSE) iw = -iw; in = ie >> 1; ru = 1.0; iu = 0.0; for (j=0; j<in; j++) { for (i=j; i<N; i+=ie) { io = i + in; rtp = Rdat[i] + Rdat[io]; itp = Idat[i] + Idat[io]; rtq = Rdat[i] - Rdat[io]; itq = Idat[i] - Idat[io]; Rdat[io] = rtq * ru - itq * iu; Idat[io] = itq * ru + rtq * iu; Rdat[i] = rtp; Idat[i] = itp; } sr = ru; ru = ru * rw - iu * iw; iu = iu * rw + sr * iw; } ie >>= 1; } What can be done in this case? , , . , . , .
PS: (Felid) SIMD .
PPS: King Crimson — Fracture — Live in Boston 1974.
Source: https://habr.com/ru/post/271905/
All Articles