Network monitoring: how we make sure that large companies have all the nodes

By the appearance of this optics going through the forest to the collector, we can conclude that the installer did not follow the technology a little. The mount on the photo also suggests that he is probably a sailor - a marine knot.
I'm from the team ensuring the physical performance of the network, simply speaking - technical support, responsible for ensuring that the lights on the routers blink as it should. We have “under the wing” various large companies with infrastructure throughout the country. We do not climb inside their business, our task is for the network to work at the physical level and the traffic to go as it should.
The general meaning of the work is constant polling of nodes, removal of telemetry, test runs (for example, checking settings for finding vulnerabilities), ensuring operability, monitoring applications, and traffic. Sometimes inventory and other perversions.
')
I'll tell you about how it is organized and a couple of stories from trips.
As it usually happens
Our team sits in an office in Moscow and shoots network telemetry. Actually, these are constant pings of nodes, as well as obtaining monitoring data if the hardware is smart. The most common situation - ping fails several times in a row. In 80% of cases for a retail network, for example, this turns out to be a power outage, therefore, seeing such a picture, we do the following:
- First we call the provider for accidents
- Then - to the power plant about the shutdown
- Then we try to contact someone at the facility (this is not always possible, for example, at 2 nights)
- And finally, if in 5-10 minutes the above did not help, we leave ourselves or send an “avatar” - a contract engineer sitting somewhere in Izhevsk or Vladivostok, if the problem is there.
- We keep constant communication with the “avatar” and “lead” it over the infrastructure - we have sensors and service manuals, he has pliers.
- Then the engineer sends us a report with a photo about what it was.
Dialogues are sometimes:
- So, the connection disappears between buildings 4 and 5. Check the router in the fifth.
- Order included. There is no connection.
- Ok, go through the cable to the fourth building, there is still a node.
- ... Oppa!
- What happened?
- Here the 4th house was demolished.
- What??
- I attach a photo to the report. I can not restore the house in SLA.

But more often it turns out to find a break and restore the channel.
Approximately 60% of trips are “into the milk”, because either the food has been killed (by a shovel, foreman, intruders), or the provider does not know about their failure, or the short-term problem is eliminated before the installer arrives. However, there are situations when we find out about the problem before the users and before the IT services of the customer, and report the decision before they even realize that something has happened. Most often, such situations occur at night when activity in customer companies is low.
Who needs it and why?
As a rule, any large company has its own IT-department, which clearly understands the specifics and objectives. In medium and large businesses, the work of enikeev and network engineers is often outsourced. It is simply beneficial and convenient. For example, one retailer has its very cool IT people, but they are far from replacing routers and tracing cable.
What are we doing
- We work on appeals - tickets and panic calls.
- We do prevention.
- We follow recommendations of vendors of iron, for example, on terms of THAT.
- We connect to the customer's monitoring and remove data from it in order to leave for incidents.
With monitoring, the story often lies in the fact that it does not exist. Or he was raised 5 years ago and not very relevant. In the simplest case, if there is really no monitoring, we offer the customer a simple, open-source Russian Zabbix for free - and he is well and easier for us.
The first method - simple checks - is just a machine that pings all nodes on the network and ensures that they respond correctly. Such an implementation does not require any changes or minimal cosmetic changes in the customer’s network at all. As a rule, in a very simple case, we put Zabbiks directly into one of the data centers (since we have two of them in the office of CROC on Volochayevskaya). In more complex, for example, if you use your own secure network - to one of the machines in the customer data center:
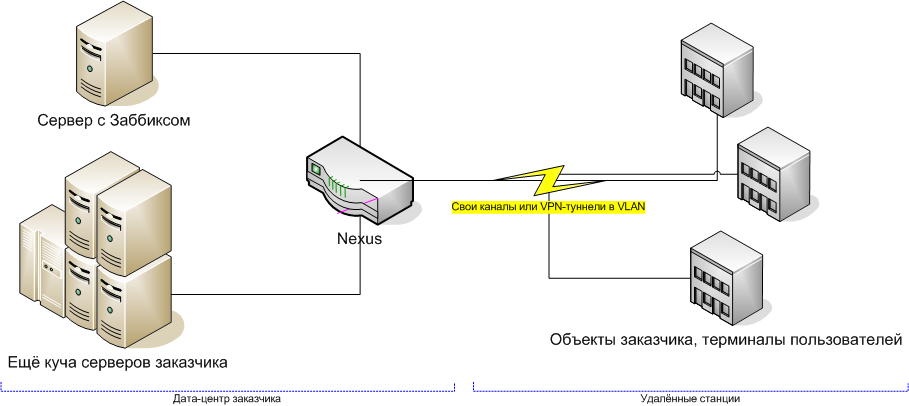
Zabbiks can be used and more difficult, for example, it has agents that are installed on * nix and win-nodes and show system monitoring, as well as external check mode (with SNMP support). However, if a business needs something like this, then either they already have their monitoring, or a more functional solution is chosen. Of course, this is no longer open source software, and it costs money, but even a banal, accurate inventory of approximately one-third discourages costs.
This we also do, but this is the story of colleagues. Here they sent a couple of screenshots to Infoshima:


I’m an avatar operator, so I’ll tell you more about my work.
What does a typical incident look like
Before us are screens with the following general status:
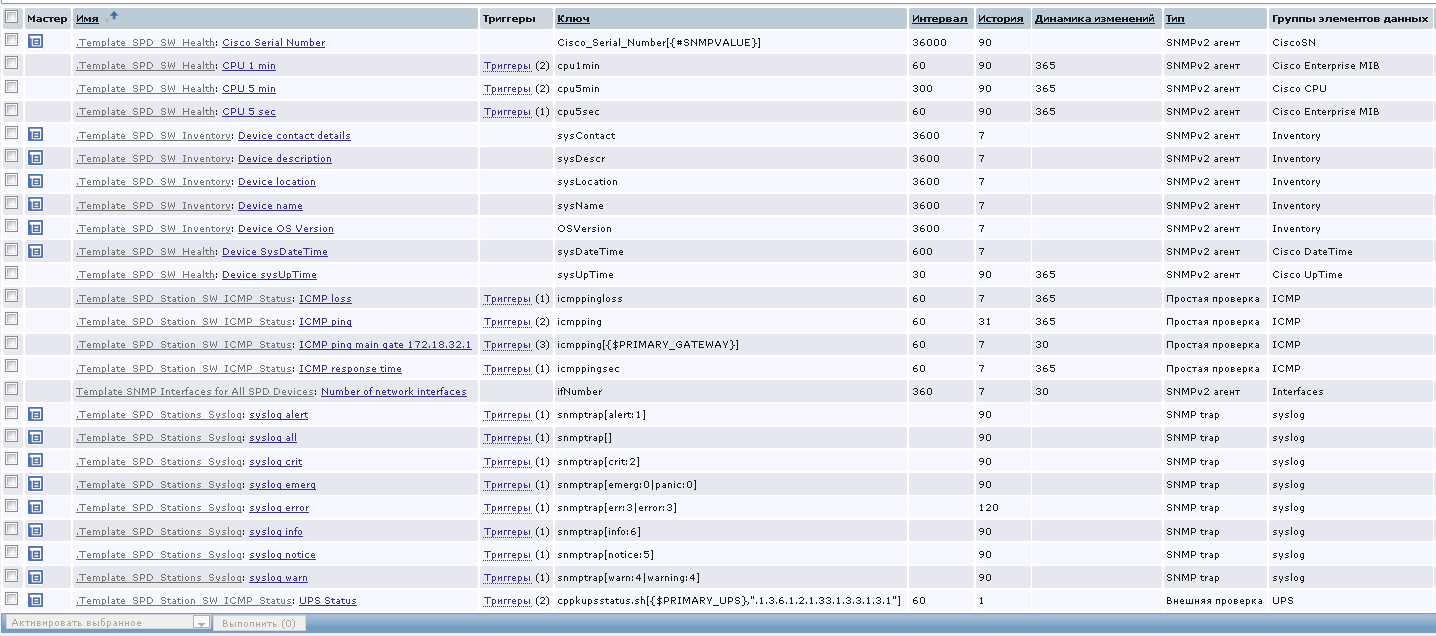
At this site, Zabbix collects quite a lot of information for us: party number, serial number, CPU load, device description, interface availability, etc. All necessary information is available from this interface.
An ordinary incident usually begins with the fall of one of the channels leading to, for example, the customer’s store (which has 200-300 pieces in the country). Retail is now prosharennaya, not like seven years ago, so the cashier will continue to work - two channels.
We take the phones and make at least three calls: to the provider, power stations and people on the spot (“Yes, we loaded the armature, someone's cable was touched ... And, yours? Well, well, we found it”).
As a rule, without monitoring, before the escalation, hours or days would pass — the same backup channels are not always checked. We know right away and leave right away. If there is additional information besides ping (for example, a model of a buggy piece of iron), we immediately complete the field engineer with the necessary parts. Further already in place.
The second most frequent call is a failure of one of the terminals of users, for example, a DECT phone or a Wi-Fi router, which distributed a network to an office. Here we learn about the problem from monitoring and almost immediately get a call with details. Sometimes a call doesn’t add anything (“I take a pipe, doesn’t ring something”), sometimes it’s very useful (“We dropped it from the table”). It is clear that in the second case it is clearly not a line break.
Equipment in Moscow is taken from our hot standby warehouses, we have several of these types:

Customers usually have their stocks of frequently failing components — office tubes, power supplies, fans, and so on. If you need to deliver something that is not in place, not to Moscow, we usually go by ourselves (because the installation). For example, I had a night trip to Nizhny Tagil.
If the customer has his own monitoring, they can upload the data to us. Sometimes we deploy Zabbiks in survey mode, just to provide transparency and control of the SLA (this is also free for the customer). We do not install additional sensors (this is done by colleagues who ensure the continuity of production processes), but we can connect to them if the protocols are not exotic.
In general, we do not touch the customer’s infrastructure, we just support it as it is.
From experience, I will say that the last ten customers have switched to external support due to the fact that we are very predictable in terms of costs. Accurate budgeting, good case management, report on each application, SLA, equipment reports, prevention. Ideally, of course, we are for CIO customers like cleaners - we come and do, everything is clean, we do not distract.
Another thing worth noting is that in some large companies, inventory becomes a real problem, and we are sometimes attracted to it purely. Plus, we also do the storage of configurations and their management, which is convenient at different level-reconnections. But, again, in difficult cases, this is also not me - we have a special team that transports data centers.
And one more important point: our department does not deal with critical infrastructure. Everything inside the data center and all banking-insurance-carrier, plus retail core systems - this is the X-team. Here are these guys.
More practice
Many modern devices are able to give a lot of service information. For example, network printers can easily monitor the level of toner in the cartridge. You can expect in advance for the replacement period, plus have a notification of 5-10% (if the office suddenly started typing wildly in a non-standard schedule) - and immediately send enikey before the panic starts to panic.
Very often, annual statistics are collected from us, which is done by the same monitoring system plus we. In the case of Zabbiks, this is a simple cost planning and understanding what happened, and in the case of Infosim it is also material for calculating the scaling for a year, loading admins and all sorts of other things. In statistics, there is energy consumption - in the last year, almost everyone began to ask him, apparently, to scatter internal costs between departments.
Sometimes you get real heroic rescue. Such situations are very rare, but from what I remember this year, we saw a temperature rise of up to 55 degrees on the tsiskokomutator about 3 nights. In a distant server room there were "stupid" air conditioners without monitoring, and they went out of order. We immediately called a cooling engineer (not ours) and called the customer’s administrator on duty. He put out some of the non-critical services and kept the server from thermal shotdown until the arrival of the guy with mobile air conditioning, and then the staff fixes.
Polikomov and other expensive video conferencing equipment very well monitor the degree of battery charge before conferences, is also important.
Monitoring and diagnostics are needed by all. As a rule, it is long and difficult to implement without the experience itself: the systems are either extremely simple and pre-configured, or with an aircraft carrier of size and with a bunch of sample reports. Sharpening a file for a company, inventing the implementation of their tasks in an internal IT department and displaying the information that they need most, plus keeping the entire story up to date - a rake, if there is no implementation experience. Working with monitoring systems, we choose the middle ground between free and top solutions - as a rule, not the most popular and “fat” vendors, but clearly solving the problem.
One time there was enough atypical treatment . The customer needed to give the router to some separate division, and exactly according to the inventory. In the router there was a module with the specified serial. When the router began to prepare for the road, it turned out that this module is not there. And no one can find it. The problem is slightly aggravated by the fact that the engineer who last year worked with this branch was already retired and went to his grandchildren in another city. Contacted us, asked to search. Fortunately, the iron gave reports on serials, and Infosim did an inventory, so we found this module in a couple of minutes in the infrastructure, described the topology. The fugitive was tracked down by cable - he was in another server room in the closet. The history of the move showed that he got there after the failure of a similar module.

Shot from the film about Hottabych, accurately describing the attitude of the population to the cameras
Many camera incidents. Once 3 cameras failed. Cable breakage at one of the sites. The installer blew out a new one in the corrugation, two of the three cameras after a number of shamanism rose. And the third is not. Moreover, it is not clear where it is at all. I raise the video stream - the last frames right before the fall - 4 in the morning, three men in scarves on their faces come up, something bright below, the camera is shaking and falling.
Once set up the camera, which should focus on the "hares", climbing through the fence. While we were driving, we thought how we would designate the point where the violator should appear. Not useful - in the 15 minutes that we were there, 30 people penetrated the object only at the point we needed. Straight tuning table.
As I have already cited the example above, the story of a demolished building is not a joke. Once the link to the equipment disappeared. At the site - there is no pavilion where the copper was held. The pavilion was torn down, the cable was gone. We saw that the router was dead. The assembler arrived, begins to look - and there is a couple of kilometers between the nodes. He has a Vipnet tester in his set, a standard — he rang from one connector, he rang from another — went to look. Usually the problem is immediately obvious.

Cable tracing: this is the optics in the corrugation, the continuation of the story from the very top of the post about the marine knot. Here, as a result, apart from a completely surprising installation, the problem was revealed that the cable had moved away from the fixings. Here all who feel like it are climbing, and metal structures are being loosened. About a representative of the proletariat of about five thousand had torn the optics.
At one site, about once a week, all nodes were disconnected. And at the same time. We have been looking for a pattern for quite a while. The installer found the following:
- The problem always happens in the change of the same person.
- It differs from others in that it wears a very heavy coat.
- For the clothes hanger mounted automatic.
- Someone took the lid of the machine for a very long time, even in prehistoric times.
- When this friend comes to an object, he hangs up his clothes, and she turns off the machines.
- He immediately includes them back.
At one facility at the same time, the equipment was turned off at night. It turned out that local craftsmen had connected to our power supply, brought out an extension cord and stuck a kettle and a hot plate there. When these devices work at the same time - knocks out the entire pavilion.
In one of the shops of our vast country, the entire network was falling all the time with the closure of the shift. The installer saw that all the power is on the lighting line. As soon as the store turns off the overhead lighting of the hall (which consumes a lot of energy), all network equipment also turns off.
There was a case that the janitor with a shovel cut the cable.
Often we see just copper, lying with a ripped corrugation. Once between the two workshops, local craftsmen simply threw a twisted pair without any protection.
Away from civilization, employees often complain that they are irradiated by "our" equipment. Switches on some distant objects can be in the same room as the attendant. Accordingly, we had a couple of times mischievous grandmas, who by hook or by crook turned them off at the beginning of the shift.
In another distant city, a mop was hung up on optics . They otkolupali corrugation from the wall, began to use it as hardware for the equipment.

In this case, the food is clearly a problem.
What can "big" monitoring
I’ll also talk briefly about the possibilities of more serious systems, using the example of Infosim installations. There are 4 solutions combined into one platform:
- Fault management - control of failures and event correlation.
- Performance Management.
- Inventory and automatic topology detection.
- Configuration management.
What is important, Infosim supports at once a bunch of equipment “out of the box”, that is, it can easily sort out all their internal exchange and get access to all their technical data. Here is a list of vendors: Cisco Systems, Huawei, HP, AVAYA, Redback Networks, F5 Networks, Extreme Networks, Juniper, Alcatel-Lucent, Fujitsu Technology Solutions, ZyXEL, 3Com, Ericsson, ZTE, ADVA Optical Networking, Nortel Networks, Nokia Siemens Networks , Allied Telesis, RADCOM, Allot Communications, Enterasys Networks, Telco Systems, etc.
Separately, about the inventory. The module does not just show the list, but also builds the topology itself (at least in 95% of cases it tries and hits correctly). It also allows you to have on hand an up-to-date base of used and idle IT equipment (network, server equipment, etc.), and to replace outdated equipment (EOS / EOL) in time. In general, it is convenient for big business, but in small things a lot of it is done by hand.
Report examples:
- Reports broken down by OS type, firmware, models and equipment manufacturers;
- Report on the number of free ports on each switch in the network / by selected manufacturer / by model / by subnet, etc .;
- Report on newly added devices for a specified period;
- Notice of low toner in printers;
- Evaluation of the suitability of the communication channel for traffic sensitive to delays and losses, active and passive methods;
- Monitoring the quality and availability of communication channels (SLA) - generation of reports on the quality of communication channels with a breakdown by telecom operators;
- Control of failures and event correlation functionality is implemented through the Root-Cause Analysis mechanism (without the need for the administrator to write rules) and the Alarm States Machine mechanism. Root-Cause Analysis is an analysis of the root cause of an accident based on the following procedures: 1. automatic detection and localization of the fault location; 2. reducing the number of emergency events to one key; 3. identifying the consequences of failure — who and what was affected by the failure.
You can also put on the network such things that are immediately integrated into the monitoring:

Stablenet - Embedded Agent (SNEA) - a computer the size of a little more than a pack of cigarettes.
Installation is performed in ATMs, or in dedicated network segments where availability is required. With their help load tests are performed.
Cloud monitoring
Another installation model is SaaS in the cloud. They did it for one global customer (a company with a continuous production cycle with a geography of distribution from Europe to Siberia).
Dozens of objects, including factories and warehouses of finished products. If their channels fell and their support came from foreign offices, then shipping delays started, which led to losses further. All work was done on request and spent a lot of time on investigating the incident.
We set up monitoring specifically for them, then drank it on a number of sites according to the features of their routing and hardware. This was all done in the CRIC cloud. We made and passed the project very quickly.
The result is:
- Due to the partial transfer of control of the network infrastructure, it was possible to optimize at least 50%. Equipment unavailability, channel loading, exceeding the parameters recommended by the manufacturer: all this is fixed for 5-10 minutes, diagnosed and eliminated within an hour.
- When receiving a service from the cloud, the customer translates the capital expenditures on the deployment of its network monitoring system into operational costs of the subscription fee for our service, which you can opt out at any time.
The advantage of the cloud is that in our decision we stand as if above their network and we can look at everything that happens more objectively. At that time, if we were inside the network, we would only see the picture before the node of failure, and what happens behind it would not be known.
A couple of pictures last
This is the “morning puzzle”:

And we found this treasure:

In the chest was this:

And finally, about the most fun departure. I once went to a retail facility.
The following happened there: first, it began to drip from the roof onto the false ceiling. Then a lake formed in the false ceiling, which washed away and pressed through one of the tiles. As a result, all of this rushed to the electrics. Then I don’t know exactly what exactly happened, but somewhere in the next room, the fire went off and the fire started. First, powder fire extinguishers worked, and then firefighters arrived and filled everything with foam. I arrived after them for disassembly. I must say that the tsiska 2960 got the grip after all this - I was able to pick up the config and send the device for repair.
One more time during the drawdown of the powder system, the tsiskovsky 3745 in one can was almost completely filled with powder. All interfaces were plugged - 2 to 48 ports. It was necessary to turn on the spot. They remembered the last case, decided to try to remove the configs "for hot", shook them out, cleaned them as best they could. They turned on the device - at first the device said “pff” and sneezed at us with a large jet of powder. And then purred and rose.
Source: https://habr.com/ru/post/271823/
All Articles