An example of express analysis of the performance of storage using the free service Mitrend

The study of performance problems and the search for solutions are familiar to many firsthand. There are a large number of tools for visualizing and parsing I / O statistics. At present, automation of intellectual analysis based on Internet services is gaining momentum.
In this post I want to share an example of analyzing the performance problem of storage systems based on one of these services (Mitrend) and offer ways to solve it. In my opinion, this example is an interesting study that I think can be useful for a wide range of IT readers.
')
So, the customer asked EMC to see the performance of the VNX5500 hybrid storage system deployed in its SAN. VMware servers are connected to the storage system, on which "everything is altogether": from infrastructure tasks to file balls and database servers. The reason for carrying out this rapid assessment was complaints about the suspension of applications deployed on servers connected to VNX.
For preprocessing, I used the freely available Mitrend service.
A detailed description of this service is not included in the objectives of this post, so I invite everyone to learn more about it - go to its website and see for yourself.
Mitrend receives input files with input / output statistics from the system under study and prepares graphs for the most frequently requested parameters, as well as makes preliminary analytics, the results of which will be used later.

One example of such analytics is a heat map showing how much the various components of the system are loaded at different points in time. In fact, this is a schematic depiction of the system and its components, within each of which a schedule of its loading is built. A general view of it allows you to see potentially problematic places. In this case, it is clear that the cache is a write cache. Here is the chart:

Record cache utilization is at a high level, from which regular “shooting” into the red zone (above 90%) occurs.
This is a typical symptom of performance problems. A kind of "high temperature". In this case, we have to study what exactly leads to such a situation and outline ways to solve it.
Disks, processors, I / O ports, disk bus are not loaded. And this is a bit strange, amid the fact that the write cache is “crammed”.



Let's now take a look at the disks in more detail. For clarity, I circled various-colored discs with different lines and signed a legend from below. In the file with the analysis it can be seen without a legend.
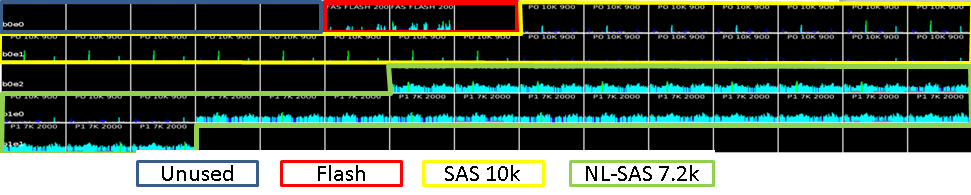
Let's take a closer look at what the disk system in question is all about: three 200GB flash drives, two of which are configured in FAST Cache with a usable volume of 183GB, and the third is in hot spare. Those. very robust, mirrored hot-flash flash memory. The effectiveness of its work can be seen in the graph below:

The system has 5 900 GB disks that are not used at all. Since these are system disks, they try not to touch them out of habit, because there is an opinion that this causes performance problems. My opinion on this is that they can be used if it is done in a meaningful way. Performance problems are usually for completely different reasons.
Usually, disks of different types are combined into hybrid pools, so that the system itself determines where it is better to place the data (using FAST VP). But in this case, the implementation specialists did not trust her with this responsible business and rigidly divided the data by disk type. Therefore, the disks are divided into 2 separate groups - Pool 0 and Pool 1. They did this in order to isolate them from the point of view of performance, so that non-critical applications would not affect those that need speed.
Pool 0 (RAID5) is designed for critical application servers and consists of SAS 10k disks.
Pool 1 (RAID6) - this is a custom "balls" and any kind of performance-friendly environment. It consists of NL SAS 7.2k disks.
Examining the disk group summary shows that FAST Cache is disabled on the Pool 1 group.

The conversation with the customer made it clear that this was done in order to increase the priority of resources for the performance-critical Pool 0.
It is interesting to note that despite this, complaints come precisely from applications using Pool 0, whose disks are almost not loaded. Moreover, 80% of all read operations and 91% of all write operations of this pool are serviced by FAST Cache.

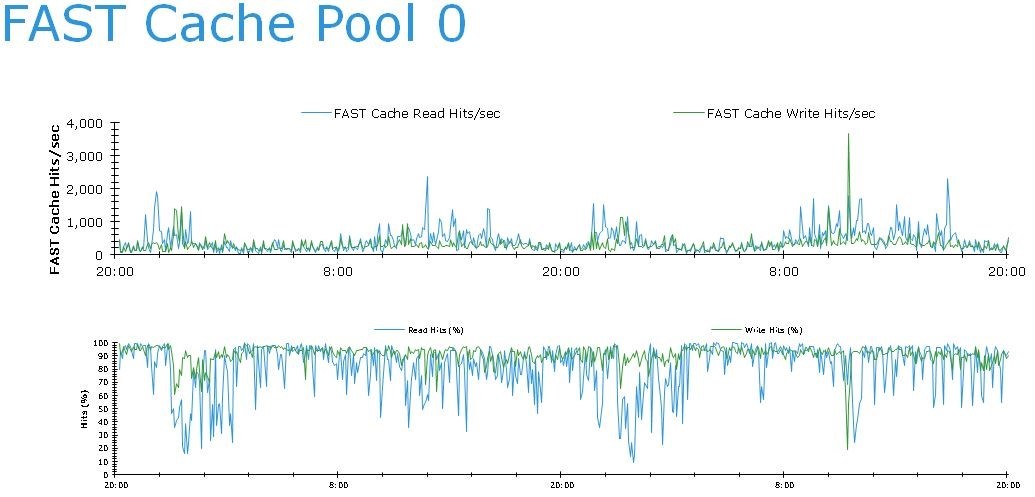
That is, despite the amazing efficiency of FAST Cache, applications are experiencing problems. Why? To go further, let's look at the LUNs and load distribution.
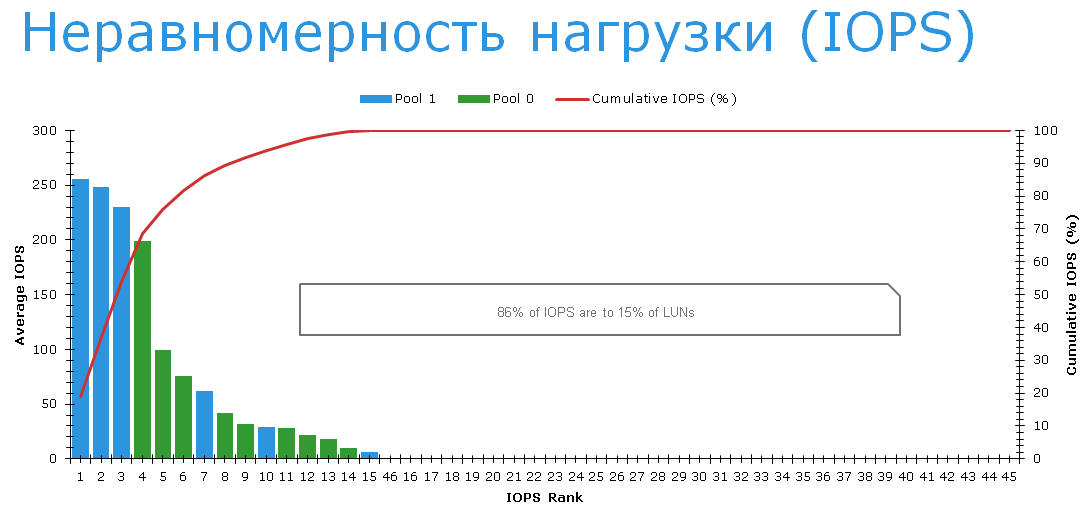
It turns out that the three most heavily loaded LUNs are located exactly on slow NL-SAS disks in RAID6. There are no complaints about them. A conversation with users showed that they were extremely pleased with how quickly their file servers began to work after switching to VNX.
There are complaints about LUNs on Pool 0 (green on the chart above). Specifically, this is LUN with numbers 0 through 8, which are listed in the table below.

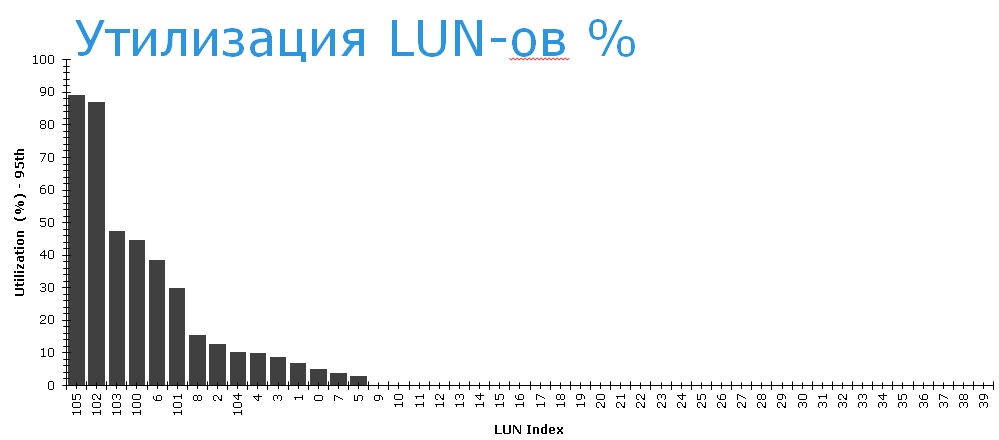
If you now look at the degree of utilization of LUNs, then it can be seen that the LUNs from Pool 0 are recycled rather poorly. The chart below shows the LUN numbers horizontally, so it's easy to identify which LUNs are “ours”. The most "loaded" of them busy working only 40%.
The system works "on average well." The average response time of volumes within 10 ms. This is the average temperature of the hospital.
Against the background that the load on the problematic LUNs is low, it can be concluded that their competition for some common resource causes problems.

Let's see how the system cache works. Reading from the cache is very efficient.

Analysis of the write cache shows that its load is kept within the specified framework of 60-80% with periodic bursts of up to 90% or more. It's not very good.

Let's see how often the system has to resort to extreme measures in order to clear the cache to an acceptable level.
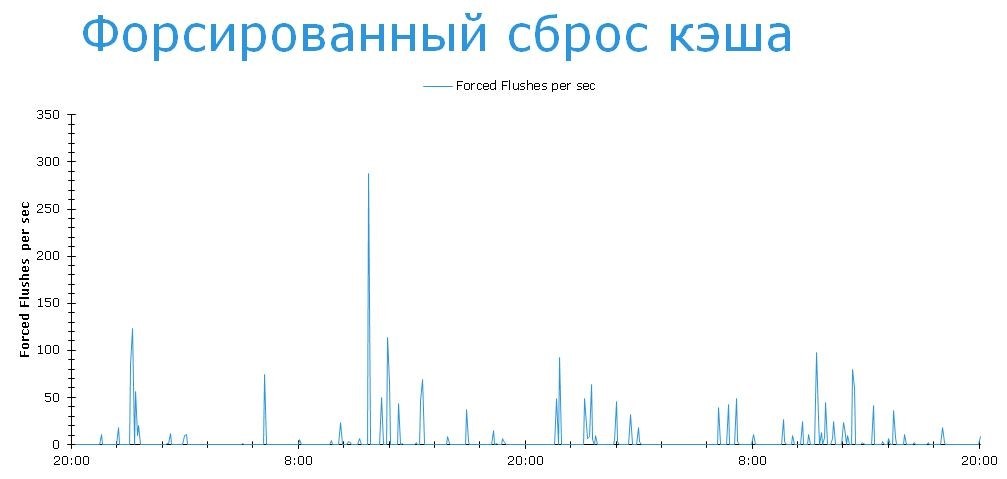
This means that the system does not have time to work out recording bursts. But the system settings can be changed by moving the upper and lower limits to more comfortable levels. 30-50%, for example. But this is the same as bringing down the temperature of the patient. To do this, you must first establish the diagnosis and the root cause. Now let's look at the pools and try to understand what exactly causes forced cache flushes.
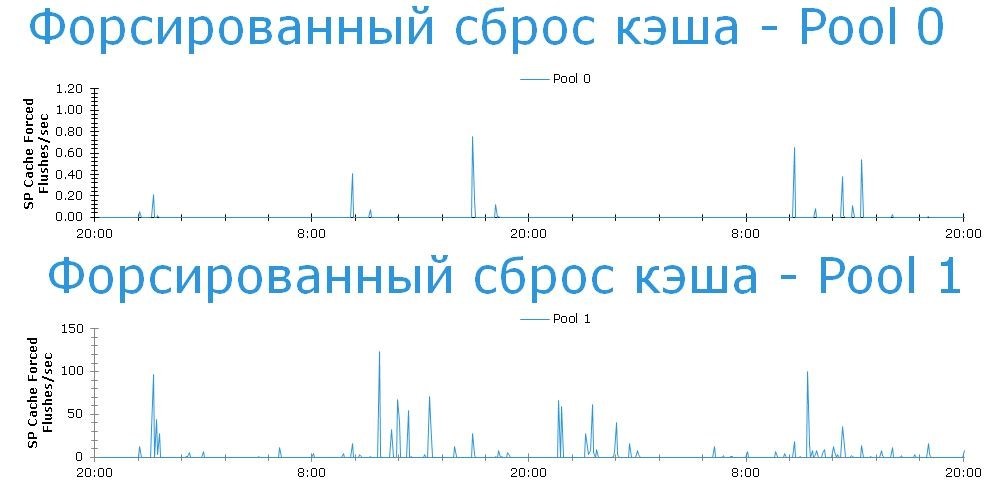
We see that regular forced drops occur on both disk pools. And if at Pool 0 this happens extremely rarely (isolated cases), then at Pool 1 this situation is very difficult (tens and hundreds of events per hour). But Pool 0 interests us. Everything is fine there, isn't it?
We have come close to the solution. But to move on is a lyrical digression, since we need to clarify the logic for managing the write cache fullness in VNX. It is shown below.
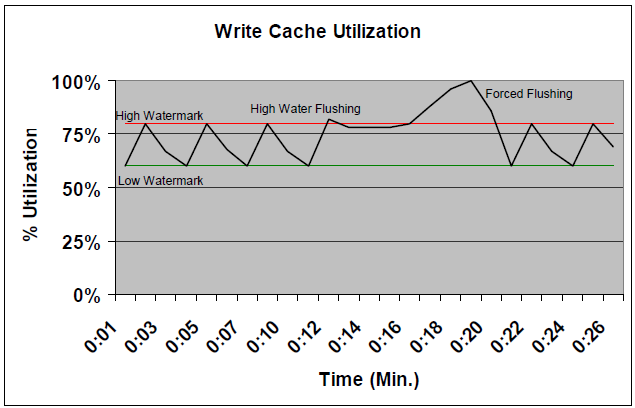
In normal mode, the system maintains a cache between two boundaries — High and Low watermarks.
The lower limit is the threshold below which the write cache is not reset, since the data it contains may be needed for reading, or be overwritten. In addition, the VNX write cache, by its nature, keeps some amount of data blocks, in the hope that they can be combined to write with other blocks nearby, for writing to physical disks. This reduces the load on the back-end.
The upper limit is the threshold for enabling disc write cache. When High Watermark Flushing mode is turned on, data is flushed from the cache to disk to the lower level, and then goes back to standby mode.
We do not want the cache to fill up to 100%, because then we will not be able to provide space for new entries. Therefore, try to keep the upper limit at a safe distance of 100%. Usually 80% is normal. But maybe lower. It all depends on the nature of the load.
If the cache fills up to 100%, then from High Watermark flush mode the system includes forced cache flush, or Forced Flush.
Forced Flush mode has a major impact on all write operations on the storage system. New data is written to the storage system with an additional delay. Those. in order to write a data block in the storage system, you must first free up space from the old data using the LRU algorithm (Least Recently Used), etc.
Let's return to our situation. Obviously, the slower Pool 1 is the weak link in terms of write cache. Data that arrives on slow disks in RAID6 lingers in the cache longer than necessary, and when it comes to Forced Flush, it takes too long to go to physical disks.
It is necessary to pay attention to the fact that Pool 0 uses FAST Cache, and most of the requests are served from flash disks. Until Forced Flush comes on, and the response time of the flash begins to depend on how quickly the data on the NL-SAS is cleared. It seems that the weak link was found. How true this conclusion is is that the hypothesis test should show in practice.
How then can the “suspect” alibi be explained - low loading of NL-SAS disks? Since the load is average over the time interval, and in this case, the statistics collection interval was 10 minutes, it is possible that during this time there was a short burst of data recording, causing a short “freeze” of applications, and on average 10 minutes the load was not so big . Since we have found where the highest value of Forced Flush occurs, there can be no doubt about the “guilt” of this disk pool.
What can you do about it?
The implementation itself, in itself, contains planning errors, since the old approach to configuration in a system with a new generation architecture has been used. Communication with the customer helped to clarify that the matter is in previously accepted standards, which were not revised at the time of planning. But since the system is already combat, and it is impossible to rebuild it, it remains to look for solutions in the field of online reconfigurations in order not to interrupt the operation of applications.
I found at least three measures that can be taken either individually or together, complementing each other. I list the degree of complexity of implementation.
- In order for the storage system to work out periodic bursts of load, it is necessary to lower Low / High watermarks to the level of 30/50 and see how well these bursts will be worked out. Ideally, filling the write cache during bursts should not be up to 90%.
- Enable FAST Cache on Pool 1. The most frequently updated data will be transferred from slow disks to SSD. Resetting the write cache on the SSD is much faster. This will reduce the likelihood of Forced Flush.
- Create a RAID10 RAID group on free SAS 900GB 10k disks (4 pieces) and transfer the most frequently updated LUNs from Pool 1 to them. Disable the write cache in the created RAID group.
There are other ways to optimize, however, I specifically tried not to complicate this example in order to more compactly demonstrate one of the possible approaches.
You can start with these measures, since all of the listed changes are reversible and can be applied or reversed in any order.
In the process of further researching the behavior of the system, other useful conclusions can be made.
Afterword
Intelligent storage systems have rich built-in functionality for both analysis and performance tuning. However, detailed manual analysis and adjustment are quite time-consuming tasks that we have touched on in this post only superficially. Usually, administrators have very little time to fully study the work of the storage system and optimize it. With dynamic workloads and increasingly complex IT infrastructures, a new level of development and automation is required.
To solve these problems, a whole complex of technologies has been developed at all levels.
From more convenient and fast performance analysis to new intelligent and self-optimizing systems.
Here are just some examples:
- 1. Mitrend - freely available for all automated analysis of the IT infrastructure of different manufacturers
2. Automated multi-level storage and cache on SSD: FAST VP and FAST Cache
3. The next-generation systems have implemented an adaptive VNX2 cache with intelligent auto-tuning of the data reset rate per LUN ( see whitepaper page 13 ).
Source: https://habr.com/ru/post/271799/
All Articles