Use TSQL to play Baldu
Recently, I remembered the wonderful intellectual game " Balda ", which I had met in my school years.
The other day I wondered - how difficult would it be to implement the algorithm of this game for a computer opponent?
Since I like working with relational data the most and my favorite language is SQL, I decided to combine business with pleasure and try to write this algorithm using only TSQL. This is my first attempt to write AI using only SQL capabilities.
')
Archive files can be downloaded from the following link - scripts .
All words in the dictionary in uppercase, as well as in it the letters "E" and "E" are considered as one (as "E").
As a result, the following scheme was created:
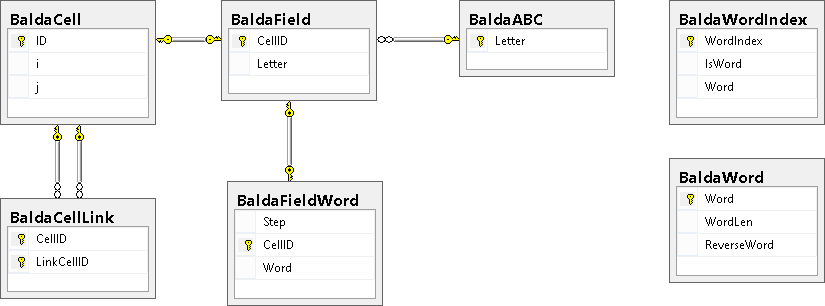
Description of tables:
Script for creating and filling tables:
Search algorithm (first version):
On my computer, this script runs for about 2 seconds.
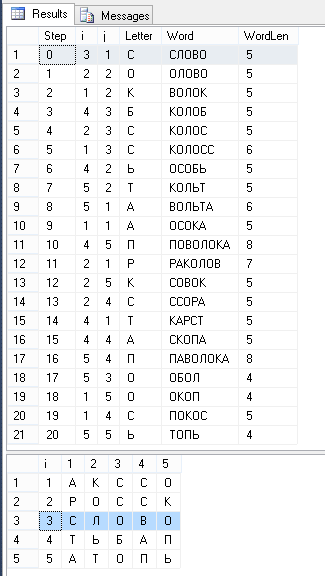
To view the result we use the following 2 queries:
Result:
While preparing the article came up with a more optimal option, which wins in speed almost 2 times (especially noticeable when expanding the size of the field). In the second variant, the auxiliary table BaldaWordIndex is expanded, due to which we can not use the BaldaWord table.
Script to re-create the BaldaWordIndex table:
New search algorithm:
The new version of the script on my computer runs in about 1 second.
To view the result, use the following 2 queries again:
Actually, everything.
This work was done in a hurry and more of sports interest, to refresh the memory a little, and also to see how optimal and fast the solution will be using SQL.
In my opinion, the solution turned out to be quite good and fairly transparent - SQL did a good job with this task. The main recursive query can be easily rewritten into any other SQL dialect which has support for recursive CTE expressions.
Learn SQL - this is a great language for data manipulation.
Hope the article was interesting.
Good luck and thank you for your attention!
All with the first day of winter!
Recently playing “Balda” with my wife on paper, I realized that the algorithm I quoted above looks only for words that contain a new letter at the beginning or end of a word.
He hastily completed the old algorithm, now it takes into account the chains containing the new letter in the middle of the word.
New, smarter algorithm:
This algorithm on my computer completely fills the 5 * 5 field in 10-15 seconds.
The field size of 10 * 10 I filled in about 13 minutes.
Check what happened:
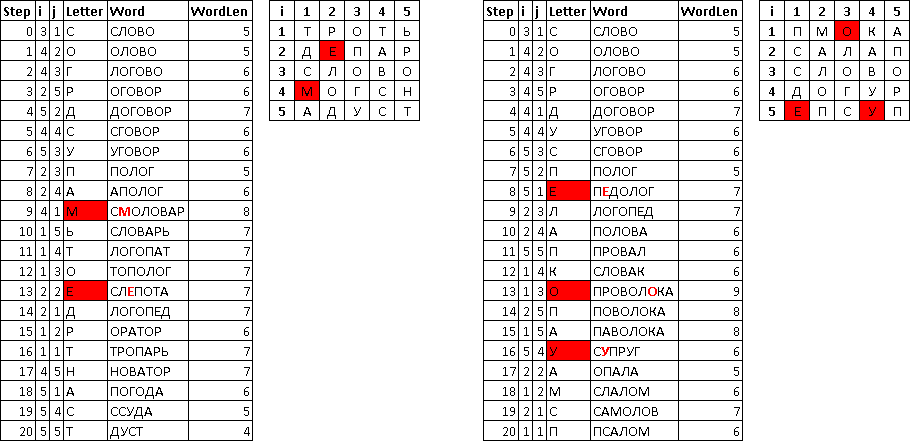
Although the speed and fell, but apparently the quality of the search has increased - there are long words containing a new letter in the middle of the word.
Since The new query is an old query modified in a hurry (it was newWordCte, and there was newWordCte1 + newWordCte2), then, if you wish, I think it will be possible to optimize it well.
Archive with new files can also be downloaded from the same link - scripts .
Thanks again for your attention!
The other day I wondered - how difficult would it be to implement the algorithm of this game for a computer opponent?
Since I like working with relational data the most and my favorite language is SQL, I decided to combine business with pleasure and try to write this algorithm using only TSQL. This is my first attempt to write AI using only SQL capabilities.
')
Archive files can be downloaded from the following link - scripts .
All words in the dictionary in uppercase, as well as in it the letters "E" and "E" are considered as one (as "E").
As a result, the following scheme was created:
Description of tables:
- BaldaCell - Cells (i is the row number, j is the column number)
- BaldaCellLink - Links cells with other cells
- BaldaABC - Alphabet (letters used to make words)
- BaldaField - Used for the current description of the state of the playing field.
- BaldaFieldWord - Used to memorize words already used.
- BaldaWord - A dictionary used by a computer to find matching words.
- BaldaWordIndex - Auxiliary index table used for more optimal query execution
Script for creating and filling tables:
/* DROP TABLE BaldaWord DROP TABLE BaldaFieldWord DROP TABLE BaldaField DROP TABLE BaldaCellLink DROP TABLE BaldaCell DROP TABLE BaldaABC DROP TABLE BaldaWordIndex */ -------------------------------------------------------------------- -- -------------------------------------------------------------------- CREATE TABLE BaldaCell( ID int NOT NULL, i int NOT NULL, j int NOT NULL, CONSTRAINT PK_BaldaCell PRIMARY KEY(ID) ) GO -- DECLARE @MaxW int=5 DECLARE @MaxH int=5 -- ;WITH iCte AS( SELECT 1 i UNION ALL SELECT i+1 FROM iCte WHERE i<@MaxW ), jCte AS( SELECT 1 j UNION ALL SELECT j+1 FROM jCte WHERE j<@MaxH ) INSERT BaldaCell(ID,i,j) SELECT 10000+i*100+j,i,j FROM iCte CROSS JOIN jCte OPTION(MAXRECURSION 0) GO -------------------------------------------------------------------- -- -------------------------------------------------------------------- CREATE TABLE BaldaCellLink( CellID int NOT NULL, LinkCellID int NOT NULL, CONSTRAINT PK_BaldaCellLink PRIMARY KEY(CellID,LinkCellID), CONSTRAINT FK_BaldaCellLink_CellID FOREIGN KEY(CellID) REFERENCES BaldaCell(ID), CONSTRAINT FK_BaldaCellLink_LinkCellID FOREIGN KEY(LinkCellID) REFERENCES BaldaCell(ID) ) GO -- INSERT BaldaCellLink(CellID,LinkCellID) SELECT c.ID,l.ID FROM BaldaCell c JOIN BaldaCell l ON (cj=lj AND ci IN(li-1,l.i+1)) OR (ci=li AND cj IN(lj-1,l.j+1)) GO /* SELECT * FROM BaldaCellLink WHERE CellID=10303 -- 4 SELECT * FROM BaldaCellLink WHERE CellID=10503 -- 3 SELECT * FROM BaldaCellLink WHERE CellID=10105 -- 2 */ -------------------------------------------------------------------- -- -------------------------------------------------------------------- CREATE TABLE BaldaABC( Letter nchar(1) NOT NULL, CONSTRAINT PK_BaldaABC PRIMARY KEY(Letter) ) GO -- INSERT BaldaABC(Letter) VALUES (N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''), (N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''), (N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''),(N''), (N''),(N'') GO -------------------------------------------------------------------- -- -------------------------------------------------------------------- CREATE TABLE BaldaField( CellID int NOT NULL, Letter nchar(1) NOT NULL, CONSTRAINT PK_BaldaField PRIMARY KEY(CellID), CONSTRAINT FK_BaldaField_CellID FOREIGN KEY(CellID) REFERENCES BaldaCell(ID), CONSTRAINT FK_BaldaField_Letter FOREIGN KEY(Letter) REFERENCES BaldaABC(Letter) ) GO -------------------------------------------------------------------- -- -------------------------------------------------------------------- CREATE TABLE BaldaFieldWord( Step int NOT NULL, CellID int NOT NULL, Word nvarchar(50) NOT NULL, CONSTRAINT PK_BaldaFieldWord PRIMARY KEY(CellID), CONSTRAINT UK_BaldaFieldWord UNIQUE(Word), CONSTRAINT FK_BaldaFieldWord_CellID FOREIGN KEY(CellID) REFERENCES BaldaField(CellID) ON DELETE CASCADE, ) GO -------------------------------------------------------------------- -- -------------------------------------------------------------------- CREATE TABLE BaldaWord( Word nvarchar(50) NOT NULL, WordLen int NOT NULL, ReverseWord nvarchar(50) NOT NULL, CONSTRAINT PK_Word PRIMARY KEY(Word) ) GO CREATE TABLE #TempWord( Word nvarchar(50) NOT NULL ) -- (ASCII) BULK INSERT #TempWord FROM 'd:\Temp\.txt' WITH ( FIRSTROW = 1, FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', CODEPAGE = 'ACP' ); INSERT BaldaWord(Word,WordLen,ReverseWord) SELECT Word,LEN(Word),REVERSE(Word) FROM #TempWord DROP TABLE #TempWord -------------------------------------------------------------------- -- / -------------------------------------------------------------------- CREATE TABLE BaldaWordIndex( WordIndex nvarchar(50) NOT NULL, CONSTRAINT PK_BaldaWordIndex PRIMARY KEY(WordIndex) ) GO DECLARE @MaxWordLen int=(SELECT MAX(WordLen) FROM BaldaWord) DECLARE @IndexLen int=2 WHILE @IndexLen<@MaxWordLen BEGIN INSERT BaldaWordIndex(WordIndex) SELECT LEFT(Word,@IndexLen) FROM BaldaWord WHERE LEN(LEFT(Word,@IndexLen))=@IndexLen UNION SELECT LEFT(ReverseWord,@IndexLen) FROM BaldaWord WHERE LEN(LEFT(ReverseWord,@IndexLen))=@IndexLen SET @IndexLen+=1 END GO Search algorithm (first version):
Algorithm text ...
-- DELETE BaldaField -- INSERT BaldaField(CellID,Letter) VALUES (10301,N''), (10302,N''), (10303,N''), (10304,N''), (10305,N'') -- INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'') /* INSERT BaldaField(CellID,Letter) VALUES (10301,N''), (10302,N''), (10303,N''), (10304,N''), (10305,N'') INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'') */ /* INSERT BaldaField(CellID,Letter) VALUES (10301,N''), (10302,N''), (10303,N''), (10304,N''), (10305,N'') INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'') */ DECLARE @Step int=1 DECLARE @NewCellID int=0 DECLARE @NewLetter nchar(1) DECLARE @Word nvarchar(50) DECLARE @WordLen int WHILE @NewCellID IS NOT NULL BEGIN -- WITH newWordCte AS( SELECT CellID NewCellID, Letter NewLetter, CellID, CAST(Letter AS nvarchar(50)) Word, 1 WordLen, CAST(CellID AS varchar(300)) CellPath FROM ( SELECT l.LinkCellID CellID,abc.Letter FROM BaldaField f -- JOIN BaldaCellLink l ON f.CellID=l.CellID AND l.LinkCellID NOT IN(SELECT CellID FROM BaldaField) -- CROSS JOIN BaldaABC abc ) q UNION ALL SELECT w.NewCellID, w.NewLetter, f.CellID, CAST(w.Word+f.Letter AS nvarchar(50)), w.WordLen+1, CAST(w.CellPath+','+CAST(f.CellID AS varchar(10)) AS varchar(300)) FROM newWordCte w JOIN BaldaCellLink l ON w.CellID=l.CellID JOIN BaldaField f ON f.CellID=l.LinkCellID -- , JOIN BaldaWordIndex i ON w.Word+f.Letter=i.WordIndex -- , WHERE CHARINDEX(CAST(f.CellID AS varchar(10)),w.CellPath)=0 ) SELECT DISTINCT NewCellID,NewLetter,Word INTO #ResultAll FROM newWordCte WHERE WordLen>1 -- .. OPTION(MAXRECURSION 0); SELECT TOP 1 WITH TIES -- NewCellID, NewLetter, Word, WordLen INTO #Result FROM ( -- , SELECT r.NewCellID,r.NewLetter,w.Word,w.WordLen FROM #ResultAll r JOIN BaldaWord w ON r.Word=w.Word WHERE w.Word NOT IN(SELECT Word FROM BaldaFieldWord) UNION -- SELECT r.NewCellID,r.NewLetter,w.Word,w.WordLen FROM #ResultAll r JOIN BaldaWord w ON r.Word=w.ReverseWord WHERE w.Word NOT IN(SELECT Word FROM BaldaFieldWord) UNION -- , SELECT NULL,NULL,NULL,-1 ) q ORDER BY WordLen DESC DROP TABLE #ResultAll -- DECLARE @RowCount int=(SELECT COUNT(*) FROM #Result) SELECT @NewCellID=NewCellID, @NewLetter=NewLetter, @Word=Word, @WordLen=WordLen FROM #Result ORDER BY NewCellID OFFSET CAST(FLOOR(RAND()*@RowCount) AS int) ROWS FETCH NEXT 1 ROWS ONLY DROP TABLE #Result IF @NewCellID IS NOT NULL BEGIN -- INSERT BaldaField(CellID,Letter) VALUES(@NewCellID,@NewLetter) INSERT BaldaFieldWord(Step,CellID,Word) VALUES(@Step,@NewCellID,@Word) SET @Step+=1 END END On my computer, this script runs for about 2 seconds.
To view the result we use the following 2 queries:
-- SELECT uw.Step,ci,cj,f.Letter,uw.Word,LEN(uw.Word) WordLen FROM BaldaFieldWord uw JOIN BaldaField f ON uw.CellID=f.CellID JOIN BaldaCell c ON c.ID=f.CellID ORDER BY uw.Step -- SELECT * FROM ( SELECT ci,cj,f.Letter FROM BaldaCell c LEFT JOIN BaldaField f ON c.ID=f.CellID ) q PIVOT(MAX(Letter) FOR j IN([1],[2],[3],[4],[5])) p ORDER BY i Result:
While preparing the article came up with a more optimal option, which wins in speed almost 2 times (especially noticeable when expanding the size of the field). In the second variant, the auxiliary table BaldaWordIndex is expanded, due to which we can not use the BaldaWord table.
Script to re-create the BaldaWordIndex table:
-------------------------------------------------------------------- -- / - 2 -------------------------------------------------------------------- DROP TABLE BaldaWordIndex GO CREATE TABLE BaldaWordIndex( WordIndex nvarchar(50) NOT NULL, IsWord bit NOT NULL, Word nvarchar(50), CONSTRAINT PK_BaldaWordIndex PRIMARY KEY(WordIndex) ) GO DECLARE @MaxWordLen int=(SELECT MAX(WordLen) FROM BaldaWord) DECLARE @IndexLen int=2 WHILE @IndexLen<=@MaxWordLen BEGIN INSERT BaldaWordIndex(WordIndex,IsWord,Word) SELECT WordIndex,MAX(IsWord),MAX(Word) FROM ( SELECT LEFT(Word,@IndexLen) WordIndex,IIF(LEN(Word)=@IndexLen,1,0) IsWord,IIF(LEN(Word)=@IndexLen,Word,NULL) Word FROM BaldaWord WHERE LEN(LEFT(Word,@IndexLen))=@IndexLen UNION SELECT LEFT(ReverseWord,@IndexLen),IIF(LEN(Word)=@IndexLen,1,0),IIF(LEN(Word)=@IndexLen,Word,NULL) FROM BaldaWord WHERE LEN(LEFT(ReverseWord,@IndexLen))=@IndexLen ) q GROUP BY WordIndex SET @IndexLen+=1 END GO /* SELECT COUNT(*) FROM BaldaWordIndex WHERE IsWord=1 SELECT COUNT(*) FROM ( SELECT Word FROM BaldaWord UNION SELECT ReverseWord FROM BaldaWord ) q */ New search algorithm:
Algorithm text ...
-- DELETE BaldaField -- INSERT BaldaField(CellID,Letter) VALUES (10301,N''), (10302,N''), (10303,N''), (10304,N''), (10305,N'') -- INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'') DECLARE @Step int=1 DECLARE @NewCellID int=0 DECLARE @NewLetter nchar(1) DECLARE @Word nvarchar(50) DECLARE @WordLen int WHILE @NewCellID IS NOT NULL BEGIN -- WITH newWordCte AS( SELECT CellID NewCellID, Letter NewLetter, CellID, CAST(Letter AS nvarchar(50)) Word, 1 WordLen, CAST(CellID AS varchar(300)) CellPath, CAST(0 AS bit) IsWord, CAST(NULL AS nvarchar(50)) ResWord FROM ( SELECT l.LinkCellID CellID,abc.Letter FROM BaldaField f -- JOIN BaldaCellLink l ON f.CellID=l.CellID AND l.LinkCellID NOT IN(SELECT CellID FROM BaldaField) -- CROSS JOIN BaldaABC abc ) q UNION ALL SELECT w.NewCellID, w.NewLetter, f.CellID, CAST(w.Word+f.Letter AS nvarchar(50)), w.WordLen+1, CAST(w.CellPath+','+CAST(f.CellID AS varchar(10)) AS varchar(300)), i.IsWord, i.Word FROM newWordCte w JOIN BaldaCellLink l ON w.CellID=l.CellID JOIN BaldaField f ON f.CellID=l.LinkCellID -- , JOIN BaldaWordIndex i ON w.Word+f.Letter=i.WordIndex -- , WHERE CHARINDEX(CAST(f.CellID AS varchar(10)),w.CellPath)=0 ) SELECT TOP 1 WITH TIES -- NewCellID, NewLetter, Word, WordLen INTO #Result FROM ( SELECT DISTINCT NewCellID,NewLetter,ResWord Word,WordLen FROM newWordCte WHERE IsWord=1 -- AND ResWord NOT IN(SELECT Word FROM BaldaFieldWord) ) q ORDER BY WordLen DESC OPTION(MAXRECURSION 0); DECLARE @RowCount int=(SELECT COUNT(*) FROM #Result) SET @NewCellID=NULL IF @RowCount>0 BEGIN -- SELECT @NewCellID=NewCellID, @NewLetter=NewLetter, @Word=Word, @WordLen=WordLen FROM #Result ORDER BY NewCellID OFFSET CAST(FLOOR(RAND()*@RowCount) AS int) ROWS FETCH NEXT 1 ROWS ONLY -- INSERT BaldaField(CellID,Letter) VALUES(@NewCellID,@NewLetter) INSERT BaldaFieldWord(Step,CellID,Word) VALUES(@Step,@NewCellID,@Word) SET @Step+=1 END DROP TABLE #Result END The new version of the script on my computer runs in about 1 second.
To view the result, use the following 2 queries again:
-- SELECT uw.Step,ci,cj,f.Letter,uw.Word,LEN(uw.Word) WordLen FROM BaldaFieldWord uw JOIN BaldaField f ON uw.CellID=f.CellID JOIN BaldaCell c ON c.ID=f.CellID ORDER BY uw.Step -- SELECT * FROM ( SELECT ci,cj,f.Letter FROM BaldaCell c LEFT JOIN BaldaField f ON c.ID=f.CellID ) q PIVOT(MAX(Letter) FOR j IN([1],[2],[3],[4],[5])) p ORDER BY i Actually, everything.
This work was done in a hurry and more of sports interest, to refresh the memory a little, and also to see how optimal and fast the solution will be using SQL.
In my opinion, the solution turned out to be quite good and fairly transparent - SQL did a good job with this task. The main recursive query can be easily rewritten into any other SQL dialect which has support for recursive CTE expressions.
Learn SQL - this is a great language for data manipulation.
Hope the article was interesting.
Good luck and thank you for your attention!
Addition to the article (12/01/2015)
All with the first day of winter!
Recently playing “Balda” with my wife on paper, I realized that the algorithm I quoted above looks only for words that contain a new letter at the beginning or end of a word.
He hastily completed the old algorithm, now it takes into account the chains containing the new letter in the middle of the word.
New, smarter algorithm:
-- DELETE BaldaField -- INSERT BaldaField(CellID,Letter) VALUES (10301,N''), (10302,N''), (10303,N''), (10304,N''), (10305,N'') -- INSERT BaldaFieldWord(Step,CellID,Word) VALUES(0,10301,N'') DECLARE @Step int=1 DECLARE @NewCellID int=0 DECLARE @NewLetter nchar(1) DECLARE @Word nvarchar(50) DECLARE @WordLen int CREATE TABLE #Sets( SetID nvarchar(20) NOT NULL, CellID int NOT NULL, Letter nchar(1) NOT NULL, IsNewCell int NOT NULL, NewCellID int, NewLetter nchar(1), PRIMARY KEY(SetID,CellID) ) WHILE @NewCellID IS NOT NULL BEGIN -- TRUNCATE TABLE #Sets -- INSERT #Sets(SetID,CellID,Letter,IsNewCell,NewCellID,NewLetter) SELECT res.* FROM ( -- , SELECT l.LinkCellID FROM BaldaField f JOIN BaldaCellLink l ON f.CellID=l.CellID AND l.LinkCellID NOT IN(SELECT CellID FROM BaldaField) GROUP BY l.LinkCellID HAVING COUNT(f.CellID)>1 ) q -- CROSS JOIN BaldaABC abc -- + CROSS APPLY ( SELECT CAST(q.LinkCellID AS nvarchar(10))+abc.Letter SetID,q.LinkCellID CellID,abc.Letter,CAST(1 AS int) IsNewCell,q.LinkCellID NewCellID,abc.Letter NewLetter UNION ALL SELECT CAST(q.LinkCellID AS nvarchar(10))+abc.Letter,f.CellID,f.Letter,0,NULL,NULL FROM BaldaField f ) res; -- / WITH newWordCte1 AS( SELECT CellID NewCellID, Letter NewLetter, CellID, CAST(Letter AS nvarchar(50)) Word, 1 WordLen, CAST(CellID AS varchar(300)) CellPath, CAST(0 AS bit) IsWord, CAST(NULL AS nvarchar(50)) ResWord FROM ( SELECT q.LinkCellID CellID,abc.Letter FROM ( -- , SELECT l.LinkCellID FROM BaldaField f JOIN BaldaCellLink l ON f.CellID=l.CellID AND l.LinkCellID NOT IN(SELECT CellID FROM BaldaField) GROUP BY l.LinkCellID HAVING COUNT(f.CellID)=1 ) q -- CROSS JOIN BaldaABC abc ) q UNION ALL SELECT w.NewCellID, w.NewLetter, f.CellID, CAST(w.Word+f.Letter AS nvarchar(50)), w.WordLen+1, CAST(w.CellPath+','+CAST(f.CellID AS varchar(10)) AS varchar(300)), i.IsWord, i.Word FROM newWordCte1 w JOIN BaldaCellLink l ON w.CellID=l.CellID JOIN BaldaField f ON f.CellID=l.LinkCellID -- , JOIN BaldaWordIndex i ON w.Word+f.Letter=i.WordIndex -- , WHERE CHARINDEX(CAST(f.CellID AS varchar(10)),w.CellPath)=0 ), -- , newWordCte2 AS( SELECT SetID, CellID, CAST(Letter AS nvarchar(50)) Word, 1 WordLen, CAST(CellID AS varchar(300)) CellPath, CAST(0 AS bit) IsWord, CAST(NULL AS nvarchar(50)) ResWord, IsNewCell, NewCellID, NewLetter FROM #Sets -- UNION ALL SELECT w.SetID, f.CellID, CAST(w.Word+f.Letter AS nvarchar(50)), w.WordLen+1, CAST(w.CellPath+','+CAST(f.CellID AS varchar(10)) AS varchar(300)), i.IsWord, i.Word, w.IsNewCell+f.IsNewCell, ISNULL(w.NewCellID,f.NewCellID), ISNULL(w.NewLetter,f.NewLetter) FROM newWordCte2 w JOIN BaldaCellLink l ON w.CellID=l.CellID JOIN #Sets f ON w.SetID=f.SetID AND f.CellID=l.LinkCellID -- , JOIN BaldaWordIndex i ON w.Word+f.Letter=i.WordIndex -- , WHERE CHARINDEX(CAST(f.CellID AS varchar(10)),w.CellPath)=0 ) SELECT TOP 1 WITH TIES -- NewCellID, NewLetter, Word, WordLen INTO #Result FROM ( SELECT NewCellID,NewLetter,ResWord Word,WordLen FROM newWordCte1 WHERE IsWord=1 -- AND ResWord NOT IN(SELECT Word FROM BaldaFieldWord) UNION SELECT NewCellID,NewLetter,ResWord Word,WordLen FROM newWordCte2 WHERE IsWord=1 -- AND IsNewCell=1 -- AND ResWord NOT IN(SELECT Word FROM BaldaFieldWord) ) q ORDER BY WordLen DESC OPTION(MAXRECURSION 0); DECLARE @RowCount int=(SELECT COUNT(*) FROM #Result) SET @NewCellID=NULL IF @RowCount>0 BEGIN -- SELECT @NewCellID=NewCellID, @NewLetter=NewLetter, @Word=Word, @WordLen=WordLen FROM #Result ORDER BY NewCellID OFFSET CAST(FLOOR(RAND()*@RowCount) AS int) ROWS FETCH NEXT 1 ROWS ONLY -- INSERT BaldaField(CellID,Letter) VALUES(@NewCellID,@NewLetter) INSERT BaldaFieldWord(Step,CellID,Word) VALUES(@Step,@NewCellID,@Word) SET @Step+=1 END DROP TABLE #Result END DROP TABLE #Sets This algorithm on my computer completely fills the 5 * 5 field in 10-15 seconds.
The field size of 10 * 10 I filled in about 13 minutes.
Check what happened:
-- SELECT uw.Step,ci,cj,f.Letter,uw.Word,LEN(uw.Word) WordLen FROM BaldaFieldWord uw JOIN BaldaField f ON uw.CellID=f.CellID JOIN BaldaCell c ON c.ID=f.CellID ORDER BY uw.Step -- SELECT * FROM ( SELECT ci,cj,f.Letter FROM BaldaCell c LEFT JOIN BaldaField f ON c.ID=f.CellID ) q PIVOT(MAX(Letter) FOR j IN([1],[2],[3],[4],[5])) p ORDER BY i Although the speed and fell, but apparently the quality of the search has increased - there are long words containing a new letter in the middle of the word.
Since The new query is an old query modified in a hurry (it was newWordCte, and there was newWordCte1 + newWordCte2), then, if you wish, I think it will be possible to optimize it well.
Archive with new files can also be downloaded from the same link - scripts .
Thanks again for your attention!
Source: https://habr.com/ru/post/271795/
All Articles