Exasol: Badoo Experience
 Exasol is a modern high-performance proprietary database for analytics. Its direct competitors are HP Vertica, Teradata, Redshift, BigQuery. They are widely covered in RuNet and Habré, while there is almost no word about Exasol in Russian. We would like to correct this situation and share the experience of practical use of the DBMS in the company Badoo.
Exasol is a modern high-performance proprietary database for analytics. Its direct competitors are HP Vertica, Teradata, Redshift, BigQuery. They are widely covered in RuNet and Habré, while there is almost no word about Exasol in Russian. We would like to correct this situation and share the experience of practical use of the DBMS in the company Badoo.Exasol is based on three main concepts:
1. Massively Parallel Architecture (massive parallel processing, MPP)
SQL queries are executed in parallel on all nodes, making the most of all available resources: processor cores, memory, disks, and the network. The concept of "master node" is absent - all servers in the system are equivalent.
')
Separate stages of the execution of a single request can also go in parallel. In this case, partially calculated results are transmitted to the next stage, without waiting for the end of the previous one.
2. Column storage (English columnar store)
Exasol stores data in column form , and not in the form of separate rows, as in classical DBMS. Each column is stored separately, divided into large blocks, sorted, compressed and evenly distributed across all nodes.
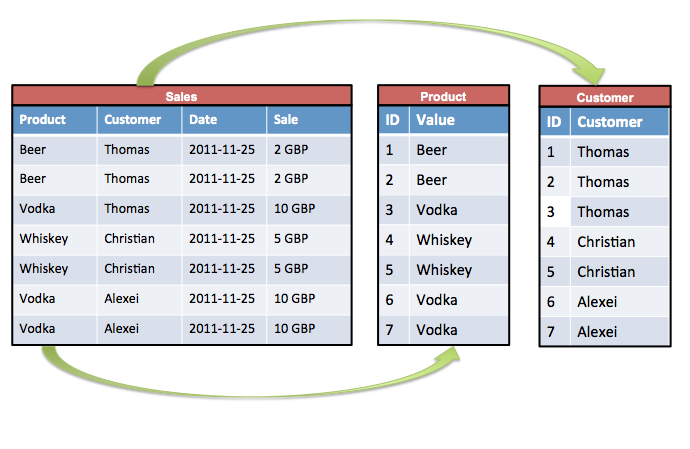
Compression efficiency varies greatly depending on the data types and the distribution of values in the tables. On average, Badoo data is compressed 6.76 times.
Column storage allows you to repeatedly accelerate analytical queries, as well as read only the data that is necessary to fulfill the query. In classical DBMS, it is necessary to read the entire series as a whole, even if it uses only one column.
3. In-memory analytics
Exasol has a mechanism similar to MySQL's buffer pool or PostgreSQL's shared buffer. Data blocks once loaded from disk remain in memory and can be reused for subsequent requests.
As a rule, in real life, users work primarily with “hot” data (last day, week, month). If the cluster has enough memory to hold them all, then Exasol will not touch the disk at all.
These three concepts, brought together in one DBMS, show high performance regarding the complexity of SQL queries and the hardware used. We give specific numbers.
Now Badoo cluster uses 8 servers with the following characteristics:
- 16 to 20 CPU Cores;
- 768 GB RAM;
- 16x1 TB HDD (RAID 1 - 8 TB);
- 10 Gbps network.
The total memory available to Exasol is approximately 5.6 TB.
The total amount of uncompressed data is about 85 TB.
The sizes of large tables vary from 500 million to 50 billion rows. One analytical query processes an average of about 4.5 billion rows.
Performance on real queries for the last month:
| Number of objects in the request | All requests | Requests lasting from 1 second | ||||
|---|---|---|---|---|---|---|
| Qty | Median | The average | Qty | Median | The average | |
| Until 3 | 240914 | 0.021 seconds | 9 sec | 34808 | 29 sec | 63 seconds |
| 4 to 10 | 45122 | 13 seconds | 47 sec | 30005 | 34 sec | 70 seconds |
| From 11 to 30 | 12642 | 24 sec | 69 sec | 5615 | 45 seconds | 156 seconds |
| From 31 and more | 740 | 41 sec | 303 sec | 740 | 41 sec | 303 sec |
This is not a synthetic test, but real statistics on real requests from live users. As you can see, even in the most difficult cases, it is most often about seconds and minutes, but not about hours or days.
The complexity of the query in this example is conditionally calculated by simply searching for the words FROM and JOIN in the SQL text. Thus, we find the approximate number of objects used. The more objects used, the more difficult the request.
Separating requests from 1 second into a separate group is necessary in order to reduce the impact of too fast in-memory requests for the result and to show the most realistic picture for those cases when you still need to read something from the disk.
Due to this, high performance is achieved, in addition to the above concepts.
Joins (eng.) And indices
Exasol can do very fast joins, and it doesn’t bother at all about their number.
An effective join always occurs by index. Indexes are created automatically at the moment when you first try to merge two tables using specific keys. If the index is not used for a long time, then it is also automatically deleted.
When adding or deleting data in tables with existing indexes, “deltas” are created that contain only changes. If there are too many changes (about 20% of the total volume), then INDEX MERGE occurs, which combines the main index with the delta, after which the delta is deleted. This is much faster than rebuilding the index from scratch. The mechanism is somewhat similar to Sphinx.
Indexes occupy a relatively small amount of memory. The vast majority of indexes in our database takes less than 100 GB, including the case for multi-billion dollar tables. The size of the index is determined by the number of columns included in it, their data types and value variability.
Global joins vs local joins
Joyns are global and local. A global join occurs when the data to be merged is physically stored on different nodes.

A local join occurs when the merged data is stored on the same node.

Local joins are much faster than global ones, because in this case the network is not used. This effect can be achieved by pre-distributing data on nodes in a special way. In our example, this can be done as follows:
ALTER TABLE CUSTOMER DISTRIBUTE BY CITY_ID; ALTER TABLE CITIES DISTRIBUTE BY ID; At the same time, it is guaranteed that for both tables, rows with the same city_id values will always be physically located together on the same node.
Also, small tables are automatically replicated (copied entirely) on all nodes, which automatically guarantees fast local joins to them. This is especially true for numerous small listings.
The main difference between Exasol and other distributed DBMS is that you don’t have to fear global joins and there is no need to create special projections to avoid them. Of course, global joins are slower than local ones, but not so much that it creates problems. The vast majority of joins in Badoo are global.
Effective join conditions
In order for a join to occur according to the most effective scenario, it is necessary to follow a number of simple rules:
1. Conditions must be in columnA = columnB format only.
Good:
JOIN table2 b ON (a.id=b.id) Poorly:
JOIN table2 b ON (a.purchase_date > b.create_date) 2. It is undesirable to use expressions.
Good:
JOIN table2 b ON (a.purchase_date=b.purchase_date) Poorly:
JOIN table2 b ON (a.purchase_date=TO_DATE(b.purchase_time)) 3. Several conditions can be combined with AND, but OR should be avoided.
Good:
JOIN table2 b ON (a.id=b.id AND a.name=b.name) Poorly:
JOIN table2 b ON (a.id=b.id OR a.name=b.name) 4. The types of data columns must match. DECIMAL to DECIMAL, VARCHAR to VARCHAR, DATE to DATE and so on.
If at least one of the conditions is not met, then the following occurs:
- or the index will still be created, but after the query is executed, it will be immediately deleted (the so-called Expression Index);
- or Exasol will do the “everything to everything” join, and then the filtering. The latter is not so bad as long as you do not get several trillion rows in the intermediate result. Billions - quite possible.
Root filter
The concept of “Root filter” makes a significant contribution to the high performance of Exasol. It cannot be found in the official documentation, but can be seen in secret system "views" and query execution plans.
How does the filter work?
If the query has a fairly selective WHERE condition with constants, then Exasol will read only those data blocks that fit the specified condition. He will not read all the other blocks.
In these examples, the filter will be used:
WHERE registration_date BETWEEN '2015-01-01' AND '2015-10-01' WHERE foo >= 115 WHERE product_type IN ('book','car','doll') And in these examples the filter will not be used:
WHERE registration_date BETWEEN CURRENT_DATE – INTERVAL '1' YEAR AND CURRENT_DATE WHERE foo > (15 + 17) WHERE email REGEXP_LIKE '(?i)@mail\.ru$' If Exasol can predefine clear and simple boundaries of exactly which data it needs to read, then it will take advantage of this opportunity and will reduce the number of read operations a dozen or hundreds of times. The fewer reads and the smaller the size of intermediate results, the faster everything works. At the same time, no special indexes are needed - only statistics based on the data storage column structure are used.
SQL Features and Features
Exasol fully supports basic ANSI SQL. This includes GROUP BY, HAVING, ORDER BY, LIMIT, OFFSET, MERGE, FULL JOIN, DISTINCT, etc. - in a word, everything that we used to see.
From an analytical SQL perspective, the following is suggested:
- Window functions, ROW_NUMBER, medians, ranks, percentiles for every taste;
- Common Table Expressions;
- CUBE, ROLLUP, GROUPING SETS;
- GROUP_CONCAT;
- PCRE regular expressions, including searching, capturing patterns and replacing them;
- functions for working with dates and time zones;
- Geospatial-functions.
We found it interesting that Exasol treats the empty string as NULL. It can not be disabled. Apparently, the transformation occurs somewhere at very deep levels, but this does not create serious problems. You just need to remember this when importing.
Exasol rigidly validates data types. No automatic type conversions, implicit truncations of lines that are too long, rounding, etc. not happening. In such cases, you will always see an error, which is good.
Transactions
Exasol - transactional DBMS, full ACID compliant . Isolation level is serializable . In practice, in the current implementation, this means that only one writer can write to a table in parallel. Readers can be any number, and they are not blocked by the writer. "Parallel writers" will be executed sequentially one after another, or, in case of conflicts and deadlocks, a ROLLBACK will occur.
DDL queries are also transactional. This means that you can create new tables, views, add columns, etc. - all this can occur in a single transaction. If necessary, you can easily make a ROLLBACK and return everything as it was.
Due to the storage column structure, the addition and removal of columns occurs almost instantly. There is no downtime due to long “alters” when changing the table schema in practice.
Data import
It is most efficient to import data into Exasol using the built-in exajload utility. It makes the most of the flow control and parallel connections to several nodes at once.
It is allowed to transmit compressed data stream without prior decompression, which significantly reduces the load on the network. Supported formats: gz, zip, bz2.
For analytical DBMS, the issue of effective data loading from Hadoop is relevant. Exasol allows you to directly load files into multiple streams using WebHDFS, bypassing intermediate servers and reducing overall overhead.
Due to the transactionality, you can also load data directly into the production-table, entirely bypassing staging. If the download is interrupted (for any reason), then ROLLBACK will occur, and you will have an old copy of the table. If the download completes successfully, the new data will replace the old one.
Like in many other analytical DBMSs, the ELT (Extract - Load - Transform) approach in Exasol is much more efficient than the classic ETL (Extract - Transform - Load) approach. It is better to load the raw data into an intermediate table, and then transform it with the means of the DBMS itself, while using all the advantages of Massive Parallel Processing.
Briefly about support
1. In Exasol, there is currently no advanced support for servers with different configurations within a single cluster. All nodes receive the same amount of data and the same amount of computational tasks. The entire cluster will operate at the speed of the weakest node. Therefore, it is better to put 2-4 powerful servers at the very beginning than 10 weak ones. Expand then you will be much easier.
2. Adding a new node takes several minutes. After that, Exasol can immediately raise and allow users, without waiting for the final redistribution of data on the disks. In this case, everything will work a little slower due to additional network operations, but as the number of nodes increases, the difference becomes less noticeable. The data reorganization process can be controlled manually by running the REORGANIZE command for specific schemas or tables. Thus, it is possible to reorganize more important tables earlier than all the others.
3. Fault tolerance. In our practice, we encountered several accident scenarios. For example, the free space ended, or someone accidentally physically disconnected part of the working servers from the network. We did not notice any significant problems with this. The database writes in advance about the problem, stops and waits for the situation to be corrected. In some cases, an automatic restart occurs if the problem disappears. Moreover, if you do not look into the logs, you can not know that something was happening at all.
Exasol is able to survive the complete loss of a certain number of nodes without stopping work. There is a special “redundancy” parameter that determines how many nodes will physically store each data block. The higher the value of this parameter, the more nodes can be lost. But for this it is expected to pay a place on the disks.
4. SSD drives for Exasol do not play a big role. The data blocks are very large, they are read and written in large batches one after another. Random disk access is almost absent. Instead of SSD it is better to put more memory.
Prices
Unfortunately, Exasol is not open source software. You must pay for the license. There are no fixed prices - the company agrees individually with each partner. Most likely, the cost will depend on the amount of RAM used, which is typical for DBMSs that position themselves as in-memory.
Exasol also has a free trial . It is a version that works only on one node and uses up to 10 GB of RAM. This is enough for the devel-environment and to check your requests for a small part of the data and make a general impression.
In addition, Exasol launched a special program for startups , which offers 500 GB of data in the cloud for 500 euros per month. You do not need to buy expensive iron. Unfortunately, we can not appreciate the benefits of their clouds, because we did not work with him.
Physically, Exasol is located in the city of Nuremberg (Germany). You can come to visit them, take training courses, talk with the developers.
Conclusion
Overall, Exasol has become a real discovery for us. You simply load the data and can analyze it immediately at high speed. It just works.
At the same time there is no fuss with indexes, views, some kind of manual optimizations. You can link together data from completely different sources, and not only those that were previously intended for this. Any joins at your service.
In fact, you are limited only by the ability to formulate your task in the form of a SQL query. If for some special cases SQL capabilities are not enough, then Exasol allows you to create custom functions in Python, LUA, Java, R. At the same time, all the advantages of column storage, general parallelism of all operations and efficient memory use are preserved.
If you are interested in any other aspects of working with Exasol, as well as the organization of an effective ETL process, write in the comments, I will be happy to answer you.
Thanks for attention!
useful links
- Exasol website
- User Manual (ver 5.0.11)
- Technical Whitepaper - explanations about Massive Parallel Processing
- Free trial
- Solution center - mostly useful videos and answers to frequently asked questions.
Source: https://habr.com/ru/post/271753/
All Articles