Yandex announces its own weather forecasting technology Meteum. Accurate to home
Today we are announcing a new technology Meteum - now with its help Yandex.Pogoda will build its own weather forecast, and not rely only on the data of partners, as it was before.
Moreover, the forecast will be calculated separately for each point from which you request it, and recalculated every time you look at it, to be as up-to-date as possible.

')
In this post I want to tell a little about how the world of weather models is arranged in our time, how our approach differs from the usual ones, why we decided to build our own forecast and why we believe that we will succeed better than everyone else.
We built our own forecast using the traditional atmospheric model and the most detailed grid, but also tried to collect all possible sources of data on atmospheric conditions, statistics on how the weather behaves in practice, and applied machine learning to this data to reduce the likelihood of errors.
Now in the world there are several basic models that predict the weather. For example, the open source model WRF , the GFS model, which was originally an American development. Now NOAA is engaged in its development.
The WRF model is supported and developed by scientists around the world, but it also has an official version — its development and support is handled by the American scientific institute NCAR , located in Boulder, Colorado. Initially, the WRF developed as two parallel branches - ARW and NMM , now abolished. GFS and WRF models have a slightly different development vector (GFS distributes global and US-oriented products). WRF is primarily a local model that can be customized for a specific terrain.
At its core, WRF is an open source program written in Fortran (see box) and reflecting the current understanding by scientists of the laws of physics and the dynamics of the atmosphere and, accordingly, the weather. Like any self-respecting representative of open source software, WRF does not work out of the box. That is, probably, most linuksoids will be able to run it, but only after a fair amount of time spent on reading manuals and compiling. In this case, the quality of weather predictions using the raw version can be unpleasantly surprising. WRF was created to describe a complex dynamic system - the atmosphere of the Earth, and therefore needs to be carefully tuned.
The whole process of the model can be divided into two conditional parts: the prediction of physics and the prediction of dynamics. The WRF physical modules track the amount of heat that is released and absorbed in the atmosphere, as well as the formation of precipitation at the right time and place. Dynamics is the movement of air masses, the wind rose, the formation of cyclones and so on. For physics, there is a set of semi-empirical models, one for one process or another, for dynamics, a parameterized version of the Euler equation .
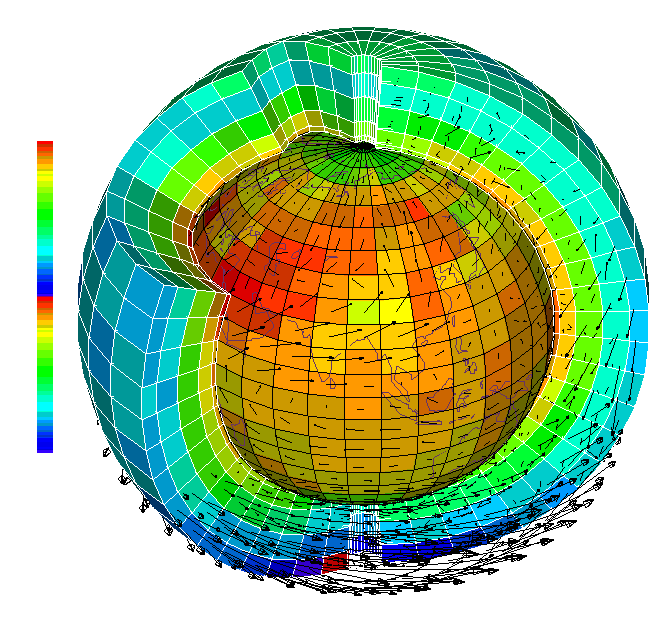
The picture shows a slice of the calculated model grid. The results of the temperature calculations are displayed in the color of the cells and are mainly the result of physical processes — heating and cooling. The arrows show the transfer of air masses, that is, the result of the calculation of the dynamics.
The Euler equation is a partial differential equation. It is clear that a computer cannot solve partial differential equations without help. Help in this case is to decompose the equations of the mathematical model into finite-difference schemes. That is, by representing the derivatives as differences, you can get the most correct solution to the equation.
The difficulty, however, is not only to bring the numerical solution as closely as possible to the analytical one that has not yet been found. It is also to adequately parameterize the processes that control the atmosphere from the outside. Solar radiation, thermal radiation of the soil, the influence of greenhouse gases, phase transitions of water vapor - this is an incomplete list of all that needs to be taken into account when trying to predict the weather.
Probably, this task would be very very heavy, if not for observation. During the years in which humanity was interested in future weather conditions (and this is a long time), some experience in conducting atmospheric measurements has accumulated. Such things as weather stations, satellite spectrometers, aircraft instruments, radars, lidars were invented - but what else could it be. The amount of data that is minimally needed to make a forecast at an accuracy level that meets modern standards should use all available information sources: more than 10,000 weather stations around the world, more than 80 satellites in near-earth orbit, about 1,500 stations of radiological sensing.
Now, observations of the atmosphere around the globe, taken at one fixed point in time, are terabytes of station observations, radar scans and satellite imagery. They are few in order to fully describe the current state of the atmosphere, but they can be used to refine the initial conditions of the model.

Some of the atmospheric observation methods available to mankind
Since the accuracy of solving differential equations depends largely on the accuracy of the initial conditions, all observational data are used to compile the most accurate field of atmospheric parameters. To reconcile model calculations and isolated experimental data, there is a data assimilation technology that inherits a sophisticated mathematical apparatus from control theory and calculus of variations . Thus, in addition to numerical models, the data of synchronous observations from orbit and ground stations help us in weather forecasting.
Now our system of computational areas of the numerical model is designed to cover the territory of our vast country with two types of predictions - on a grid with a rough resolution (6 by 6 km) and on a grid with a fine resolution (2 on 2 km). These grids are nested in each other and interact, passing between the data on the boundary and initial conditions.
To calculate, process and store the parameters of the atmosphere on such a scale, huge computational power is needed. The daily volume of incoming forecasts to the repository is more than 10 TB. The weather forecast for 48 hours with a given level of detail for the Moscow region even on Yandex clusters takes about 6 hours.
The weather forecast is calculated every time a user accesses the service. This is dictated not only by the desire to give the most accurate current weather forecast specifically for the coordinates of the user, but also by severe necessity. The fact is that the amount of high-resolution weather data is so large that it will take several hours to predict such a forecast over the territory of our entire country, and not a single runtime base will be able to respond to requests in a reasonable time. This is also true not only for the results of Meteum, but also for some models that are included in its composition. For example, the GFS and WRF models transmit so much information that microservice was organized for their transfer to the API, which, unlike many databases, stores, updates and sends data directly from the memory of machines included in the microservice.

So at one of the early stages of the work, the location of the calculated areas in the central region of the Russian Federation looked like. Red - external domain with a grid of 6 to 6 km, blue - nested areas with higher resolution (2 to 2 km)
The system of receiving, processing and analyzing data, model calculations and their combination in the data assimilation algorithm is a chain of many links. In addition to the correct processing of incoming data, it is necessary to properly configure their assimilation in the initial conditions for differential equations. The theory of data assimilation, the science of the correct combination of observations with predictions of mathematical models, is responsible for the development and physical justification of these algorithms. However, observations of the state of the atmosphere, which we obtain from various sources, may be useful for other purposes.
WRF is the standard of the weather forecasting industry, however there are other models: we receive forecasts made using them from our partners. Despite all the knowledge of mankind about atmospheric processes, satellites and supercomputers, all these models, as you know, are mistaken. It is interesting that in their forecasts there are systematically replicable patterns.
In addition to the WRF model itself, which is calculated on Yandex clusters, we get forecasts for 12,000 cities around the world, made by one of our partners, Foreca. More detailed information about the global state of the atmosphere comes to us from the US model of the Global Forecast System , which is considered one of the most accurate global models in the world and has a resolution of 0.25 degrees.

The behavior of these models in different meteorological situations allows Meteum to more accurately assess the adjustments that need to be made to the forecast and optimally select a combination of source data.
Some of the models of the weather forecast overstate the amount of precipitation on the earth, others lower the night-time temperature within the city. Having at our disposal an archive of model predictions, one can single out a lot of such regularities, including much less obvious than those I mentioned above. It is quite difficult for a person to do this because of the huge amounts of data, but the machine learning algorithms do a great job with this. To identify patterns and relationships between model predictions and the actual meteorological situation, we use the Matriksnet machine learning algorithm that you know.
Matrixnet accepts the input of specially processed archives of weather forecasts and compares them with data on the real meteorological situation. Observations obtained at thousands of professional weather stations around the world are used as real weather data.
As a result of such comparisons, a forecast adjustment formula is obtained, which, depending on the meteorological situation, constitutes the optimal combination of forecasts from the given models provided by our suppliers.

Meteum uses a huge amount of data, and this is just the beginning. For example, in some regions of Russia, accurate meteorological measurements are quite rare.

They are not enough to build a hyperlocal forecast. Therefore, Meteum is able to use a large amount of data indirectly pointing to meteorological conditions. We already use Yandex.Maps data that help us take into account the terrain landscape. I will give one more example. Many phone models have barometers built-in. They are not as accurate as in weather stations, but there are millions of them. And they are distributed where people live. Next year we will start using their data to clarify the actual state of the atmosphere.

In addition, right now in the Yandex.Pogoda applications there is an opportunity to tell you about the weather right now where you are. We initially created Meteum expandable for various classes of data that indirectly indicate the weather, so we can take into account your observations.
Habr's readers, probably, are especially clearly aware that behind the processes described above, there should be an appropriately designed infrastructure.
Real-time model predictions needed for Meteum operation are collected from several different sources. The forecasts of WRF and GFS in microservice weigh more than 60 GB and are updated every minute. And they do it atomically, in large pieces. Such requirements made it impossible to use traditional runtime databases. Foreca's forecasts are stored in PostgreSQL, since their volumes and update frequency are much lower. After processing and displaying to the user, the results of the formula, along with the component parts (supplier forecasts and other factors transferred to Matrixnet), are sent to the MapReduce cluster. This data is subsequently used to verify and further customize the operation of Meteum.
All those processes that we described above occur every time a user logs in to Yandex. Weather. When making a request, you send your geographic coordinates to Meteum. It collects all the data necessary for forecasting, analyzes the meteorological situation, the type of underlying surface and, based on this data, makes its own forecast specifically for your position.

According to our own estimates (alas, there are no independent meters in this area yet), for today our weather forecast is more accurate than all the competitors we know. For example, the temperature forecast for 24 hours, we are mistaken for 35% less than the nearest competitor.
But we understand that the ideal is still far away, and we hope that after a while we will be able to further increase the accuracy, thanks to data from users of the application, as well as additional sources of information about the atmosphere.
Moreover, the forecast will be calculated separately for each point from which you request it, and recalculated every time you look at it, to be as up-to-date as possible.
')
In this post I want to tell a little about how the world of weather models is arranged in our time, how our approach differs from the usual ones, why we decided to build our own forecast and why we believe that we will succeed better than everyone else.
We built our own forecast using the traditional atmospheric model and the most detailed grid, but also tried to collect all possible sources of data on atmospheric conditions, statistics on how the weather behaves in practice, and applied machine learning to this data to reduce the likelihood of errors.
Now in the world there are several basic models that predict the weather. For example, the open source model WRF , the GFS model, which was originally an American development. Now NOAA is engaged in its development.
The WRF model is supported and developed by scientists around the world, but it also has an official version — its development and support is handled by the American scientific institute NCAR , located in Boulder, Colorado. Initially, the WRF developed as two parallel branches - ARW and NMM , now abolished. GFS and WRF models have a slightly different development vector (GFS distributes global and US-oriented products). WRF is primarily a local model that can be customized for a specific terrain.
Part 1. About classical meteorology
At its core, WRF is an open source program written in Fortran (see box) and reflecting the current understanding by scientists of the laws of physics and the dynamics of the atmosphere and, accordingly, the weather. Like any self-respecting representative of open source software, WRF does not work out of the box. That is, probably, most linuksoids will be able to run it, but only after a fair amount of time spent on reading manuals and compiling. In this case, the quality of weather predictions using the raw version can be unpleasantly surprising. WRF was created to describe a complex dynamic system - the atmosphere of the Earth, and therefore needs to be carefully tuned.
Lyrical digression about FORTRAN
It is clear that FORTRAN is probably not the best choice for building large open source systems. But there are two good reasons not to rewrite WRF into other languages. The first - the code, as they say, is time tested: more than one generation of scientists contributed to the formation of a physical model. In addition, this code is widely supported by scientific groups around the world. The second reason is that describing such a complex system as the environment around us requires considerable computational resources. Modern compilers, such as Intel Fortran, allow you to build executable files so that they run with maximum performance.
The whole process of the model can be divided into two conditional parts: the prediction of physics and the prediction of dynamics. The WRF physical modules track the amount of heat that is released and absorbed in the atmosphere, as well as the formation of precipitation at the right time and place. Dynamics is the movement of air masses, the wind rose, the formation of cyclones and so on. For physics, there is a set of semi-empirical models, one for one process or another, for dynamics, a parameterized version of the Euler equation .
The picture shows a slice of the calculated model grid. The results of the temperature calculations are displayed in the color of the cells and are mainly the result of physical processes — heating and cooling. The arrows show the transfer of air masses, that is, the result of the calculation of the dynamics.
The Euler equation is a partial differential equation. It is clear that a computer cannot solve partial differential equations without help. Help in this case is to decompose the equations of the mathematical model into finite-difference schemes. That is, by representing the derivatives as differences, you can get the most correct solution to the equation.
The difficulty, however, is not only to bring the numerical solution as closely as possible to the analytical one that has not yet been found. It is also to adequately parameterize the processes that control the atmosphere from the outside. Solar radiation, thermal radiation of the soil, the influence of greenhouse gases, phase transitions of water vapor - this is an incomplete list of all that needs to be taken into account when trying to predict the weather.
Probably, this task would be very very heavy, if not for observation. During the years in which humanity was interested in future weather conditions (and this is a long time), some experience in conducting atmospheric measurements has accumulated. Such things as weather stations, satellite spectrometers, aircraft instruments, radars, lidars were invented - but what else could it be. The amount of data that is minimally needed to make a forecast at an accuracy level that meets modern standards should use all available information sources: more than 10,000 weather stations around the world, more than 80 satellites in near-earth orbit, about 1,500 stations of radiological sensing.
Now, observations of the atmosphere around the globe, taken at one fixed point in time, are terabytes of station observations, radar scans and satellite imagery. They are few in order to fully describe the current state of the atmosphere, but they can be used to refine the initial conditions of the model.
Some of the atmospheric observation methods available to mankind
Since the accuracy of solving differential equations depends largely on the accuracy of the initial conditions, all observational data are used to compile the most accurate field of atmospheric parameters. To reconcile model calculations and isolated experimental data, there is a data assimilation technology that inherits a sophisticated mathematical apparatus from control theory and calculus of variations . Thus, in addition to numerical models, the data of synchronous observations from orbit and ground stations help us in weather forecasting.
Now our system of computational areas of the numerical model is designed to cover the territory of our vast country with two types of predictions - on a grid with a rough resolution (6 by 6 km) and on a grid with a fine resolution (2 on 2 km). These grids are nested in each other and interact, passing between the data on the boundary and initial conditions.
To calculate, process and store the parameters of the atmosphere on such a scale, huge computational power is needed. The daily volume of incoming forecasts to the repository is more than 10 TB. The weather forecast for 48 hours with a given level of detail for the Moscow region even on Yandex clusters takes about 6 hours.
The weather forecast is calculated every time a user accesses the service. This is dictated not only by the desire to give the most accurate current weather forecast specifically for the coordinates of the user, but also by severe necessity. The fact is that the amount of high-resolution weather data is so large that it will take several hours to predict such a forecast over the territory of our entire country, and not a single runtime base will be able to respond to requests in a reasonable time. This is also true not only for the results of Meteum, but also for some models that are included in its composition. For example, the GFS and WRF models transmit so much information that microservice was organized for their transfer to the API, which, unlike many databases, stores, updates and sends data directly from the memory of machines included in the microservice.
So at one of the early stages of the work, the location of the calculated areas in the central region of the Russian Federation looked like. Red - external domain with a grid of 6 to 6 km, blue - nested areas with higher resolution (2 to 2 km)
The system of receiving, processing and analyzing data, model calculations and their combination in the data assimilation algorithm is a chain of many links. In addition to the correct processing of incoming data, it is necessary to properly configure their assimilation in the initial conditions for differential equations. The theory of data assimilation, the science of the correct combination of observations with predictions of mathematical models, is responsible for the development and physical justification of these algorithms. However, observations of the state of the atmosphere, which we obtain from various sources, may be useful for other purposes.
Part 2. About machine learning
WRF is the standard of the weather forecasting industry, however there are other models: we receive forecasts made using them from our partners. Despite all the knowledge of mankind about atmospheric processes, satellites and supercomputers, all these models, as you know, are mistaken. It is interesting that in their forecasts there are systematically replicable patterns.
In addition to the WRF model itself, which is calculated on Yandex clusters, we get forecasts for 12,000 cities around the world, made by one of our partners, Foreca. More detailed information about the global state of the atmosphere comes to us from the US model of the Global Forecast System , which is considered one of the most accurate global models in the world and has a resolution of 0.25 degrees.
The behavior of these models in different meteorological situations allows Meteum to more accurately assess the adjustments that need to be made to the forecast and optimally select a combination of source data.
Some of the models of the weather forecast overstate the amount of precipitation on the earth, others lower the night-time temperature within the city. Having at our disposal an archive of model predictions, one can single out a lot of such regularities, including much less obvious than those I mentioned above. It is quite difficult for a person to do this because of the huge amounts of data, but the machine learning algorithms do a great job with this. To identify patterns and relationships between model predictions and the actual meteorological situation, we use the Matriksnet machine learning algorithm that you know.
Matrixnet accepts the input of specially processed archives of weather forecasts and compares them with data on the real meteorological situation. Observations obtained at thousands of professional weather stations around the world are used as real weather data.
As a result of such comparisons, a forecast adjustment formula is obtained, which, depending on the meteorological situation, constitutes the optimal combination of forecasts from the given models provided by our suppliers.
Meteum uses a huge amount of data, and this is just the beginning. For example, in some regions of Russia, accurate meteorological measurements are quite rare.
They are not enough to build a hyperlocal forecast. Therefore, Meteum is able to use a large amount of data indirectly pointing to meteorological conditions. We already use Yandex.Maps data that help us take into account the terrain landscape. I will give one more example. Many phone models have barometers built-in. They are not as accurate as in weather stations, but there are millions of them. And they are distributed where people live. Next year we will start using their data to clarify the actual state of the atmosphere.
In addition, right now in the Yandex.Pogoda applications there is an opportunity to tell you about the weather right now where you are. We initially created Meteum expandable for various classes of data that indirectly indicate the weather, so we can take into account your observations.
Part 3. Behind blue eyes
Habr's readers, probably, are especially clearly aware that behind the processes described above, there should be an appropriately designed infrastructure.
Real-time model predictions needed for Meteum operation are collected from several different sources. The forecasts of WRF and GFS in microservice weigh more than 60 GB and are updated every minute. And they do it atomically, in large pieces. Such requirements made it impossible to use traditional runtime databases. Foreca's forecasts are stored in PostgreSQL, since their volumes and update frequency are much lower. After processing and displaying to the user, the results of the formula, along with the component parts (supplier forecasts and other factors transferred to Matrixnet), are sent to the MapReduce cluster. This data is subsequently used to verify and further customize the operation of Meteum.
Part 4. Total Runtime
All those processes that we described above occur every time a user logs in to Yandex. Weather. When making a request, you send your geographic coordinates to Meteum. It collects all the data necessary for forecasting, analyzes the meteorological situation, the type of underlying surface and, based on this data, makes its own forecast specifically for your position.
Part 5. What happened
According to our own estimates (alas, there are no independent meters in this area yet), for today our weather forecast is more accurate than all the competitors we know. For example, the temperature forecast for 24 hours, we are mistaken for 35% less than the nearest competitor.
But we understand that the ideal is still far away, and we hope that after a while we will be able to further increase the accuracy, thanks to data from users of the application, as well as additional sources of information about the atmosphere.
Source: https://habr.com/ru/post/271725/
All Articles