Machine Learning Hackathon: Come. To train a model. To win
Standard plan of any hackathon ↓

This weekend will be held on hackathon machine learning , organized by the company Microsoft. Participants of the hackathon will have 2 days in order not to sleep well and make the world a better place.
')
The story in this article will be held in the same impetuous manner in which, I believe, for the majority of the participants, the hackathon will pass. No water (if you are not familiar with Azure ML, then it is better to read “water” or some introductory material), long definitions and such long introductions as this is just what you need to win at the hackathon.
one)Grab Find a coffee machine.
2) You have only 2 days, so do notto make a fuss complex models: they are easily retrained and do them for a long time. Take the most naive assumption and iteratively complicate it. At each successful iteration, save a set of data supplied to the machine learning algorithm and the resulting model. This is done using the “Save as Dataset”, “Save Model” menu items in the context menu of Azure ML Studio (this is the web IDE). This way you will have dataset – trained_model pairs for each of the iterations.
Create already Workspace! Open manage.windowsazure.com, select Azure ML and create a faster Workspace. One for the whole team, and not for everyone his personal! Collect email from all participants and expand the Workspace between them.

Contribute to global warming
Below is what the simplest learning graph in Azure ML looks like.
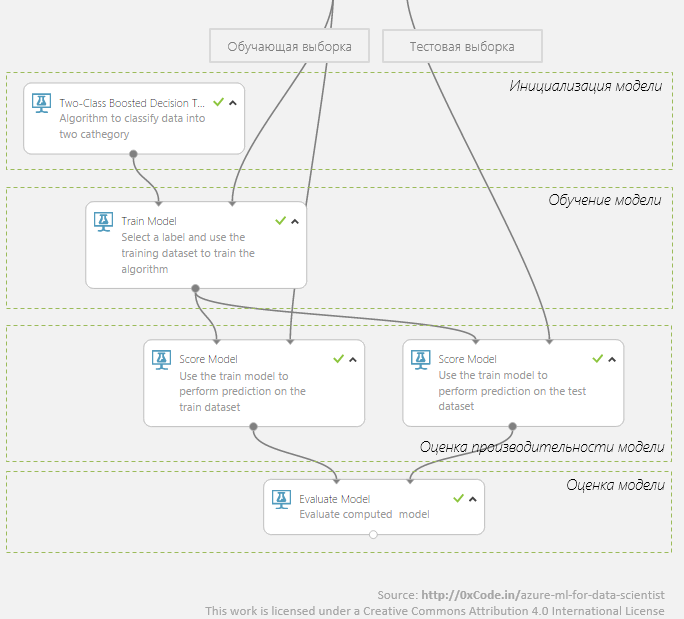
But it is not that! So you will do at home: run, drink tea, go for a walk, come, watch what happened, think, scratch your shoulder, start again, drink tea ... There is no time for this hackathon!
Check at once all the algorithms that may come up. “Everything” is Azure, not your home laptop! Azure datacenters will warm the atmosphere of the west coast of the United States, but the process of learning models will perform! Here is an example of what this should look like on 5 algorithms of two-class classification.

Comparison of models trained on the logistic regression algorithm (blue curve) and the support vector machine (red curve):

Cross validation
Include already cross-validation! And turn it on correctly: with validation dataset, with folds, with indication of the metric you want to maximize (that is, as shown in the illustration with cross-validation).
By enabling cross-validation, you will find out what potential best results can show the machine learning algorithm on your data, and understand how stable this algorithm is (the smaller the standard deviation, the more stable the algorithm shows).
Results for each fold:

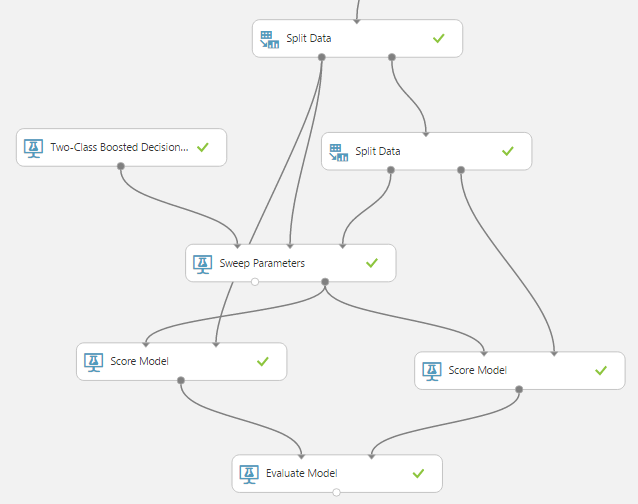
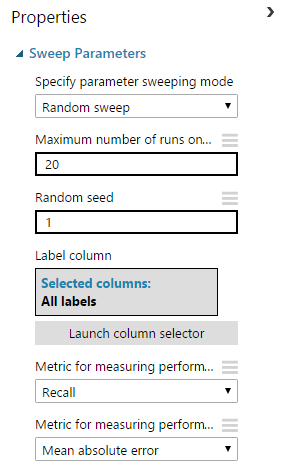
Sweep parameters
The key impact on the performance of the model is provided by the parameters of the machine learning algorithm. So for a neural network, this is the number of hidden layers of neurons, the initial weights, for a decision tree, the number of trees, the number of leaves per tree.
You will be engaged in the new year (and maybe in time) by manually searching several parameters for 4 classification algorithms, in the conditions of a gushing fountain of new ideas. Make the new year something else! And on the hackathon use the built-in module Sweep Parameters.
Module settings:

Fair data split
Separate the test and training sets (Split module). Depending on the amount of available data in data science, it is customary to leave in the test set from 10% to 30% of the data. Notengage in self-deception teach the model on a test suite, do not use it to check the results of cross-validation. You only need a test dataset for one thing - check the final model.
Speed up learning
The faster your model is in time to study, the more hypotheses you will have time to test. Use modules from the Feature Selection section to not only reduce training time, but also to get the most relevant predictors and generalize the model (to make its performance better with real data).
So, using the filter-based feature selection module in the task of determining the tonalities of tweets, I reduced the number of predictors from 160K to 20K.
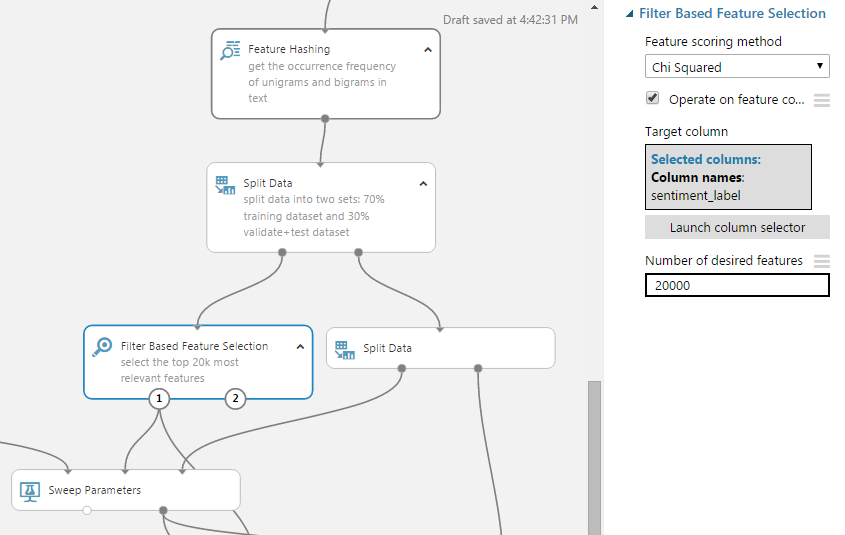
Result - see the number of predictors (columns) before and after filtering:


And the fisher linear discriminant module helped me reduce Iris Dataset from the 4xN matrix to 2xN, where N is the number of observations.
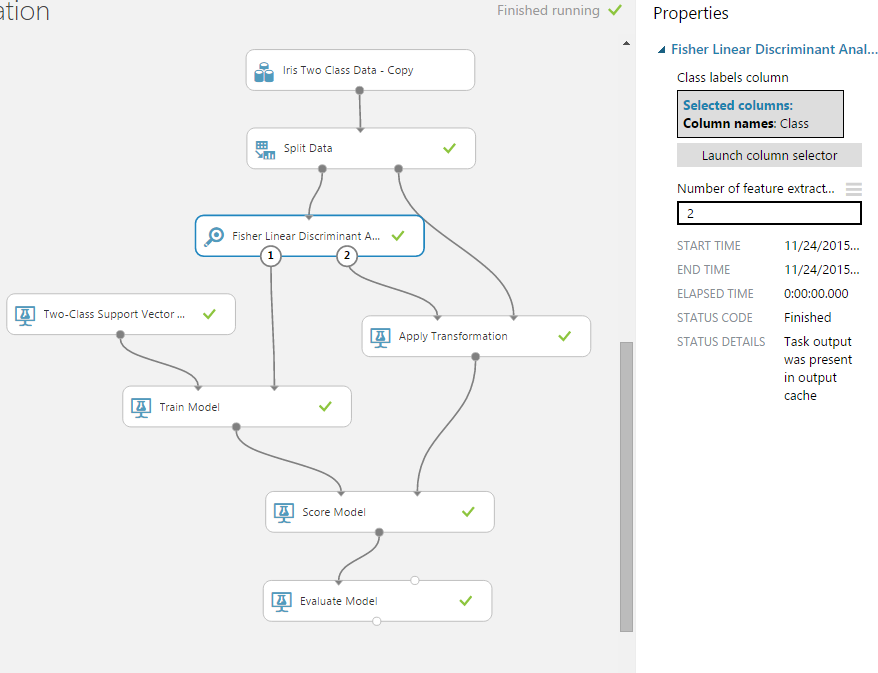
Result - see the number of predictors (columns) before and after filtering:


Accelerate learning. Part 2
Azure ML can execute your R / Python scripts. So out of the box there is support for ~ 400 R-packages, export to Python Notebooks and this is just the beginning.
But (!) Do not write R / Python-scripts simply because you are too lazy to understand which module in Azure ML does the same thing. Built-in modules:
Without pleading your programming talent, I note that your wonderfully written python script is unlikely to be executed this way, because for Azure ML, such a script is a black box.
Feature Engineering
Understand your data! To do this, Azure ML has both visualization tools and the ability to use ggplot2. In addition, do not neglect the Descriptive Statistics module of descriptive statistics, which at any stage of the experiment can tell you a lot about the data.
Pre-processing
Mark the data correctly - use the Metadata Editor module.
The Clean Missing Data module will help you cope with the missing data (delete them, replace them with the default value, median or mode).
Anomaly Detection section and simple visualization will help detect outliers.
Normalize (at least try) all the numeric data, whose distribution is different from the normal, using the Normalize module. Using the same module, scale (scale) all numeric data whose absolute values are large.
Jedi technology
Jedi Techniques: Boosting and Stacking
Go to the terminology:
Boosting is an approach in which the result is a weighted / empirically calculated estimate of several different models.
Stacking is an approach similar to boosting: you also have several models trained in data, but you no longer have any empirical formula — you are building a metamodel based on estimates of the initial models.
These are very cool techniques that use data scientists of level 80 with kaggle to the fullest. Azure ML does not have any built-in modules implementing boosting or stacking (or just bagging). Their implementation is not very difficult, but it has its long list of subtleties.
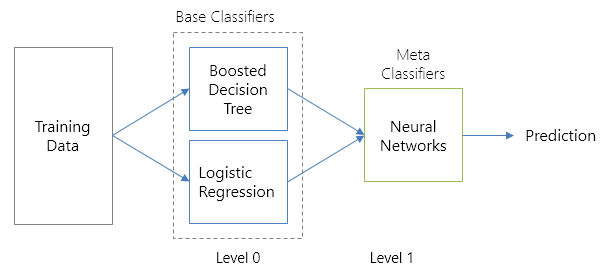
Here's how my application of stacking looks like to create a metamodel trained using a neural network on the Boosted Decision Tree classifiers and logistic regression.
Schematic diagram of implemented stacking:
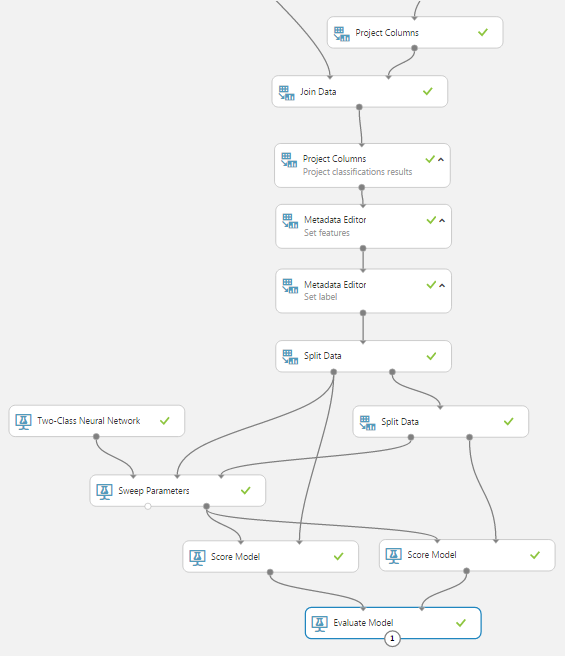
Level 1:

Level 2:
Implementing the boosting and stacking approaches in Azure ML is a topic for a separate interesting article that cannot be covered in this article. But (!) On the second day of the hackathon you can find me (the bottom right on the page of the hackathon speakers ; I will look as bad as in the photo), and I will definitely show how to add stacking to your model and possibly improve its performance on important ones. such events are a couple-five percent.
Jedi techniques: Hadoop / HBase / Spark-cluster
I'm not kidding: you need a cluster! But do not rush to buy hardware and start to deploy / administer the entire Hadoop ecosystem rich in software products. It is long, expensive and ... good. And we need to quickly and well, i.e. HDInsight.
Azure HDInsight is a cloud service that provides a Hadoop / HBase / Spark cluster on demand. Passing the cluster creation wizard takes 2 minutes, the cluster creation itself goes to Azure1 coffee mug ~ 10 minutes.
But the most delicious thing is that HBase (if exactly, Hive requests) is supported as one of the data sources in Azure ML. So if there is a lot of data and you need to make complex queries on them, then without hesitation, deploy the HBase cluster to Azure and upload the data to Azure ML directly from there.
Jedi Techniques: Data Science VM
Use one of the virtual machine images available in Azure VM — the “Data Science VM” image with the pre-installed Revolution R Open, Anaconda Python, Power BI, and more .
Do not limit yourself to a loved one: take a virtual machine with the right amount of memory (up to 448 GB of RAM is available), the number of cores (up to 32-cores), and, if necessary, an SSD-drive. In general, create a comfortable working environment.
Participate not for prizes
A hackathon is an event for which one should go for the sake of the atmosphere, for the sake of communication with like-minded people, acquaintances with experts, free coffee and, if it's cold outside, but there is no place to live. Communicate, share experiences! (The trickiest will win anyway.)
By the way about communication, tomorrow Moscow Data Science Meetup will be held - the most outstanding event in the most pleasant format for data scientists and those who are interested in this area.
This weekend will be held on hackathon machine learning , organized by the company Microsoft. Participants of the hackathon will have 2 days in order not to sleep well and make the world a better place.
')
The story in this article will be held in the same impetuous manner in which, I believe, for the majority of the participants, the hackathon will pass. No water (if you are not familiar with Azure ML, then it is better to read “water” or some introductory material), long definitions and such long introductions as this is just what you need to win at the hackathon.
Keep it simple
one)
2) You have only 2 days, so do not
About the structure of the article
This is more or less the standard workflow of learning with a teacher. I will begin with the most delicious - from the heart of this process - the training model ( Train model ), gradually moving to the Pre-processing data stage.

Collaboration
Create already Workspace! Open manage.windowsazure.com, select Azure ML and create a faster Workspace. One for the whole team, and not for everyone his personal! Collect email from all participants and expand the Workspace between them.
Contribute to global warming
Below is what the simplest learning graph in Azure ML looks like.
But it is not that! So you will do at home: run, drink tea, go for a walk, come, watch what happened, think, scratch your shoulder, start again, drink tea ... There is no time for this hackathon!
Check at once all the algorithms that may come up. “Everything” is Azure, not your home laptop! Azure datacenters will warm the atmosphere of the west coast of the United States, but the process of learning models will perform! Here is an example of what this should look like on 5 algorithms of two-class classification.
Comparison of models trained on the logistic regression algorithm (blue curve) and the support vector machine (red curve):
Cross validation
Include already cross-validation! And turn it on correctly: with validation dataset, with folds, with indication of the metric you want to maximize (that is, as shown in the illustration with cross-validation).
By enabling cross-validation, you will find out what potential best results can show the machine learning algorithm on your data, and understand how stable this algorithm is (the smaller the standard deviation, the more stable the algorithm shows).
Results for each fold:
Sweep parameters
The key impact on the performance of the model is provided by the parameters of the machine learning algorithm. So for a neural network, this is the number of hidden layers of neurons, the initial weights, for a decision tree, the number of trees, the number of leaves per tree.
You will be engaged in the new year (and maybe in time) by manually searching several parameters for 4 classification algorithms, in the conditions of a gushing fountain of new ideas. Make the new year something else! And on the hackathon use the built-in module Sweep Parameters.
Module settings:
Fair data split
Separate the test and training sets (Split module). Depending on the amount of available data in data science, it is customary to leave in the test set from 10% to 30% of the data. Not
Speed up learning
The faster your model is in time to study, the more hypotheses you will have time to test. Use modules from the Feature Selection section to not only reduce training time, but also to get the most relevant predictors and generalize the model (to make its performance better with real data).
So, using the filter-based feature selection module in the task of determining the tonalities of tweets, I reduced the number of predictors from 160K to 20K.
Result - see the number of predictors (columns) before and after filtering:
And the fisher linear discriminant module helped me reduce Iris Dataset from the 4xN matrix to 2xN, where N is the number of observations.
Result - see the number of predictors (columns) before and after filtering:
Accelerate learning. Part 2
Azure ML can execute your R / Python scripts. So out of the box there is support for ~ 400 R-packages, export to Python Notebooks and this is just the beginning.
But (!) Do not write R / Python-scripts simply because you are too lazy to understand which module in Azure ML does the same thing. Built-in modules:
- Optimized for Azure ML (most likely most of them are written in C ++, which sounds like “this is fast”);
- the work inside them is potentially parallelized and is distributed (since it is known in advance which modules perform parallel tasks and which ones do not);
- machine learning algorithms implemented in embedded modules can also potentially be LSML history (run distributed on a cluster).
Without pleading your programming talent, I note that your wonderfully written python script is unlikely to be executed this way, because for Azure ML, such a script is a black box.
Feature Engineering
Understand your data! To do this, Azure ML has both visualization tools and the ability to use ggplot2. In addition, do not neglect the Descriptive Statistics module of descriptive statistics, which at any stage of the experiment can tell you a lot about the data.
Pre-processing
Mark the data correctly - use the Metadata Editor module.
The Clean Missing Data module will help you cope with the missing data (delete them, replace them with the default value, median or mode).
Anomaly Detection section and simple visualization will help detect outliers.
Normalize (at least try) all the numeric data, whose distribution is different from the normal, using the Normalize module. Using the same module, scale (scale) all numeric data whose absolute values are large.
Jedi technology
Jedi Techniques: Boosting and Stacking
Go to the terminology:
Boosting is an approach in which the result is a weighted / empirically calculated estimate of several different models.
Stacking is an approach similar to boosting: you also have several models trained in data, but you no longer have any empirical formula — you are building a metamodel based on estimates of the initial models.
These are very cool techniques that use data scientists of level 80 with kaggle to the fullest. Azure ML does not have any built-in modules implementing boosting or stacking (or just bagging). Their implementation is not very difficult, but it has its long list of subtleties.
Here's how my application of stacking looks like to create a metamodel trained using a neural network on the Boosted Decision Tree classifiers and logistic regression.
Schematic diagram of implemented stacking:
Level 1:
Level 2:
Implementing the boosting and stacking approaches in Azure ML is a topic for a separate interesting article that cannot be covered in this article. But (!) On the second day of the hackathon you can find me (the bottom right on the page of the hackathon speakers ; I will look as bad as in the photo), and I will definitely show how to add stacking to your model and possibly improve its performance on important ones. such events are a couple-five percent.
Jedi techniques: Hadoop / HBase / Spark-cluster
I'm not kidding: you need a cluster! But do not rush to buy hardware and start to deploy / administer the entire Hadoop ecosystem rich in software products. It is long, expensive and ... good. And we need to quickly and well, i.e. HDInsight.
Azure HDInsight is a cloud service that provides a Hadoop / HBase / Spark cluster on demand. Passing the cluster creation wizard takes 2 minutes, the cluster creation itself goes to Azure
But the most delicious thing is that HBase (if exactly, Hive requests) is supported as one of the data sources in Azure ML. So if there is a lot of data and you need to make complex queries on them, then without hesitation, deploy the HBase cluster to Azure and upload the data to Azure ML directly from there.
Jedi Techniques: Data Science VM
Use one of the virtual machine images available in Azure VM — the “Data Science VM” image with the pre-installed Revolution R Open, Anaconda Python, Power BI, and more .
Do not limit yourself to a loved one: take a virtual machine with the right amount of memory (up to 448 GB of RAM is available), the number of cores (up to 32-cores), and, if necessary, an SSD-drive. In general, create a comfortable working environment.
Look over your shoulder. Build conspiracies. Find the oil!
Participate not for prizes
A hackathon is an event for which one should go for the sake of the atmosphere, for the sake of communication with like-minded people, acquaintances with experts, free coffee and, if it's cold outside, but there is no place to live. Communicate, share experiences! (The trickiest will win anyway.)
By the way about communication, tomorrow Moscow Data Science Meetup will be held - the most outstanding event in the most pleasant format for data scientists and those who are interested in this area.
Source: https://habr.com/ru/post/271697/
All Articles