Developing your own solution: risks and responsibilities
Hi, Habr! This article will discuss how we at Mail.Ru Group approach code writing; when to use ready-made solutions, and when it is better to write yourself; Well, and most importantly - what steps need to be done so that your work does not prove fruitless and benefits others. All these nuances will be considered on the example of the task of creating our internal JSSDK, which arose because of the need to merge the code base of the two projects.

Michael Parkes illustration
We constantly hear that reinventing bicycles is bad, but where is the line between the bicycle and the finished product? At what stage did Backbone , Ember or Angular cease to be? This is rarely talked about. It so happened that for the last four years I have been continuously developing various kinds of “bicycles” - not because I like it (and I really like it), just some solutions are outdated, others are tied to a specific technology (for example, on the same jQuery ), not necessary to us, and tearing off which is equivalent to writing from scratch. But the main problem lies in the narrow specialization and lack of opportunities for expansion. There are a lot of solutions on the same githaba, but not everyone has a future. Therefore, if you decide to urgently accomplish the task, having written what you think is an excellent thing, then do not waste time and take pity on other people who need to support this after you. With a 99% chance they will overwrite everything. So when can and even need to reinvent your own bike?
Start with the task, evaluate it:
These simple points apply to almost any task, be it the development of a framework or a jQuery plugin.
')
Our story began three years ago: the task was to “develop mail for touch devices”, which required choosing a technology on the basis of which everything was done. There were three options:
It was not possible to use the big mail code - 17 years of history make themselves known. Therefore, it remains to either write by yourself or look for ready-made tools. Developing a framework for such a task is very difficult, even taking into account our experience, this one has practically no potential, since it is very likely that this will be a highly specialized solution that is strictly tied to the wheelbarrow. Approximately imagining what we need, we chose the appropriate solutions for our task (and most importantly - the teams):
These simple tools allowed us to quickly develop a project and begin its implementation. Everything was good, until the touch-mail started to catch up with a lot of functionality. Because of this, many product features were made twice - first at the big post, and then at touch.mail.ru, although the differences in implementation were minimal and were configurable. The situation was aggravated by the introduction of a new backend API, which was no longer enough just to "pull and get" the answer:
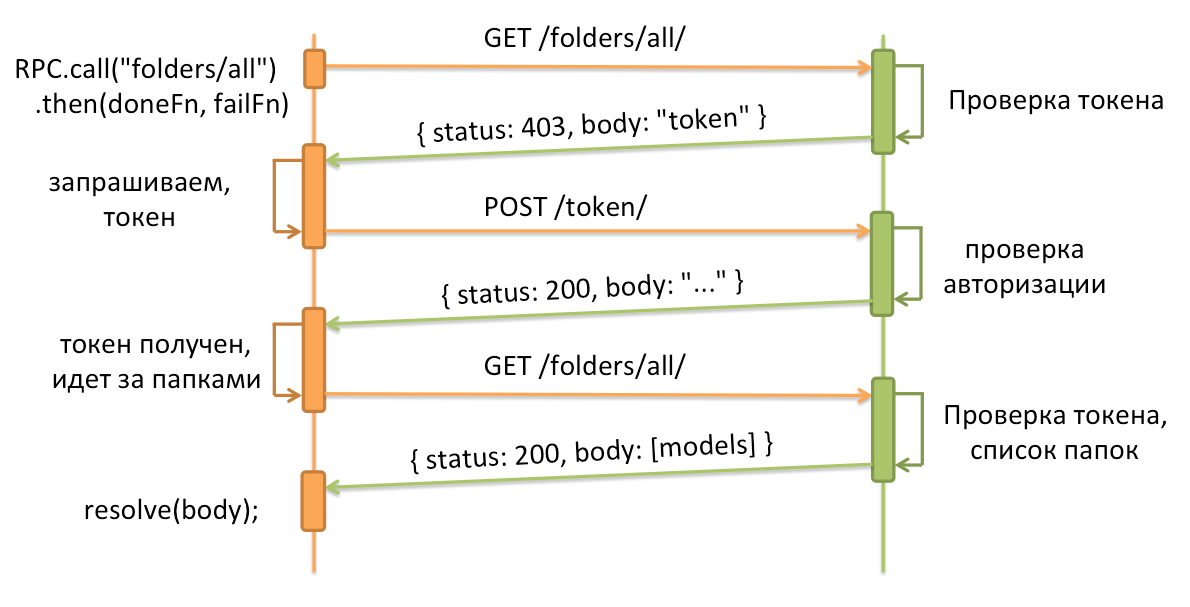
Having looked at all this, we decided that it was impossible to continue to live like this - double development, double bugs, double testing, again bugs ... And there are other internal projects that want to integrate some piece of Mail functionality.
Everything spoke of the need for a common code base, which would be located in a separate repository, and within which the common components would be implemented.
Summing up our knowledge of projects, we have defined a basic set of packages:
Next thing is small: on what to build these components:
To answer this question, for myself, I formulated the following steps:
The first thing to start with is, of course, the definition of the requirements for a solution. This should be a list of features required for a specific task (which you have already sorted out before), plus extensibility. Do not engage in overengineering, since it will not lead to anything good, but will only confuse and lead you away from the goal.
So, the first thing was to decide what to do with the models, on the basis of what to build them. However, please note that the solution must have the following capabilities:
As I said, touch-mail, as well as a number of other projects built on Backbone, is a good foundation that gives you Emitter, Model, Collection, Router and View. This can cover all our needs.
Everything rested only on the big mail, which was not Backbone, but those models that were, had a similar interface (get / set).
As you can see, it turned out that the basic capabilities that have a big mail, was not in Backbone. But! Backbone is a well-established tool, time-tested and has a huge community and active support, so almost any missing features can be covered with an extension that has long been written and tested.
So the dot notation can be obtained by using:
To implement getters there are https://github.com/asciidisco/Backbone.Mutators (but only with get).
And so on. Alas, no matter how I searched, I could not find an extension to support the “integrity of the model” out of the box, when such an opportunity was the cornerstone of a large mail.
Consider an example of receiving a letter:
At first glance, the problem can be corrected by modifying, for example, the findOne method, so that it remembers the promise and returns it:
But besides searching for models by id, there is also a list of models (collections). And wherever I get a collection, it must consist of references to instances of the same models, to maintain integrity at any point in the application.
Of course, this can be wound on top of Backbone, but the problem is not only this. For example, after executing any collection method, we get an array on output.
So in order for Backbone to do what we want, we need to:
Even if it were possible to find some extensions that realize the necessary capabilities, I would not risk building anything on this hodgepodge - the likelihood of bugs and conflicts between these extensions, as well as a significant performance failure, is very high. Such capabilities should be integrated into the core of the framework itself.
Well, well, we will write the models ourselves. Let's try to find at least solutions for other components. (It was still possible to fork Backbone, such as Parse.com , and I even planned it, but the scope of our changes is comparable to the volume of the models themselves.)
Going to github and setting the “ Event Emitter ”, you will find the following libraries:
As you can see, none of them support such things as handleEvent and the event object, and they are not very productive in speed. But in general, are suitable and can be used as a turnkey solution.
Q, when and others - not only promises, but also a car and a cart of different functional, but we need only promises. So Native + polyfil are perfect if not for one big but: native promises are incompatible with jQuery (all because of this piece of code).
Here is a boundless sea of solutions, which, all as one, are similar and do not have:
The closest fit option is jQuery.ajax only.
So, every solution we found for various reasons does not fit our requirements. For example:
Of course, you could take one of the solutions, cut yourself off by the possibilities and get involved in jQuery. But these modules are not so voluminous, and the presence of jQuery did not inspire optimism.
And at this moment we return to point number 4: If nothing has come up to you, then are you ready ...
Are you ready ...
The last point may seem strange to someone, but do not rush - in fact this is an important point. In fact, it doesn’t matter to the business that you are under the hood - it is concerned about profit (I’m talking now in general), so if you insisted and even managed to seize the time for implementation, the support will be at your expense, and it will be honest - this was your choice, your decision. Many people underestimate this point, and it seems to me that this is why the githab was filled with decisions whose support died the very next day. You need to be ready for two or three tasks a week (and then a day), and what is the maximum for you will be thanked for what is already good (and this is not counting the bugs that will be, even with tests).
So you have decided where to start? The main thing is not to code! You need to start with the project infrastructure.
Remember that each of the items solves a specific problem and outlines the rules that will guide users.
For us, I chose the following stack :
Comes on github and sees:
As you can see, here are the steps that the developer needs to perform if he wants to use or develop the project.
We proceed directly to the development.
In JSSDK, each module is a separate folder containing four files. For example, Model:
As I already wrote, automate everything that can be automated. Therefore, to create a module, we have a separate grunt task.
So, for example, the creation of the mail.Folder model, which inherits the RPCModel, will look like:
When developing, first of all tests are written and only then the code. After making changes or writing a new module, the most interesting part begins - commit and push:

If the task executes with an error, then commit or push will not work, it allows you to keep the code in the master always working. Zavomit non-working code can only be in a branch other than master. In any other thread, errors will simply be displayed. Also, a push may not pass from a weak test coverage. Weakly consider everything that is less than 100% (currently it is 1,635 assertions).
Coverage tests - not a panacea for all ills, it does not give a 100% guarantee of the absence of bugs. The main thing that gives coverage is the ability to assess how much your tests affect all the possibilities, and sometimes allows you to rethink the final implementation of a particular piece of code.
The developer starts
But the code itself and its coverage:

The final touch is the generation of documentation. For this we use the official JSDoc3 and our publisher (in fact, npm is full of similar solutions). The final documentation exists in two forms, it is:
This is what the module's README.md looks like:

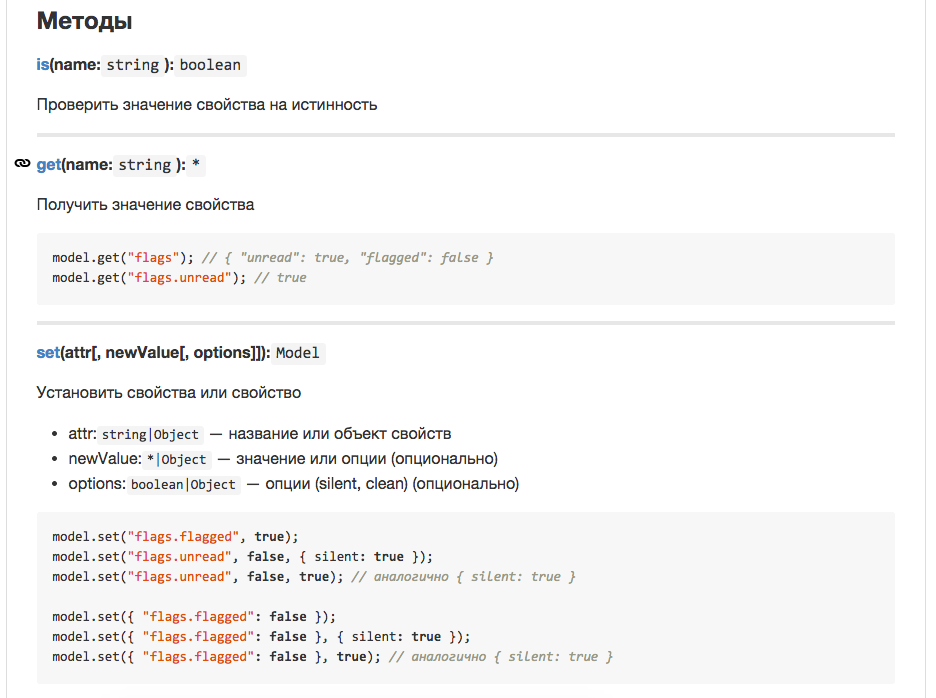
Here we immediately see examples and descriptions of methods, as well as references to impurities. Each item can be given a link, in addition, by clicking on the name of the method, you can quickly go to the code.
README.md is convenient because it can be viewed from anywhere, without any additional effort. But for everyday use, there is also a web interface for viewing documentation that can be picked up locally. It looks like this:
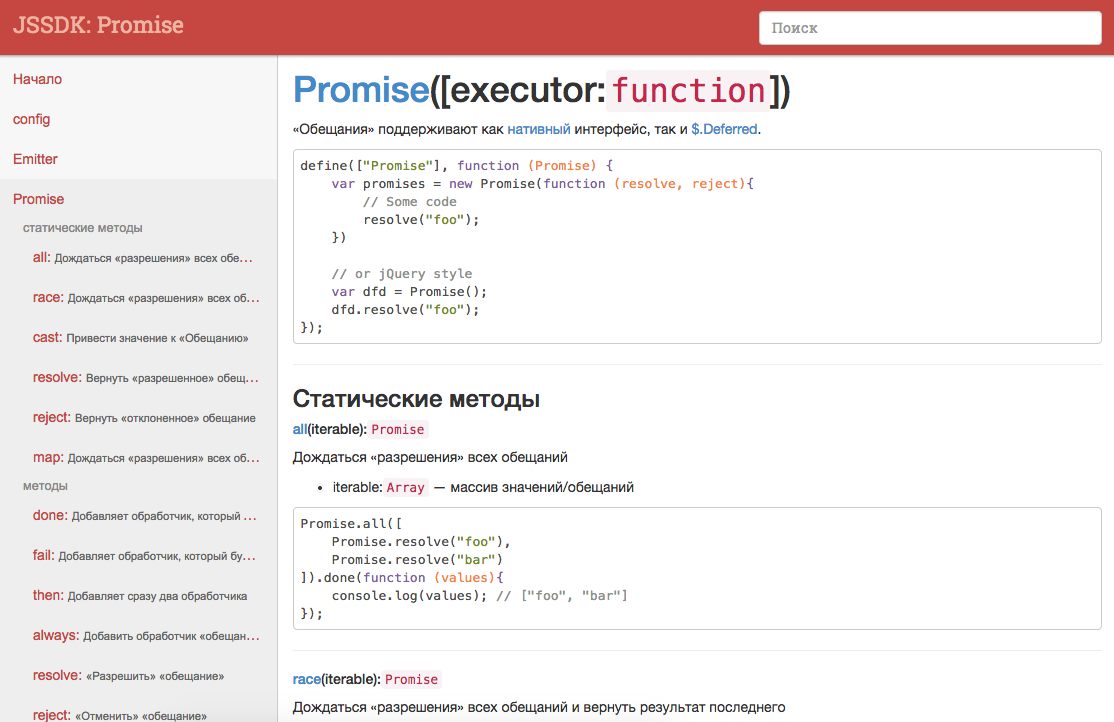
All content is based on md-files, so it is also always relevant. But the most important thing is a one-page application that has a kind of fuzzy search, which allows you to quickly switch to the desired method.

The main thing is that all this not only does not slow down the development process, but also helps a lot. There is an opinion that tests and documentation take time. Sometimes it seems to me that those who have not tried to write them say so. But let's not talk about it. Personally, they allowed me to not only improve the quality of the code, but also significantly reduce development time. The second common myth is that comments are not needed by the code, since the code must be expressive and speak for itself ... Yes, that's right, but in most cases it is simpler and, most importantly, faster to read like a human being than to build an interpreter.
In conclusion, I will say it again: always look for a ready-made solution! If nothing good is found, think about how to change the task. If you decide to write from scratch - do everything possible so that the decision could live without your participation. And most importantly - write tools, not bicycles. Test and document! Thanks for attention.
Michael Parkes illustration
We constantly hear that reinventing bicycles is bad, but where is the line between the bicycle and the finished product? At what stage did Backbone , Ember or Angular cease to be? This is rarely talked about. It so happened that for the last four years I have been continuously developing various kinds of “bicycles” - not because I like it (and I really like it), just some solutions are outdated, others are tied to a specific technology (for example, on the same jQuery ), not necessary to us, and tearing off which is equivalent to writing from scratch. But the main problem lies in the narrow specialization and lack of opportunities for expansion. There are a lot of solutions on the same githaba, but not everyone has a future. Therefore, if you decide to urgently accomplish the task, having written what you think is an excellent thing, then do not waste time and take pity on other people who need to support this after you. With a 99% chance they will overwrite everything. So when can and even need to reinvent your own bike?
Start with the task, evaluate it:
- potential (is there a scope and development prospects, perhaps tomorrow it will not be necessary anymore);
- generalization (possibility of application in other tasks and projects);
- alienability (independence from internal infrastructure).
These simple points apply to almost any task, be it the development of a framework or a jQuery plugin.
')
Our story began three years ago: the task was to “develop mail for touch devices”, which required choosing a technology on the basis of which everything was done. There were three options:
- use the best practices of the mail;
- take a popular framework;
- write by yourself.
It was not possible to use the big mail code - 17 years of history make themselves known. Therefore, it remains to either write by yourself or look for ready-made tools. Developing a framework for such a task is very difficult, even taking into account our experience, this one has practically no potential, since it is very likely that this will be a highly specialized solution that is strictly tied to the wheelbarrow. Approximately imagining what we need, we chose the appropriate solutions for our task (and most importantly - the teams):
- Grunt - project build;
- RequireJS - organization of modules;
- Backbone - model, view, routing;
- Fest - template engine.
These simple tools allowed us to quickly develop a project and begin its implementation. Everything was good, until the touch-mail started to catch up with a lot of functionality. Because of this, many product features were made twice - first at the big post, and then at touch.mail.ru, although the differences in implementation were minimal and were configurable. The situation was aggravated by the introduction of a new backend API, which was no longer enough just to "pull and get" the answer:
Having looked at all this, we decided that it was impossible to continue to live like this - double development, double bugs, double testing, again bugs ... And there are other internal projects that want to integrate some piece of Mail functionality.
Everything spoke of the need for a common code base, which would be located in a separate repository, and within which the common components would be implemented.
Summing up our knowledge of projects, we have defined a basic set of packages:
- Emitter - event emitter;
- Promise - promises;
- Request - sending HTTP requests to the server;
- RPC - is responsible for the logic of working with the server API;
- Model - model class;
- RPCModel - an extended model for working through RPC;
- Model.List - class for working with the list of models (collection).
Next thing is small: on what to build these components:
- choose ready libraries / frameworks;
- write by yourself.
To answer this question, for myself, I formulated the following steps:
- drawing up a list of ready-made solutions (even those that are not fully suitable);
- studying the list (about a week, then look at the code, support, tasks on github, if any, etc.);
- if the solution does not fit the task, we try to change the task (we go to the manager / designer, we offer an alternative, but not “this is impossible, all fools”);
- if nothing came up, are you ready ... (more on that later).
Search for ready-made solutions
The first thing to start with is, of course, the definition of the requirements for a solution. This should be a list of features required for a specific task (which you have already sorted out before), plus extensibility. Do not engage in overengineering, since it will not lead to anything good, but will only confuse and lead you away from the goal.
So, the first thing was to decide what to do with the models, on the basis of what to build them. However, please note that the solution must have the following capabilities:
- Dot notation - access to model properties through dot notation, for example, model.get ('foo.bar.baz');
- Getters - access to properties without `get`, model.foo // {bar: {baz: true}};
- Caching - the ability to recover data from localStorage or IndexedDB;
- Persist model - the integrity of the model.
As I said, touch-mail, as well as a number of other projects built on Backbone, is a good foundation that gives you Emitter, Model, Collection, Router and View. This can cover all our needs.
Everything rested only on the big mail, which was not Backbone, but those models that were, had a similar interface (get / set).
| Backbone | post office | |
|---|---|---|
| Depencies | jQuery, undescore | jQuery |
| Dot notation | - | + |
| Getters | - | + |
| Caching | - | - |
| Persist model | - | + |
As you can see, it turned out that the basic capabilities that have a big mail, was not in Backbone. But! Backbone is a well-established tool, time-tested and has a huge community and active support, so almost any missing features can be covered with an extension that has long been written and tested.
So the dot notation can be obtained by using:
To implement getters there are https://github.com/asciidisco/Backbone.Mutators (but only with get).
And so on. Alas, no matter how I searched, I could not find an extension to support the “integrity of the model” out of the box, when such an opportunity was the cornerstone of a large mail.
What is “model integrity”?
Consider an example of receiving a letter:
function findOne(id) { var dfd = $.Deferred(); var model = new Backbone.Model({id: id}); model.fetch({ success: dfd.resolve, error: dfd.error }); return dfd.promise(); } // - #1 findOne(123).then(function (model) { model.on("change:flag", function () { // console.log(model.get("flag")); }); }); // - #2 findOne(123).then(function (model) { model.set("flag", true); // }); At first glance, the problem can be corrected by modifying, for example, the findOne method, so that it remembers the promise and returns it:
var _promises = {}; // // function findOne(id) { if (_promises[id] === undefined) { var dfd = $.Deferred(); var model = new Backbone.Model({id: id}); model.fetch({ success: dfd.resolve, error: dfd.reject }); _promises[id] = dfd.promise(); } return _promises[id]; } But besides searching for models by id, there is also a list of models (collections). And wherever I get a collection, it must consist of references to instances of the same models, to maintain integrity at any point in the application.
Of course, this can be wound on top of Backbone, but the problem is not only this. For example, after executing any collection method, we get an array on output.
// id var ids = collection .where({ flag: true }) .pluck("id"); // TypeError: undefined is not a function So in order for Backbone to do what we want, we need to:
- Dot notation - connect the Nested / Deep Model or write it yourself;
- Learning - I did not find anything intelligible;
- Persist model - write by yourself.
- And also: logging, moki and other trifles
Even if it were possible to find some extensions that realize the necessary capabilities, I would not risk building anything on this hodgepodge - the likelihood of bugs and conflicts between these extensions, as well as a significant performance failure, is very high. Such capabilities should be integrated into the core of the framework itself.
A little bit about logging
A long time ago we wanted to get high-quality logging, which could help the developer to follow the action from the beginning to the end. In order for the log entries to have connections, not just an array, but most importantly, for the main functionality, logging should work out of the box
Now our logger looks like this, let's look at an example:
And log output:

As you can see, the log turned out to be nested, and in addition, each entry is tied to a line of code, which allows you to view the log directly in the context of the code through specials. interface (even if the code is minified):
rubaxa.imtqy.com/Error.stack
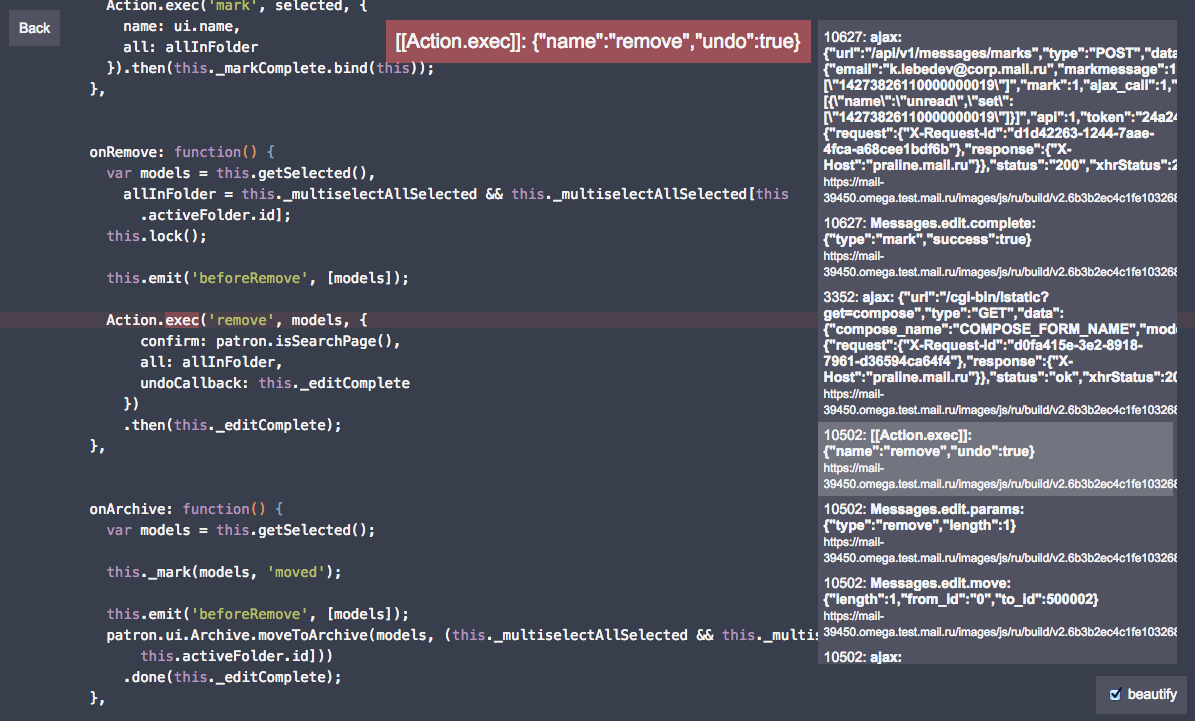
Now our logger looks like this, let's look at an example:
// Folder.find({limit: 50}).then(function (folders) { logger.add('folders', {length: folders.length}); // «» return folders.filter({type: Folder.TYPE_SMAP})[0].save({name: 'Bulk'}); }); And log output:
As you can see, the log turned out to be nested, and in addition, each entry is tied to a line of code, which allows you to view the log directly in the context of the code through specials. interface (even if the code is minified):
rubaxa.imtqy.com/Error.stack
Well, well, we will write the models ourselves. Let's try to find at least solutions for other components. (It was still possible to fork Backbone, such as Parse.com , and I even planned it, but the scope of our changes is comparable to the volume of the models themselves.)
Emitter
Going to github and setting the “ Event Emitter ”, you will find the following libraries:
- EventEmitter - 1,240 (stars) / 170 (forks)
- EventEmitter2 - 1 220/128 (as well as EventEmitter3 , which is also gaining popularity)
- microevent - 531/88
- and others
| on / off / emit | tests | handleEvent | event object | |
|---|---|---|---|---|
| EventEmitter2 | + | + | - | - |
| EventEmitter | + | + | - | - |
| microevent | + | - | - | - |
| jQuery | + | + | - | + |
As you can see, none of them support such things as handleEvent and the event object, and they are not very productive in speed. But in general, are suitable and can be used as a turnkey solution.
Promise
- Native Promise + Polyfil ;
- jQuery.Deferred;
- Q , when and others /
Q, when and others - not only promises, but also a car and a cart of different functional, but we need only promises. So Native + polyfil are perfect if not for one big but: native promises are incompatible with jQuery (all because of this piece of code).
Request
Here is a boundless sea of solutions, which, all as one, are similar and do not have:
- events (start, end, error, loss of WiFi authorization, etc.);
- timings (start and end time, duration of the request);
- error handling and result modification;
- retry request, for example, in case of an error.
The closest fit option is jQuery.ajax only.
So, every solution we found for various reasons does not fit our requirements. For example:
- Emitter - does not support handleEvent and / or event object;
- Promise - incompatible with jQuery;
- Request is the closest analogue to jQuery.
Of course, you could take one of the solutions, cut yourself off by the possibilities and get involved in jQuery. But these modules are not so voluminous, and the presence of jQuery did not inspire optimism.
And at this moment we return to point number 4: If nothing has come up to you, then are you ready ...
Are you ready ...
- To write a common solution, and not to solve a narrow problem.
- Write tests and documentation.
- Maintain 7/24.
- Do it all for free.
The last point may seem strange to someone, but do not rush - in fact this is an important point. In fact, it doesn’t matter to the business that you are under the hood - it is concerned about profit (I’m talking now in general), so if you insisted and even managed to seize the time for implementation, the support will be at your expense, and it will be honest - this was your choice, your decision. Many people underestimate this point, and it seems to me that this is why the githab was filled with decisions whose support died the very next day. You need to be ready for two or three tasks a week (and then a day), and what is the maximum for you will be thanked for what is already good (and this is not counting the bugs that will be, even with tests).
So you have decided where to start? The main thing is not to code! You need to start with the project infrastructure.
Infrastructure
- Build grunt or gulp .
- Code style.
- Tests, control coatings and CI .
- JS, CS, TS or ES6 / Babel.
- Automation of change control.
- Documenting code and documentation.
- Method of distribution (github, bitbucket, etc.).
Remember that each of the items solves a specific problem and outlines the rules that will guide users.
For us, I chose the following stack :
- GruntJS to build the project;
- JSHint and .editconfig - remove all questions and extra holivars about coding style or tab vs. space, you can not argue with the robot;
- QUnit + Istanbul - tests not only improve the quality of the product, but also speed up the development and refactoring process. The coverage will provide an opportunity to see how well your tests cover the capabilities that you lay in the api. As CI was Travis , now Bamboo ;
- ES5 + Polyphils - one of the most important points. TS , CS or ES6 are not just technologies. This choice will greatly influence the decision whether to use your decision by another developer or not;
- git pre-commit-hook (JSHint) + git pre-push-hook (QUnit + Istanbul) - automate what can be automated, as well as installing hooks via preinstall or postinstall in package.json ;
- JSDoc3 - document and comment on the code, modern IDEs are able to build autocomplete by JSSDK, but the main thing is that another developer, having read the comment or parameter descriptions, will penetrate your code and its logic more quickly.
Where does the developer start?
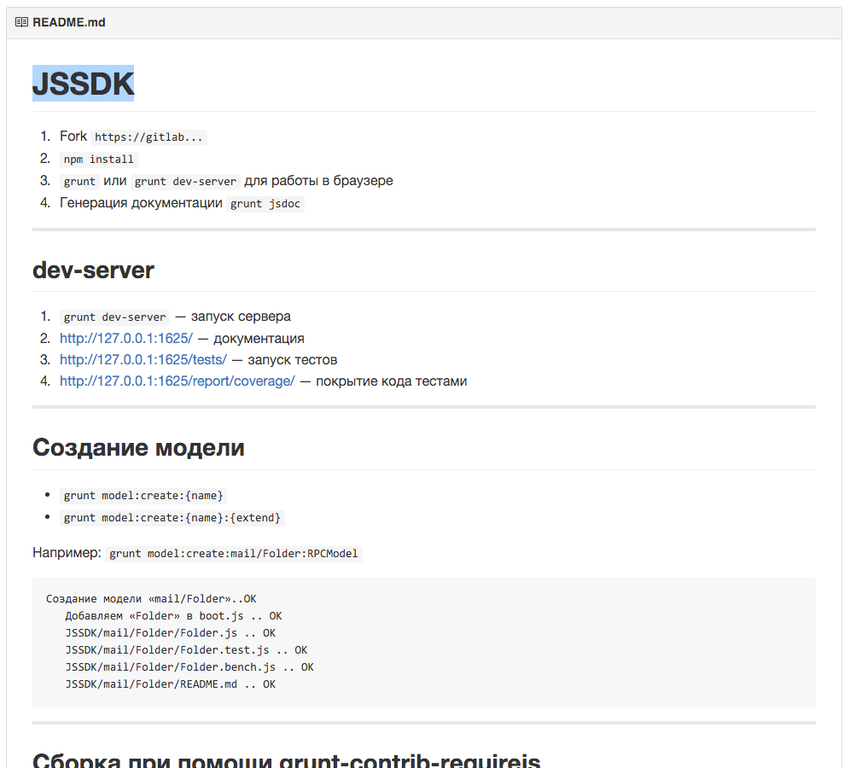
Comes on github and sees:
As you can see, here are the steps that the developer needs to perform if he wants to use or develop the project.
We proceed directly to the development.
In JSSDK, each module is a separate folder containing four files. For example, Model:
- Model.js - module code;
- Model.tests.js - tests;
- Model.bench.js - performance tests (if needed);
- README.md - documentation (generated by JSDoc3).
As I already wrote, automate everything that can be automated. Therefore, to create a module, we have a separate grunt task.
So, for example, the creation of the mail.Folder model, which inherits the RPCModel, will look like:
> grunt model:create:mail/Folder:RPCModel «mail/Folder»..OK «Folder» boot.js .. OK JSSDK/mail/Folder/Folder.js .. OK JSSDK/mail/Folder/Folder.test.js .. OK JSSDK/mail/Folder/Folder.bench.js .. OK JSSDK/mail/Folder/README.md .. OK When developing, first of all tests are written and only then the code. After making changes or writing a new module, the most interesting part begins - commit and push:
git commit -am"..." - runs grunt jshintgit push original master - grunt testIf the task executes with an error, then commit or push will not work, it allows you to keep the code in the master always working. Zavomit non-working code can only be in a branch other than master. In any other thread, errors will simply be displayed. Also, a push may not pass from a weak test coverage. Weakly consider everything that is less than 100% (currently it is 1,635 assertions).
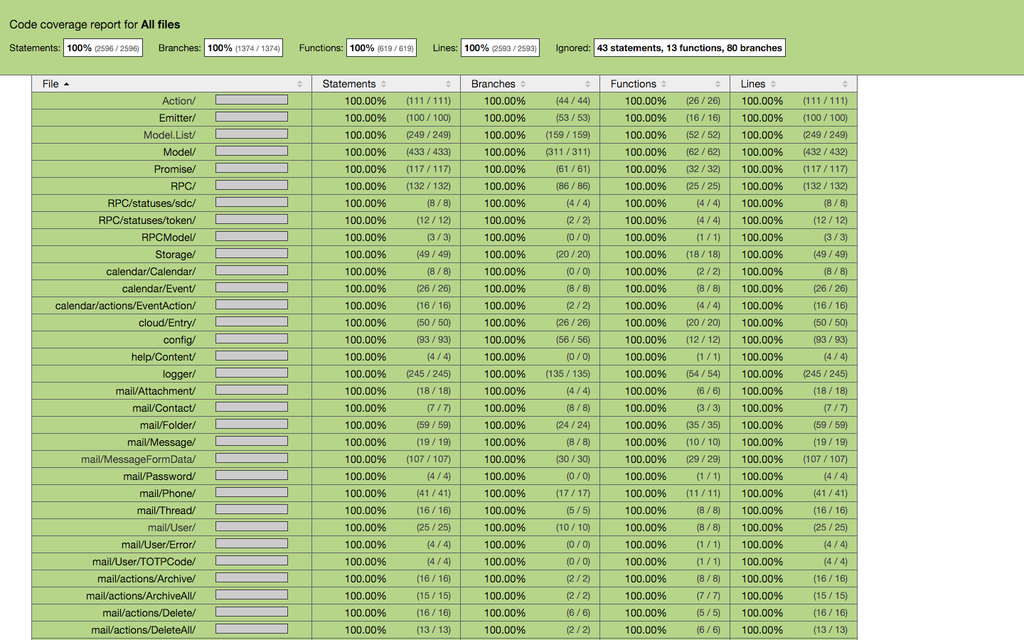
Test coverage
Coverage tests - not a panacea for all ills, it does not give a 100% guarantee of the absence of bugs. The main thing that gives coverage is the ability to assess how much your tests affect all the possibilities, and sometimes allows you to rethink the final implementation of a particular piece of code.
The developer starts
grunt dev-server and sees the following picture:But the code itself and its coverage:
Documentation
The final touch is the generation of documentation. For this we use the official JSDoc3 and our publisher (in fact, npm is full of similar solutions). The final documentation exists in two forms, it is:
- README.md;
- 127.0.0.1 : 1625 / - dev-server with documentation.
This is what the module's README.md looks like:
Here we immediately see examples and descriptions of methods, as well as references to impurities. Each item can be given a link, in addition, by clicking on the name of the method, you can quickly go to the code.
README.md is convenient because it can be viewed from anywhere, without any additional effort. But for everyday use, there is also a web interface for viewing documentation that can be picked up locally. It looks like this:
All content is based on md-files, so it is also always relevant. But the most important thing is a one-page application that has a kind of fuzzy search, which allows you to quickly switch to the desired method.
The main thing is that all this not only does not slow down the development process, but also helps a lot. There is an opinion that tests and documentation take time. Sometimes it seems to me that those who have not tried to write them say so. But let's not talk about it. Personally, they allowed me to not only improve the quality of the code, but also significantly reduce development time. The second common myth is that comments are not needed by the code, since the code must be expressive and speak for itself ... Yes, that's right, but in most cases it is simpler and, most importantly, faster to read like a human being than to build an interpreter.
In conclusion, I will say it again: always look for a ready-made solution! If nothing good is found, think about how to change the task. If you decide to write from scratch - do everything possible so that the decision could live without your participation. And most importantly - write tools, not bicycles. Test and document! Thanks for attention.
Source: https://habr.com/ru/post/271689/
All Articles