Intensive German: how ABBYY Compreno teaches new languages
 As you know, ABBYY is developing the Compreno natural language analysis technology. Now the system works in English and Russian, and is actively used in many projects. However, initially the technology itself was conceived as multilingual, so we pay a lot of attention to “learning” other foreign languages. And here you can draw some analogy with a person: after learning a foreign language, others are easier. In particular, we are now adding German language to technology and at the same time we are exploring market opportunities - is there any interest in this area? Immediately make a reservation - while we are not talking about products that support German, we are at the very beginning.
As you know, ABBYY is developing the Compreno natural language analysis technology. Now the system works in English and Russian, and is actively used in many projects. However, initially the technology itself was conceived as multilingual, so we pay a lot of attention to “learning” other foreign languages. And here you can draw some analogy with a person: after learning a foreign language, others are easier. In particular, we are now adding German language to technology and at the same time we are exploring market opportunities - is there any interest in this area? Immediately make a reservation - while we are not talking about products that support German, we are at the very beginning.What is Compreno?
Before we talk about the addition of "new" languages, let's talk about the "old", more precisely, the source database, which was built on the basis of Russian and English languages.
Despite the fact that there are already quite a few scientific publications about Compreno,
(links to them - under the spoiler)
Yes, and in the press was given a description of the basic principles, there are still a lot of questions to the fact that this is all the same and what it can do. Therefore, we will once again “look under the hood” of technology to see what its basic principles are and how they are implemented in multilingual.● Anisimovich KV, Druzhkin K. Ju., Minlos FR, Petrova MA, Selegey VP Zuev KA Syntactic and semantic parser based on ABBYY Compreno linguistic technologies. In: Computational linguistics and intellectual technologies. 2012 Vol. 11
● Selegey V. 2012. On automated semantic and syntactic texts for lexicographic purposes. // Proceedings of the International Conference “Euralex 2012”
')
● E. Manicheva, M. Petrova, E. Kozlova & T. Popova - an integral framework for multilingual lexical database
= Proceedings of the 3rd Workshop on Cognitive Aspects of the Lexicon, COLING conference, Mumbai, 2012
● Bogdanov A.V. Description of the mapping in the automatic translation system // Dialogue 2012
● A.V. Bogdanov, A.P. Leontyev. Description of the Russian construction with an external sessionor in the system of automatic processing of natural language. Alexander E. Kibrik. In Memoriam. Materials of scientific memorial readings in memory of A.Ye. Kibrika. December 9, 2012 M .: Publishing House Mosk. University, 2012
● Zuyev KA, Indenbom EM, Yudina MV Statistical system translation with linguistic language model. In: Computational linguistics and intellectual technologies. 2013 Vol. 12
● M.Goncharova, E. Kozlova, T. Popova. Lexique multilingue dans le cadre du modèle linguistique Compreno développé par ABBYY. In: 20 conférence du Traitement Automatique du Langage Naturel 2013 (TALN 2013)
● Bogdanov AV, Leontyev AP, Dialogue 2013
● MA Petrova, THE COMPRENO SEMANTIC MODEL: THE UNIVERSALITY PROBLEM
The Compreno Semantic Model: The Universality Problem // International Journal of Lexicography (2014) 27 (2): 105-129. doi: 10.1093 / ijl / ect038
● Dialogue 2013
● Marina KULICHIKHINA, Natalia RUBAN. Semantisches Wörterbuch der deutschen Sprache für maschinelle Sprachverarbeitungssysteme. In: Aussiger Beiträge - Germanistische Schriftenreihe aus Forschung und Lehre 7 (2013). Lexikologie und Lexikografie. Aktuelle Entwicklungen und Herausforderungen (hrsg. Von Hana Bergerová, Marek Schmidt und Georg Schuppener), 310 S., h-net.msu.edu/cgi-bin/logbrowse.pl?trx=vx&list=H-Germanistik&month=14. MDHb3ZWmZ6YjUOXokqHvjA
ff.ujep.cz/files/kger/ab/ab203_abstracts_en.pdf
● Elena KOZLOVA, Maria GONCHAROVA. Le modèle linguistique Compreno développé par ABBYY. In: 82e du Congrès de l'Acfas - Colloque 635 - Langues naturelles, informatique et sciences cognitives, May 2014, Montréal, Canada
● Elena KOZLOVA, Maria GONCHAROVA. ABBYY Compreno technology. In: 27th Canadian Conference on Artificial Intelligence, Canadian AI 2014, Montréal, QC, Canada, May 6-9, 2014
● Irina Burukina. Translating implicit elements in RBMT
● Use ABBYY Compreno technology for natural language processing. Report at the conference AINL 2013, St. Petersburg
● Technology for developing domain-specific information extraction systems. Report at the conference AINL 2014, Moscow
● Bogdanov AV, Dzhumaev SS, Skorinkin DA, Starostin AS ANAPHORA ANALYSIS BASED ON ABBYY COMPRENO LINGUISTIC TECHNOLOGIES // Dialogue 2014
● Leontiev AP, Petrova MA The description of the locative dependencies in a natural language processing model // Dialogue 2014
● Starostin A., Smurov I., Stepanova M., Aging System for Syntactic Semantic Analysis. Computational Linguistics and Intellectual Technologies: Papers from the Annual International Conference “Dialogue” (2014), Bekasovo, June 2014, pp. 659-667
● Bogdanov AV, Gorbunova IM The Case of Russian Subject Pro in Machine Translation System // Dialogue 2015
● Goncharova M. B., Kozlova E. A., Pasyukov A. V., Garashchuk R. V., Selegei V. P. Meaning leveling based on the linguistic model as a means of integrating the new language into a multilingual lexico-semantic database with interlingua // Dialogue 2015
● Skorinkin DA Wardrobe and Peas: Understanding Leo Tolstoy with ABBYY Compreno // Dialogue 2015
● Selegey V. 2012. On automated semantic and syntactic texts for lexicographic purposes. // Proceedings of the International Conference “Euralex 2012”
')
● E. Manicheva, M. Petrova, E. Kozlova & T. Popova - an integral framework for multilingual lexical database
= Proceedings of the 3rd Workshop on Cognitive Aspects of the Lexicon, COLING conference, Mumbai, 2012
● Bogdanov A.V. Description of the mapping in the automatic translation system // Dialogue 2012
● A.V. Bogdanov, A.P. Leontyev. Description of the Russian construction with an external sessionor in the system of automatic processing of natural language. Alexander E. Kibrik. In Memoriam. Materials of scientific memorial readings in memory of A.Ye. Kibrika. December 9, 2012 M .: Publishing House Mosk. University, 2012
● Zuyev KA, Indenbom EM, Yudina MV Statistical system translation with linguistic language model. In: Computational linguistics and intellectual technologies. 2013 Vol. 12
● M.Goncharova, E. Kozlova, T. Popova. Lexique multilingue dans le cadre du modèle linguistique Compreno développé par ABBYY. In: 20 conférence du Traitement Automatique du Langage Naturel 2013 (TALN 2013)
● Bogdanov AV, Leontyev AP, Dialogue 2013
● MA Petrova, THE COMPRENO SEMANTIC MODEL: THE UNIVERSALITY PROBLEM
The Compreno Semantic Model: The Universality Problem // International Journal of Lexicography (2014) 27 (2): 105-129. doi: 10.1093 / ijl / ect038
● Dialogue 2013
● Marina KULICHIKHINA, Natalia RUBAN. Semantisches Wörterbuch der deutschen Sprache für maschinelle Sprachverarbeitungssysteme. In: Aussiger Beiträge - Germanistische Schriftenreihe aus Forschung und Lehre 7 (2013). Lexikologie und Lexikografie. Aktuelle Entwicklungen und Herausforderungen (hrsg. Von Hana Bergerová, Marek Schmidt und Georg Schuppener), 310 S., h-net.msu.edu/cgi-bin/logbrowse.pl?trx=vx&list=H-Germanistik&month=14. MDHb3ZWmZ6YjUOXokqHvjA
ff.ujep.cz/files/kger/ab/ab203_abstracts_en.pdf
● Elena KOZLOVA, Maria GONCHAROVA. Le modèle linguistique Compreno développé par ABBYY. In: 82e du Congrès de l'Acfas - Colloque 635 - Langues naturelles, informatique et sciences cognitives, May 2014, Montréal, Canada
● Elena KOZLOVA, Maria GONCHAROVA. ABBYY Compreno technology. In: 27th Canadian Conference on Artificial Intelligence, Canadian AI 2014, Montréal, QC, Canada, May 6-9, 2014
● Irina Burukina. Translating implicit elements in RBMT
● Use ABBYY Compreno technology for natural language processing. Report at the conference AINL 2013, St. Petersburg
● Technology for developing domain-specific information extraction systems. Report at the conference AINL 2014, Moscow
● Bogdanov AV, Dzhumaev SS, Skorinkin DA, Starostin AS ANAPHORA ANALYSIS BASED ON ABBYY COMPRENO LINGUISTIC TECHNOLOGIES // Dialogue 2014
● Leontiev AP, Petrova MA The description of the locative dependencies in a natural language processing model // Dialogue 2014
● Starostin A., Smurov I., Stepanova M., Aging System for Syntactic Semantic Analysis. Computational Linguistics and Intellectual Technologies: Papers from the Annual International Conference “Dialogue” (2014), Bekasovo, June 2014, pp. 659-667
● Bogdanov AV, Gorbunova IM The Case of Russian Subject Pro in Machine Translation System // Dialogue 2015
● Goncharova M. B., Kozlova E. A., Pasyukov A. V., Garashchuk R. V., Selegei V. P. Meaning leveling based on the linguistic model as a means of integrating the new language into a multilingual lexico-semantic database with interlingua // Dialogue 2015
● Skorinkin DA Wardrobe and Peas: Understanding Leo Tolstoy with ABBYY Compreno // Dialogue 2015
So Compreno is
• technology of semantic-syntactic analysis of the text,
• based on language model
• and on statistics.
Of course, such a definition has not yet clarified the situation, so we will analyze it in parts.
"Compreno is a technology for semantic-syntactic analysis of the text." The semantic analysis is implemented due to the fact that the meanings of words of different languages are described and put into a semantic hierarchy in the Compreno database. By itself, the semantic hierarchy is conceived as an interlingua (interlanguage level), consisting of concepts that exist in every language. Currently, there are 145,000 such concepts in the system. Each such concept contains one or more values of a specific language. For example, the concept of CONTRACT is implemented by Russian contract, contract, agreement , etc., and in English, contract, agreement, treaty , etc. The semantic nodes can be filled with both individual words and groups of words ( public health ). The hierarchy is not a semantic network, but a semantic tree, which allows you to pass on characteristics from parent to descendants. The syntactic analysis is possible because each language has its own syntactic description, i.e. "Grammar", which takes into account both morphological signs, and signs of partial and grammatical features, which are explained by the meaning of a word. For example, being in the meaning of POSITION_IN_SPACE is used only returnable, as opposed to being in the meaning TO_FIND (The house is in the garden. - Words are not easily found in the text ).
"Compreno is a technology for semantic-syntactic analysis of text based on a language model ." The database describes not only the meanings of words and their grammatical features, but also systematically describes the possible connections between meanings, both semantic and grammatical, which we call the Model. We refer to semantic relationships as deep positions ( # [[Possessor: Company] [Time: annually] Predicate: purchases [[from] Source: supplier] [Object: equipment]] ). There are about 300 such semantic “roles” in our system. Grammatical relationships are described using surface positions ( # [[$ Subject: Company] [$ AdjunctTime: annual] $ Verb: purchases [[$ Preposition: from] $ Object_Indirect_Y: supplier] [$ Object_Direct: equipment]] ).
"Compreno is a technology for semantic-syntactic analysis of text based on a language model and on statistical data ." When analyzing text, Compreno relies on a detailed language model, as well as on estimates of probabilities. The language model determines which analysis options are in principle possible. Statistics suggest which of the possible options are most likely. The statistical component of our system is trained in parallel (Russian-English-German) and mono-language textual cases.
Thus, Compreno is a technology that, to some extent, models a person’s linguistic (linguistic) thinking, how a person determines the meanings of words and the connections between them in a sentence.
Let us see how semantic-syntactic analysis takes place using the example of an ambiguous phrase green spruces . Compreno analyzes the text on the principle of Michelangelo: takes everything possible, and then gradually cuts off the excess.

Larger
So, at the initial stages, morphology is checked, by what forms from which words, in what way, number, the words "green" and "ate" can in principle be. We go to the semantic hierarchy and look at the meanings of such words (GREEN, ENVIRONMENTALIST, FIR, TO_EAT). Further, all possible grammatical and semantic links between them are considered, incompatible forms are cut off, and then semantic-syntactic structures are built. With the help of a number of statistical assessments based on the frequency of occurrence of a phenomenon, a word in a given meaning, etc. in the marked hulls, the structure is chosen “winner”. At the final stage, all features of the source languages are removed, and only the semantic structure remains with semantic links and universal concepts of hierarchy as nodes.
Why do you need Compreno technology?
At the expense of the model, Compreno reveals semantic links in the text (What? Who? When? Where? Why? Why? To whom? How much?, Etc.), which can be expressed differently syntactically. Accordingly, the technology is best applied where the machine is required to understand contexts, complex semantic statements, often complexly syntactically shaped (analysis of the text of contracts, correspondence, etc.). For the analysis of special texts, the corresponding branches are expanded with terminological vocabulary.
Based on the Compreno linguistic technology, various applied tasks related to the processing of textual information are solved:
- information retrieval,
- semantic classification,
- semantic search
- etc.
How is multilingual implementation?
Unlike many semantic systems, Compreno was based on the principle of multilingualism from the very beginning. This is evidenced by the fact that the system was created not in one, but in two languages at once - Russian and English - having different ways of language display of reality. For example, in Russian, derivatives of words are widely used ( run-run-run ), while in English there is a tendency to express the same thing with additional words ( run away-run into-run around ). In our system, additional meanings, whether they are expressed by a prefix or a single word, are encoded by a single semantic attribute, or semanteme, independent of a particular language (“Depart” - “To” - “InVariousDirections”). The hierarchy structure also takes into account the fact that a broad concept in one language ( go ) can correspond to several narrower concepts in others ( go, go; gehen, fahren ). Thus, the hierarchy of values is not tied to the logic of one language, but is conceived as an interlingual level, or interlingual. The added value immediately receives a match in all described languages.
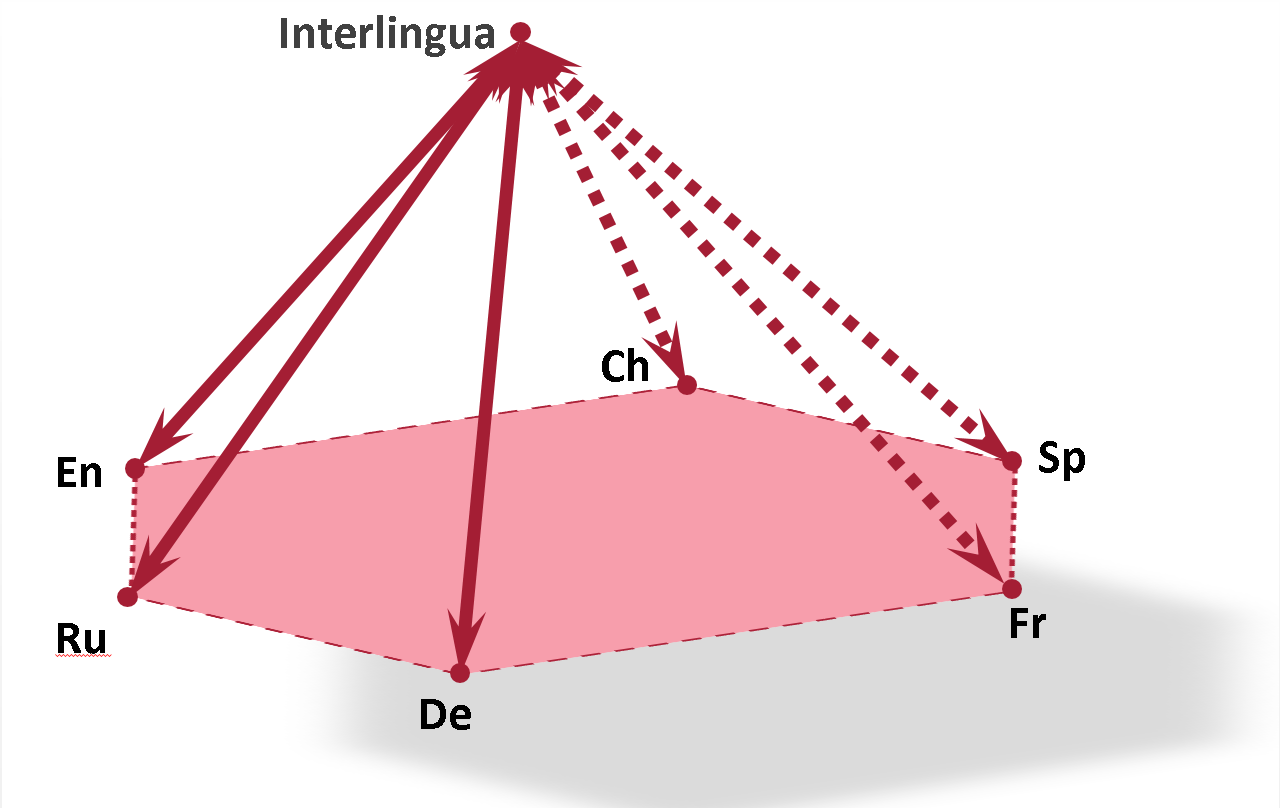
Since the analysis of the text results in a structure that includes meanings and semantic links, one deep structure can be the result of different specific implementations of the same meaning in different languages:

Larger
How can you speed up the description of new languages in semantic systems?
Sooner or later, the idea of speeding up the description of the meanings of new integrable languages comes to mind to all those involved in semantic text analysis. Why? Because the description of all the meanings of even one or two languages "manually" requires huge resources and no less fortitude to bring the matter to the result. And having one or two well-described languages, i.e. Having a structure and description methodology, a “manual” description is no longer necessary, because it is very efficient to use parallel or multilingual resources that have connections between languages. In modern linguistics, this is called semantic alignment of resources (Word Sense Alignment), i.e. juxtaposition of values in different sources. The term Word Sense Alignment itself was originally used to denote such an alignment, which was intended to collect different information about a single value. For example, in one source there is a good definition, in the other - examples, in the third - synonyms, etc., because initially there was no such resource that would set an ambitious goal to describe “everything”, each was focused on something "His". But in essence, the same principle of comparison of values is used in the automatic integration of new languages into semantic systems.
To add new languages in different approaches of semantic leveling of resources are used:
- two or multilingual dictionaries;
- encyclopedic or ontological resources (for example, Wikipedia), where there are hyperlinks between languages;
- parallel enclosures;
- Machine translate.
Also, alignment of ready-made semantic networks is used.
How does Compreno learn new languages?
As a result of the "learning" of Russian and English, the universal semantic tree Compreno has grown and expanded. Some of its parts may change, expand, and be supplemented, but the principles and basic structure after many years of continuous testing can be considered workers. Due to the finished universal description, less effort is needed to describe the new language. We will show it on the example of German.
The algorithm for adding a new language is that the program analyzes a part of parallel word-by-word aligned sources in the “learned” language and, through a deep structure, suggests in which part of the hierarchy the value of the new language should be added. The job of a linguist is to check what the program suggested and to describe complex phenomena. However, it should be understood that the semi-automatic phase is always preceded by “manual” work on the detailed description of syntax, nuclear vocabulary (about 5000 values) and the main branch model.
How do we use semantic alignment to add a new language?
So, our task is to find a place in the hierarchy not just for the German word, but for the meanings of this word, which we take from the bilingual German-English dictionary. We do this with a parser, i.e. program that analyzes the text. The uniqueness of the Compreno parser is that it builds not only the syntactic, but also the semantic structure of sentences. We analyze what we know, i.e. English part of the dictionary entry, and through the deep structure we obtain hypotheses about how we position the German value in the hierarchy. In essence, we align dictionary values with the universal values of our hierarchy.
However, in the dictionary entry there are quite a few contexts necessary for proper parsing through the Compreno-parser. Therefore, to improve the result, we use the analysis of parallel English-German text boxes, which are also automatically parsed by our parser. In real sentences, contexts are much clearer, and for each hypothesis its frequency is known, i.e. how many times such a match was found in the body. In the same way, it is not enough for a person to learn all vocabulary values to learn a language, he needs real texts.
The results of the analysis of parallel cases and the dictionary entry are compared, universal values that have met both there and there are considered to be the primary hypothesis for positioning, that is, for placing the value in our universal hierarchy. Further, these hypotheses pass several additional filters. And only the very best get to the “finals”.

Let us see how this happens using the meanings of the German verb blühen . We take a dictionary entry in which there are two meanings ( blossom, flourish ), for each of which we need to find a place in the hierarchy. We analyze the English part of the article and get a list of hypotheses for each value. We take a leveled parallel English-German corps, in which it is known not only that blühendes Geschäft is a prospering business , but also that blühendes is prospering , and Geschäft is a business . We analyze the English part, with each hypothesis from the resulting list has a frequency indicator. The algorithm program intersects two sets; as a result, two hypotheses for adding to the hierarchy (TO_BLOSSOM, BLOSSOM_AS_TO_DEVELOP) remain for the first value of blühen , and one for TO the second (TO_PROSPER).
Sometimes the list of hypotheses, resulting from the intersection, is still quite long, which is inconvenient for a quick view by a linguist. Therefore, the hypotheses that emerged from the analysis of the translation, synonyms and examples from the dictionary entry, pass through several filters.
As an example, consider the first value from the Beweis dictionary entry (evidence, proof) . The analysis of a dictionary entry consists of an analysis of translations, examples and synonyms. After the intersection of the results of the analysis of the dictionary entry and the corpses, we obtained a rather large list of hypotheses from seven concepts. To shorten it and simplify the task of checking the linguist, use the additional filters listed in the picture:
Beweis
1) · JUR (Nachweis) proof , evidence
example :
● im Hintergrund wurden Beweise gegen ihn gesammelt - evidence was secretly gathered together

After applying the filters, the list was reduced to one concept - EVIDENCE_PROOF.
What did you get?
As a result, for 1,21852 values from the 92985 dictionary entries of the German-English dictionary, we obtained positioning hypotheses in the hierarchy. This made it possible to speed up the work of linguists 10 times in simple vocabulary and 5 times in complicated language.
What are we planning to get?
So, as a result of the experiment with the German language, we tried our own universal means of leveling resources based on the Compreno semantic-syntactic parser. In fact, it can be used not only to add new language values from the general vocabulary to the semantic hierarchy, but also to fill, for example, terminological gaps in the hierarchy using additional resources, Wikipedia or special dictionaries. For example, articles for USt-IdNr. (TIN) are not available in general German dictionaries, however there is an article in Wikipedia and a legal dictionary.
The article is based on the report presented at the Dialogue international conference on computational linguistics. We wrote about conferences of past years in our blog here , here and here . If you want to make a report at the “Dialogue” in 2016, you can submit an application to the program committee from the end of December 2015 (watch for announcements on the website www.dialog-21.ru ). Registration for conference attendees begins at the end of April 2016.
Maria Goncharova,
Elena Kozlova,
technology development department
Source: https://habr.com/ru/post/271601/
All Articles