Asyncio Tarantool Queue, get in line

In one of my articles, I talked about asynchronous work with Tarantool in Python . In this article I will continue this topic, but I want to pay attention to the processing of information through the queues at Tarantool . My colleagues have published several articles about the benefits of queues (The infrastructure for processing queues on the social network My World and Push notifications in the REST API using the example of the Target Mail.Ru system ). I want to add information about queues on the example of solutions to our problems, as well as talk about working with Tarantool Queue in Python and asyncio. Why do we choose Tarantool, not Redis or RabbitMQ?
The task of sending messages "throughout the user base"
On Mail.Ru there are many media sites: News , Auto , Lady , Health , Hi-Tech , etc., and every day they are visited by millions of users. Sites are adapted for mobile devices, for most of them there is a touch-version. For the convenience of users, we created the News mobile application , which is popular on Android and iOS devices. After the publication of the “hot” news, each user of our application receives a push notification. It usually looks like this: the chief editor chooses the news, clicks the Fire button in the admin panel, and that's it - let's go! And what next? Then you need as quickly as possible to send this news to the entire database of subscribers. If someone receives a push notification in half an hour, then perhaps the news will not be so hot anymore, and the user will learn about it from another source. This is not our case.
So, there is a database that is stored in our favorite Tarantool. It is necessary as soon as possible to bypass the entire base and send a push notification to all subscribers. For each of them, a push-token and a little information about the device are stored in the database in json-format: application version, screen resolution, time zone, time interval in which the user wants to receive notifications. Specifying the time zone is very important, because sending push notifications at night when everyone is sleeping is not a good idea.
')
The requirements are clear, we go further.
Solve the problem
Usually we begin to solve the problem in the forehead, in a simple way. Simple code always looks very nice and clear:
while « »: «» - «» The main
while will run until it bypasses all users. If the user base is small, then you can do nothing, the problem is solved. What can be improved here? How to speed up such a cycle? How to send for a fixed time, regardless of the size of the database? To do this, you need to clarify the details of the process of sending notifications.For simplicity, I’ll focus on two Android and iOS platforms. What is the "send push"? How to do it? There is a description of the Google Cloud Messaging and Apple Push Notification Service protocols. There are ready-made libraries for sending push notifications in Android and iOS to Python, designed to work in the usual "synchronous" mode. If you dig deeper, then each platform has its own specifics. Push to Android is sending json data via https; in iOS, sending binary data to an ssl socket. Apple soon promises support for the HTTP / 2 protocol. Under Android, sending to multiple destinations is possible. IOS has the ability to group multiple users and send notifications to a group. That is, the grouping for each platform also has its own characteristics.
Clearly begs the decision with the queues. I would like to separate the process of selecting users from the database and the process of sending notifications to the platforms. But there are many important details. For the independence of the process of sending one platform from another, we can separate users from the selected “packs” on iOS and Android, group the users and add a message to send to the queue we need. Further, the messages can be processed, that is, directly perform the work itself on sending push notifications. Schematically, all these processes can be represented as follows:
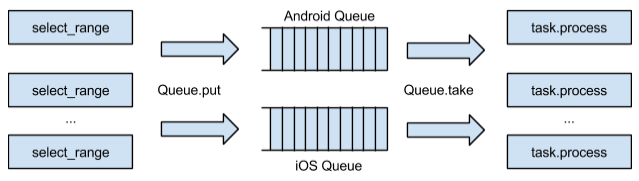
Scheme of crawling user base and processing messages through the queue
What will this approach give? We will separate the process of crawling the user base from sending push notifications. Thus, we will start to
select_range faster (execute select_range ) “bundles” in our initial cycle. If, when processing messages on one of the platforms, we encounter potential problems (and these are quite often), this will not affect the distribution on the other platform. Thus, we can easily parallelize the processing of messages on server cores, because we now have logical queues. If you need to expand our system a little, we will simply add new logical queues.Solve problems with load and scaling
With increasing load on one server, the CPU will end quickly. Add another server? Yes, exactly the same. But it is better to do it at the design stage of the service. If you make the system work on two servers, then add a couple of dozen is not difficult. We adhere to this principle: at least two servers, even when there is no real load. Several servers will also increase service reliability. The service architecture takes the following form:
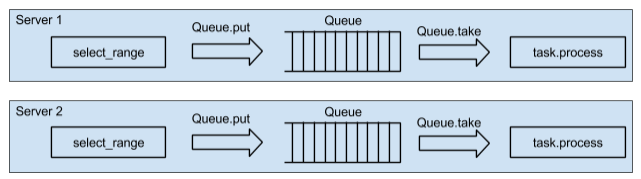
The scheme of bypass of user base on two servers
So, we have two servers, each of which has its own queues (there is, of course, a user base, we believe that it is just nearby, is available for
select_range , we will not pay much attention to this). It is very important to run a loop traversal in parallel on two servers. You can iterate through our cycle on one of the servers, select “packs”, place each “pack” in different queues, and evenly distribute “packs” across all servers. With this approach, we will be forced to “chase” data over the network. Choosing a “pack” and putting it in a queue on another server is the weak side of this approach. It is necessary to parallelize select_range across servers.To do this, on one of the servers, you need to select a “pack”, add a small message with the information about the last user id from the current “pack” to the queue on the “neighboring” server. When processing a small message on the second server, we have to get a “new packet” starting with the specified id, form a similar message to the “neighbor server”, etc., until we touch through the entire database. The current “pack” should always be processed locally in its turn. Thus, we “sort of” move the code to our data, parallelize the generation of “packs” across the servers and do not drive the data over the network.
The sequence diagram will look like this:

The cycle “by all users” is done implicitly via
queue.put(last_id) . The mailing process will end after users end in select_range . It is very important that in the distribution scheme there are no blockages in the database. This scheme is very similar to the Hadoop MapReduce process, the same principle of “Divide and Conquer”.Exactly the same architecture is used in our production. For each type of mobile application and platform, separate logical queues are used, which allows to achieve independent parallel execution of processes. It takes about 2 minutes to send push notifications for news about our combat 2 million user base. Simultaneously with such mailings, a cluster of eight servers sends about 10 thousand push notifications per second.
Features of writing code for Tarantool Queue
How to work with a large number of logical queues? How to simultaneously rake and generate data for all the queues in a single Python process? Asynchronous programming techniques come to the rescue. In the examples, I will use Centos 6.4, Python 3, asyncio, aiotarantool_queue , Tarantool 1.6 and Tarantool Queue.
The Tarantool Queue queue withstands quite large loads. There is a description on github. In one instance with Tarantool Queue, you can create multiple logical queues by calling
queue.create_tube . Logical queues are called tube. Several types of logical queues are supported. Tarantool Queue has a take/ack mechanism. Call take marks task as “in work”. The ack call removes the task from the queue, thus confirming its successful execution. If it does not reach the ack call, another process will “pick up” the task and execute take . You can delay the execution of a task for some time using the delay parameter. Not every line has this functionality and performance.Using Tarantool for both the user repository and the queue system makes our service simple in terms of the technologies used. Use Tarantool Queue is not necessary. Tarantool and Lua provide the opportunity to implement their own queue.
Install Tarantool, place github.com/tarantool/queue in the / usr / local / lua directory. In the config Tarantool /etc/tarantool/instances.enabled/q1.lua we specify:
#!/usr/bin/env tarantool package.path = package.path .. ';/usr/local/lua/tarantool-queue/?.lua' box.cfg{listen = 3301, slab_alloc_arena = 2} queue = require 'queue' queue.start() box.queue = queue We start our instance with the queue:
tarantoolctl start q1 Go to the console:
# tarantoolctl enter q1 /usr/bin/tarantoolctl: Connecting to /var/run/tarantool/q1.control /usr/bin/tarantoolctl: connected to unix/:/var/run/tarantool/q1.control unix/:/var/run/tarantool/q1.control Allow guest access and create a logical queue
q1 : q1.control> box.schema.user.grant('guest','read,write,execute','universe') q1.control> queue.create_tube('q1', 'fifo') ^D You can rake one queue like this:
queue = Tarantool.Queue(host="localhost", port=3301) while True: task = queue.take(tube="q1") process(task) task.ack() In order to rake N queues, you can create N processes. In each process, connect to the desired queue and run the exact same cycle. It is a working approach, but if there are many queues, there will be many connections to Tarantool Queue. There will also be a lot of processes running that consume physical server memory. Well, "many connections" does not make working with Tarantool as effective as it can be. Also in the processes will have to keep connections to the servers of Google and Apple. And again, the less connections we have to Google or Apple servers, the less we load them, the more resources of our server are available to us.
In the article “Asynchronous work with Tarantool on Python” I described in detail why turning one connection to Tarantool can give a noticeable performance boost (this is very important for our workloads). This approach can be applied here. We modify our initial pseudo-code a bit to clear the queue. Adapt it under asyncio.
import asyncio import aiotarantool_queue @asyncio.coroutine def worker(tube): while True: task = yield from tube.take(.5) if not task: break # process(task.data) yield from task.ack() loop = asyncio.get_event_loop() queue = aiotarantool_queue.Queue("127.0.0.1", 3301, loop=loop) workers = [asyncio.async(worker(tube), loop=loop) for tube in (queue.tube('q1'), queue.tube('q2'), queue.tube('q3'))] loop.run_until_complete(asyncio.wait(workers)) loop.run_until_complete(queue.close()) loop.close() In one process we create a connection to the queue. Create coroutines with a take / ack cycle for all logical queues. We start event loop and we clean all our turns. This is our queuing pattern.
It should be noted that the code remained linear, there are no callbacks. Also "under the hood" of this code is hidden that the task from the queue will be read in "bundles" - all this comes from the
aiotarantool_queue box. And no expectations, pulling queues and timeouts! Cool? To load all the server cores on the CPU, of course, you will have to do several such processes, but this is a matter of technology. Processing queues on Python processes would look pretty much the same. Instead of korutin there would be processes. And with a synchronous approach, the code could get even more confusing, and most importantly - not so productive.But there are downsides to using asyncio. It is necessary to make third-party libraries work, which is not so difficult to do, but you will have to carefully review the code of these libraries and adapt their work using asyncio calls. If we need a productive service, then all the efforts to support the work of third-party libraries under asyncio will be justified.
What about Redis and RabbitMQ?
Why do we use Tarantool Queue, not Redis or RabbitMQ? The choice in favor of this or that product is not so easy to make - we considered both Redis and RabbitMQ. There was even a prototype on Redis. All these solutions have a fairly good performance. But it’s not just “who is faster” ...
First of all, I want the queue to be reliable, and not in the memory. Tarantool with its WAL looks more reliable than Redis and RabbitMQ.
Each of the queue systems has its own characteristics. Redis has a pub / sub mechanism, but it is not suitable for solving our tasks - we just need a queue. Redis has lists and rpush / blpop operations with locking and waiting for data to appear, but there is no take / ack mechanism. In our production, reliability is ensured by this very mechanism - it has repeatedly shown itself from the best side.
RabbitMQ is rich in various queue patterns. To solve our problems, only a part of the RabbitMQ functional is required. Its performance is really very high, but if you enable saving data to disk, the performance drops dramatically under load. To operate RabbitMQ, experienced system administrators are needed who can diagnose production problems, and not just restart the RabbitMQ instance.
RabbitMQ deserves special attention in its Python API and asyncio connector. The queue API is implemented on callback. The code from callbacks becomes complicated and hard to maintain. To make message.ack in asyncio, you need to create a future and wait for it . This code looks very difficult. Also, we could not send a few put / take in one connection.
Redis with asyncio is much better: there is an excellent connector from the author of asyncio itself. It works really fast.
In Redis and RabbitMQ, there is no such data integration in the database and lua as in Tarantool. As a rule, production tasks require a bit more “logic” from the box from the queue. And in Tarantool this is easy to achieve thanks to lua. For example, you can start storing counters or a cache with data, or statistics directly on queued instances. All this makes Tarantool convenient for solving various tasks.
Summing up
We looked at the architecture of how to quickly and efficiently parallelize the crawling of the entire user base using the queue system on several servers. We looked at patterns using Tarantool Queue and asyncio. We paid attention to the problems of developing code using queue systems. Considered the problems of RabbitMQ and Redis, as well as the advantages of Tarantool Queue.
I hope the information will be useful for Habr's readers. I would be glad if someone shared their case studies of queues and talked about the reasons for choosing this or that solution.
References used in writing this article:
- Tarantool - A NoSQL database running in a Lua application server tarantool.org
- Python asyncio asyncio.org
- Tarantool connection driver for work with asyncio github.com/shveenkov/aiotarantool
- Tarantool Queue bindings for work with python asyncio github.com/shveenkov/aiotarantool-queue-python
- Infrastructure processing queues in the social network My World habrahabr.ru/company/mailru/blog/228131
- Push notifications in the REST API on the example of the Target system Mail.Ru habrahabr.ru/company/mailru/blog/232981
- Asynchronous work with Tarantool on Python habrahabr.ru/company/mailru/blog/254727
Source: https://habr.com/ru/post/271513/
All Articles