Angular and RequireJS project builder and some build thoughts
What is the most inconvenient in project builders? Right! The fact that you need to write the assembly yourself. Study grunt / gulp / webpack, shaman with plug-ins, think how to break the config into modules when it grows up to several hundred lines, then for several months rejoice that everything works, and when a critical change appears in the project, climb into this swamp again.
I, too, am pretty tired of all this, so I wrote a collector, devoid of these shortcomings . Its gulpfile.js looks like this:
They copied the project for themselves, and never go there again, and forever forget what an assembly is.
The only thing you have to learn is three commands:
')
Open localhost: 7000 and enjoy the local version of the site, and in the
- But what about templates, they need to be implemented in js?
- Of course! Everything is implemented as it should be.
- And I write styles on less, sass, stylus, do I need to compile them?
- Write as they wrote, everything will miraculously work.
- Are the pictures in CSS included?
- So long ago everything is in CSS. All included as a five star hotel.
- A split the collapsed file into modules?
- Check the build folder. All modules? With unique names based on file content? Here, and you were worried!
- And here's something else ...
- And it works too.
But how is this possible? We will consider this in the article. And at the end I'll tell you why RequireJS
Always something to sacrifice. In our case, these are restrictions imposed on the project structure and directly the result of the assembly. But here it’s not to cry, but to rejoice, because we sacrificed such evil as “I need maximum flexibility and control, I will write everything myself”. Let’s look around and hand in hand, we’ll conclude that most developers have little idea of the front-end single-page application architecture, let alone how to build it correctly (in a single file, in modules, synchronously load, asynchronously, no one’s performance measured, no one analyzed anything). And does a web developer need this? For this he took a job?
Closer to the topic. The builder is designed for projects based on RequireJS and AngularJS. However, it works with projects both on pure JS and theoretically with any other frameworks.
The working directory with your application will have the following structure:
In large applications, a
In separate projects, it is worth making a new version of the site (to organize a smooth transition), assemblies for A / B testing, temporary landing pages, etc.
The
In
In the
An example of
- And how can I add my script there or connect analytics?
- Through an array of scripts in the config or in the corresponding module in the project. In the demo application specifically added an example with analytics and meta tags.
Inmicroframe forks the most necessary methods that should be available before loading the main framework. Such as: the definition of the browser, the user's locale, loading scripts and so on. In theory, it should not be necessary to change this file, but so far it has not debugged it enough to guarantee this.
Now consider the simplified structure of a separate project:
Come with the end.
In
The
If next to the script file is template.html or style.css / .sass / .scss / .less / .stylus, they will be added to the template cache or compiled style file. Very simple rule. The collector does not drag anything, and takes only what is related to the script file in the sequence in which the scripts are loaded.
The most interesting is
Configurations for various environments are stored here. Supported formats are json, json5, hjson, cson, yaml. As soon as IDE starts supporting json5, I will translate all the examples into it and leave it with the only supported format. In
To build a project with the necessary config you need to specify its name by the first parameter.
The default is
Configuration file structure:
The config is probably the hardest thing in the collector. To present it, it is better to look at examples of applications more difficult , simpler and documentation .
Of course, so that the modules are loaded as needed, and not all at once ... Someone will say. But no.
The assembled project has the following structure:
If you think about it, you can conclude that in any vendor project (a module with library components) it will have the largest weight of about 1MB (in no way less than 500KB). At the same time, lazy loading cannot be organized, since all libraries must be loaded before the project starts. Of course, you can split it into files for each library, but then loading them will clog up all browser streams and postpone loading of the rest of the project files, which will not bring significant gains. It is saved by the fact that vendor of all modules changes least of all, therefore it will almost always be taken from the cache.
The next in size is the main module, which describes the general logic and common styles for the entire project. It also rarely changes.
Next are 10–20 modules for sections and various business logic. They change often, but weigh a penny. Moreover, in sum, their weight is comparable to the weight of all libraries.
To speed up the loading and quickly display the elements, it makes sense to move the style files from the vendor and the main module into separate modules (the assembly allows you to customize the inclusion of CSS in JS and the order of loading individually for each module). In the example in the figure below, it would be possible to render the styles of the payment module, since they include heavy icons of payment systems .
And now let's see how the first download of the project will take place (the files have a small weight, since gzip is enabled):
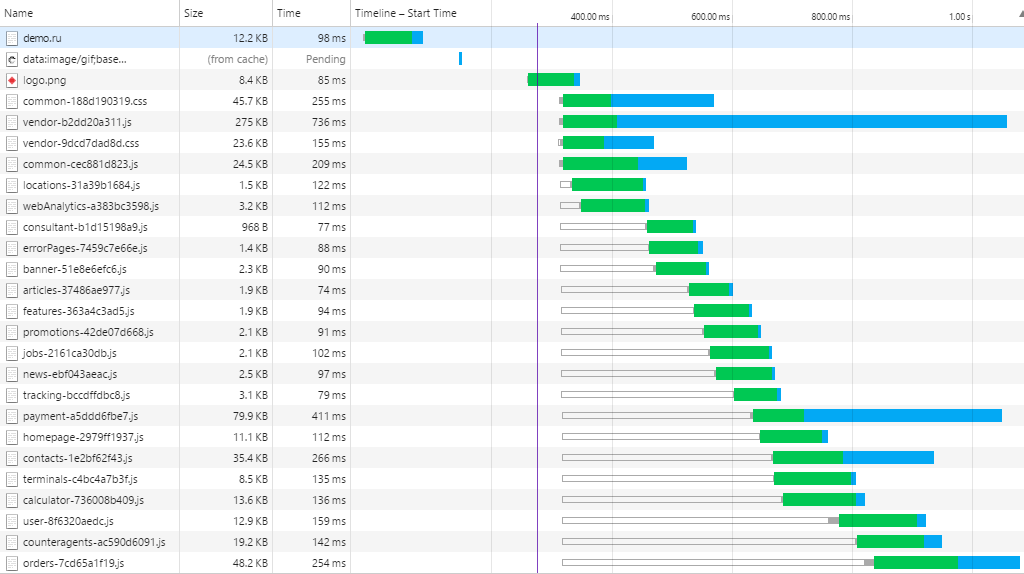
It is well noticeable that while the vendor is loading, almost all project resources manage to load. That is, there is no point in lazy loading modules. Moreover, it will slow down the site, since you will have to wait for the download of some 10KB file if the user moves to another section. In other words, neither for large projects nor for small projects, RequireJS is NOT NEEDED!
So why is it used? Exclusively for development.
Its main advantage is that you can easily connect dependencies and borrow components from different projects. For example, the same routing, the same resources, the same error handling are used in the admin. Why copy-paste if you can just connect the necessary modules from the main project? This allows you to deploy new projects as quickly as possible.
The secondary advantage is that the local collector does not need a collector (only the server is running). Scripts are not compiled. The result is available instantly, and in large projects it costs a lot. But what about Babel, ES6, Coffee, TypeScript? No way. The build was created for use in large and medium-sized projects in production. If you have a university research paper or a homepage, why do you need an assembly at all? And if all this is in a serious project, but in production ... Let us put our hands on the heart again, you just learn new technologies at the expense of the employer. For the same reason, no html preprocessors are supported (although this is quite simple). JS and HTML know any web developers, unlike other technologies that are popular today, and tomorrow everyone has forgotten about them.
Install globally bower and gulp:
Download a simplified or full demo project, type commands in its folder:
Open localhost: 7000 , admire.
Dial:
Open localhost: 7200 , admire the assembled version for production, which will appear in the build folder
Something didn't work?
So npm did not load or clumsily loaded modules. If there is a problem with Karma, make sure that it and all its plugins are in the same node_modules folder. If it does not find node-sass, most likely you recently updated the node - reinstall all the plugins. No rights to change the folder - try another console. When installing solid errors, but everything works / does not work - you have Winda.
Thank you for your attention, I am ready to listen to criticism.
I, too, am pretty tired of all this, so I wrote a collector, devoid of these shortcomings . Its gulpfile.js looks like this:
var gulp = require('gulp'); var arjs = require('arjs-builder')(); gulp.task('build', arjs.build); gulp.task('test', arjs.test); gulp.task('default', arjs.run); They copied the project for themselves, and never go there again, and forever forget what an assembly is.
The only thing you have to learn is three commands:
')
gulp #, gulp build # gulp test # Open localhost: 7000 and enjoy the local version of the site, and in the
build
folder build
already lies down version.- But what about templates, they need to be implemented in js?
- Of course! Everything is implemented as it should be.
- And I write styles on less, sass, stylus, do I need to compile them?
- Write as they wrote, everything will miraculously work.
- Are the pictures in CSS included?
- So long ago everything is in CSS. All included as a five star hotel.
- A split the collapsed file into modules?
- Check the build folder. All modules? With unique names based on file content? Here, and you were worried!
- And here's something else ...
- And it works too.
But how is this possible? We will consider this in the article. And at the end I'll tell you why RequireJS
Project structure
Always something to sacrifice. In our case, these are restrictions imposed on the project structure and directly the result of the assembly. But here it’s not to cry, but to rejoice, because we sacrificed such evil as “I need maximum flexibility and control, I will write everything myself”. Let’s look around and hand in hand, we’ll conclude that most developers have little idea of the front-end single-page application architecture, let alone how to build it correctly (in a single file, in modules, synchronously load, asynchronously, no one’s performance measured, no one analyzed anything). And does a web developer need this? For this he took a job?
Closer to the topic. The builder is designed for projects based on RequireJS and AngularJS. However, it works with projects both on pure JS and theoretically with any other frameworks.
The working directory with your application will have the following structure:
projects/ ├──project1/ ├──project2/ ├──project3/ ├──files/ ├──vendor/ ├──compiled/ ├──build/ ├──index.html ├──lib.js └──lib.css .bowerrc bower.json package.json gulpfile.js project1..3 - project folders. The project describes a separate section of the site or a separate site. Projects can be written on different frameworks or without them. For projects can be used as a common index.html or your own. There will be at least three projects in the middle tier application:main- the main siteadmin-adminpanelold-browser- stub for old browsers, written in the most primitive JS
In large applications, a
lib project may appear in which the main modules used in other projects (routing, authorization, working with resources ...) will be assembled.In separate projects, it is worth making a new version of the site (to organize a smooth transition), assemblies for A / B testing, temporary landing pages, etc.
files are put into files that will not be inserted into CSS (candidates for transfer to a file server). The rest will be converted to base64 and inserted into styles, even if it is 2GB of video. Because the project describes only the interface, the content must be taken from other places.The
vendor copies libraries from bower.In
compiled , temporary files for local work (styles, vendor libraries) are added.In the
build collected projects, ready for uploading to the server.An example of
index.html can be found here . It, like gulpfile.js, never changes.- And how can I add my script there or connect analytics?
- Through an array of scripts in the config or in the corresponding module in the project. In the demo application specifically added an example with analytics and meta tags.
The abstract marketing agency asks you to add Yandex.Metrica, googleAnalitycs, googleTagManager, vkontakte, mailru, doubleClick counters ... and everyone needs to place their script in the index, and in order to increase others, so that it creates its own shit-ifframe or shit-picture in one pixel. And not fucked you, gentlemen? Do you think you can just shit in the index? Now all these upstarts are enclosed in a separate module and are connected only if there is permission in the config. We do not want to observe a bunch of left-hand queries in local development?
In
lib.js are Now consider the simplified structure of a separate project:
_config/ ├──default.yaml ├──dev.yaml └──production.yaml module1/ ├──_tests ├──someFolder1/ │ ├──some.js │ ├──style.sass │ └──template.html ├──someFolder2/ └──config.js module2/ module3/ bootstrap.js requireconfig.js Come with the end.
requireconfig.js - connects library files to the projectbootstrap.js - include project files. The standard work scheme require.jsmodule1..3 - project modules. At the time of assembly, each module is collected in a separate file.In
_tests are tests related to files in the current folder. As tests, files ending in spec.js .The
config.js describes the dependencies of the corresponding module.someFolder can have any structure (the main thing is that all dependencies are described)If next to the script file is template.html or style.css / .sass / .scss / .less / .stylus, they will be added to the template cache or compiled style file. Very simple rule. The collector does not drag anything, and takes only what is related to the script file in the sequence in which the scripts are loaded.
The most interesting is
_configConfigurations for various environments are stored here. Supported formats are json, json5, hjson, cson, yaml. As soon as IDE starts supporting json5, I will translate all the examples into it and leave it with the only supported format. In
default settings common to all environments are described. The rest of configs are defaulted.To build a project with the necessary config you need to specify its name by the first parameter.
gulp --qa gulp build --production The default is
dev .Configuration file structure:
{ public: { ... }, //, project.config localhost: { webserver: { ... }, // - manifest: { ... } // }, build: { /* */ ... manifest: { ... }, // modules: { ... }, // , vendor mangle: true, copy: { ... } // - , robots.txt }, vendor: { ... }, // . , bootstrap angularStrap } The config is probably the hardest thing in the collector. To present it, it is better to look at examples of applications more difficult , simpler and documentation .
Why all the RequireJS?
Of course, so that the modules are loaded as needed, and not all at once ... Someone will say. But no.
The assembled project has the following structure:
vendor-f8acc4024d.js #800 vendor-9dcd7dad8d.css #100 common-95dafc6502.js #200 homepage-2979ff1937.js #30 news-ebf043aeac.js #10 ... If you think about it, you can conclude that in any vendor project (a module with library components) it will have the largest weight of about 1MB (in no way less than 500KB). At the same time, lazy loading cannot be organized, since all libraries must be loaded before the project starts. Of course, you can split it into files for each library, but then loading them will clog up all browser streams and postpone loading of the rest of the project files, which will not bring significant gains. It is saved by the fact that vendor of all modules changes least of all, therefore it will almost always be taken from the cache.
The next in size is the main module, which describes the general logic and common styles for the entire project. It also rarely changes.
Next are 10–20 modules for sections and various business logic. They change often, but weigh a penny. Moreover, in sum, their weight is comparable to the weight of all libraries.
To speed up the loading and quickly display the elements, it makes sense to move the style files from the vendor and the main module into separate modules (the assembly allows you to customize the inclusion of CSS in JS and the order of loading individually for each module). In the example in the figure below, it would be possible to render the styles of the payment module, since they include heavy icons of payment systems .
And now let's see how the first download of the project will take place (the files have a small weight, since gzip is enabled):
It is well noticeable that while the vendor is loading, almost all project resources manage to load. That is, there is no point in lazy loading modules. Moreover, it will slow down the site, since you will have to wait for the download of some 10KB file if the user moves to another section. In other words, neither for large projects nor for small projects, RequireJS is NOT NEEDED!
So why is it used? Exclusively for development.
Its main advantage is that you can easily connect dependencies and borrow components from different projects. For example, the same routing, the same resources, the same error handling are used in the admin. Why copy-paste if you can just connect the necessary modules from the main project? This allows you to deploy new projects as quickly as possible.
The secondary advantage is that the local collector does not need a collector (only the server is running). Scripts are not compiled. The result is available instantly, and in large projects it costs a lot. But what about Babel, ES6, Coffee, TypeScript? No way. The build was created for use in large and medium-sized projects in production. If you have a university research paper or a homepage, why do you need an assembly at all? And if all this is in a serious project, but in production ... Let us put our hands on the heart again, you just learn new technologies at the expense of the employer. For the same reason, no html preprocessors are supported (although this is quite simple). JS and HTML know any web developers, unlike other technologies that are popular today, and tomorrow everyone has forgotten about them.
So how does all this run?
Install globally bower and gulp:
npm i -g bower npm i -g gulp Download a simplified or full demo project, type commands in its folder:
npm i bower i gulp Open localhost: 7000 , admire.
Dial:
gulp build --production gulp Open localhost: 7200 , admire the assembled version for production, which will appear in the build folder
Something didn't work?
So npm did not load or clumsily loaded modules. If there is a problem with Karma, make sure that it and all its plugins are in the same node_modules folder. If it does not find node-sass, most likely you recently updated the node - reinstall all the plugins. No rights to change the folder - try another console. When installing solid errors, but everything works / does not work - you have Winda.
Future plans
- Build build will be possible without RequireJS. Now the extra 17KB are tolerable (compared to the weight of the entire project).
- Simplify API.
- Support for other frameworks (not alone).
- Speed ... Although now all processes occur in RAM, and livereload compiles only the styles of the changed module.
- Support for multilingual projects.
- Generating documentation from code.
- Write an article about the architecture of the project on AngularJS. Now only the general structure has been affected, which does not explain what modules should be in the project and how they should be written.
- In general, rewrite everything in C ++, getting rid of the crap, and so on. (probably not in this life)
Thank you for your attention, I am ready to listen to criticism.
Source: https://habr.com/ru/post/271281/
All Articles