Classic cryptanalysis

For centuries, people invented ingenious ways of hiding information - ciphers, while other people came up with even more ingenious ways of opening information - methods of hacking.
In this topic, I want to briefly go through the most well-known classical encryption methods and describe the hacking technique of each of them.
Caesar cipher
The easiest and one of the most famous classical ciphers - Caesar's cipher is perfect for the role of an aperitif.
The Caesar cipher refers to the group of the so-called one-alphabetic substitution ciphers. When using ciphers of this group, “each character of the plaintext is replaced with some symbol of the same alphabet, fixed with this key” wiki .
Ways to select keys may be different. In Caesar's cipher, the key is an arbitrary number k, selected in the range from 1 to 25. Each letter of the plaintext is replaced by a letter standing k characters farther than it in the alphabet. For example, let the key be the number 3. Then the letter A of the English alphabet will be replaced with the letter D, the letter B with the letter E and so on.
')
For clarity, we encrypt the word HABRAHABR with the Caesar cipher with the key k = 7. Build a lookup table:
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
| h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z | a | b | c | d | e | f | g |
And replacing each letter in the text we get: C ('HABRAHABR', 7) = 'OHIYHOHIY'.
When deciphering each letter is replaced by a letter, standing in the alphabet for k characters earlier: D ('OHIYHOHIY', 7) = 'HABRAHABR'.
Caesar's Crypt Analysis Cipher
The small space of keys (only 25 options) makes brute-force the most effective and simple attack option.
For opening it is necessary to replace each letter of the ciphertext with a letter standing one character to the left in the alphabet. If, as a result, it was not possible to get a readable message, then it is necessary to repeat the action, but already shifting the letters two characters to the left. And so on, until the result is readable text.
Affiliate Cipher
Consider a slightly more interesting one-alphabetic substitution cipher called an affine cipher. It also implements a simple substitution, but provides a slightly larger key space compared to Caesar’s cipher. In the affine cipher, each letter of the alphabet of size m is assigned a number from the range 0 ... m -1. Then, using a special formula, a new number is calculated, which will replace the old one in the ciphertext.
The encryption process can be described by the following formula:
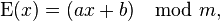 ,
,where x is the number of the letter to be encrypted in the alphabet; m is the size of the alphabet; a, b - encryption key.
For decryption, another function is calculated:
 ,
,where a -1 is the reciprocal of a modulo m . This means that for correct decryption, the number a must be mutually simple with m .
Given this limitation, we calculate the key space of an affine cipher using the example of the English alphabet. Since the English alphabet contains 26 letters, then as a can only be chosen to be mutually prime with 26 number. There are only twelve such numbers: 1, 3, 5, 7, 9, 11, 15, 17, 19, 21, 23 and 25. The number b, in turn, can take any value in the range from 0 to 25, which ultimately gives us 12 * 26 = 312 variants of possible keys.
Cryptanalysis affine cipher
Obviously, in the case of an affine cipher, the easiest way to break is to iterate over all possible keys. But as a result of the search, there will be 312 different texts. It is possible to analyze such a number of messages manually, but it is better to automate this process using such a characteristic as the frequency of the appearance of letters .
It has long been known that letters in natural languages are not evenly distributed. For example, the frequency of occurrence of letters of the English language in the texts have the following meanings:

Those. in the English text, the most common letters are E, T, A. While the rarest letters are J, Q, Z. Therefore, considering the frequency of each letter in the text, we can determine how much the frequency response of the text corresponds to English.
To do this, calculate the value:
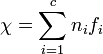 ,
,where n i is the frequency of the i- th letter of the alphabet in natural language. And f i - the frequency of the i- th letter in the ciphertext.
The greater the value of χ, the greater the likelihood that the text is written in natural language.
Thus, to break an affine cipher, it suffices to iterate over 312 possible keys and calculate the value of χ for the resulting text decryption. The text for which the value of χ will be the maximum, with a high degree of probability, is an encrypted message.
Of course, it should be borne in mind that the method does not always work with short messages, in which the frequency characteristics can be very different from the characteristics of a natural language.
Simple replacement cipher
The next cipher belonging to the group of single-alphabet substitution ciphers. The cipher key is an arbitrarily mixed alphabet. For example, the key may be the following sequence of letters: XFQABOLYWJGPMRVIHUSDZKNTEC.
When encrypting each letter in the text is replaced by the following rule. The first letter of the alphabet is replaced by the first letter of the key, the second letter of the alphabet is replaced by the second letter of the key, and so on. In our example, the letter A will be replaced by X, the letter B by F.
When decrypting, the letter is first searched for in the key and then replaced with the letter in the alphabet in the same position.
Simple replacement cryptanalysis
The simple replacement cipher key space is huge and equal to the number of permutations of the alphabet used. So for the English language this number is 26! = 2 88 . Of course, a naive enumeration of all possible keys is hopeless and a more sophisticated technique is needed for hacking, such as searching for a climb to the top :
- A random sequence of letters is selected — the primary key. The ciphertext is decrypted using the primary key. For the resulting text is calculated coefficient characterizing the probability of belonging to a natural language.
- The primary key undergoes slight changes (permutation of two randomly selected letters). The decoding is performed and the coefficient of the received text is calculated.
- If the coefficient is higher than the stored value, then the primary key is replaced with the modified version.
- Steps 2-3 are repeated until the coefficient becomes constant.
To calculate the coefficient, one more characteristic of the natural language is used - the frequency of occurrence of trigrams.
The closer the text to the English language, the more often it will meet such trigrams as THE, AND, ING. Summarizing the frequency of occurrence in the natural language of all trigrams encountered in the text, we obtain the coefficient that most likely will determine the text written in natural language.
Polybius code
Another substitution cipher. The cipher key is a 5 * 5 square (for English) containing all letters of the alphabet except J.

When encrypting, each letter of the source text is replaced by a pair of characters representing the line number and the column number in which the letter to be replaced is located. The letter a will be substituted in the ciphertext with the pair BB, the letter b - with the pair EB and so on. Since the key does not contain the letter J, before encrypting it in the source text, J should be replaced by I.
For example, encrypt the word HABRAHABR. C ('HABRAHABR') = 'AB BB EB DA BB AB BB EB DA'.
Cryptanalysis of Polybius cipher
The cipher has a large key space (25! = 2 83 for English). However, the only difference between the Polybius square and the previous cipher is that the letter of the source text is replaced by two characters.
Therefore, for the attack, you can use the technique used when hacking a simple replacement cipher - search by climbing to the top.
As the main key, a random square of 5 * 5 is selected. During each iteration, the key is subject to minor changes and it is checked whether the distribution of trigrams in the text obtained as a result of the decryption corresponds to the distribution in natural language.
Swap cipher
In addition to substitution ciphers, permutation ciphers are also widely used. As an example, we will describe the vertical permutation cipher .
The encryption process records the message as a table. The number of columns of the table is determined by the size of the key. For example, encrypt the message WE ARE DISCOVERED. FLEE AT ONCE using the key 632415.
Since the key contains 6 digits, add the message to the length of a multiple of 6 randomly selected letters QKJEU and write the message in a table containing 6 columns, from left to right:

To obtain the ciphertext, we will write out each column from the table in the order determined by the key: EVLNE ACDTK ESEAQ ROFOJ DEECU WIREE.
When decrypted, the text is written to the table in columns from top to bottom in the order determined by the key.
Cryptanalysis Permutation Cipher
The best way to attack a vertical permutation cipher will be a complete enumeration of all possible keys of small length (up to 9 inclusive - about 400,000 variants). If the search did not give the desired results, you can use the search to climb to the top.
For each possible length, a search for the most plausible key is performed. To assess the likelihood, it is better to use the frequency of the appearance of trigrams. As a result, a key is returned that provides the text of the decrypted message that is closest to the natural language.
Code Player
The Player's cipher is a wildcard cipher that implements the replacement of digrams. For encryption, a key is needed, which is a table of letters 5 * 5 in size (without the letter J).
The encryption process is reduced to finding the digram in the table and replacing it with a couple of letters that form a rectangle with the original digram.
Consider, as an example, the following table forming the Playfer cipher key:
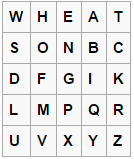
Encrypt the pair 'wn'. The letter W is located in the first row and first column. And the letter N is in the second line and third column. These letters form a rectangle with corners WESN. Therefore, when encrypting, the WN digram is converted to the ES digram.
In case letters are located in one line or column, the result of encryption is a digram located one position to the right / below. For example, the NG bigram is converted to the GP digram.
Cryptanalysis of the Playfer cipher
Since the Player's cipher key is a table containing 25 letters of the English alphabet, it can be mistakenly assumed that the search method to climb to the top is the best way to break this cipher. Unfortunately, this method will not work. Reaching a certain level of text matching, the algorithm will get stuck at a local maximum point and will not be able to continue the search.
To successfully crack the Playfer cipher, it is better to use the annealing simulation algorithm .
The difference between the annealing imitation algorithm and the climb-to-top search lies in the fact that the latter, on the way to the correct solution, never accepts weaker options as a possible solution. While the simulated annealing algorithm periodically rolls back to less likely solutions, which increases the chances of ultimate success.
The essence of the algorithm is reduced to the following actions:
- A random sequence of letters is chosen — primary-key. The ciphertext is decrypted using the primary key. For the resulting text is calculated coefficient characterizing the probability of belonging to a natural language.
- The primary key undergoes minor changes (permutation of two randomly selected letters, permutation of columns or rows). The decoding is performed and the coefficient of the received text is calculated.
- If the coefficient is higher than the stored value, then the primary key is replaced with the modified version.
- Otherwise, the replacement of the primary key with the modified one occurs with a probability that is directly dependent on the difference in the coefficients of the primary and modified keys.
- Steps 2-4 are repeated about 50,000 times.
The algorithm periodically replaces the main key, the key with the worst characteristics. Moreover, the probability of replacement depends on the difference in characteristics, which prevents the algorithm from accepting bad options too often.
To calculate the coefficients that determine the text to belong to the natural language, it is best to use the frequency of the appearance of trigrams.
Vigenera cipher
Vigenera cipher belongs to the group of poly-alphabetic substitution ciphers. This means that, depending on the key, the same letter of the plaintext can be encrypted into different characters. This encryption technique hides all the frequency characteristics of the text and makes it difficult to cryptanalysis.
The Vigenere cipher is a sequence of several Caesar ciphers with different keys.
Let us demonstrate, as an example, the encryption of the word HABRAHABR using the key 123. We write down the key under the source text, repeating it the required number of times:
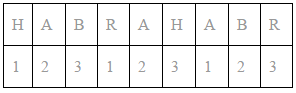
Key numbers determine how many positions you need to move a letter in the alphabet to get a ciphertext. The letter H must be shifted by one position - the result is the letter I, the letter A by 2 positions - the letter C, and so on. Having made all the substitutions, we get the result of the ciphertext: ICESCKBDU.
Cryptanalysis of the Vigenere cipher
The first task in cryptoanalysis of Vigener's cipher is to find the length used for encryption, the key.
To do this, you can use the index of matches.
The coincidence index is a number characterizing the probability that two arbitrarily selected letters from the text will be the same.
For any text, the coincidence index is calculated by the formula:
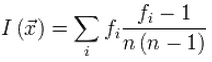 ,
,where f i is the number of occurrences of the i-th letter of the alphabet in the text, and n is the number of letters in the text.
For English, the coincidence index is 0.0667, while for a random set of letters, this figure is 0.038.
Moreover, for a text encrypted using a single alphabetic substitution, the coincidence index is also equal to 0.0667. This is explained by the fact that the number of different letters in the text remains unchanged.
This property is used to find the length of the Vigenere cipher key. From the ciphertext, every second letter is selected in turn, and the index of matches is considered for the received text. If the result roughly corresponds to the coincidence index of a natural language, then the key length is equal to two. Otherwise, every third letter is selected from the ciphertext and again the coincidence index is considered. The process is repeated until the high value of the index of matches indicates the key length.
The success of the method is explained by the fact that if the key length is guessed correctly, the selected letters form a ciphertext encrypted with a simple Caesar cipher. And the index of matches should be approximately the same as the index of matches of a natural language.
After the key length is found, the hack comes down to opening several Caesar ciphers. To do this, you can use the method described in the first section of this topic.
PS
The sources of all the above ciphers and attacks on them can be viewed on GitHub .
Links
1. Cryptanalysis of classical ciphers at practicalcryptography.com .
2. Frequency characteristics of English on the website practicalcryptography.com
3. Description of the algorithm for simulating annealing on wikipedia
4. Description of the search by climbing to the top on wikipedia
Source: https://habr.com/ru/post/271257/
All Articles