How to make the test environment as close as possible to the combat

One of the possibilities for improving the quality of the product being produced is matching the environments on the combat servers and in the testing environment. We tried to minimize the number of errors associated with the difference in configurations by moving from our old test environment, where the settings of services were very different from the battle, to the new environment, where the configuration almost corresponds to the battle. We did this with the help of docker and ansible, got a lot of profit, but did not avoid various problems. I will try to tell about this transition and interesting details in this article.
At HeadHunter, about 20 engineers are involved in the testing process: manual testing specialists, automatics testers, and a small QA team that develops its process and infrastructure. The infrastructure is quite extensive - about 100 test benches with their own tools for their deployment, more than 5,000 autotests with the ability to run them by any technical department employee.
On the other hand, production, where even more servers and where the price of the error is much higher.
')
What do our testers want? Release the product without bugs and downtime in a combat environment. And they achieve this on the current test environment. However, sometimes they skip problems that cannot be caught in this environment. Such as configuration changes.
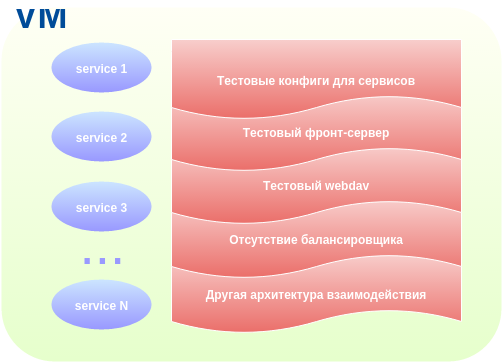
The old test environment had a number of features:
- Its configuration files for applications that are different from production and require constant support.
- Lack of application deployment testing.
- The absence of some applications that exist and work in a combat environment.
- Completely your web server and webdav test configs.
All these points led to various bugs, the most unpleasant of which was almost an hour of simple site due to the incorrect nginx config.
What I wanted from the new environment:
- use of configuration as close as possible to the combat environment (the same nginx locations, balancers, etc.);
- the ability to do everything that we could do on the old environment, and even a little more - to test the application application and their interaction;
- the relevance of the configuration in the test environment relative to the combat environment;
- ease in supporting change.
The beginning of the way
The idea of using a configuration with production in a test environment appeared quite a long time ago (about 3 years ago), but there were other more important tasks, and we did not take on the implementation of this idea.
And we took it by chance, deciding to try a new technological trend in the form of a docker at the time when version 0.8 was released.
To understand what is so special about our test environment, we need to know a little bit about what hh.ru production consists of.
Production of hh.ru is a fleet of servers on which separate parts of the site are running - applications, each of which is responsible for its own function. Applications communicate with each other via http.
The idea was to recreate the same structure, replacing the server park with lxc containers. And so that it would be convenient to manage this whole economy, use an add-on called docker.
Not quite docker-way
We did not follow the true docker-way, when one service was launched in one container. The task was to make test benches similar to the production and service infrastructure.
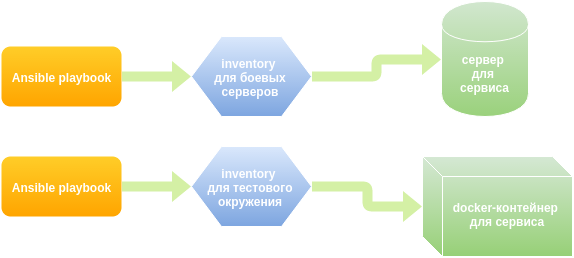
The operation service uses ansible for application deployment and server configuration. The order of display and configs patterns for each service is described in the yaml file, in the terminology of ansible - playbook. It was decided to use the same playbooks in the test environment. The flexibility here is in the ability to replace values and have a completely different, test set of variable values.
As a result, we have formed several docker images - a base image in the form of ubuntu with init & ssh, with a test database, with cassandra, with a deb-repository and a maven-repository, which are available in the internal docker registry. From these images we create the number of containers we need. Then ansible rolls out the necessary playbooks, to the containers-hosts specified in inventory (list of server groups with which ansible will work).
All running containers are in the same (internal for each host machine) network, and each container has a fixed IP address and DNS name — and this is also not a docker-way. To completely recreate the production infrastructure, some containers even have the IP addresses of the combat servers.

You can access containers by ssh directly from the host machine. Inside the container there is the same location of the files as on the production servers, the same versions of applications and dependencies.
For easy search of errors on the host machine, directories with logs from each container are aggregated using the mechanism of symbolic links. Each request for a production has a unique number, and now the same system is available in the test environment, which allows having the request id to find its mention in the logs of all services.
We create and configure the host machine for containers from our test bench management system using vmbuilder & ansible. New machines took more RAM due to additional services that were not previously in the test environment.
To facilitate the work, a lot of scripts (python, shell) were written - to start playbooks (so testers didn't memorize various tags and ansible launch parameters), to work with containers, to create the whole environment from scratch and update, update and restore test databases and etc.
The assembly of services from the code for testing is also automated here, and the new environment uses exactly the same build program as for the release of releases for production. The build is done in a special container, where all the necessary build dependencies are installed.
What problems were and how we solved them
Container IPs and their permanent list.
The default docker gives the IP addresses from the subnet in random order and the container can get any address. In order to somehow tie up in the DNS zone, we decided to send each container its unique, assigned to it address specified in the config file.
Parallel run ansible.
The operation service never encounters the task of creating a production from scratch, so they never run all the ansible-playbooks at once. We tried, and the sequential launch of playbooks to deploy all services took about 3 hours. Such a time did not suit us completely when deploying a test environment. It was decided to launch playbooks in parallel. And here we were again waited by an ambush: if we start everything in parallel, then some services do not start due to the fact that they are trying to establish a connection with other services that have not yet had time to start.
Designating an approximate map of these dependencies, we selected groups of services and launch the playbooks in parallel within these groups.
Tasks that are missing from the application release process by the maintenance service.
The operation service is engaged in the deployment of already assembled applications in deb-packages, the tester, as well as the developer, has to build applications from the source code, while assembling there are other dependencies regarding those that are necessary during installation. To solve the assembly problem, we added another container, in which we put all the necessary dependencies. A separate script collects the package inside this container from the source of the currently needed application. Then the package is poured into the local repository and rolled out on those containers where it is needed.
Problems with increased iron requirements.
In view of the larger number of services (balancers) and other application settings with respect to the old test environment, more RAM was needed for the new stands.
Problems with timeouts.
In production, each service is on its own server, quite powerful. In a test environment, services in containers share common resources. The established timeouts in production turned out to be inoperative in the test environment. They were rendered into variables ansible and modified for the test environment.
Problems with retracts and aliases for containers.
Some errors occurring in the services are treated in production by repeated requests for another copy of the service (retracting). In the old environment, retracts were not used at all. In the new environment, although we raised one container with the service one, dns-aliases were made for some services for retracts to work. Retrai make the system a little more stable.
pgbouncer and number of connections.
In the old test environment, all services went straight to postgres, in production before each postgres is pgbouncer, the database connection manager. If there is no manager, then each connection to the database is a separate postgres process, eating off additional memory. After installing pgbouncer, the number of postgres processes was reduced from 300 to 35 on a running test bench.
Service monitoring.
For ease of use and running autotests, easy monitoring was done, which with a delay of less than a minute shows the status of the services inside the containers. Made on the basis of haproxy, which makes http check for services from the config. The configuration file for haproxy is generated automatically based on ansible inventory and data on addresses and ports from ansible playbooks. Monitoring has a user-friendly view for people and json-view for autotests, which check the state of the stand before launch.
There were many other problems: with containers, with ansible, with our applications, with their settings, etc. We have decided most of them and continue to decide what is left.
How to use all this for testing?
Each test bench has its own dns-name on the network. Previously, to get access to the test bench, the tester entered hh.ru.standname and received a copy of the website hh.ru. It was quite simple, but did not allow testing many things and made it difficult to test mobile applications.
Now, thanks to the use of production configs for nginx, which do not really want to accept URIs that end in standname as input, the tester writes a proxy in his browser (squid is raised on each host machine) and opens in the browser hh.ru or any other site from of our pool (career.ru, jobs.tut.by, etc) and any of the third level domains, for example, nn.hh.ru.
Using a proxy allows you to easily test mobile applications by simply turning on the proxy in the wifi settings.
If the tester or developer wants to access the service and its port directly from the outside, then port forwarding is done using haproxy, for example, for debugging or other purposes.
Profit
At the moment, we are still in the process of transition to a new environment and realize all sorts of wishes that have appeared in the process of work. We have already transferred manual testing to new stands and the main release stand. In the near future we plan to transfer the auto-testing infrastructure to a new environment.

At the moment, we already have a profit in the following cases:
- for the release of a new service, the developer himself can write and test the ansible playbook and only then transfer it to the operation service. This allows you to test configs and the layout process as closely as possible to production;
- You can easily raise several instances of the same service in different containers and check the version compatibility or balancer operation when one of them is disconnected, or how the site will work if two instances out of three single services suddenly stop responding;
- You can check for some complex changes in the nginx configs or change the way webdav works;
- for debugging, you can easily connect a test server to our monitoring and conveniently investigate problems;
- while working on the new environment, many bugs were found and fixed in the production configuration and in ansible playbooks.
As with all innovations, there are those who are satisfied, and those who accept the new one with hostility. The main stumbling block is the use of a proxy - someone is not very comfortable, which is understandable. Together we will try to solve this problem.
The following plans complete the automation of the creation of stands for each release and the exclusion of a person from the build process and auto-testing releases.
Source: https://habr.com/ru/post/271221/
All Articles