Master class by Dmitry Sklyarov. DRM: yesterday, today and tomorrow
Today we continue the series of publications of master classes of our educational projects and present to your attention a post based on the speeches of Dmitry Sklyarov's speeches, which he conducted in the Technosphere and Technotrack. The topic of the presentation is Digital Rights Management. Watch the performance video on IT.MAIL.RU , and the text below.
The idea of this speech grew out of a report that I read at the DEFCON conference in 2001, after which I and the company I worked for (ElcomSoft) had some legal difficulties. 1.5 years after this speech, a trial was held in the United States, as a result of which the company was found not guilty on all five counts, but the story was loud enough. Years later, I decided to make a new version of that report, adding information about new trends in the field of Digital Rights Management (DRM).
I'll tell you how the idea of DRM. It all started with a domestic Betamax video recorder, which Sony released to the market in 1975. It became the first device to record TV broadcasts for later viewing. And in 1976, Sony received a lawsuit from Universal Studios and The Walt Disney Company, which said that the use of consumer video technology violates copyright. That is, I can record a movie from TV, and after that, for example, sell it or give it to someone who has nothing to do with television, or something like that. So Sony is guilty in advance of having created such a device, and such devices should be banned.
')

The court of first instance decided that this lawsuit does not make sense, since it is impossible to prevent users from viewing the programs at a convenient time for them, after having recorded them. But the appellate court agreed that the distribution of video recorders is a violation of copyright. At the same time, the public actively objected to such a decision, citing the following comparison as an argument: producing weapons is legal, and producing video recorders is for some reason a violation of the law. Thank God, the judicial system had time to think again, and in the last instance, in the Supreme Court, it was decided that the recording of television programs for private viewing does not violate copyrights, that this is the so-called Fair Use - a concept enshrined in US legislation. That is, a person has the right to watch what he is told, when he wants, and in the way he wants. It was a small victory. It's funny that in 1984 the lawsuit was won, and in 1989, Sony bought the Columbia Pictures studio and became the copyright owner, starting to produce films that could be copied using its technologies.
Content producers eventually came to terms with the existence of VCRs. The main argument was that when dubbing an analog image, there is a loss of quality. That is, it is impossible to rewrite one video tape to another 100 times in turn (from the first to the second, from the second to the third, etc.), because after a few iterations it will be impossible to watch.

In 1982, the first digital consumer product entered the market - CDs that could be listened to in special players. They had a very simple internal organization, a very simple recording format without any compression, a 16-bit stereo channel and a sampling frequency of 44.1 kHz. This time the pioneers were Sony and Phillips.

Five years after the CD, the next medium for digital sound recording, Digital Audio Tape, was launched. Studio tape recorders and personal players were produced for them, which made it possible to reproduce tapes in this format. The main feature of these tapes was to preserve the quality when rewriting. But the developers, taking into account the experience gained with video formats, laid the sampling rate not 48 KHz, but 48 KHz. It seems to be a good goal - to improve the sound quality. But if you try to rewrite a CD with a Digital Audio Tape, you cannot do this without D / A and A / D conversion, that is, without loss of quality. In fact, the specification introduced support for 44.1 kHz, but with restrictions. They concluded that if you have a cassette that someone recorded at 44.1 KHz, that is, at a CD, you can play it, but you will not be able to record such a tape yourself.
Further evolution has led to the fact that the possibility of rewriting a compact disc onto a digital magnetic tape with a sampling frequency of 44.1 kHz still appeared, but after that it is no longer possible to rewrite the data to another tape. That is, from 48 kHz to 48 kHz it is possible to rewrite, and from 44 kHz to 44 kHz - alas. Thus limited replication of compact discs on magnetic tapes. This was one of the first public manifestations of DRM, that is, digital content management was implemented with a ban on a number of operations.
The story of attempts to protect content on DVDs is widely known. In 1996, Sony offered the DVD market. At the design stage, it was possible to control who could watch the disc and who would not. For this, the world was divided into seven regions - seven zones. The disc and player must be released for the same zone - in this case, this player can play this disc. If the zones do not match, the disk will not be visible. The motivation was this: there are countries with low incomes, and there are rich America and Europe. Americans can afford to buy a disc for $ 12, but Africans do not. Therefore, we will sell Africans discs for $ 6, but you can only watch them on players that are sold in Africa. It is clear that African players will not be able to massively bring to America, and the disc purchased in Africa will not be played on the American player. Also provided protection against copying DVDs.
Generally, copying from disk to disk has become widely used with cheaper and increasing the number of writing drives. In 1994, I had the experience of dealing with a writing CD-drive, which then cost $ 1 thousand, and one disc to it - $ 35. In this case, about half of the blanks spoiled drive when recording. That is, to burn one disc will require $ 70. It is clear that it is much cheaper to buy original licensed CDs than to try to copy them at home. But when the cost of the blanks dropped to 10 cents, and the drives to $ 40, consumer copying issues became urgent.
In 1996, DVDs with the Content Scrambling System protection system were released onto the market, and in 1997 they developed the DeCSS program. There is no exact information about who, how and when it was developed, there are only guesses that by analyzing the software implementation of the XingDVD player, the algorithm and keys necessary for its operation were obtained. That is, while the DVD players were only hardware, it was difficult and expensive to analyze them, so no one did it. But as soon as the software implementation appeared, everything became quite simple - you sit down with the debugger and disassembler, find out how the program works, what is happening inside, ultimately build the exact same algorithm as in this player. This algorithm has been extracted and published on the Internet. Video companies have attempted to prohibit the publication of the text of the algorithm, the programs that implement it, as well as links to them. There was a small scandal with the publication of alt.2600, to which an injunction was banned from publishing a link to a page where you could familiarize yourself with the algorithm. Of course, users began to protest against the ban on distributing programs just because someone wanted to. As a result, it came to the point that the texts of DeCSS were printed on T-shirts. A very original implementation was also written - a Perl program that decrypts the content of a DVD. In just a few lines, people managed to fit everything they needed. They say it works, although I have not tried it.
Since the advent of protection technology until it was hacked, only a year has passed. As soon as some product enters the mass market, they soon begin to explore it, and sooner or later find ways to circumvent this protection.
I took up electronic books around 1999. At the same time, I was writing my dissertation on the Method for Analyzing Software for Protecting Electronic Documents. I started to see what technologies exist on the market and how hard it is to compromise them.
A little bit about how electronic publishing works and how it differs from the traditional one. When we talk about the publication of an ordinary paper book, we understand that the process is very long: first, the author must write a book (by hand or on a computer). Then the typist will type 300 or 400 pages of text in a fairly short time. After the text is translated into electronic form, you need to lay out the page to see how they will look on print. Once it was done by hands: lead letters were inserted into a special box, they were smeared with paint, and then the page was printed. Then mechanical semi-automatic machines began to do this, and the layout designer simply typed the text with buttons. Now everything is done on the computer. After that, the images of the folded pages are printed out and printed. Perhaps now there are printing houses that print fairly large circulations without an intermediate stage with films — immediately from an electronic layout.
After the paper sheets are printed, they must be cut, stitched, stitched and pasted the cover. Next you need to solve logistics issues so that the products first get to the warehouse, and then to the shops where the person comes, find a book of interest on the shelf and buy it. This has been the case for the past 200 years, for there is an active book printing and book trade.
What has changed with the transition to electronic editions? The first two stages are the same: write a book, then make them. But then you can literally press one button to make this book in the device for reading - in the reader. Thus, several costly stages are excluded: printing, logistics, payment of retail space, remuneration of employees at each stage. It would seem that the e-book should be very much cheaper for the end user. I myself, for example, am the author of one book, and under the contract I received, if I am not mistaken, 12% of the wholesale cost of each copy. Plus, the store still about 100% wound up and put the book on sale. That is, the share of royalties in the total cost of the book is small, mostly the price is the cost of raw materials, salaries and overhead costs.
E-books have a lot of advantages in comparison with paper ones. They are much cheaper to make, and you can also replicate indefinitely. The book I wrote was produced in three editions of 3 thousand copies, and now it is no longer possible to buy it in stores. True, the network has a scanned copy, and recently began to more or less officially trade through the Ozon electronic version of the book.
Also, e-books get to readers faster. You can carry in one reader at least the entire encyclopedia "Britannica", the paper version of which consists of 50 volumes. E-books allow you to quickly find the desired text, they do not wear out, they can implement navigation mechanisms such as hyperlinks, insert multimedia objects, animation, sound - beauty, convenience and joy for those who want to deliver their content to consumers and for those who this content consumes.
But along with the advantages of e-books have disadvantages. Firstly, the format is often associated with the type of reader - that is, what can be read on one reader, on the other can be unreadable (but this problem can be solved with the help of special software - by converting to other formats). Secondly, and this is the main problem of electronic books, control of compliance with copyright is imposed here. If I want to replicate a paper book, then I need to scan each page, print it, then somehow stitch it, glue the cover, and only then can I give it away or sell it. The cost of the copy will be high, probably even more expensive than the original, if we are talking about comparable quality. And an e-book is just a file that can be sent out in millions of copies. And now the right holder has lost control over the distribution, everyone reads, and no one pays the money. This is the biggest horror story for copyright holders who want to make as much money as possible. They can also be understood. As a result, e-book protection technologies began to appear that can be read, but there are restrictions on certain operations.
The market of electronic books as of 2000 can be roughly divided into three categories.
A few years ago, a friend of my boss, himself engaged in publishing some educational materials, wanted to protect these materials. Online, he came across eBook Pro Compiler, which positioned itself as (free translation from English) “The only software in the Universe that makes your information almost 100% protected from hacking comes with a lifetime money back guarantee, if you something not like it. Finally, you can sell information online and make thousands of sales daily without the risk that your information will be stolen or sold by others . ” That is, it was stated that this program is the coolest solution for publishers in the world. But to sell thousands of copies a day, you need to have such good content that thousands of people want to buy it a day. If your name is Daria Dontsova, then you have the chance to write a book that in the first couple of months will be bought by a thousand people a day. If you are writing a scientific textbook, then, having sold only 10 thousand copies, we can say that you are lucky, because, unfortunately, we don’t use smart books.
Believing advertising, my boss's friend bought this program. It turned out that by opening the compiled "protected" book, using the Ctrl + A and Ctrl + Insert combinations, you can get all the content of the current page in the clipboard, paste it into Word, and now you have stolen the content. You could also go to the Temp directory and find all the HTML pages and pictures as they were before you compiled the book. And they will still be in the temporary directory, because the compiler used the Internet Explorer engine to view e-books. And the developers did not even bother to implement a mechanism for storing the original data in memory, and not on disk. That is, they simply unloaded them onto a disk and told IE: “Show us these files from the disk”. Completely childish implementation of the process of working with protected content. I dug a little with the debugger-disassembler and understood how the format works. All data from which the book consists (pictures, CSS, HTML), are packed into a container, from which they are then extracted at the moment of display. For packaging, the free and open Zlib library is used, and the data itself is encrypted with a very interesting algorithm: all bytes of the word “encrypted” are successively superimposed on each byte of the encrypted data using the XOR operation. The people who wrote this, not only do not understand anything in cryptography, but do not even know how XOR works. After all, XOR in series with different bytes can be reduced to XOR with one byte. That is, they all content xorili with one single-byte constant. This does not provide any protection, but nonetheless calmly argued the opposite.
I will not say about all the e-book creation systems that I mentioned earlier, but I think that a good half of them were similar. Content protection has one feature. For example, as a graphic editor you use Photoshop and compare it with the Gimp. In some operations, Photoshop works much better or much worse - it does not matter. You see the difference. Input data are the same, and the result is different. But when you protect something, encrypt, it is impossible to evaluate the result "by eye". How to understand, good protection or bad? Can it be hacked or not, is it easy or difficult? The fact that you have been hacked, you will know only when it happens. And the degree of ease of hacking can not be adequately assessed if you do not understand the technology of information protection. Therefore, unfortunately, there have always been a lot of bad decisions on the market, they will not disappear anywhere and will be successfully sold, because selling a good solution without a beautiful wrapper is much more difficult than selling a bad solution in a beautiful wrapper. If you have an advertising budget, you are on a horse, and your safety products will be purchased regardless of their quality.

In my research I paid special attention to PDF files. I studied their device, the content security mechanisms incorporated into them. At that time, the volume of the PDF specification was about 600 pages, of which 20-30 pages concerned safety and were of the greatest interest. Since then, the specification has been rewritten many times, and the latest versions are supported, if I'm not mistaken, not by Adobe, but by some of the ISO subcommittees. That is, PDF is trying to make an international standard. When designing this format (Portable Document Format) one of the main tasks was to ensure the same display on all devices. Why is this so important? Surely you found yourself in a situation where, creating a complex document in Word on one computer, and typing on another, it turned out that the layout was “floated”, the pictures did not fit, etc. The reason is that Microsoft Word is not a publishing system, but a system for preparing texts, not intended for creating full-fledged layouts for printing.
PDF was designed to be more compact than Postscript, a format that can be opened and printed on any platform. It was also meant that this format is not intended for editing, but is intended for incremental update. That is, the document can be supplemented, remove something, add a remark. To do this, the developers decided that the viewer should read the document from the end. The so-called trailer is stored there, from which information about where the Cross Reference Table object allocation table is located is taken. The file itself consists of a header, a set of objects, a cross reference table and a trailer. With the Cross Reference Table, you can quickly find an object in the file by its number. If you want to add something new to the file, you add new objects, a new Cross Reference Table and a new trailer. In this case, you will not modify the beginning of the file.
An object can be either some kind of data element, or a so-called stream. A stream consists of a dictionary, a descriptor that allows you to set characteristics for data that will be in the stream, and some binary data set that is not defined by the standard. But the possibilities of its interpretation are defined, that is, what may actually be in the stream. In the stream there may be a description of a page on a subset of the Postscript language, there may be a picture, etc. There are quite a few basic data types:
According to the original idea, when you change an existing object, a new version of this object is recorded, and the generation value is incremented by one, although the object number remains the same. The maximum value is 65 534. 65 535 means that this object has been deleted and will no longer be used.
In practice, all PDF update systems remove old objects and append new ones with new numbers, because this is easier. I have not seen a single real document in which the generation would be equal to one or more.
There is an object of the “name” type, it starts with a slash, then letters, numbers, a dot and an underscore can go on. There is an object of type "string" - this is a simple data set. The name size is limited to 128 bytes, the string has no length limit. The main object that stores all the content is the same stream that can be compressed, packaged, encrypted, etc. There are two complex data types. If you use the Python language, this will be familiar to you. An array type object is a sequentially arranged ordered element that can be accessed by indices. In this case, in the array, the first element is the reference to the 23rd object, then the name XYZ, and then the zero object. The dictionary is unsorted named values. There is a pair of "name - value; name - value ". In this case, the value can be any object other than a stream. That is, your value can be another dictionary or another array, or reference to the object that contains the stream.
With the help of such a simple set of objects, one can describe an arbitrarily complex data structure necessary for the presentation of a document.

The encryption specification was developed by Adobe before PDFs began to be used to store documents protected by DRM. Initially, it was provided that the so-called Encryption Dictionary is stored in a specific place in the document - a dictionary that describes all the security parameters and how the document should be decrypted. One of the elements of the Encryption Dictionary is the name of the Security Handler. This program, which takes from the Encryption Dictionary document, requests additional information that is needed to confirm the user's right to open the document. What it will be - the program decides. You can ask for a password, you can go online, you can look at the current date, compare it with the protection in the document and decide whether the document is overdue.
If the program decides that the content can be shown, it uses a certain algorithm to compute a new entity called the Document Encryption Key. In fact, Security Handler does not work by itself, but as a viewer component. Adobe Acrobat was the main PDF viewer at the time - there were almost no competing solutions. Acrobat could be expanded using plugins, including to ensure data protection. If the viewer detected that the document was protected, he called a special function from the plug-in and transferred the Encryption Dictionary to it, the plug-in processed and returned the key with which the viewer decrypted the content and showed it to the user. With the advent of Digital Rights Management, Adobe did not intend to change this approach: "We will write new Security Handlers that will implement DRM to us." Security handlers as of 2000 existed quite a lot. I will tell about them in more detail.
The specification said how to get the decrypted document from the Document Encryption Key. RC4 streaming algorithm was used for encryption. It has such a feature: if you encrypt two different objects with the same key, they are encrypted in the gamma generator mode. That is, a pseudo-random sequence that is almost unlimited in length is generated from the key, and the XOR is superimposed on the processed data. When encrypting two objects with one key, a plaintext attack is possible. If you know a pair of "plaintext - encrypted text" for one object, you do XOR between them, recognize the scale and can decrypt the second object. , , : « , ». , ID Generation, - MD5, .
. Object ID Generation , , sAlT. — . « » — . — . PDF … «». — , . , , - . , , , . , , . , 40 , - . , PDF 40 . .
Security Handler- Standart Security Handler. Acrobat . , . :
. owner-, , . , , , . . , , , . , , , , , . . , .
Acrobat . , - , . — . — . , . — . , 300 dpi, 1600 dpi .
«» — . , , , . MD5 RC4. 190 . . , 100 . . Security Handler Adobe , , — 51 MD5 20 RC4 . 3,25 . . — . : ZIP , 1 . RAR 3 ( 450 MHz) — 30 . Microsoft - BitLocker, Windows 7 BitLocker to Go, - . 3,25 . ( 190 .) — . Adobe - .
2000 . 40 . . Pentium 3450 MHz 960 , — , — . , . 512 . , , 15 . , , , .
Security Handler-, — , Security Handler Rot13. New Paradigm Resource Group, — . $3 . . , 99% sample-, SDK Acrobat. SDK, , , . , -, , .
FileOpen. , - PDF-. , , Adobe, . FileOpen : , . $2,5 . security- Adobe , Acrobat 5 . , 2.3 . 2.4 , , . 40-, .
SoftLock Security Handler. : , ID . , : «ID -. ». ID , , . , , ID . Document Encryption Key, . . , , «». 24 40, 30 .
Adobe — Adobe WebBuy (PDF Merchant). , RMF- (Rights Management), . :
, Document Encryption Key RSA- , . 1024 , — 768 . , , .
, Adobe, . . PDF RMF, - Document Encryption Key . , Adobe, , « . — ».
GlassBook, Adobe 2000 . eBook Reader Adobe. GlassBook EBX (Electronic Book Exchange), - . , , «» «», «» . , «» . «», . «» .
RSA-. , ID, . , , Document Encryption Key, , . , . , Document Encryption Key RSA . Document Encryption Key, . , Document Encryption Key . . , . Adobe .

GlassBook Reader . , SHA1 . son.dat . , , , son.dat .
, mor.dat, RC5, RSA Private Key. , , Document Encryption Key, . .

A little note. — Document Encryption Key, Object Encryption Key. , . . Document Encryption Key, . Document Encryption Key MD5, — , , .
Acrobat , . Acrobat , . Acrobat DocBox, .
GlassBook PACE InterLok — . , , , Mac Windows, GlassBook Mac Windows.
InterLok . , API « ». BSOD. GlassBook, , , , , — . ? , , Visual Studio, , , , . Visual Studio, . , . , . PACE InterLok , , — .
PDF
MD5? , :
: Init, Update, , Final. Init , , , , . , Update. Update . 64 , MD5, Transform, Update.
: , Adobe, sAlT. , . , , . , — MD5 Update. Update , . , , . Security Handler- . , , . .
, PDF, , Adobe Acrobat Adobe Reader. Adobe Digital Rights Management , :
DRM Adobe « ». Adobe, DRM . , , WebBuy, . , Reader Acrobat , , Adobe. Why? SDK Acrobat API . , . , «», .
Adobe ? , , . , Adobe, , , , - , , - DLL. , , . Visual Studio, C Acrobat Reader. , . , .
RSA 512 ( 512 1999 .). . . Adobe , , SDK . , , , .
2001 . Digital Rights Management, ? , Rainbow Tables. 1970- , « ». , , , . 40- PDF , 4 , (- ). 15 , — 10 . , 40- .
Adobe Acrobat 256 AES, . , . Adobe . , 50 . , , , 100 .
, , — . , Adobe, — . . 12 (, , ), . , , , .
MD5 Acrobat Reader . . Adobe : , . RSA 1024. , , . , , . , Acrobat, , , , Acrobat , , SDK Acrobat, . , Adobe.
Security Handler :
Adobe Security Handler. $100 , $25 . , . , , , . ? , , Panasonic Crypto NewsStand, . , . , , , - . , . .
Adobe, PDF — . , , . , . Digital Rights Management: , , , , - .
Adobe — . Adobe Digital Editions. C Flash, Flash. — PDF ePub. PDF MD5 Update. ePub AES. ePub , , , , , , . , - AES. AES, .
, , LIT- . Microsoft , , . Microsoft , . Microsoft, , , .
LIT. Microsoft, , . Compound Storage. Microsoft, . , Word Excel , CHM.
: , : « », GUID, iStorage, , « », « » « ». handle iStream, , , . , - iStorage. , , DLL , , Microsoft , , , . , Microsoft , .
Microsoft Reader LIT , Windows 8 2003 . , , .
2006 . Blu-ray, Advanced Access Content System — CSS (Content Scrambling System). , - , . , , , , — .
. . , , HDMI. HDCP (High Definition Content Protection) , . , , Blu-ray . , High Definition Content Protection , Advanced Access Content System 2007 ., . , , . , DVD, Blu-ray.
, — . , , , . — .
, - , . , Apple , , . , . - , . — .
— . , PDF , , API . Adobe . . Microsoft LIT, Compound Storage.
— Digital Millennium Copyright Act . , 1980- Betamax. , , . , , , — . , , , PDF . , , , . .
, , . , , , .
-, . , . . , . — , . . , .
Apple, iTunes. - $12, 12 . ITunes — $1 . , , , - , — , 12. iTunes , . ?
, ( , ) . , 2003 . Amazon :
, , . : « , , ». , , , , .
, , DRM, . Watermarking , , . , , .
Penaut Press, Palm, . , . , — , , , . . , , , , , . - — , , , . , , . . , , « ».
, Apple — . , iBooks. , . , . , , - , - , — . — . — , - .
, . , , , . -, - . How? I do not know. , , .
The idea of this speech grew out of a report that I read at the DEFCON conference in 2001, after which I and the company I worked for (ElcomSoft) had some legal difficulties. 1.5 years after this speech, a trial was held in the United States, as a result of which the company was found not guilty on all five counts, but the story was loud enough. Years later, I decided to make a new version of that report, adding information about new trends in the field of Digital Rights Management (DRM).
DRM in audio and video
I'll tell you how the idea of DRM. It all started with a domestic Betamax video recorder, which Sony released to the market in 1975. It became the first device to record TV broadcasts for later viewing. And in 1976, Sony received a lawsuit from Universal Studios and The Walt Disney Company, which said that the use of consumer video technology violates copyright. That is, I can record a movie from TV, and after that, for example, sell it or give it to someone who has nothing to do with television, or something like that. So Sony is guilty in advance of having created such a device, and such devices should be banned.
')
The court of first instance decided that this lawsuit does not make sense, since it is impossible to prevent users from viewing the programs at a convenient time for them, after having recorded them. But the appellate court agreed that the distribution of video recorders is a violation of copyright. At the same time, the public actively objected to such a decision, citing the following comparison as an argument: producing weapons is legal, and producing video recorders is for some reason a violation of the law. Thank God, the judicial system had time to think again, and in the last instance, in the Supreme Court, it was decided that the recording of television programs for private viewing does not violate copyrights, that this is the so-called Fair Use - a concept enshrined in US legislation. That is, a person has the right to watch what he is told, when he wants, and in the way he wants. It was a small victory. It's funny that in 1984 the lawsuit was won, and in 1989, Sony bought the Columbia Pictures studio and became the copyright owner, starting to produce films that could be copied using its technologies.
Content producers eventually came to terms with the existence of VCRs. The main argument was that when dubbing an analog image, there is a loss of quality. That is, it is impossible to rewrite one video tape to another 100 times in turn (from the first to the second, from the second to the third, etc.), because after a few iterations it will be impossible to watch.
In 1982, the first digital consumer product entered the market - CDs that could be listened to in special players. They had a very simple internal organization, a very simple recording format without any compression, a 16-bit stereo channel and a sampling frequency of 44.1 kHz. This time the pioneers were Sony and Phillips.
Five years after the CD, the next medium for digital sound recording, Digital Audio Tape, was launched. Studio tape recorders and personal players were produced for them, which made it possible to reproduce tapes in this format. The main feature of these tapes was to preserve the quality when rewriting. But the developers, taking into account the experience gained with video formats, laid the sampling rate not 48 KHz, but 48 KHz. It seems to be a good goal - to improve the sound quality. But if you try to rewrite a CD with a Digital Audio Tape, you cannot do this without D / A and A / D conversion, that is, without loss of quality. In fact, the specification introduced support for 44.1 kHz, but with restrictions. They concluded that if you have a cassette that someone recorded at 44.1 KHz, that is, at a CD, you can play it, but you will not be able to record such a tape yourself.
Further evolution has led to the fact that the possibility of rewriting a compact disc onto a digital magnetic tape with a sampling frequency of 44.1 kHz still appeared, but after that it is no longer possible to rewrite the data to another tape. That is, from 48 kHz to 48 kHz it is possible to rewrite, and from 44 kHz to 44 kHz - alas. Thus limited replication of compact discs on magnetic tapes. This was one of the first public manifestations of DRM, that is, digital content management was implemented with a ban on a number of operations.
The story of attempts to protect content on DVDs is widely known. In 1996, Sony offered the DVD market. At the design stage, it was possible to control who could watch the disc and who would not. For this, the world was divided into seven regions - seven zones. The disc and player must be released for the same zone - in this case, this player can play this disc. If the zones do not match, the disk will not be visible. The motivation was this: there are countries with low incomes, and there are rich America and Europe. Americans can afford to buy a disc for $ 12, but Africans do not. Therefore, we will sell Africans discs for $ 6, but you can only watch them on players that are sold in Africa. It is clear that African players will not be able to massively bring to America, and the disc purchased in Africa will not be played on the American player. Also provided protection against copying DVDs.
Generally, copying from disk to disk has become widely used with cheaper and increasing the number of writing drives. In 1994, I had the experience of dealing with a writing CD-drive, which then cost $ 1 thousand, and one disc to it - $ 35. In this case, about half of the blanks spoiled drive when recording. That is, to burn one disc will require $ 70. It is clear that it is much cheaper to buy original licensed CDs than to try to copy them at home. But when the cost of the blanks dropped to 10 cents, and the drives to $ 40, consumer copying issues became urgent.
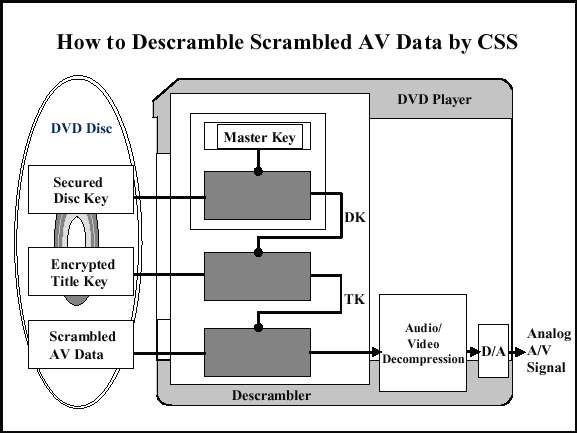
In 1996, DVDs with the Content Scrambling System protection system were released onto the market, and in 1997 they developed the DeCSS program. There is no exact information about who, how and when it was developed, there are only guesses that by analyzing the software implementation of the XingDVD player, the algorithm and keys necessary for its operation were obtained. That is, while the DVD players were only hardware, it was difficult and expensive to analyze them, so no one did it. But as soon as the software implementation appeared, everything became quite simple - you sit down with the debugger and disassembler, find out how the program works, what is happening inside, ultimately build the exact same algorithm as in this player. This algorithm has been extracted and published on the Internet. Video companies have attempted to prohibit the publication of the text of the algorithm, the programs that implement it, as well as links to them. There was a small scandal with the publication of alt.2600, to which an injunction was banned from publishing a link to a page where you could familiarize yourself with the algorithm. Of course, users began to protest against the ban on distributing programs just because someone wanted to. As a result, it came to the point that the texts of DeCSS were printed on T-shirts. A very original implementation was also written - a Perl program that decrypts the content of a DVD. In just a few lines, people managed to fit everything they needed. They say it works, although I have not tried it.
#!/usr/bin/perl # 472-byte qrpff, Keith Winstein and Marc Horowitz <sipb-iap-dvd@mit.edu> # MPEG 2 PS VOB file -> descrambled output on stdout. # usage: perl -I <k1>:<k2>:<k3>:<k4>:<k5> qrpff # where k1..k5 are the title key bytes in least to most-significant order s''$/=\2048;while(<>){G=29;R=142;if((@a=unqT="C*",_)[20]&48){D=89;_=unqb24,qT,@ b=map{ord qB8,unqb8,qT,_^$a[--D]}@INC;s/...$/1$&/;Q=unqV,qb25,_;H=73;O=$b[4]<<9 |256|$b[3];Q=Q>>8^(P=(E=255)&(Q>>12^Q>>4^Q/8^Q))<<17,O=O>>8^(E&(F=(S=O>>14&7^O) ^S*8^S<<6))<<9,_=(map{U=_%16orE^=R^=110&(S=(unqT,"\xb\ntd\xbz\x14d")[_/16%8]);E ^=(72,@z=(64,72,G^=12*(U-2?0:S&17)),H^=_%64?12:0,@z)[_%8]}(16..271))[_]^((D>>=8 )+=P+(~F&E))for@a[128..$#a]}print+qT,@a}';s/[D-HO-U_]/\$$&/g;s/q/pack+/g;eval Since the advent of protection technology until it was hacked, only a year has passed. As soon as some product enters the mass market, they soon begin to explore it, and sooner or later find ways to circumvent this protection.
DRM in the field of electronic books
I took up electronic books around 1999. At the same time, I was writing my dissertation on the Method for Analyzing Software for Protecting Electronic Documents. I started to see what technologies exist on the market and how hard it is to compromise them.
A little bit about how electronic publishing works and how it differs from the traditional one. When we talk about the publication of an ordinary paper book, we understand that the process is very long: first, the author must write a book (by hand or on a computer). Then the typist will type 300 or 400 pages of text in a fairly short time. After the text is translated into electronic form, you need to lay out the page to see how they will look on print. Once it was done by hands: lead letters were inserted into a special box, they were smeared with paint, and then the page was printed. Then mechanical semi-automatic machines began to do this, and the layout designer simply typed the text with buttons. Now everything is done on the computer. After that, the images of the folded pages are printed out and printed. Perhaps now there are printing houses that print fairly large circulations without an intermediate stage with films — immediately from an electronic layout.
After the paper sheets are printed, they must be cut, stitched, stitched and pasted the cover. Next you need to solve logistics issues so that the products first get to the warehouse, and then to the shops where the person comes, find a book of interest on the shelf and buy it. This has been the case for the past 200 years, for there is an active book printing and book trade.
What has changed with the transition to electronic editions? The first two stages are the same: write a book, then make them. But then you can literally press one button to make this book in the device for reading - in the reader. Thus, several costly stages are excluded: printing, logistics, payment of retail space, remuneration of employees at each stage. It would seem that the e-book should be very much cheaper for the end user. I myself, for example, am the author of one book, and under the contract I received, if I am not mistaken, 12% of the wholesale cost of each copy. Plus, the store still about 100% wound up and put the book on sale. That is, the share of royalties in the total cost of the book is small, mostly the price is the cost of raw materials, salaries and overhead costs.
E-books have a lot of advantages in comparison with paper ones. They are much cheaper to make, and you can also replicate indefinitely. The book I wrote was produced in three editions of 3 thousand copies, and now it is no longer possible to buy it in stores. True, the network has a scanned copy, and recently began to more or less officially trade through the Ozon electronic version of the book.
Also, e-books get to readers faster. You can carry in one reader at least the entire encyclopedia "Britannica", the paper version of which consists of 50 volumes. E-books allow you to quickly find the desired text, they do not wear out, they can implement navigation mechanisms such as hyperlinks, insert multimedia objects, animation, sound - beauty, convenience and joy for those who want to deliver their content to consumers and for those who this content consumes.
But along with the advantages of e-books have disadvantages. Firstly, the format is often associated with the type of reader - that is, what can be read on one reader, on the other can be unreadable (but this problem can be solved with the help of special software - by converting to other formats). Secondly, and this is the main problem of electronic books, control of compliance with copyright is imposed here. If I want to replicate a paper book, then I need to scan each page, print it, then somehow stitch it, glue the cover, and only then can I give it away or sell it. The cost of the copy will be high, probably even more expensive than the original, if we are talking about comparable quality. And an e-book is just a file that can be sent out in millions of copies. And now the right holder has lost control over the distribution, everyone reads, and no one pays the money. This is the biggest horror story for copyright holders who want to make as much money as possible. They can also be understood. As a result, e-book protection technologies began to appear that can be read, but there are restrictions on certain operations.
The market of electronic books as of 2000 can be roughly divided into three categories.
- The first category is quite large, and, in my opinion, quite confused - the so-called software compilers and e-book readers that allowed you to take a text file, HTML or Word document and turn it into an executable file. For reading, you had to enter a password or activate via the Internet. That is, the output was something more or less protected, working as an executable file or as a separate viewing program that can display files created by a particular program. It is clear that for the user the program itself was free to view, but you had to pay for the content. The publishers themselves, who wanted to distribute their books through some programs, had to pay them to the developers.
- The second category is “iron” readers. Now they have become a mass product, but at that time there were only two models of these devices (as far as I know). At that time, the readers were with black and white LCD screens of not very good quality: RocketBook and eBookMan Reader. The first was slightly more popular. About the distribution of secure e-books for these devices, I, unfortunately, do not know anything.
- The third category is the market segment that two large companies tried to seize, having decided that the market has a future and it will bring revenue. The first is Adobe, which had long since developed PDF. Based on this format, she tried to create a commercial e-book technology so that people pay for the content of the document. The second major player is Microsoft, which produces a line of Pocket PC devices. She developed Reader.Lit (Literature) technology so that you can read protected documents in .lit format either on a personal computer or on a handheld device, depending on the activation method.
A few years ago, a friend of my boss, himself engaged in publishing some educational materials, wanted to protect these materials. Online, he came across eBook Pro Compiler, which positioned itself as (free translation from English) “The only software in the Universe that makes your information almost 100% protected from hacking comes with a lifetime money back guarantee, if you something not like it. Finally, you can sell information online and make thousands of sales daily without the risk that your information will be stolen or sold by others . ” That is, it was stated that this program is the coolest solution for publishers in the world. But to sell thousands of copies a day, you need to have such good content that thousands of people want to buy it a day. If your name is Daria Dontsova, then you have the chance to write a book that in the first couple of months will be bought by a thousand people a day. If you are writing a scientific textbook, then, having sold only 10 thousand copies, we can say that you are lucky, because, unfortunately, we don’t use smart books.
Believing advertising, my boss's friend bought this program. It turned out that by opening the compiled "protected" book, using the Ctrl + A and Ctrl + Insert combinations, you can get all the content of the current page in the clipboard, paste it into Word, and now you have stolen the content. You could also go to the Temp directory and find all the HTML pages and pictures as they were before you compiled the book. And they will still be in the temporary directory, because the compiler used the Internet Explorer engine to view e-books. And the developers did not even bother to implement a mechanism for storing the original data in memory, and not on disk. That is, they simply unloaded them onto a disk and told IE: “Show us these files from the disk”. Completely childish implementation of the process of working with protected content. I dug a little with the debugger-disassembler and understood how the format works. All data from which the book consists (pictures, CSS, HTML), are packed into a container, from which they are then extracted at the moment of display. For packaging, the free and open Zlib library is used, and the data itself is encrypted with a very interesting algorithm: all bytes of the word “encrypted” are successively superimposed on each byte of the encrypted data using the XOR operation. The people who wrote this, not only do not understand anything in cryptography, but do not even know how XOR works. After all, XOR in series with different bytes can be reduced to XOR with one byte. That is, they all content xorili with one single-byte constant. This does not provide any protection, but nonetheless calmly argued the opposite.
I will not say about all the e-book creation systems that I mentioned earlier, but I think that a good half of them were similar. Content protection has one feature. For example, as a graphic editor you use Photoshop and compare it with the Gimp. In some operations, Photoshop works much better or much worse - it does not matter. You see the difference. Input data are the same, and the result is different. But when you protect something, encrypt, it is impossible to evaluate the result "by eye". How to understand, good protection or bad? Can it be hacked or not, is it easy or difficult? The fact that you have been hacked, you will know only when it happens. And the degree of ease of hacking can not be adequately assessed if you do not understand the technology of information protection. Therefore, unfortunately, there have always been a lot of bad decisions on the market, they will not disappear anywhere and will be successfully sold, because selling a good solution without a beautiful wrapper is much more difficult than selling a bad solution in a beautiful wrapper. If you have an advertising budget, you are on a horse, and your safety products will be purchased regardless of their quality.
PDF structure
In my research I paid special attention to PDF files. I studied their device, the content security mechanisms incorporated into them. At that time, the volume of the PDF specification was about 600 pages, of which 20-30 pages concerned safety and were of the greatest interest. Since then, the specification has been rewritten many times, and the latest versions are supported, if I'm not mistaken, not by Adobe, but by some of the ISO subcommittees. That is, PDF is trying to make an international standard. When designing this format (Portable Document Format) one of the main tasks was to ensure the same display on all devices. Why is this so important? Surely you found yourself in a situation where, creating a complex document in Word on one computer, and typing on another, it turned out that the layout was “floated”, the pictures did not fit, etc. The reason is that Microsoft Word is not a publishing system, but a system for preparing texts, not intended for creating full-fledged layouts for printing.
PDF was designed to be more compact than Postscript, a format that can be opened and printed on any platform. It was also meant that this format is not intended for editing, but is intended for incremental update. That is, the document can be supplemented, remove something, add a remark. To do this, the developers decided that the viewer should read the document from the end. The so-called trailer is stored there, from which information about where the Cross Reference Table object allocation table is located is taken. The file itself consists of a header, a set of objects, a cross reference table and a trailer. With the Cross Reference Table, you can quickly find an object in the file by its number. If you want to add something new to the file, you add new objects, a new Cross Reference Table and a new trailer. In this case, you will not modify the beginning of the file.
An object can be either some kind of data element, or a so-called stream. A stream consists of a dictionary, a descriptor that allows you to set characteristics for data that will be in the stream, and some binary data set that is not defined by the standard. But the possibilities of its interpretation are defined, that is, what may actually be in the stream. In the stream there may be a description of a page on a subset of the Postscript language, there may be a picture, etc. There are quite a few basic data types:
- empty object (zero);
- boolean true or false;
- real or integer numeric;
- link to another object by number. 23 0 R - object reference. R is the reference sign, 23 is the object number, 0 is the object generation.
According to the original idea, when you change an existing object, a new version of this object is recorded, and the generation value is incremented by one, although the object number remains the same. The maximum value is 65 534. 65 535 means that this object has been deleted and will no longer be used.
In practice, all PDF update systems remove old objects and append new ones with new numbers, because this is easier. I have not seen a single real document in which the generation would be equal to one or more.
There is an object of the “name” type, it starts with a slash, then letters, numbers, a dot and an underscore can go on. There is an object of type "string" - this is a simple data set. The name size is limited to 128 bytes, the string has no length limit. The main object that stores all the content is the same stream that can be compressed, packaged, encrypted, etc. There are two complex data types. If you use the Python language, this will be familiar to you. An array type object is a sequentially arranged ordered element that can be accessed by indices. In this case, in the array, the first element is the reference to the 23rd object, then the name XYZ, and then the zero object. The dictionary is unsorted named values. There is a pair of "name - value; name - value ". In this case, the value can be any object other than a stream. That is, your value can be another dictionary or another array, or reference to the object that contains the stream.
With the help of such a simple set of objects, one can describe an arbitrarily complex data structure necessary for the presentation of a document.
PDF Encryption
The encryption specification was developed by Adobe before PDFs began to be used to store documents protected by DRM. Initially, it was provided that the so-called Encryption Dictionary is stored in a specific place in the document - a dictionary that describes all the security parameters and how the document should be decrypted. One of the elements of the Encryption Dictionary is the name of the Security Handler. This program, which takes from the Encryption Dictionary document, requests additional information that is needed to confirm the user's right to open the document. What it will be - the program decides. You can ask for a password, you can go online, you can look at the current date, compare it with the protection in the document and decide whether the document is overdue.
If the program decides that the content can be shown, it uses a certain algorithm to compute a new entity called the Document Encryption Key. In fact, Security Handler does not work by itself, but as a viewer component. Adobe Acrobat was the main PDF viewer at the time - there were almost no competing solutions. Acrobat could be expanded using plugins, including to ensure data protection. If the viewer detected that the document was protected, he called a special function from the plug-in and transferred the Encryption Dictionary to it, the plug-in processed and returned the key with which the viewer decrypted the content and showed it to the user. With the advent of Digital Rights Management, Adobe did not intend to change this approach: "We will write new Security Handlers that will implement DRM to us." Security handlers as of 2000 existed quite a lot. I will tell about them in more detail.
The specification said how to get the decrypted document from the Document Encryption Key. RC4 streaming algorithm was used for encryption. It has such a feature: if you encrypt two different objects with the same key, they are encrypted in the gamma generator mode. That is, a pseudo-random sequence that is almost unlimited in length is generated from the key, and the XOR is superimposed on the processed data. When encrypting two objects with one key, a plaintext attack is possible. If you know a pair of "plaintext - encrypted text" for one object, you do XOR between them, recognize the scale and can decrypt the second object. , , : « , ». , ID Generation, - MD5, .
. Object ID Generation , , sAlT. — . « » — . — . PDF … «». — , . , , - . , , , . , , . , 40 , - . , PDF 40 . .
Security Handler- Standart Security Handler. Acrobat . , . :
- user-, , ;
- owner-, .
. owner-, , . , , , . . , , , . , , , , , . . , .
Acrobat . , - , . — . — . , . — . , 300 dpi, 1600 dpi .
«» — . , , , . MD5 RC4. 190 . . , 100 . . Security Handler Adobe , , — 51 MD5 20 RC4 . 3,25 . . — . : ZIP , 1 . RAR 3 ( 450 MHz) — 30 . Microsoft - BitLocker, Windows 7 BitLocker to Go, - . 3,25 . ( 190 .) — . Adobe - .
2000 . 40 . . Pentium 3450 MHz 960 , — , — . , . 512 . , , 15 . , , , .
Security Handler
Security Handler-, — , Security Handler Rot13. New Paradigm Resource Group, — . $3 . . , 99% sample-, SDK Acrobat. SDK, , , . , -, , .
FileOpen. , - PDF-. , , Adobe, . FileOpen : , . $2,5 . security- Adobe , Acrobat 5 . , 2.3 . 2.4 , , . 40-, .
SoftLock Security Handler. : , ID . , : «ID -. ». ID , , . , , ID . Document Encryption Key, . . , , «». 24 40, 30 .
Adobe — Adobe WebBuy (PDF Merchant). , RMF- (Rights Management), . :
- , ;
- , ;
- ;
- .
, Document Encryption Key RSA- , . 1024 , — 768 . , , .
, Adobe, . . PDF RMF, - Document Encryption Key . , Adobe, , « . — ».
GlassBook
GlassBook, Adobe 2000 . eBook Reader Adobe. GlassBook EBX (Electronic Book Exchange), - . , , «» «», «» . , «» . «», . «» .
RSA-. , ID, . , , Document Encryption Key, , . , . , Document Encryption Key RSA . Document Encryption Key, . , Document Encryption Key . . , . Adobe .
GlassBook Reader . , SHA1 . son.dat . , , , son.dat .
, mor.dat, RC5, RSA Private Key. , , Document Encryption Key, . .
A little note. — Document Encryption Key, Object Encryption Key. , . . Document Encryption Key, . Document Encryption Key MD5, — , , .
Acrobat , . Acrobat , . Acrobat DocBox, .
GlassBook PACE InterLok — . , , , Mac Windows, GlassBook Mac Windows.
InterLok . , API « ». BSOD. GlassBook, , , , , — . ? , , Visual Studio, , , , . Visual Studio, . , . , . PACE InterLok , , — .
MD5? , :
- Init, — ;
- Update, , ;
- Final, .
: Init, Update, , Final. Init , , , , . , Update. Update . 64 , MD5, Transform, Update.
: , Adobe, sAlT. , . , , . , — MD5 Update. Update , . , , . Security Handler- . , , . .
, PDF, , Adobe Acrobat Adobe Reader. Adobe Digital Rights Management , :
- , Acrobat. Acrobat, , , , Acrobat;
- . , Adobe . $100 . , Acrobat, Reader.
DRM Adobe « ». Adobe, DRM . , , WebBuy, . , Reader Acrobat , , Adobe. Why? SDK Acrobat API . , . , «», .
Adobe ? , , . , Adobe, , , , - , , - DLL. , , . Visual Studio, C Acrobat Reader. , . , .
RSA 512 ( 512 1999 .). . . Adobe , , SDK . , , , .
DRM
2001 . Digital Rights Management, ? , Rainbow Tables. 1970- , « ». , , , . 40- PDF , 4 , (- ). 15 , — 10 . , 40- .
Adobe Acrobat 256 AES, . , . Adobe . , 50 . , , , 100 .
, , — . , Adobe, — . . 12 (, , ), . , , , .
MD5 Acrobat Reader . . Adobe : , . RSA 1024. , , . , , . , Acrobat, , , , Acrobat , , SDK Acrobat, . , Adobe.
Security Handler :
- NewStand 20- , ;
- Panasonic Crypto, Panasonic, ;
- Normex , .
Adobe Security Handler. $100 , $25 . , . , , , . ? , , Panasonic Crypto NewsStand, . , . , , , - . , . .
Adobe, PDF — . , , . , . Digital Rights Management: , , , , - .
Adobe — . Adobe Digital Editions. C Flash, Flash. — PDF ePub. PDF MD5 Update. ePub AES. ePub , , , , , , . , - AES. AES, .
, , LIT- . Microsoft , , . Microsoft , . Microsoft, , , .
LIT. Microsoft, , . Compound Storage. Microsoft, . , Word Excel , CHM.
: , : « », GUID, iStorage, , « », « » « ». handle iStream, , , . , - iStorage. , , DLL , , Microsoft , , , . , Microsoft , .
Microsoft Reader LIT , Windows 8 2003 . , , .
Blue-ray
2006 . Blu-ray, Advanced Access Content System — CSS (Content Scrambling System). , - , . , , , , — .
. . , , HDMI. HDCP (High Definition Content Protection) , . , , Blu-ray . , High Definition Content Protection , Advanced Access Content System 2007 ., . , , . , DVD, Blu-ray.
Digital Rights Management
, — . , , , . — .
, - , . , Apple , , . , . - , . — .
— . , PDF , , API . Adobe . . Microsoft LIT, Compound Storage.
— Digital Millennium Copyright Act . , 1980- Betamax. , , . , , , — . , , , PDF . , , , . .
, , . , , , .
Digital Rights Management
-, . , . . , . — , . . , .
Apple, iTunes. - $12, 12 . ITunes — $1 . , , , - , — , 12. iTunes , . ?
, ( , ) . , 2003 . Amazon :
- — ;
- — ;
- , , . , , , .
, , . : « , , ». , , , , .
, , DRM, . Watermarking , , . , , .
Penaut Press, Palm, . , . , — , , , . . , , , , , . - — , , , . , , . . , , « ».
FairPlay —
, Apple — . , iBooks. , . , . , , - , - , — . — . — , - .
, . , , , . -, - . How? I do not know. , , .
Source: https://habr.com/ru/post/271071/
All Articles