How we moved the disk space of hundreds of bank branches to a single storage system in Moscow without losing LAN speeds in the field
It is given: a bank with a data center in Moscow and many branches.
In the data center there is a bunch of x86-machines and a serious high-end data storage system (DSS). In branches, a network with a central server or mini cluster (+ backup server and low-end storage) with a disk basket is implemented. Backup of general data is done on the tape (and in the evening in the safe) or on another server next to the first one. Critical data (financial transactions, for example) are replicated asynchronously to the center. The server is running Exchange, AD, antivirus, file server, and so on. There is also data that is not critical for the banking network (these are not direct transactions), but still very important - for example, documents. They are not replicated, but sometimes they are backed up at night when the branch does not work. Half an hour after the end of the working day, all sessions are extinguished, and a large copy begins.
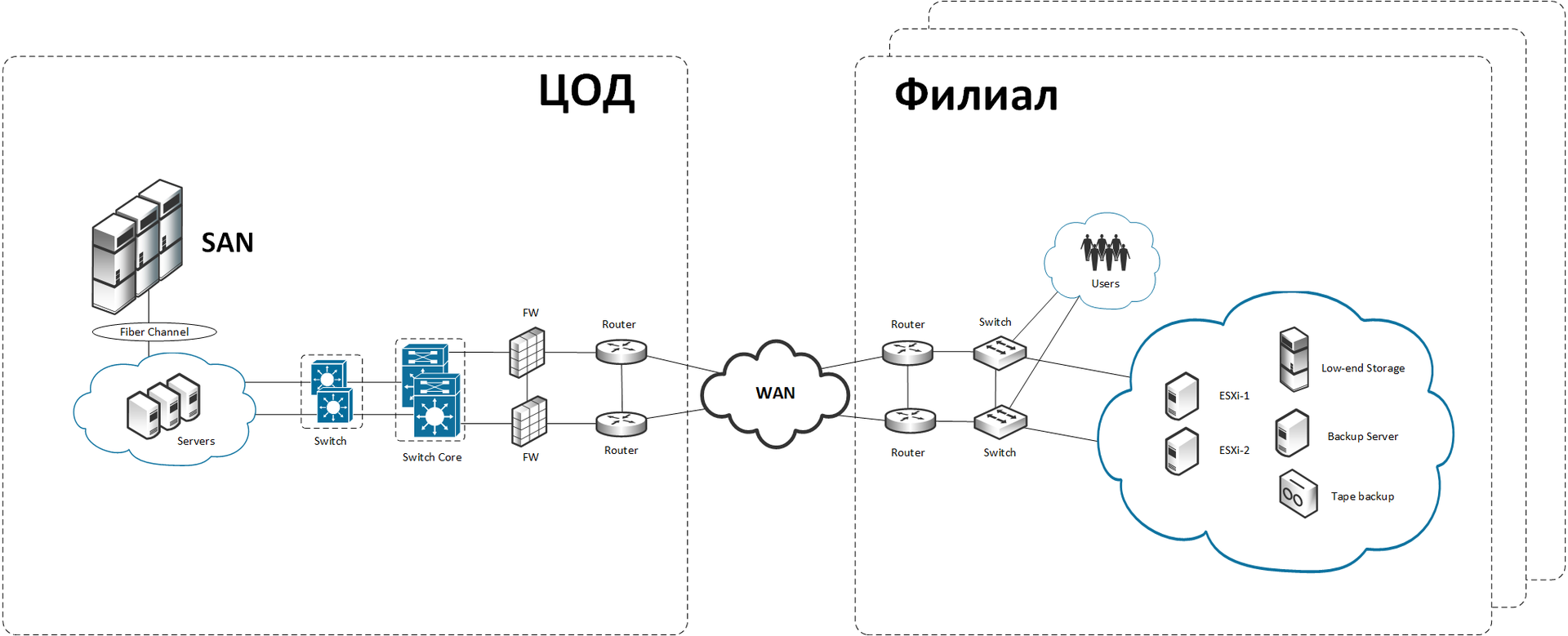
That's how it was arranged before the start of work.
')
The problem, of course, is that all this is slowly beginning to increase the technological debt. A good solution would be to make VDI access (this would eliminate the need to keep a huge service team and would greatly simplify administration), but VDI requires extensive channels and small delays. And this is not always easy in Russia due to the lack of main optics in a number of cities. With each month, the number of unpleasant “pre-emergency” incidents increases, and iron restrictions constantly interfere.
And now the bank decided to do what seems to be more expensive to implement, if we take it directly, but it greatly simplifies servicing the server infrastructure in the branches and guarantees the safety of the branch data: consolidate all the data into one central storage system . Only not simple, but also with a smart local cache.
Naturally, we turned to world experience - after all, such problems were solved several times for mining companies for sure. First found was Alamos Gold, a corporation that digs for gold in Mexico and explores deposits in Turkey.
The data (and there are quite a lot of them, especially raw from geological exploration) must be transferred to the head office in Toronto. WAN channels are narrow, slow, and often weather dependent. As a result, they wrote on flash drives and blanks and sent data by physical mail or physical couriers. IT support was a natural “phone sex”, only corrected by 2-3 language leaps through translators. Because of the need to save data locally, increasing the WAN speed alone would not solve the problem. Alamos was able to avoid the cost of deploying physical servers at each mine by using Riverbed SteelFusion, a specialized Riverbed SFED device that combines the ability to increase WAN speed, the Virtual Services Platform (VSP) virtualization environment and the SteelFusion peripheral virtual server infrastructure (edge-VSI). VSP gave local computing resources. Without upgrading the channels, it was possible, after receiving the master volume snapshot, to transfer data back and forth normally. Return on investment - 8 months. There was a normal disaster recovery procedure.
They began to pick this solution and found two more cases with the iron manufacturer, describing our situation almost exactly.
Bill Barrett Corporation needed to upgrade equipment at remote sites; at first, it looked at the traditional half-rack solution, which was expensive but would not solve many current problems. In addition, most likely, it would be necessary to increase the channel bandwidth to these sites, which doubled the cost. High costs are not the only drawback of this approach. The IT skills of personnel at remote sites were limited, and the proposed solution required someone to manage servers, switches and backup equipment. They also installed Riverbed SteelFusion, as a result, the case turned out to be three times cheaper than the traditional solution, and the space in the racks was significantly less.
The law firm Paul Hastings LLP grew, opening offices in Asia, Europe and the USA, and the number of its data processing centers increased (four central data centers and many small data centers for 19 offices). Although this architecture provided the availability of remote offices, each data center needed a manager and 1–2 analytics, as well as physical host servers and tape backup systems. This was costly, and in some regions data protection was not as reliable as the company would have liked. We decided the same, only the second motive was safety.
Accordingly, they calculated this and a couple more options in traditional architectures and showed them to the customer. The customer thought for a long time, thought, asked a bunch of questions and chose this option with the condition of test deployment of one “branch” (before purchasing the main project hardware) on the test bases.
That's what we did
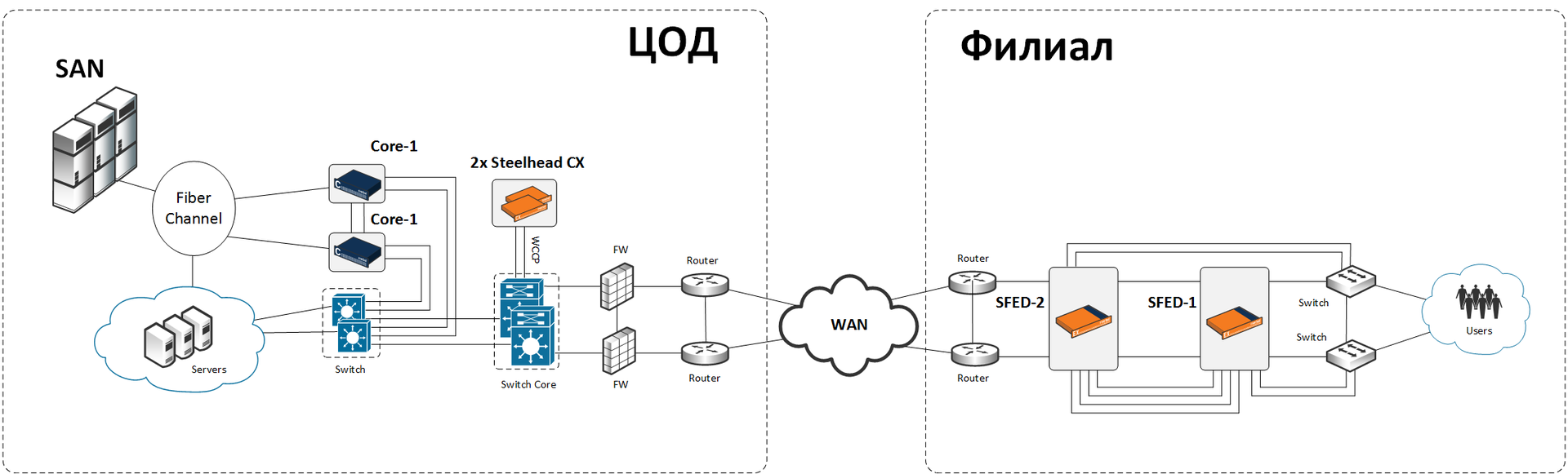
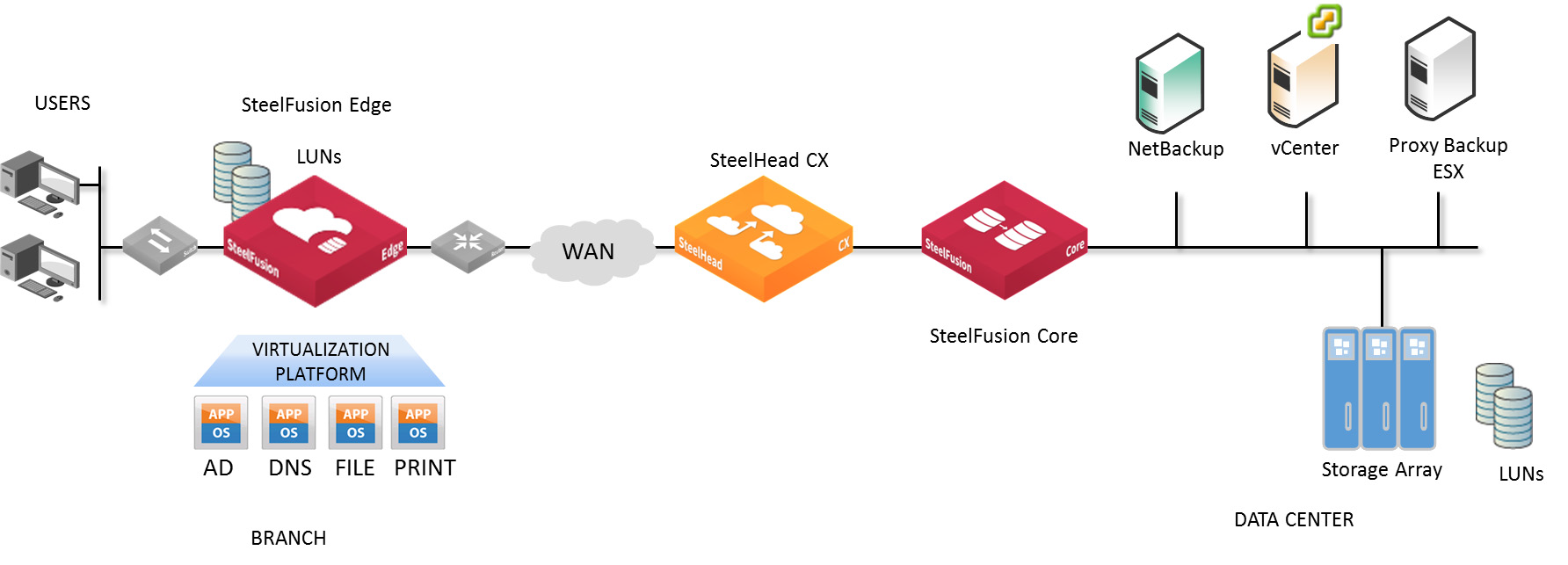
We do not have the ability to change channels, but we can put the hardware on the side of the data center and on the branch side. The storage system in the data center is split into multiple volumes, and each branch works with 2–4 of them (injective connection: several branches cannot work with the same volume). We throw out disk shelves and some servers at places, they are no longer needed as storage and replication controllers. In the data center, we set up simple Riverbed Steelhead CX traffic optimizers + SteelFusion Core virtual devices; a pair of Riverbed SFEDs (SteelFusion Edge) is installed on site.
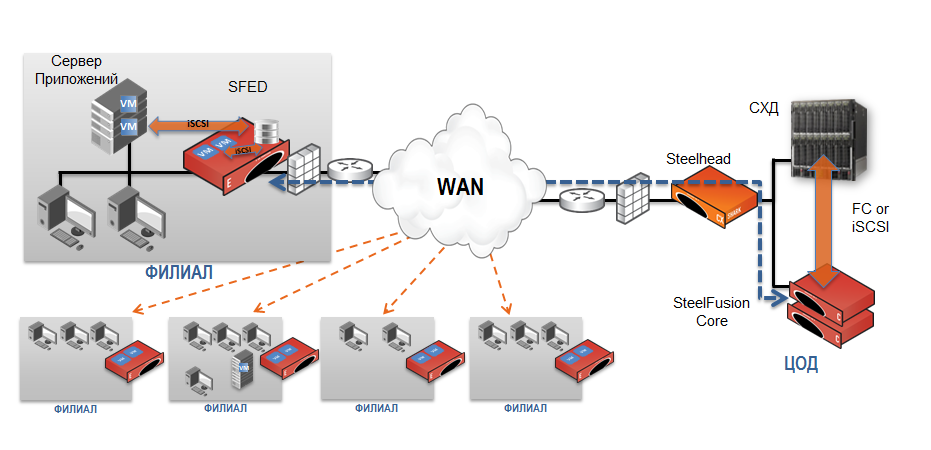
Previously, servers worked with data locally (on local disks or on low-end storage systems). The servers now work with data from the central storage system through a local projection of LUNs provided by SteelFusion. At the same time, the servers “think” that they work with local volumes in the local branch network.
The main branch of the branch is called Riverbed SFED (SteelFusion Edge), it consists of three components. These are SteelHead (optimization + traffic compression), SteelFusion Edge (element of the data centralization system) and VSP (virtualization by the integrated hypervisor ESXi).
At a practical level, the software has earned almost without delay, replication at night is forgotten like a bad dream. Another feature - in the center is really all the data of the branch. That is, if previously “file-washing” scans of documents, presentations, various non-critical documents and everything that is expensive for ordinary users could be on local disks - now it also lies in the center and is also easily restored if it fails. But about this and increasing resiliency just below. And of course, one storage system is much easier to maintain than a dozen. No more "phone sex" with a "programmer" from a faraway small town.

They are mounted like this:
In the current infrastructure - nothing special. Data continues to be written to the SFED cache, and when the channel is restored, it is synchronized. Users at the request "in the center" is given a local cache. It is worth adding that the problem of “schizophrenia” does not arise, since access to the LUN is only through the SFED of a specific branch, that is, from the data center side nobody writes to our volume.
If the connection is broken for a long time, the moment may come when the local SFED cache is full, and the file system will signal that there is not enough space to write. The necessary data can not be recorded, as the system will warn the user or the server.
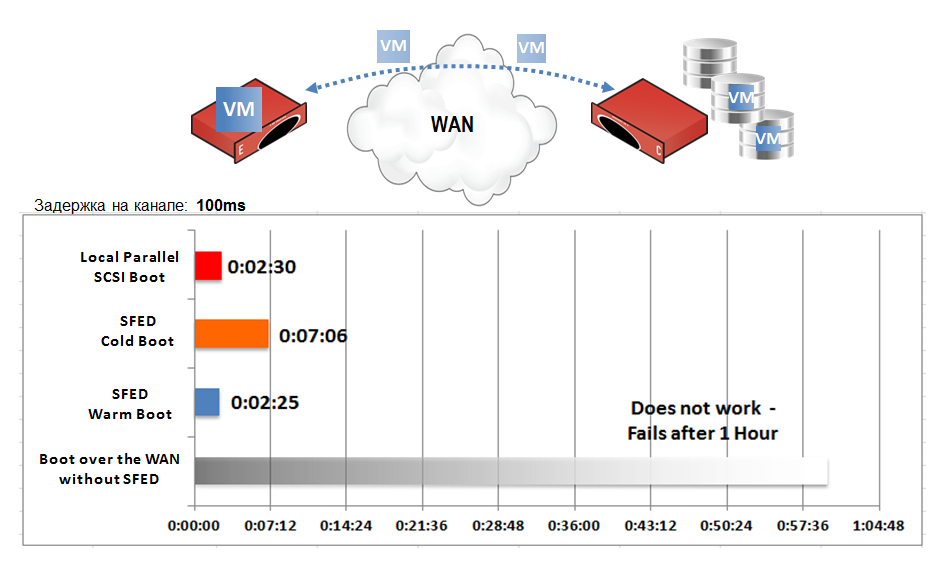
We tested this emergency branch in Moscow several times. The time calculation is:
Windows boot time on the communication channel with a delay of 100 milliseconds is less than 10 minutes. The point is that to boot the OS, you do not need to wait until all the data from the C drive is transferred to the local cache. Booting the OS, of course, is accelerated by intelligent block prefetching, mentioned above, and advanced Riverbed optimization.
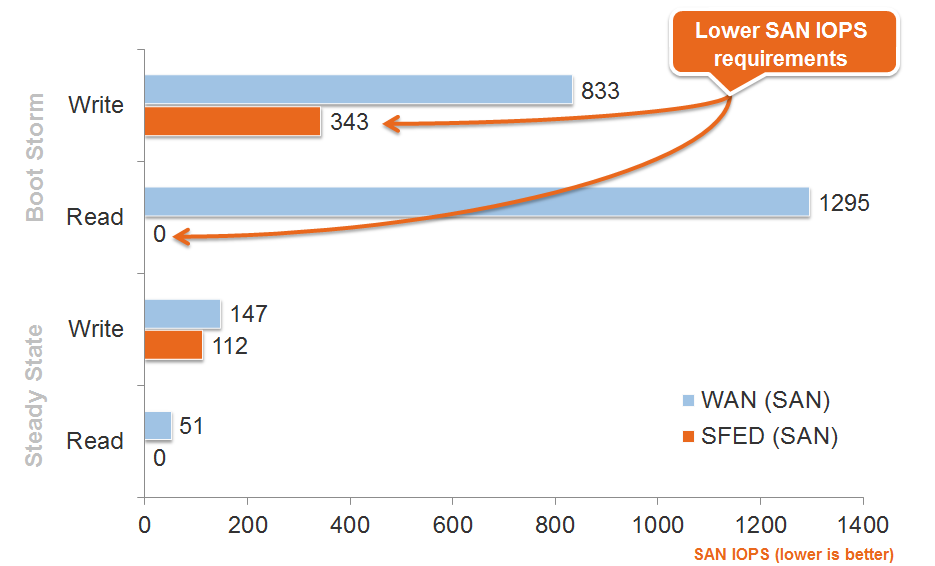
Naturally, the load on the central storage system drops, because most of the work falls on the devices in the branches. Here is a picture from the manufacturer on tests of storage performance optimization, because there are now far fewer references to it:
Before I spoke about Pin the LUN, when the cache is equal LUN. Since the cache on the devices in the branches is not upgraded (you need to buy a new piece of hardware or put a second row, and by the time it is needed - in 4–5 years, they will already be a new generation, most likely), you need to take into account the demand for a sharp increase in the number data in the branch. The planned is calculated and laid for many years to come, but the unplanned will be decided by switching to the Working Set mode.

This is when the blockstore (local cache dictionary) is less than branch data. Typically, the proportion of the cache in comparison with the total amount of data - 15-25%. It is not possible to work completely autonomously here, using the cache as a copy of the central LUN: at this moment, in the link fail mode, the recording goes but is buffered. The channel will be restored - give the record in the center. When a block is requested that is not in the local storage, a normal connection error is generated. If there is a block, the data is sent. I suppose that in those 5 years, when the amount of data exceeds the capacity of the branch cache, admins will not buy more hardware, but simply centralize mail and transfer the file into the Working Set mode, the critical data will be left in Pin the LUN mode.
One more thing. Retrofitting with the second SFED creates a failover cluster, which may also be important in the future.
We did such a rather unusual combination and virtualization of storage systems for the first time - the project differs from others by setting up local blockstore, linked in the PAC with traffic optimizers and virtualization servers. I collapsed several times and collected clusters of devices to see possible problems in the process. A couple of times on a significant reconfiguration, I caught a full warm-up of the cache at the branch, but found a way to bypass it (when not needed). From pitfalls - it is quite nontrivial to completely reset the blockstore on one specific device, it is better to learn from tests before working with combat data. Plus, on the same tests, they caught one exotic kernel crush on a central machine, described the situation in detail, sent it to the manufacturer, they sent a patch.
By recovery time - the wider the channel, the faster the data will be restored at the branch.
It is important that the core does not give the possibility to give the data to specific SFEDs in priority, that is, the storage operations and channels are used evenly - to give a “green” for fast data transfer to a fallen branch using this PAC will not work. Therefore, one more recommendation is to leave a small power storage margin for such cases. In our case, the capacity of the storage system is enough for the eyes. However, it is possible for QoS configurations on the same SteelHead or other network devices to allocate bandwidth for each branch. And on the other hand, limit SteelFusion synchronization traffic so that centralized business application traffic does not suffer.
The second most important - resistance to cliffs. As I understand it, their security officers added a voice for the project, who liked the idea of keeping all the data in the center. Admins are glad that they no longer fly to the field, but, of course, some of the local enikeev suffered because the tape and servers did not have to be serviced.
By itself, this architecture on the Riverbed hardware allows us to do a lot of everything, in particular, fumble printers around the cities, do not quite ordinary proxies and firewalls, use the server power of other cities for big miscalculations, etc. But we are not in the project required (at least for now), so it remains only to rejoice and wonder how many more features you can nakovyryat.
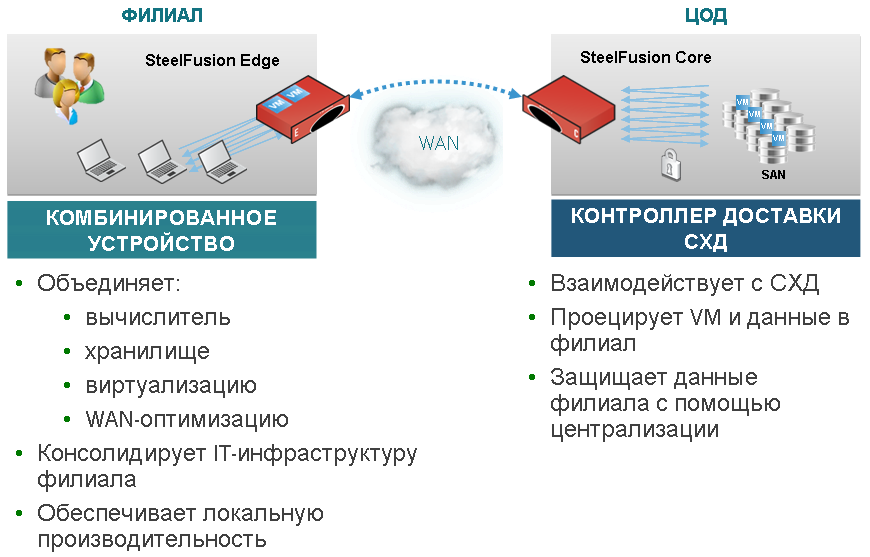
SteelFusion Edge: A converged device that integrates servers, storage, networking and virtualization to run local branch office applications. No other infrastructure in the branch office is required anymore.
SteelFusion Core: The storage delivery controller is located in the data center and interacts with the storage system. SteelhFusion Core projects centralized data to the branches, eliminating backups in the branches, and provides rapid deployment of new branches and disaster recovery.
Actually, perhaps you will still be interested to know:
In the data center there is a bunch of x86-machines and a serious high-end data storage system (DSS). In branches, a network with a central server or mini cluster (+ backup server and low-end storage) with a disk basket is implemented. Backup of general data is done on the tape (and in the evening in the safe) or on another server next to the first one. Critical data (financial transactions, for example) are replicated asynchronously to the center. The server is running Exchange, AD, antivirus, file server, and so on. There is also data that is not critical for the banking network (these are not direct transactions), but still very important - for example, documents. They are not replicated, but sometimes they are backed up at night when the branch does not work. Half an hour after the end of the working day, all sessions are extinguished, and a large copy begins.
That's how it was arranged before the start of work.
')
The problem, of course, is that all this is slowly beginning to increase the technological debt. A good solution would be to make VDI access (this would eliminate the need to keep a huge service team and would greatly simplify administration), but VDI requires extensive channels and small delays. And this is not always easy in Russia due to the lack of main optics in a number of cities. With each month, the number of unpleasant “pre-emergency” incidents increases, and iron restrictions constantly interfere.
And now the bank decided to do what seems to be more expensive to implement, if we take it directly, but it greatly simplifies servicing the server infrastructure in the branches and guarantees the safety of the branch data: consolidate all the data into one central storage system . Only not simple, but also with a smart local cache.
Study
Naturally, we turned to world experience - after all, such problems were solved several times for mining companies for sure. First found was Alamos Gold, a corporation that digs for gold in Mexico and explores deposits in Turkey.
The data (and there are quite a lot of them, especially raw from geological exploration) must be transferred to the head office in Toronto. WAN channels are narrow, slow, and often weather dependent. As a result, they wrote on flash drives and blanks and sent data by physical mail or physical couriers. IT support was a natural “phone sex”, only corrected by 2-3 language leaps through translators. Because of the need to save data locally, increasing the WAN speed alone would not solve the problem. Alamos was able to avoid the cost of deploying physical servers at each mine by using Riverbed SteelFusion, a specialized Riverbed SFED device that combines the ability to increase WAN speed, the Virtual Services Platform (VSP) virtualization environment and the SteelFusion peripheral virtual server infrastructure (edge-VSI). VSP gave local computing resources. Without upgrading the channels, it was possible, after receiving the master volume snapshot, to transfer data back and forth normally. Return on investment - 8 months. There was a normal disaster recovery procedure.
They began to pick this solution and found two more cases with the iron manufacturer, describing our situation almost exactly.
Bill Barrett Corporation needed to upgrade equipment at remote sites; at first, it looked at the traditional half-rack solution, which was expensive but would not solve many current problems. In addition, most likely, it would be necessary to increase the channel bandwidth to these sites, which doubled the cost. High costs are not the only drawback of this approach. The IT skills of personnel at remote sites were limited, and the proposed solution required someone to manage servers, switches and backup equipment. They also installed Riverbed SteelFusion, as a result, the case turned out to be three times cheaper than the traditional solution, and the space in the racks was significantly less.
The law firm Paul Hastings LLP grew, opening offices in Asia, Europe and the USA, and the number of its data processing centers increased (four central data centers and many small data centers for 19 offices). Although this architecture provided the availability of remote offices, each data center needed a manager and 1–2 analytics, as well as physical host servers and tape backup systems. This was costly, and in some regions data protection was not as reliable as the company would have liked. We decided the same, only the second motive was safety.
Accordingly, they calculated this and a couple more options in traditional architectures and showed them to the customer. The customer thought for a long time, thought, asked a bunch of questions and chose this option with the condition of test deployment of one “branch” (before purchasing the main project hardware) on the test bases.
That's what we did
We do not have the ability to change channels, but we can put the hardware on the side of the data center and on the branch side. The storage system in the data center is split into multiple volumes, and each branch works with 2–4 of them (injective connection: several branches cannot work with the same volume). We throw out disk shelves and some servers at places, they are no longer needed as storage and replication controllers. In the data center, we set up simple Riverbed Steelhead CX traffic optimizers + SteelFusion Core virtual devices; a pair of Riverbed SFEDs (SteelFusion Edge) is installed on site.
Previously, servers worked with data locally (on local disks or on low-end storage systems). The servers now work with data from the central storage system through a local projection of LUNs provided by SteelFusion. At the same time, the servers “think” that they work with local volumes in the local branch network.
The main branch of the branch is called Riverbed SFED (SteelFusion Edge), it consists of three components. These are SteelHead (optimization + traffic compression), SteelFusion Edge (element of the data centralization system) and VSP (virtualization by the integrated hypervisor ESXi).
What happened
- Addressing for a branch is a single LAN with a central storage system (more precisely, a pair of its volumes). Servers access the central storage system as an instance within the LAN.
- At the first request, data blocks begin to be broadcast from the center to the branch (slowly, but only once). Running a little further, we use the Pin the LUN mode when the cache (blockstore) is equal to the size of the LUN, that is, we immediately remove the full data cast from the central storage system on the first run.
- When any data changes on our side, they queue up for synchronization and immediately become available “as if in the center”, but from the SteelFusion Edge cache located locally.
- When transferring data to any of the parties, efficient compression, deduplication and protocol overrides are used to optimize them (bulky and chatty protocols are translated by devices into optimized for narrow channels with a large delay).
- In general, all data is always stored in a data storage system in a central data center.
- "For dessert" there was a cool block-level prefetching. By reading the contents of the blocks and applying knowledge of file systems, SteelFusion is able to determine what the OS is actually doing (for example, loading, launching an application, opening a document). It can then determine which data blocks will be needed for reading, and loads them before the OS requests them. Which is much faster than doing everything consistently.
At a practical level, the software has earned almost without delay, replication at night is forgotten like a bad dream. Another feature - in the center is really all the data of the branch. That is, if previously “file-washing” scans of documents, presentations, various non-critical documents and everything that is expensive for ordinary users could be on local disks - now it also lies in the center and is also easily restored if it fails. But about this and increasing resiliency just below. And of course, one storage system is much easier to maintain than a dozen. No more "phone sex" with a "programmer" from a faraway small town.
They are mounted like this:
What happened:
- The so-called quasi-synchronous replication (this is when for the branch they look like synchronous, and for the center - as fast asynchronous).
- There were quick and convenient recovery points up to minutes, and not "at least a day ago."
- Previously, in the event of a fire at the branch, the local file ball and mail of the city employees were lost. Now all this is also synchronized and will not be lost in case of an accident.
- The new box has simplified all branch recovery procedures - a new office is deployed on a new hardware in a matter of minutes (the new city is being developed from ready-made images in the same way).
- We had to remove servers from the infrastructure on the ground, plus throw out small tape drives for backup, also on the ground. Instead, Riverbed's hardware was purchased, a central storage system was replenished with disks, and a new large backup library was purchased for backup installed in another Moscow data center.
- Data security has improved thanks to uniform and easily controlled access rules and more robust channel encryption.
- With the disaster of the branch, accompanied by the destruction of infrastructure, there was a simple opportunity to run virtual servers in the data center. As a result, RTO and RPO are rapidly decreasing.
What happens when a short break connection?
In the current infrastructure - nothing special. Data continues to be written to the SFED cache, and when the channel is restored, it is synchronized. Users at the request "in the center" is given a local cache. It is worth adding that the problem of “schizophrenia” does not arise, since access to the LUN is only through the SFED of a specific branch, that is, from the data center side nobody writes to our volume.
What happens when a connection breaks for more than 4 hours?
If the connection is broken for a long time, the moment may come when the local SFED cache is full, and the file system will signal that there is not enough space to write. The necessary data can not be recorded, as the system will warn the user or the server.
We tested this emergency branch in Moscow several times. The time calculation is:
- Delivery time spares.
- SFED initial configuration time (<30 minutes).
- The load time of the OS virtual servers through the communication channel with an empty cache.
Windows boot time on the communication channel with a delay of 100 milliseconds is less than 10 minutes. The point is that to boot the OS, you do not need to wait until all the data from the C drive is transferred to the local cache. Booting the OS, of course, is accelerated by intelligent block prefetching, mentioned above, and advanced Riverbed optimization.
Load on storage
Naturally, the load on the central storage system drops, because most of the work falls on the devices in the branches. Here is a picture from the manufacturer on tests of storage performance optimization, because there are now far fewer references to it:
Explanation of quasi-synchronous replication modes
Before I spoke about Pin the LUN, when the cache is equal LUN. Since the cache on the devices in the branches is not upgraded (you need to buy a new piece of hardware or put a second row, and by the time it is needed - in 4–5 years, they will already be a new generation, most likely), you need to take into account the demand for a sharp increase in the number data in the branch. The planned is calculated and laid for many years to come, but the unplanned will be decided by switching to the Working Set mode.
This is when the blockstore (local cache dictionary) is less than branch data. Typically, the proportion of the cache in comparison with the total amount of data - 15-25%. It is not possible to work completely autonomously here, using the cache as a copy of the central LUN: at this moment, in the link fail mode, the recording goes but is buffered. The channel will be restored - give the record in the center. When a block is requested that is not in the local storage, a normal connection error is generated. If there is a block, the data is sent. I suppose that in those 5 years, when the amount of data exceeds the capacity of the branch cache, admins will not buy more hardware, but simply centralize mail and transfer the file into the Working Set mode, the critical data will be left in Pin the LUN mode.
One more thing. Retrofitting with the second SFED creates a failover cluster, which may also be important in the future.
Tests and trial operation
We did such a rather unusual combination and virtualization of storage systems for the first time - the project differs from others by setting up local blockstore, linked in the PAC with traffic optimizers and virtualization servers. I collapsed several times and collected clusters of devices to see possible problems in the process. A couple of times on a significant reconfiguration, I caught a full warm-up of the cache at the branch, but found a way to bypass it (when not needed). From pitfalls - it is quite nontrivial to completely reset the blockstore on one specific device, it is better to learn from tests before working with combat data. Plus, on the same tests, they caught one exotic kernel crush on a central machine, described the situation in detail, sent it to the manufacturer, they sent a patch.
By recovery time - the wider the channel, the faster the data will be restored at the branch.
It is important that the core does not give the possibility to give the data to specific SFEDs in priority, that is, the storage operations and channels are used evenly - to give a “green” for fast data transfer to a fallen branch using this PAC will not work. Therefore, one more recommendation is to leave a small power storage margin for such cases. In our case, the capacity of the storage system is enough for the eyes. However, it is possible for QoS configurations on the same SteelHead or other network devices to allocate bandwidth for each branch. And on the other hand, limit SteelFusion synchronization traffic so that centralized business application traffic does not suffer.
The second most important - resistance to cliffs. As I understand it, their security officers added a voice for the project, who liked the idea of keeping all the data in the center. Admins are glad that they no longer fly to the field, but, of course, some of the local enikeev suffered because the tape and servers did not have to be serviced.
By itself, this architecture on the Riverbed hardware allows us to do a lot of everything, in particular, fumble printers around the cities, do not quite ordinary proxies and firewalls, use the server power of other cities for big miscalculations, etc. But we are not in the project required (at least for now), so it remains only to rejoice and wonder how many more features you can nakovyryat.
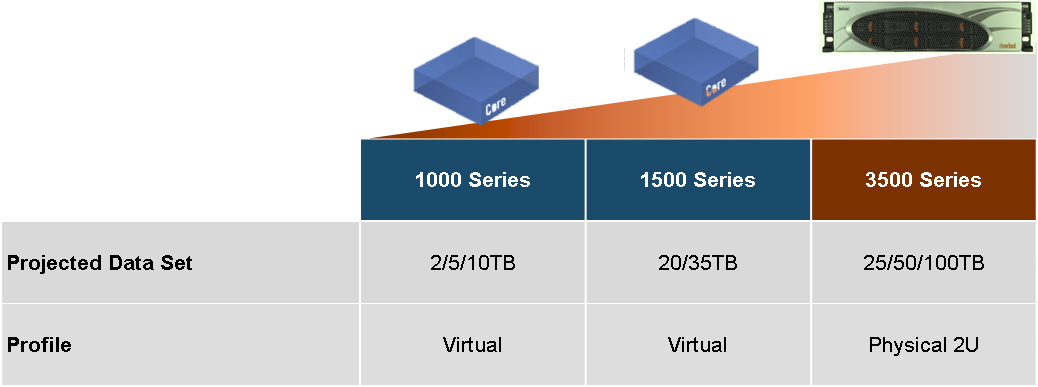
Iron
SteelFusion Edge: A converged device that integrates servers, storage, networking and virtualization to run local branch office applications. No other infrastructure in the branch office is required anymore.
SteelFusion Core: The storage delivery controller is located in the data center and interacts with the storage system. SteelhFusion Core projects centralized data to the branches, eliminating backups in the branches, and provides rapid deployment of new branches and disaster recovery.
Links
Actually, perhaps you will still be interested to know:
- Pro basic use of traffic optimizers with a local blockstore .
- The practical solution to optimize traffic , where it was not necessary to do LAN speeds in the branches (satellite channels).
- About the network detective with the search for anomalies (it was an educational detective, no one was hurt).
- Here you can download a general description of the solution and application options from the vendor (but there you will have to fill in the form with the mail).
- And my mail, if your question is not for comments, or if you need to first estimate the cost of a similar solution for yourself: AVrublevsky@croc.ru
- The day after tomorrow, November 12, we are holding a webinar on how to reduce the cost of this part of the IT infrastructure . Everything is detailed there, with practical calculations and with an overview of various options for action.
Source: https://habr.com/ru/post/270549/
All Articles