OpenStreetMap as a geodata source
In the work of the programmer sometimes there is a need for geodata. You can use OpenStreetMap (OSM) for this. The appeal of OSM is the ability to perfectly use high-quality map information.
The purpose of the publication is to analyze the process of extracting geodata OSM using working examples. The result will be a program code (in C #), which can be assembled in Visual or Xamarin Studio, run it on different OS (under Mono) and get the result in CSV and geoJSON formats. There are no restrictions on the size of processed OSM data (from minimum to full). The publication is designed for software developers with no experience with OSM.
How to independently get an answer to seemingly simple and understandable questions (just for fun):
- how many states on Earth, what is their population?
- where are the cities on Earth with a population of, for example, more than a million people?
- how many volcanoes on Earth?
Or (easy to get based on examples):
- where are the hospitals, hotels in your / foreign city? And between cities?
- where are gas stations, zoos, museums, restaurants? Yes, whatever.
')
The task, in general, can be formulated something like this - to find the necessary objects, to determine their exact location (latitude, longitude), name and other available information.
Further, these objects can be displayed, for example, on a map (OSM, Google, Yandex). In the publication, for visualization of results, it is used ( automatic display on GitHub of data in the format geoJSON ).
The basic element of the OSM data structure is a point (node) with geographic coordinates - latitude (latitude) and longitude (longitude). The height of the point above sea level, at present, is not indicated.
A point can be an independent object (traffic light, kiosk, spring) and, without limitation, be part of other objects (lines and relationships). Dots can be marked and large objects - countries, cities and even continents with a set of corresponding tags.
The number of points in OSM is currently approaching a value that exceeds the capacity of 32-bit storage. Therefore, OSM switched to 64 bits (to monitor the number of points in OSM, an on-line monitor was even made).
A line is a sequence of points. You can not change the sequence. Several lines, logically, can represent one object. For example, a long road consists of several lines. The lines of one road are connected in a single whole by observing the condition - the point of the end of one line strictly corresponds to the point of the beginning of another line or several lines (in case of branching of the road or exit to another road). This point integrity for lines in OSM is well respected.
The polygon is a closed line where the first and last points coincide. The landfill is not a separate element of OSM. For large polygons (borders of states, coastlines), which consist of a set of unclosed lines, the rules are defined. For example, when determining coastlines, the land will be on the left in the direction of travel, water on the right. For administrative boundaries it is clearly indicated - who is on the left along the way of movement, who on the right.
Attitude is a logical combination of points, lines and other relationships into a single object.
Despite the seemingly high functionality, the relationship in OSM is used a little. Although there are attempts to apply relationships to different objects. For example, such a purely point object as a bus stop , according to OSM internal statistics (statistics are maintained for most objects), is represented by: 1572243 points, 2479 lines and 1140 ratios.
An object is an element (point, line, relation) with a set of tags (attributes). Tag (tag) is defined as k = "key" v = "value". If an element has no tags, then it is not an object, but is part of other objects (it can also be included with tags).
The object has no required tags. There are no mandatory requirements for the number, content and order of the tags. The one who enters the data in the OSM, he determines the composition and content of the tags ( List of recommended to use common tags ).
In different countries, regions or regions, the same objects can vary considerably in composition and content of tags. For example, a city (city) can be indicated by a dot or a line (polygon). There are clear regional preferences in OSM statistics.
Cities marked by dots: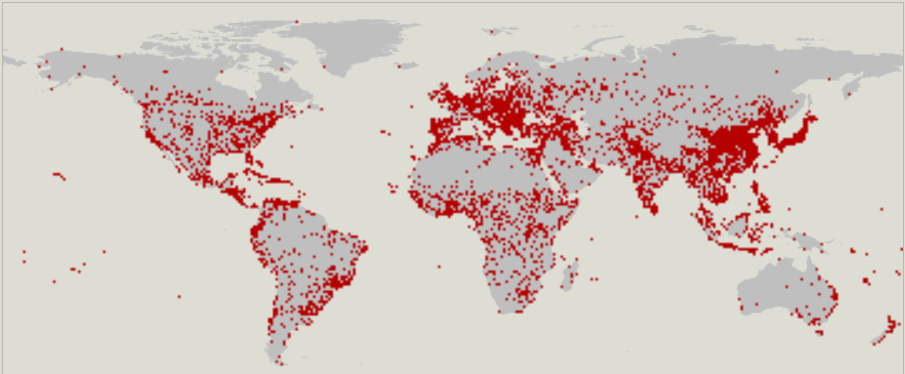
Cities marked with lines: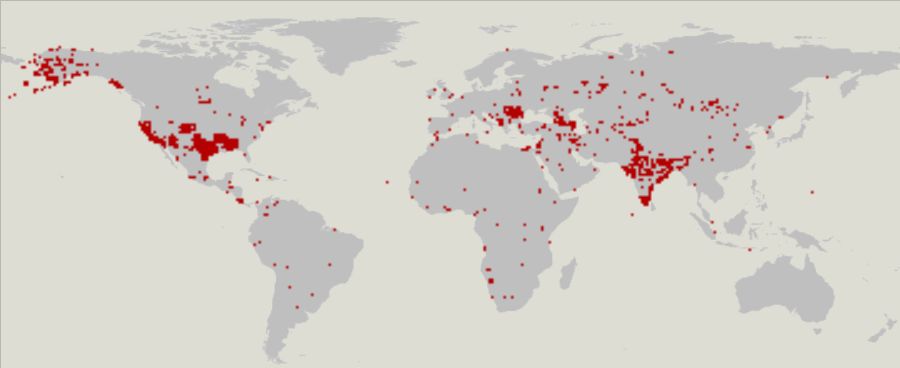
Therefore, before using a new object, it is advisable to examine it for what tags are actually used in it.
Exact geographical measurements are quite complex. It is necessary to take into account: the fact that the Earth is not an ideal ball, height above sea level, relief, different projection models for displaying a spherical Earth on a plane.
The Internet maps use the projection EPSG: 4326 - WGS-84 , which is based on the latitude and longitude of the satellite GPS navigation. Degrees are specified in decimal form: latitude (lat = 52.2600355), longitude (lon = 0.0172928).
For example, there are two points ( volcanoes on the island of Tristan da Cunha ):
1. Volcano “Green Hill” (id = 2079122352, lat = -37.1324274, lon = -12.3096104);
2. Red Hill Volcano (id = 2079124574, lat = -37.1200039, lon = -12.2383527).
OSM data is stored in a database (DB). On a regular basis, a snapshot of the database is prepared in XML format in the planet.osm file. Archived bzip2 file is 45Gb, in unpacked form - more than 600Gb. In addition, there are mirrors of planet.osm and links to Internet resources , where you can download OSM data cut by regions.
For publishing examples, data is taken from the geofabrik server. Data is conveniently cut by region and laid out, for unloading, in different formats: Shape-files (shp.zip), PBF-files (osm.pbf), XML-files (osm.bz2). The publication examples use XML files.
When reading XML, you need to consider:
The publication discusses two examples of data acquisition:
1. node-objects (countries, cities with a million population, volcanoes);
2. way-objects (desert).
The data types are chosen so that, after processing the complete OSM data, clear and visual content is obtained, but, at the same time, the result files would not be too large and could be shown on the map.
OSM-XML is taken directly from the archived bzip2 files (* .osm.bz2). SharpZipLib library is used to work with the archive. When processing large files, no problems were detected.
The CSV format is compact and convenient for recording a large amount of data, which can then be easily imported, for example, into a database.
The geoJSON format, by contrast, is redundant and verbose in structure, but is convenient because the data is immediately ready for display on the map. In the examples, for visualization, the GitHub feature for displaying geodata (files with a geojson extension) is used.
Factors that affect performance:
Mono ( ).
Visual Studio Community 2015 Windows 7. , EXE- ICSharpCode.SharpZipLib.dll ( ) Linux ( OpenSuse, Mint, Ubuntu Oracle Virtual Box) Mono ( Mono ). , .
( ):
node-
way-
(geoJSON):
.
.
.
.
( )
Planet.osm
GeoJSON
GitHub geoJSON
geofabrik
gis-lab
OSM
(SharpZipLib)
Mono
The purpose of the publication is to analyze the process of extracting geodata OSM using working examples. The result will be a program code (in C #), which can be assembled in Visual or Xamarin Studio, run it on different OS (under Mono) and get the result in CSV and geoJSON formats. There are no restrictions on the size of processed OSM data (from minimum to full). The publication is designed for software developers with no experience with OSM.
Introduction
How to independently get an answer to seemingly simple and understandable questions (just for fun):
- how many states on Earth, what is their population?
- where are the cities on Earth with a population of, for example, more than a million people?
- how many volcanoes on Earth?
Or (easy to get based on examples):
- where are the hospitals, hotels in your / foreign city? And between cities?
- where are gas stations, zoos, museums, restaurants? Yes, whatever.
')
The task, in general, can be formulated something like this - to find the necessary objects, to determine their exact location (latitude, longitude), name and other available information.
Further, these objects can be displayed, for example, on a map (OSM, Google, Yandex). In the publication, for visualization of results, it is used ( automatic display on GitHub of data in the format geoJSON ).
Basic concepts and terminology
Point (node)
The basic element of the OSM data structure is a point (node) with geographic coordinates - latitude (latitude) and longitude (longitude). The height of the point above sea level, at present, is not indicated.
A point can be an independent object (traffic light, kiosk, spring) and, without limitation, be part of other objects (lines and relationships). Dots can be marked and large objects - countries, cities and even continents with a set of corresponding tags.
Examples of points without tags and with tags (XML):
Attributes node:
- id - unique identifier in the OSM database (used for way and relation);
- lat - latitude, lon - longitude;
- uid and user — identifier and name of the operator who made the changes (used for way and relation);
- version - version of the change (used for way and relation);
- timestamp - change time (used for way and relation);
- changeset - change number (something like a transaction that can be applied or canceled) (used for way and relation).
Tags:
- k = "highway" v = "motorway_junction" - indicates the beginning of the exit from the road ;
- k = "ref" v = "29" is the exit number;
- k = "name" v = "Bar Hill" - the name;
- k = "exit_to" v = "Bar Hill B1050; Longstanton "- where;
- k = "layer" v = "3" - level;
- k = "fixme" v = "What is this layer? 3s around this junction?" - the author made a "memory knot".
<node id="231477" lat="52.2600355" lon="0.0172928" version="2" timestamp="2011-02-27T02:33:27Z" changeset="7406582" uid="39894" user="markpeers"/> <node id="231478" lat="52.2552032" lon="0.0281442" version="4" timestamp="2011-02-27T02:33:25Z" changeset="7406582" uid="39894" user="markpeers"> <tag k="exit_to" v="Bar Hill B1050; Longstanton"/> <tag k="fixme" v="What is with all the layer=3s around this junction?"/> <tag k="highway" v="motorway_junction"/> <tag k="layer" v="3"/> <tag k="name" v="Bar Hill"/> <tag k="ref" v="29"/> </node> Attributes node:
- id - unique identifier in the OSM database (used for way and relation);
- lat - latitude, lon - longitude;
- uid and user — identifier and name of the operator who made the changes (used for way and relation);
- version - version of the change (used for way and relation);
- timestamp - change time (used for way and relation);
- changeset - change number (something like a transaction that can be applied or canceled) (used for way and relation).
Tags:
- k = "highway" v = "motorway_junction" - indicates the beginning of the exit from the road ;
- k = "ref" v = "29" is the exit number;
- k = "name" v = "Bar Hill" - the name;
- k = "exit_to" v = "Bar Hill B1050; Longstanton "- where;
- k = "layer" v = "3" - level;
- k = "fixme" v = "What is this layer? 3s around this junction?" - the author made a "memory knot".
The number of points in OSM is currently approaching a value that exceeds the capacity of 32-bit storage. Therefore, OSM switched to 64 bits (to monitor the number of points in OSM, an on-line monitor was even made).
Line
A line is a sequence of points. You can not change the sequence. Several lines, logically, can represent one object. For example, a long road consists of several lines. The lines of one road are connected in a single whole by observing the condition - the point of the end of one line strictly corresponds to the point of the beginning of another line or several lines (in case of branching of the road or exit to another road). This point integrity for lines in OSM is well respected.
The polygon is a closed line where the first and last points coincide. The landfill is not a separate element of OSM. For large polygons (borders of states, coastlines), which consist of a set of unclosed lines, the rules are defined. For example, when determining coastlines, the land will be on the left in the direction of travel, water on the right. For administrative boundaries it is clearly indicated - who is on the left along the way of movement, who on the right.
Line example (XML):
The ref attribute points to the point id (to get the lat, lon coordinates). It is important to consider the sequence of nd elements.
Tags:
- k = "boundary" v = "administrative" - administrative boundary ;
- k = "admin_level" v = "6" - level 6;
- k = "left: county" v = "Cambridgeshire" - who is on the left;
- k = "right: county" v = "Essex" - who is to the right;
- k = "source" v = "OS_OpenData_Boundary-Line" - link to the source of information.
<way id="9933583" version="18" timestamp="2013-01-06T20:59:43Z" changeset="14555667" uid="30525" user="The Maarssen Mapper"> <nd ref="2098832234"/> <nd ref="81448050"/> <nd ref="1263117830"/> <nd ref="1263117982"/> <nd ref="81448052"/> <nd ref="81448053"/> <nd ref="81448054"/> <nd ref="1297466013"/> <nd ref="81448063"/> <tag k="admin_level" v="6"/> <tag k="boundary" v="administrative"/> <tag k="left:county" v="Cambridgeshire"/> <tag k="right:county" v="Essex"/> <tag k="source" v="OS_OpenData_Boundary-Line"/> </way> The ref attribute points to the point id (to get the lat, lon coordinates). It is important to consider the sequence of nd elements.
Tags:
- k = "boundary" v = "administrative" - administrative boundary ;
- k = "admin_level" v = "6" - level 6;
- k = "left: county" v = "Cambridgeshire" - who is on the left;
- k = "right: county" v = "Essex" - who is to the right;
- k = "source" v = "OS_OpenData_Boundary-Line" - link to the source of information.
Relation
Attitude is a logical combination of points, lines and other relationships into a single object.
Relationship Example (XML):
member - members of the relationship;
type - an object type (node, way, relation);
ref - link to object id;
role - the role of the object in the relationship.
This example describes a multipolygon (multipolygon) - a park with internal areas (these can be, for example, ponds, glades, or vice versa, places with vegetation).
Note: not all multipolygons are so described.
<relation id="2839278" version="1" timestamp="2013-03-25T13:56:31Z" changeset="15491865" uid="322785" user="BCNorwich"> <member type="way" ref="74424273" role="outer"/> <member type="way" ref="4950089" role="inner"/> <member type="way" ref="212392511" role="inner"/> <member type="way" ref="212392522" role="inner"/> <tag k="leisure" v="park"/> <tag k="type" v="multipolygon"/> </relation> member - members of the relationship;
type - an object type (node, way, relation);
ref - link to object id;
role - the role of the object in the relationship.
This example describes a multipolygon (multipolygon) - a park with internal areas (these can be, for example, ponds, glades, or vice versa, places with vegetation).
Note: not all multipolygons are so described.
Despite the seemingly high functionality, the relationship in OSM is used a little. Although there are attempts to apply relationships to different objects. For example, such a purely point object as a bus stop , according to OSM internal statistics (statistics are maintained for most objects), is represented by: 1572243 points, 2479 lines and 1140 ratios.
Objects and tags (tag)
An object is an element (point, line, relation) with a set of tags (attributes). Tag (tag) is defined as k = "key" v = "value". If an element has no tags, then it is not an object, but is part of other objects (it can also be included with tags).
The object has no required tags. There are no mandatory requirements for the number, content and order of the tags. The one who enters the data in the OSM, he determines the composition and content of the tags ( List of recommended to use common tags ).
In different countries, regions or regions, the same objects can vary considerably in composition and content of tags. For example, a city (city) can be indicated by a dot or a line (polygon). There are clear regional preferences in OSM statistics.
Cities marked by dots:
Cities marked with lines:
Therefore, before using a new object, it is advisable to examine it for what tags are actually used in it.
Coordinates and distances
Exact geographical measurements are quite complex. It is necessary to take into account: the fact that the Earth is not an ideal ball, height above sea level, relief, different projection models for displaying a spherical Earth on a plane.
The Internet maps use the projection EPSG: 4326 - WGS-84 , which is based on the latitude and longitude of the satellite GPS navigation. Degrees are specified in decimal form: latitude (lat = 52.2600355), longitude (lon = 0.0172928).
For example, there are two points ( volcanoes on the island of Tristan da Cunha ):
1. Volcano “Green Hill” (id = 2079122352, lat = -37.1324274, lon = -12.3096104);
2. Red Hill Volcano (id = 2079124574, lat = -37.1200039, lon = -12.2383527).
Rate accuracy
The length of one angular minute of latitude on the surface of the Earth is (approximately) 1,852 meters - ( one nautical mile ). “Approximately”, because 1852 meters is an average value: 1862 meters at the pole and 1843 meters at the equator.
The length of one degree of latitude: 1852 * 60 = 111120 m. (The length of one degree of longitude: 1852 * 60 * COS (angle of latitude)).
Thus, the coordinates of a point in OSM (0.0000001) are specified with an accuracy of ~ 1 cm.
The length of one degree of latitude: 1852 * 60 = 111120 m. (The length of one degree of longitude: 1852 * 60 * COS (angle of latitude)).
Thus, the coordinates of a point in OSM (0.0000001) are specified with an accuracy of ~ 1 cm.
Calculate the distance between points
The distance between two nearby points (without taking into account the spherical shape of the Earth) can be calculated by the Pythagorean theorem.
The distance between the volcanoes "Green Hill" and "Red Hill":
²√ ((37.1324274 - 37.1200039) ² + (12.3096104 - 12.2383527) ²) = ²√0.00523200316154 ≈ 0.072332587 (or 0.072332587 * 111120 ≈ 8037.6 meters)
The distance between the volcanoes "Green Hill" and "Red Hill":
²√ ((37.1324274 - 37.1200039) ² + (12.3096104 - 12.2383527) ²) = ²√0.00523200316154 ≈ 0.072332587 (or 0.072332587 * 111120 ≈ 8037.6 meters)
Translate coordinate values from decimal to angular and back
In the corner view:
37.1324274 = 37 °
Decimal balance per minute: 0.1324274 ° * 60 = 7.945644 '
Decimal balance in seconds: 0.945644 '* 60 = 56.73864 "≈ 57"
Total: 37.1324274 ° ≈ 37 ° 07'57 "
In decimal view:
37 ° 07'57 "= 37 ° + 7/60 + 57/3600 ≈ 37 + 0.11666667 + 0.01583333 ≈ 37.1325 °
Taking into account all rounding, the error was:
37.1325 ° - 37.1324274 ° = 0.0000726 ° (or 0.0000726 * 111120 ≈ 8 meters)
37.1324274 = 37 °
Decimal balance per minute: 0.1324274 ° * 60 = 7.945644 '
Decimal balance in seconds: 0.945644 '* 60 = 56.73864 "≈ 57"
Total: 37.1324274 ° ≈ 37 ° 07'57 "
In decimal view:
37 ° 07'57 "= 37 ° + 7/60 + 57/3600 ≈ 37 + 0.11666667 + 0.01583333 ≈ 37.1325 °
Taking into account all rounding, the error was:
37.1325 ° - 37.1324274 ° = 0.0000726 ° (or 0.0000726 * 111120 ≈ 8 meters)
Where to download OSM data
OSM data is stored in a database (DB). On a regular basis, a snapshot of the database is prepared in XML format in the planet.osm file. Archived bzip2 file is 45Gb, in unpacked form - more than 600Gb. In addition, there are mirrors of planet.osm and links to Internet resources , where you can download OSM data cut by regions.
For publishing examples, data is taken from the geofabrik server. Data is conveniently cut by region and laid out, for unloading, in different formats: Shape-files (shp.zip), PBF-files (osm.pbf), XML-files (osm.bz2). The publication examples use XML files.
When reading XML, you need to consider:
High integrity of XML files:
Integrity means:
- All objects are presented in the XML file once.
- All references to id objects will be present in the XML file (for example, when describing a line there will be no references to non-existent points).
- If the object is partially beyond the boundaries of the described area, it will still be fully described. Therefore, in the two XML files that describe the boundary areas, there are duplicate objects that go from one area to another. For example, if a relation is duplicated, then both the way and the node and relation that it contains are duplicated.
- All objects are presented in the XML file once.
- All references to id objects will be present in the XML file (for example, when describing a line there will be no references to non-existent points).
- If the object is partially beyond the boundaries of the described area, it will still be fully described. Therefore, in the two XML files that describe the boundary areas, there are duplicate objects that go from one area to another. For example, if a relation is duplicated, then both the way and the node and relation that it contains are duplicated.
Differences in the organization of XML data taken from different sources:
An example of the following geofabrik XML attributes:
An example of the following gis-lab XML attributes:
<node id="231477" lat="52.2600355" lon="0.0172928" version="2" timestamp="2011-02-27T02:33:27Z" changeset="7406582" uid="39894" user="markpeers"/> An example of the following gis-lab XML attributes:
<node id="36725955" version="7" timestamp="2012-02-05T19:48:59Z" uid="237247" user="masta" changeset="10597500" lat="43.0735049" lon="47.4662786"/> When describing a line, the order of the points cannot be changed:
An example of a closed line (simple quadrilateral structure):
<way id="243383077" version="1" timestamp="2013-10-25T08:52:05Z" uid="371711" user="knockpenny" changeset="18532019"> <nd ref="2508041246"/> <nd ref="2508041226"/> <nd ref="2508041210"/> <nd ref="2508041208"/> <nd ref="2508041246"/> <tag k="building" v="yes"/> </way> Explanation of examples
The publication discusses two examples of data acquisition:
1. node-objects (countries, cities with a million population, volcanoes);
2. way-objects (desert).
The data types are chosen so that, after processing the complete OSM data, clear and visual content is obtained, but, at the same time, the result files would not be too large and could be shown on the map.
Why not a utility?
And why not just develop a utility in which to provide all possible mechanisms for filtering and selecting OSM data? The idea was such (and even an attempt to implement it). But nothing happened. Indeed, working with OSM-XML is simple. But the logic of the conditions of selection and interaction of tags of objects can be completely unpredictable. Therefore, it is easier to have a kind of template that can be easily modified to obtain the necessary data. Examples are such patterns.
When developing examples, the following requirements were taken into account:
1. OSM data should be taken directly from the archive;
2. Results data should be submitted in CSV and geoJSON formats;
3. It is very good if work is provided on any (from minimum to full) amount of OSM data;
4. It is very good if data cleansing from duplicates is ensured;
5. Very well, if it is ensured performance on different operating systems;
6. Examples must be fully functional and complete.
2. Results data should be submitted in CSV and geoJSON formats;
3. It is very good if work is provided on any (from minimum to full) amount of OSM data;
4. It is very good if data cleansing from duplicates is ensured;
5. Very well, if it is ensured performance on different operating systems;
6. Examples must be fully functional and complete.
Processing OSM Files
OSM-XML is taken directly from the archived bzip2 files (* .osm.bz2). SharpZipLib library is used to work with the archive. When processing large files, no problems were detected.
All * .osm.bz2 files in the input directory are processed sequentially:
//.. // // string dirIn = @".\in\"; // (*.osm.bz2) string dirOut = @".\out\"; // //.. // - // if (!Directory.Exists(dirOut)) Directory.CreateDirectory(dirOut); //.. // *.osm.bz2 // foreach (string fileFullName in Directory.GetFiles(dirIn, "*.osm.bz2")) { FileInfo fileInfo = new FileInfo(fileFullName); using (FileStream fileStream = fileInfo.OpenRead()) { using (Stream unzipStream = new ICSharpCode.SharpZipLib.BZip2.BZip2InputStream(fileStream)) { XmlReader xmlReader = XmlReader.Create(unzipStream); while (xmlReader.Read()) { if (xmlReader.Name == "node") OSM_ProcessNode(xmlReader.ReadOuterXml()); else if (xmlReader.Name == "way") OSM_ProcessWay(xmlReader.ReadOuterXml()); else if (xmlReader.Name == "relation") OSM_ProcessRelation(xmlReader.ReadOuterXml()); } } } OSM_WriteResultToFiles(); // csv geojson } Conditions for the selection of objects:
In order to find the desired object, it is necessary to analyze all the tags (Key: Value pair). For example, the following conditions are defined for the selection of way-objects (desert):
To search for another object, you simply need to specify another Key: Value pair of values or several pairs, if you need to simultaneously find several objects of different types.
private static void OSM_ProcessWay(string xmlWay) { XmlDocument xmlDoc = new XmlDocument(); xmlDoc.LoadXml(xmlWay); long wayId = Int64.Parse(xmlDoc.DocumentElement.Attributes["id"].Value); foreach (XmlNode wayTag in xmlDoc.DocumentElement.ChildNodes) { if (wayTag.Name == "tag" && wayTag.Attributes["k"].Value == "natural" && wayTag.Attributes["v"].Value == "desert") { //.. } } } To search for another object, you simply need to specify another Key: Value pair of values or several pairs, if you need to simultaneously find several objects of different types.
The selected point objects are saved in string buffers:
When processing node-objects, the selected data prepared in the string form is written to the string buffer. After processing the next OSM file, the buffer is written to the result files and reset. Periodic recording in the result files is necessary in order not to overload the system (errors like - out of memory).
In the example of processing node-objects all way-and relation-objects are taken into account for statistics (which can be viewed in the log).
// Country // static StringBuilder sbCsvCountry = new StringBuilder(); static StringBuilder sbGeojsonCountry = new StringBuilder(); // City // static StringBuilder sbCsvCity = new StringBuilder(); static StringBuilder sbGeojsonCity = new StringBuilder(); static int numPopulationCityFiltr = 1000000; // Population ( >= numPopulationCityFiltr) // Volcano // static StringBuilder sbCsvVolcano = new StringBuilder(); static StringBuilder sbGeojsonVolcano = new StringBuilder(); In the example of processing node-objects all way-and relation-objects are taken into account for statistics (which can be viewed in the log).
To save the lines, the following structures are used (in the form of class lists):
Preparation of way objects takes place in two stages (in fact, two complete XML parsing of the same file). First, all way objects are defined. Then, when re-parsing, the latitude (lat) and longitude (lon) of all points (node) in the way-objects are determined. The fact is that the description of points (node) comes before the description of lines (way).
In fact, when you have to select a lot of objects (for example, coastlines, roads), errors like “Out of memory” can occur. To eliminate such errors, it is sufficient to periodically record the data in the result files (for example, after processing the next file).
// // class NodeAttrItem // node- ( node, way ) { public long NodeId = 0; public double Lat = 0; public double Lon = 0; public string Type; public string Name; public string NameEn; public string NameRu; public string Attrs; } class WayAttrItem // way- { public long WayId = 0; public string Type; public string Name; public string NameEn; public string NameRu; public string Attrs; } class WayToNodeItem // { public long WayId = 0; public long NodeId = 0; public double Lat = 0; public double Lon = 0; } // // static List<NodeAttrItem> nodeAttrList = new List<NodeAttrItem>(); static List<WayAttrItem> wayAttrList = new List<WayAttrItem>(); static List<WayToNodeItem> wayToNodeList = new List<WayToNodeItem>(); In fact, when you have to select a lot of objects (for example, coastlines, roads), errors like “Out of memory” can occur. To eliminate such errors, it is sufficient to periodically record the data in the result files (for example, after processing the next file).
CSV and geoJSON
The CSV format is compact and convenient for recording a large amount of data, which can then be easily imported, for example, into a database.
The geoJSON format, by contrast, is redundant and verbose in structure, but is convenient because the data is immediately ready for display on the map. In the examples, for visualization, the GitHub feature for displaying geodata (files with a geojson extension) is used.
A little bit about how geojson is implemented:
Line breaks, when preparing geojson, are used for easy viewing. Sometimes in OSM-XML there are combinations of characters that can make geoJSON invalid. This happens when the XML data is correct, and, after parsing, JSON perceives it as an error (the reasons for the errors have to be found in rather large files). For example, double quotes ["] should be corrected if they are found in tags. In the example, double quotes are corrected to single [']. Or the latitude / longitude can be indicated as, for example," 32. "(corrected to" 32.0 ").
In order for the lines not to be lost on the map, they are marked with dots that are clearly visible (in the example, each line is marked with a point object, the tags of which are taken from the line - the OSM_WriteResultToFilesGeojson function).
// - // string geojsonHeader = "{\"type\":\"FeatureCollection\",\"features\":["; string geojsonFooter = Environment.NewLine + "{}]}"; // (way node) // string geojsonFeatureBegin = Environment.NewLine + "{" + Environment.NewLine + "\"type\":\"Feature\"," + Environment.NewLine + "\"geometry\":"; string geojsonFeatureEnd = Environment.NewLine + "},"; // node // string geojsonPointBegin = "{\"type\":\"Point\",\"coordinates\":"; string geojsonPointEnd = "},"; // way ( Polygon) // string geojsonPolygonBegin = "{\"type\":\"Polygon\",\"coordinates\":[["; string geojsonPolygonEnd = "]]}"; // // string geojsonPropBegin = Environment.NewLine + "\"properties\":{"; string geojsonPropEnd = "}"; Line breaks, when preparing geojson, are used for easy viewing. Sometimes in OSM-XML there are combinations of characters that can make geoJSON invalid. This happens when the XML data is correct, and, after parsing, JSON perceives it as an error (the reasons for the errors have to be found in rather large files). For example, double quotes ["] should be corrected if they are found in tags. In the example, double quotes are corrected to single [']. Or the latitude / longitude can be indicated as, for example," 32. "(corrected to" 32.0 ").
In order for the lines not to be lost on the map, they are marked with dots that are clearly visible (in the example, each line is marked with a point object, the tags of which are taken from the line - the OSM_WriteResultToFilesGeojson function).
Explanation of working with XML
When referring to attributes, names are indicated, not indexes:
When reading XML elements and XML attributes, it is advisable to specify a name, not an index. This of course slows down a little, but it guarantees against unpleasant surprises, for example, when OSM data is taken from different sources with different order of attributes.
xmlDoc.DocumentElement.Attributes["lat"].Value; xmlDoc.DocumentElement.Attributes["lon"].Value; All tags are saved in CSV as a Key: Value pair:
When reading object tags, the XML block is reread twice. The first time to determine the type of object. The second time, if the desired object is found, in order to save tags.
The full composition of tags is needed, for example, if you need to analyze the composition of all tags for a new object. Some objects (big cities, countries) may have a lot of tags. The full list of tags is saved only in a CSV file.
// - // foreach (XmlNode nodeTag in xmlDoc.DocumentElement.ChildNodes) { if (nodeTag.Name == "tag") { if (nodeTag.Attributes["k"].Value == "place" && nodeTag.Attributes["v"].Value == "country") { string strAttrs = ""; bool isAttr = false; // - // foreach (XmlNode nodeTag in xmlDoc.DocumentElement.ChildNodes) { if (nodeTag.Name == "tag") { if (isAttr) strAttrs += ","; else isAttr = true; strAttrs += String.Format("\"{0}\":\"{1}\"", nodeTag.Attributes["k"].Value, nodeTag.Attributes["v"].Value.Replace('\"', '\'')); } } } } } The full composition of tags is needed, for example, if you need to analyze the composition of all tags for a new object. Some objects (big cities, countries) may have a lot of tags. The full list of tags is saved only in a CSV file.
Speed and duplicates
Factors that affect performance:
1. The speed of reading the OSM file (unzipping and parsing XML elements):
For node-objects, the OSM file must be read once, and for way-objects, 2 times.
The need for double-reading is caused by the fact that in the XML-file first go node-, and only for them way-objects. In this case, double-reading simply simplifies the algorithm, avoiding the use of intermediate structures for storing the latitude and longitude of points.
The need for double-reading is caused by the fact that in the XML-file first go node-, and only for them way-objects. In this case, double-reading simply simplifies the algorithm, avoiding the use of intermediate structures for storing the latitude and longitude of points.
2. Remove duplicates and set latitude and longitude for points included in the way:
In order not to create duplicate objects and reduce the time for determining the latitude and longitude of points included in the way, a single mechanism is used based on the use of index arrays. This approach can significantly increase the processing speed due to the optimization of search operations.
In the example of deserts (for Africa), the difference in processing time is without an index array (useIndexedCheck = false) ≈ 3.5 hours, with an index array (useIndexedCheck = true) ≈ 1 hour. But, if, for example, you need to select all the roads or coastlines on the complete OSM data, then without indexation the processing time can last for days or even weeks (the greater the number of selected objects is, the more time is spent), and with indexing it will take all the time a little more than a day.
How it works?
If, with each new parsing of a node or a way, to know - was the object with such an id already processed before?
If you quickly (without search) determine that the read point enters the line, then this gives a significant gain in speed. Since the total number of points can be quite significant (more than three billion on complete data), then the time spent on search operations for each point (on the internal arrays nodeAttrList, wayAttrList, wayToNodeList), with the accumulation of data, turn into significant. That is - the use of the index array helps to get rid of "idle" search operations.
?
node- way- id ( id ). node- way- byte, id .
node way ( XML) .
, id , .
In the example of deserts (for Africa), the difference in processing time is without an index array (useIndexedCheck = false) ≈ 3.5 hours, with an index array (useIndexedCheck = true) ≈ 1 hour. But, if, for example, you need to select all the roads or coastlines on the complete OSM data, then without indexation the processing time can last for days or even weeks (the greater the number of selected objects is, the more time is spent), and with indexing it will take all the time a little more than a day.
How it works?
If, with each new parsing of a node or a way, to know - was the object with such an id already processed before?
If you quickly (without search) determine that the read point enters the line, then this gives a significant gain in speed. Since the total number of points can be quite significant (more than three billion on complete data), then the time spent on search operations for each point (on the internal arrays nodeAttrList, wayAttrList, wayToNodeList), with the accumulation of data, turn into significant. That is - the use of the index array helps to get rid of "idle" search operations.
?
node- way- id ( id ). node- way- byte, id .
bool useIndexedCheck = true; // / // (false), *.bz2 , // (true), > 4 GB RAM //-- long wayIdxSize = 512 * 1024 * 1024 - 1; byte[] wayIdx; long nodeIdxSize = (2L * 1024 * 1024 * 1024 - 57 - 1); byte[] nodeIdx1; byte[] nodeIdx2; //-- , > 4 GB RAM // if (useIndexedCheck) { wayIdx = new byte[wayIdxSize + 1]; nodeIdx1 = new byte[nodeIdxSize + 1]; nodeIdx2 = new byte[nodeIdxSize + 1]; } node way ( XML) .
// // if (useIndexedCheck) { if(OSM_WayIdxAdd(wayId) > 1) return; } //.. // // private static byte OSM_NodeIdxAdd(long nodeId) { if (nodeId <= nodeIdxSize) return ++nodeIdx1[nodeId]; return ++nodeIdx2[nodeId - nodeIdxSize]; } , id , .
// // private static long OSM_NodeIdxDuplCount() { long numDupl = 0; for (long n = 0; n <= nodeIdxSize; n++) { if (nodeIdx1[n] > 2) numDupl++; if (nodeIdx2[n] > 2) numDupl++; } return numDupl; } Mono ( ).
Visual Studio Community 2015 Windows 7. , EXE- ICSharpCode.SharpZipLib.dll ( ) Linux ( OpenSuse, Mint, Ubuntu Oracle Virtual Box) Mono ( Mono ). , .
, :
.
Environment.NewLine.
//.. string dirIn = @".\in\"; // (*.bz2) string dirOut = @".\out\"; // ( - ) //.. OperatingSystem os = Environment.OSVersion; PlatformID pid = os.Platform; if (pid == PlatformID.Unix || pid == PlatformID.MacOSX) // 0 - Win32S, 1 - Win32Windows, 2 - Win32NT, 3 - WinCE, 4 - Unix, 5 - Xbox, 6 - MacOSX { dirIn = dirIn.Replace(@"\", @"/"); dirOut = dirOut.Replace(@"\", @"/"); } Environment.NewLine.
string geojsonFeatureBegin = Environment.NewLine + "{" + Environment.NewLine + "\"type\":\"Feature\"," + Environment.NewLine + "\"geometry\":"; string geojsonFeatureEnd = Environment.NewLine + "},"; GitHub
( ):
node-
way-
(geoJSON):
.
.
.
.
Links
( )
Planet.osm
GeoJSON
GitHub geoJSON
geofabrik
gis-lab
OSM
(SharpZipLib)
Mono
Source: https://habr.com/ru/post/270513/
All Articles