Introduction to the development of domain-specific languages (DSL) using EMFText

This is the 5th article of the model-driven development cycle. In previous articles we have already dealt with metamodels , model validation , some notations for models ( diagrams and tables ). All this was within the scope of the MOF simulation space . Today we will build a bridge to the EBNF modeling space - let's get acquainted with the textual notation for MOF models.
Introduction
In general, there is a lot of information on the development of general-purpose programming languages and domain-specific languages. Anyone who is interested in this, probably has a general idea about lexers, parsers, syntax trees, etc. But we will approach this a bit from the other side. We will not consider the development of DSL in general, we are only interested in it from the point of view of model-oriented development.
Note
')
To be honest, the introduction turned out to be some kind of cerebral. It focuses primarily on model-driven development professionals. You can scroll through it.
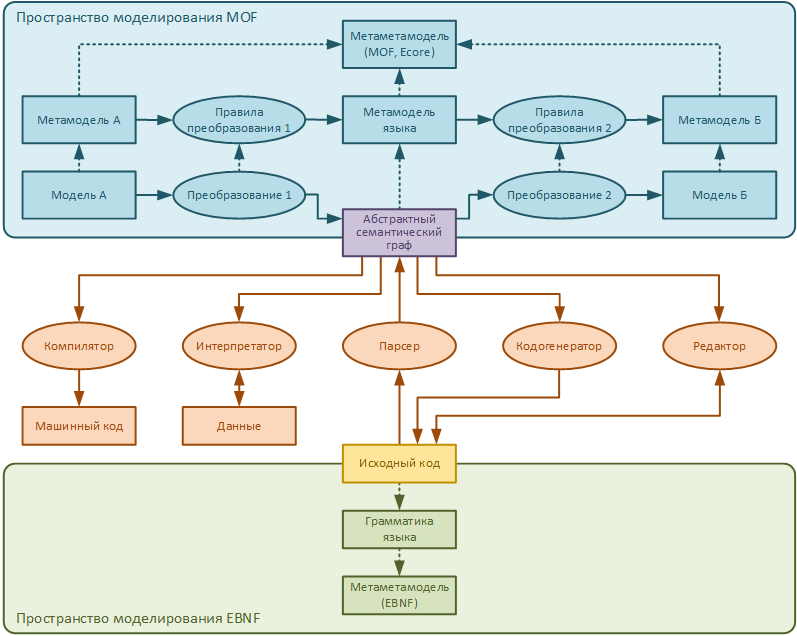
In the figure, red, yellow, purple and green colors indicate what is usually considered in the theory of programming languages. The language grammar is developed in EBNF (or some other language). Programmers then write the source code according to the grammar. The source code is fed to the parser, which converts the program text into some internal representation (let's call it abstract semantic graph). This graph is then used by the interpreter, compiler, editor, or code generator.
This is a very simplified and schematic classic of the theory of programming languages. We will not consider it in too much detail.
In parallel with all this, there is another area - model-oriented development, which this cycle of articles is devoted to.
In model-oriented development, absolutely everything from the thoughts in the developer’s head to the source code, unit tests or documentation is treated as a model (this is the main, primary entity). And the development process is the transformation of some models into others.
- For example, first in the mind of the developer a certain image (model) of the future program appears.
- Then he transforms this mental image into a UML model.
- Based on the UML model, it writes the source code (also a model from the point of view of model-oriented development).
- For source code, it writes unit tests (and this is a model).
- Writes documentation (everything is a model).
Some of these transformations are easy to automate, others are more difficult or impossible in the short term. But this does not change the essence - there are only models and transformations of models - nothing more (in fact, transformations are also models, but more on that in the next articles).
Some models are very similar to each other. For example, all UML-models are built according to certain rules in a single notation (they have a common metamodel - UML). Some BPMN or ER models are already different from UML. But, nevertheless, they are much closer to UML than the source code or thoughts of the programmer.
This is due to the fact that UML, BPMN and ER are metamodels built on the basis of a single metametamodel of MOF. And the grammar (metamodel) of a programming language is built on another metametamodel - EBNF. The thoughts of the programmer correspond also to some metamodel, which corresponds to some metametamodel, which is currently completely unformalized.
Each metametamodel forms its own modeling space, which is quite different from the others.
Note
If you don’t understand what I’m talking about, you can read the first article in the cycle about OCL and the metamodel . As well as an article about modeling space .
If it is necessary to transform models within a single modeling space (for example, MOF), then this is elementary. There are relevant specifications and tools to which we return in the next article.
But if it is necessary to (a) convert the source code into UML, or (b) form unit tests or documentation from BPMN models, then this is somewhat more difficult to do. To do this, we need a bridge between two modeling spaces. And here the theory of programming languages comes to the rescue.
In this article we will look at the metamodel of one very simple object-oriented language (blue block in the figure), we will describe its grammar (green block in the figure). We will also generate (in model-oriented development, it is not generally accepted to write code manually with a parser and code generator - a bridge between MOF and EBNF modeling spaces. Also, we will generate an editor for this language, in the future we will not need it, but let it be.
For the Eclipse Modeling Framework, there are several tools that can help us with this.
MOF Model to Text Transformation Language (Acceleo)
This is a template language for generating text from MOF models, described in the OMG specification . Acceleo is an implementation of the OMG specification. The specification has not been updated since 2008, however, Acceleo has been used successfully in many projects. The language is very simple, maybe you do not need to update anything in it. We will look at it in one of the following articles in more detail.
The advantage of this language is that it makes it quite easy to form text from models. If you need to quickly form a SQL query from a UML or ER model or unload it from the model in CSV format, then this language is optimal.
The main disadvantage is that this bridge is one-sided. It does not allow parsing the text and turning it back into a model. You also have to pay a lot of attention to formatting templates (spaces, line breaks) so that the resulting text is correctly formatted. At the same time the templates themselves are not very readable.
By the way, Acceleo is actually a template add-on over OCL. If you read this article , then to master Acceleo you need to learn a few more constructions.
EMFText
EMFText is a much more interesting thing than Acceleo. You describe the metamodel and language syntax. As a result, you get a bidirectional bridge between the MOF and EBNF modeling spaces. A parser is automatically generated for you (from text to model), a code generator (from model to text), as well as an editor (with syntax highlighting and auto-completion) and blanks for the compiler, interpreter and debugger of the language.
There are examples of languages implemented using EMFText.
In this article we will use EMFText.
Xtext
Xtext is similar in functionality to EMFText. Differs more active community. And an approach to the generation of the parser and code generator, which depend on the Xtext runtime libraries. Unlike EMFText, which is needed only in design-time and not needed in runtime. For this reason, we use EMFText in our projects, and not Xtext.
Epsilon Generation Language
An analogue of Acceleo for Epsilon .
Human Usable Textual Notation
Also worth noting is OMG HUTN . This is the textual syntax for serializing MOF models. You can take it as JSON for MOF models. For Epsilon there is its implementation . However, this thing does not suit us, because we will need to describe an arbitrary syntax, and not just with curly braces.
Some theory
Before moving on to practice, you still need a bit of theory.
Note
This section does not pretend to be complete, nor to accuracy. Everything is described in a very simplified and schematic way, only so that the following sections are understandable. If you are interested in the theory of programming languages, it is better to refer to sources that are devoted to this topic.
We are building a bridge between the EBNF and MOF simulation spaces. On one side of the bridge, the source code, on the other, a certain model of the program (for definiteness, we will call it an abstract semantic graph).
Usually the abstract semantic graph is hidden from the programmer. How exactly it is arranged is a question of the implementation of a compiler or interpreter. Programmers with this graph do not work directly, they work only with source code.
In model-oriented development, the abstract semantic graph, on the other hand, plays a key role. This is not some kind of technical internal structure of the parser, but a model with which the programmer will work. It is important for the programmer how exactly this model is designed, how comfortable it is.
Note
Of course, when programmers use the reflective capabilities of the language, they work with the program model, not the source code. But at the same time, they, probably, not understanding this themselves, fall into the field of model-oriented development. They view the program as a model.
The figure schematically shows how the parser and the language code generator work.

Lexical analysis
First, a lexical analysis of the source code is performed, as a result of which the text is divided into a sequence of tokens. Usually the lexer selects tokens using context-independent regular expressions. It is for this reason in the languages
- there are reserved words that cannot be used in identifiers so that the lexer can distinguish the keyword from the identifier;
- text literals are quoted so that the lexer can distinguish them from reserved words or identifiers;
- identifiers cannot begin or consist entirely of numbers; otherwise, it would be difficult for a lecturer to understand this identifier or a numeric literal.
Those. whenever possible, regular expressions for different types of tokens should not intersect. Unfortunately, sometimes they still intersect. Sometimes this is not a problem. And sometimes this leads to the complication of the grammar of the language - we will face this situation in the next article about the SQL parser.
Parsing
Then, a sequence of tokens is parsed. The parser, looking at the grammar of the language, organizes the tokens into a specific syntax tree. The structure of this tree is identical to the EBNF grammar of the language:
- for the initial non-terminal symbol, the root node of the tree is constructed,
- for other non-terminal symbols, internal nodes of the tree are built,
- for terminal symbols (tokens, tokens) leaf tree nodes are built.
Simplification of a specific syntax tree
It is usually very inconvenient to work with a specific syntax tree, even for very simple languages it turns out to be very deep.
In one of the following articles, we will probably consider a language for arithmetic expressions. You will see that the particular syntax tree for such a language resembles the Tower of Pisa.
For simple languages, it is enough to remove the extra intermediate floors of the tower. More complex languages require more complex simplifications. As a result, we get an abstract syntax tree.
Each tree node will be an object of a certain class. Although, in general, this is not necessary, we could easily do without classes and objects, by representing the tree, for example, in the form of an XML document. But we need exactly the object model, because the MOF to which we are moving is object. If we built a bridge to some modeling space other than MOF, then we would need not an object model of the program, but some other one.
Semantic analysis
Obviously, the program written in relatively complex language, we can not imagine in the form of a tree. For example, if this language allows you to declare variables, classes, types, functions, and then refer to them, then by resolving such text links we get an abstract semantic graph.
Code Generation
Kodogeneration is a reverse parsing process, when a textual representation of a program is formed from some abstract representation of a program (for example, in the form of an abstract semantic graph).
There are two approaches to code generation: templates and a universal code generator.
When using templates, an approximate text of the future program is written. For example, the names of classes, variables, functions in this text are replaced by special sequences of characters, instead of which actual names are substituted instead. Obviously, arbitrary code cannot be generated using templates.
A universal code generator accepts a certain program model as an input (for example, an abstract semantic graph), and outputs the corresponding source code at the output. Thus any code can be generated. However, implementing a universal code generator is much more difficult than a template. There may also be difficulties with formatting the result code. We need either additional annotations in the model containing information about spaces, line breaks, etc. Or you need a code formatter, which also needs to be written or taken somewhere. In the version with templates, this is not necessary, you format everything right in the template right in the template.
Fortunately, EMFText automatically generates a code generator with the simplest code formatting options.
Customization
As usual, you will need Eclipse Modeling Tools . Install the latest version of EMFText from here http://emftext.org/update_trunk .
Project creation
Unlike previous articles, there is no finished project. Yes, it is not needed, use the project that is created by default (File -> New -> Other ... -> EMFText Project).

In the metamodel folder, you will see blanks for the language's metamodel (myDSL.ecore) and its grammar (myDSL.cs). These two files completely describe the language. Almost everything else is generated from them.

In this article, we will limit ourselves to this simple demo DSL.
Metamodel language
Metamodel is what language is about. For example, a Java metamodel will contain metaclasses: a class, a method, a variable, an expression, etc. You cannot describe something in the language that is not in its metamodel. For example, in Java 7 metamodel there are no lambda expressions. Therefore, they are not valid in code that is written under Java 7.
The following image shows the metamodel of the demo object-oriented language that EMFText generated for us.

Note
If you do not understand what is shown in the figure, then you can read an article about the Eclipse Modeling Framework .
Our domain-specific language allows us to describe an entity model (EntityModel), which consists of two types of (Type): entities (Entity) and data types (DataType). Entities can be abstract. An entity can have three types of properties (Feature) (FeatureKind): attributes (attribute), references (reference) and components (containment). The properties are very simple, they do not even have multiplicity.
In theory, attributes should only refer to data types. And links and components should only refer to entities. But in this metamodel at the structural level, this is not limited. You can easily make a data type an integral part of an entity, or you can specify an entity as an attribute type instead of a data type. Which is probably not very correct. This can be corrected in two ways: 1) at the structural level or 2) with the help of additional restrictions.
In the first case, for each type of properties a separate metaclass is created (this is how the metametamodel Ecore itself is implemented). Those. remove the FeatureKind enumeration, delete the type association, make the Feature metaclass abstract and inherit three metaclasses from it: Attribute, Reference and Containment. First add the link to DataType, and the second and third - to the Entity.
The second method is described in the article about OCL .
We will not correct this defect. Moreover, he will even further help us understand the mechanism for resolving links.
Launch the language editor
So, we have more or less dealt with the metamodel of the demo object-oriented language that EMFText has generated for us. Before proceeding to the description of the syntax of this language, let's look at an example of source code.
To do this, create and run a second instance of Eclipse (Run -> Run Configurations ...):

In the second instance of Eclipse, create a new myDSL project (File -> New -> Other ... -> EMFText myDSL project):

In the figure below, you see an example of code written in myDSL. As you can see, our domain-specific language really allows us to describe entities, properties, data types.
At the bottom left is the syntactic tree that corresponds to the language's metamodel. Bottom right properties of one of the nodes of the tree, which also correspond to the metamodel. If you want to get some other syntax tree (add new types of nodes to it, new properties of nodes), then you need to change the metamodel of the language.

You can see that the editor has syntax highlighting. Later we will improve it a little.
Also, via Ctrl + Space, autocompletion is called, which by default does not work as we would like. For attributes, only data types should be offered, not entities. We will fix this later.

Description of the specific syntax
Now that you have seen the sample code on the test DSL, let's go back to the syntax description in the file myDSL.cs.

Line 1 indicates the file extension of the described DSL.
Line 2 indicates the metamodel namespace described by DSL.
Line 3 indicates the initial non-terminal grammar symbol and part-time root metaclass of the syntax tree.
Line 6 indicates one of the EMFText parameters. There are hundreds of such order parameters, you can independently get acquainted with them in the manual .
Next come the grammar rules of the language. You can see that the rule description language is very similar to EBNF. However, the names of non-terminal symbols on the left side of the rule must match the name of some metaclass from the metamodel of the language. And the names of (non) terminal symbols in the right part of the rule must match the names of some properties of this metaclass.
The multiplicity of symbols in the right part of the rules must correspond to the multiplicity of the corresponding properties in the metamodel.
Let's sort the rules in more detail.
In line 10, we state that any code on our DSL must begin with the keyword “model”, followed by a description of several types. And, as you should remember, in a metamodel there are two types of entities: entities (Entity) and data types (DataType).
Line 11 describes the syntax for the entities. The description of the entity can begin with the keyword "abstract", in this case the entity property of the same name in the syntactic tree will be set to its true value. Then, the “entity” keyword must be followed.
Then follows the name of the entity, which will be stored in the name property. In brackets should indicate the type of token for names. In this case, it is not specified, so the parser will wait for the default token - TEXT. We will return to tokens a bit later.
Then in curly brackets should list the properties (features) of the entity. This is a non-terminal symbol — the grammar for properties has its own rule (line 13), and in the metamodel there is a separate metaclass. Therefore, there are no square brackets, it is not possible to specify the type of token.
Line 12 describes the syntax for data types. The description of the data type must begin with the keyword "datatype", followed by the type name and a semicolon.
Line 13 describes the syntax for the properties of the entities. A property description can begin with one of three key properties (“att”, “ref” or “cont”). In the syntax tree, depending on the specified keyword, the node's kind property will take one of the values of the FeatureKind enumeration.
Further, the type of the property, the name of the property and a semicolon should follow. Moreover, the property type in the code is specified as a character string, but in the syntax tree, the link by name turns into a physical link to the corresponding type. Thus, when parsing, we get a graph, not a tree. We will return to link resolution later.
In general, what exactly we get when parsing is not a very trivial question. On the one hand, the resulting structure almost completely duplicates the grammar of the language and, sort of like, this particular syntax tree. On the other hand, EMFText resolves symbolic links, turning a particular syntax tree into an abstract semantic graph. It also allows you to fasten post-processors to the parser, with which you can simplify the model.
In other words, the parser produces at the output some kind of hybrid of a specific syntax tree and an abstract semantic graph. For such a simple language is not very important. But in the next article, when developing a metamodel for SQL, we’ll have to come back to the question “what metamodel are we doing: concrete or abstract?”.
Adding new types of tokens
Now let's improve DSL a bit. In myDSL.cs, after some terminal characters (name and type) there are empty square brackets. For these characters, the default token TEXT with a pattern is used.
('A'..'Z'|'a'..'z'|'0'..'9'|'_'|'-')+This means that entity names can consist entirely of decimal digits or begin with a minus, which is probably not very correct.
Note
Also, entity names cannot contain non-Latin letters, probably, our language support would not be hindered by unicode support.
EMFText uses regular ANTLR expressions that support unicode, but do not support character classes. Therefore, it is necessary to explicitly enumerate the ranges of valid characters. Let's not bother with it yet.
So, let type names begin only with a capital letter of the Latin alphabet and cannot begin with other characters. And the names of the properties - only with a lowercase letter of the Latin alphabet.
To describe new types of tokens, create a TOKENS section (lines 9-16).

In lines 10-12, fragments of tokens are defined.
In lines 14 and 15, tokens are defined, respectively, for type names and property names.
In lines 20-22, the tokens expected by the parser are indicated in square brackets.
However, there is a problem. Regular expressions for new tokens intersect with the default token TEXT, about which we get a warning (see the figure above). What can this lead to?
For example, in the source code the entity "Car" is defined. The name of this entity matches both regular expressions: TEXT and TYPE_NAME. If the lexer decides that “Car” is a TYPE_NAME, then everything will be fine. But if he decides that this is TEXT, then at the next stage of parsing the source code, the parser will produce an error like this: “After the keyword“ entity ”the token TYPE_NAME is expected, and the token TEXT is indicated”.
Note
If you do not understand the meaning of the previous paragraph, then look at the picture in the “Some theory” section above and read the subsections on lexical and syntactic analysis.
There are several ways to resolve this uncertainty:
- Rely on EMFText for more specific tokens to assign a higher priority by default. Those. first the lexer will search for TYPE_NAME and FEATURE_NAME, and then TEXT.
- Set priorities for tokens manually.
- Remove excess tokens.
- Complicate grammar. For example, instead of “name [TYPE_NAME]” write “name [TYPE_NAME] | name [TEXT] ".
In this case, we do not need the TEXT token, so we will simply remove it. To do this, in line 7, disable the predefined tokens: TEXT, LINEBREAK and WHITESPACE. But we still need the last two tokens, so we will define them explicitly in lines 18 and 19.

Now right-click on the project in the tree on the left and in the pop-up menu that appears, select "Generate All (EMFText)". After the source code is regenerated, launch a second instance of Eclipse.
Now if you write the name of the entity with a lowercase letter, the lexer interprets it as the property name (FEATURE_NAME), and the parser will generate an error that the token TYPE_NAME was expected.
If you start the attribute name with the underscore "_", then the lexer will not understand at all what kind of token it is.

Syntax highlighting
By default, EMFText colors all keywords in purple. Add a little more colors, for this, create a TOKENSTYLES section (lines 22-27).

Regenerate the “Geneate All (EMFText)” source code and launch a second instance of Eclipse.
It looks scary, but you get the idea :) Please note that “car” is painted in blue, not pink. This is due to the fact that the lexer selects tokens using context-independent regular expressions. He does not know that there should be the name of the entity, and not the name of the property.

Link resolution
Earlier, I drew your attention to the fact that autocompletion of type names in definitions of properties of entities does not work very well. For attributes (att), only data types should be offered, and for references (ref) and component parts (cont), only entities should be offered.
In the org.emftext.language.myDSL.resource.myDSL project, find the FeatureTypeReferenceResolver class that is responsible for autocompletion and link resolution.
The resolve method must look for matching types. If the resolveFuzzy parameter has a true value, then the method should look for types that roughly fit the specified string (this happens when autocompleting the type name). Otherwise, the method must search for the type with the specified name.
The deResolve method should, for reference in an abstract semantic column, return its textual representation in the source code.
Here is one of the implementations for resolving type references:
package org.emftext.language.myDSL.resource.myDSL.analysis; import java.util.Map; import java.util.function.Consumer; import java.util.function.Predicate; import java.util.stream.Stream; import org.eclipse.emf.ecore.EReference; import org.eclipse.emf.ecore.util.EcoreUtil; import org.emftext.language.myDSL.DataType; import org.emftext.language.myDSL.Entity; import org.emftext.language.myDSL.EntityModel; import org.emftext.language.myDSL.Feature; import org.emftext.language.myDSL.FeatureKind; import org.emftext.language.myDSL.Type; import org.emftext.language.myDSL.resource.myDSL.IMyDSLReferenceResolveResult; import org.emftext.language.myDSL.resource.myDSL.IMyDSLReferenceResolver; public class FeatureTypeReferenceResolver implements IMyDSLReferenceResolver<Feature, Type> { // , identifier public void resolve(String identifier, Feature container, EReference reference, int position, boolean resolveFuzzy, final IMyDSLReferenceResolveResult<Type> result) { // . // containment- owner, // container.getOwner().getOwner() EntityModel model = (EntityModel) EcoreUtil.getRootContainer(container); // , , // Predicate<Type> isRelevant = container.getKind() == FeatureKind.ATTRIBUTE ? type -> type instanceof DataType : type -> type instanceof Entity; Stream<Type> types = model.getTypes().stream().filter(isRelevant); // Consumer<Type> addMapping = type -> result.addMapping(type.getName().toString(), type); // , , // if (resolveFuzzy) { types.filter(type -> type.getName().toUpperCase().startsWith(identifier.toUpperCase())) .forEach(addMapping); } // ( ), else { types.filter(type -> type.getName().equals(identifier)) .findFirst() .ifPresent(addMapping); } } // ( ) public String deResolve(Type element, Feature container, EReference reference) { return element.getName(); } public void setOptions(Map<?, ?> options) { } } Code Generation
With the parser and the editor in the first approximation figured out. Only code generation is left.
The syntax tree in the lower left corner is available only for viewing. To be able to edit it, save the file in the xmi format (File -> Save As ...).
If an error occurs that the file cannot be opened using MyDSLEditor, then ignore it and rediscover the xmi file. You will see the same syntax tree, however, it can now be edited.

Rename the “Car” entity to “Vehicle” and set the true value of the “Abstract” property.
Save the xmi file with the myDSL extension. Close it and open it again:

As you can see, our changes to the syntax tree are taken into account! Those. Model to text conversion (code generation) works.
True, while saving, line breaks and some spaces disappeared.
There are three ways to achieve normal formatting of the generated code:
- Modify the metamodel by adding links to each metaclass to the metaclass LayoutInformation from the metamodel www.emftext.org/commons/layout . I personally did not do this, and I have a feeling that this would have to count the number of gaps required, calculate shifts in the text, etc. - it looks very difficult.
- Use a separate code formatter. Probably, this is the best option when generating Java code or something, for which there is already a ready formatter.
- Add a few annotations to the grammar of the language so that the default code generator will format the code a little better. This is the easiest option, so do.
In lines 30 and 31 added annotations "! 0", "! 1" and "# 1". These annotations are ignored by the parser; they are intended for the code generator. The abstract "#N" tells the code generator that it is necessary to insert N spaces in this place. And the summary "! N" denotes line feed and N tabs.

Regenerate the “Geneate All (EMFText)” source code and restart the second instance of Eclipse. Try to save the model again in text format and make sure that the code is now better formatted.
Conclusion
After reading this article, you need to take a fresh look at software development — through the prism of models and model conversions.
Models can be represented in different notations (in the form of diagrams , tables , text). From the point of view of model-driven development, a domain-specific language is just one of the notations for some metamodel.
On the other hand, the grammar of a subject-oriented language is a metamodel in the EBNF modeling space . And the source code is a model in this modeling space.
A parser is the transformation of a model from an EBNF modeling space into a model in a MOF modeling space or another.
A code generator is the inverse transformation of a model from a semantic-oriented modeling space (for example, MOF) into an EBNF modeling space.
You also got acquainted with one of the programming language development tools - EMFText.
Source: https://habr.com/ru/post/270483/
All Articles