Full Binary XML Replacement
Introduction
What is the beauty of XML? It is implemented for all platforms, “human-readable”, data schemes (conditionally human-readable) are created for it. Opening a 25-megabyte file in the browser immediately notice the shortcomings of this text format, and you start to think. We do this, of course, not often, but still - what would replace XML?
Adding self-made binary containers to a project ends in failure when partners come to you and ask to connect them to this data channel. Google Protobuf looks good at first, but soon you realize that this is not a replacement for XML, there is not enough functionality. BSON is 5 times slower than Protobuf, inferior in compactness and for it data schemes are not implemented.
Let's develop one more binary format.
USDS 1.0
USDS (or $ S) - Universal serialized data structures - universal serialized data structures, a binary format that can completely replace XML and JSON. The main differences:
')
- Instead of text tags / keys are used integers. Value "Name" - "Integer identifier" is set separately in the "Dictionary". The dictionary can be attached to the USDS document or can be transferred separately.
- No closing tags, as in XML;
- USDS documents are formed strictly according to the scheme, which is also specified in the Dictionary. Polymorphism and optional fields are supported.
- Numeric values in the USDS document are stored in binary form (not as text).
Suppose we have documented this format and created the first version of the library to work with it. Is there a profit? Benchmark puts everything in its place:

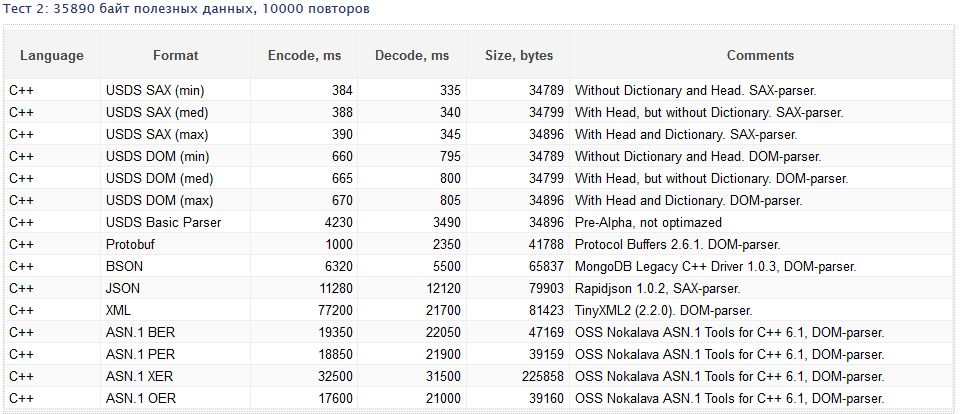
There is already something in it, although the work is still not small: Basic Parser will always be inferior to Google Protobuf, but not by the same amount.
Usage example
Although the format is binary, using it is no more difficult than XML. Let's see how it will look in C ++ (and in the distant bright future in other languages).
Step 1: compiling a Dictionary
As mentioned above, the USDS document is built only according to a scheme that may look like this:
USDS DICTIONARY ID=1000000 v.1.0 { 1: STRUCT internalObject { 1: UNSIGNED VARINT varintField; 1: UNSIGNED VARINT varintField; 2: DOUBLE doubleField; 3: STRING<UTF-8> stringField; 4: BOOLEAN booleanField; } RESTRICT {notRoot;} 2: STRUCT rootObject { 1: INT intField; 2: LONG longField; 3: ARRAY<internalObject> arrayField; } } All the rules for constructing the scheme can be found here . The USDS Basic Parser library does not yet support all the elements of the scheme, but the example above is working. Save the schema in a text file, or paste it directly into the source code, what's next?
Step 2: initialize the parser:
Anyway, the data scheme was in the “text_dictionary” array, we’ll feed it to the parser:
BasicParser* clientParser = new BasicParser(); clientParser->addDictionaryFromText(text_dictionary, strlen(text_dictionary), USDS_UTF8); The parser is ready to generate binary USDS documents. If you only need to decode the binary, then initialization with the dictionary is not required: the parser will automatically pull out the dictionary directly from the USDS binary document.
Step 3: create a binary document:
The algorithm is no different from working with any other DOM parser: we add several root objects, initialize them with values, generate the output data array.
UsdsStruct* tag = clientParser->addStructTag("rootObject"); tag->setFieldValue("intField", 1234); tag->setFieldValue("longField", 5000000000); ... BinaryOutput* usds_binary_doc = new BinaryOutput(); clientParser->encode(usds_binary_doc, true, true, true); const unsigned char* binary_data = usds_binary_doc->getBinary(); size_t binary_size = usds_binary_doc->getSize(); The features of working with arrays are omitted; you can view them separately by downloading the sample source code.
Step 4: Decoding a binary document:
For the purity of the experiment, we will create a separate parser object, we will not initialize it with a dictionary and see if it parses our binary document:
BasicParser* serverParser = new BasicParser(); serverParser->decode(binary_data, binary_size); int int_value = 0; long long long_value = 0; tag->getFieldValue("intField", &int_value); std::cout << "\tintField = " << int_value << "\n"; tag->getFieldValue("longField", &long_value); std::cout << "\tlongField = " << long_value << "\n"; Please note that the “Server” does not know anything about the data schema beforehand, but calmly received the binary, found the fields in it using their text names and correctly converted them to the values of the C ++ variables. This feature is not available in Google Protobuf and ASN.1.
You can significantly speed up the program if you initialize the fields by their numeric identifiers (IDs, which are the same as those specified in the Dictionary), see the source code of the example.
Human readability
This is really a very important feature: you can’t read Google’s Google Protobuf or ASN.1 binary package (except XER), and sometimes you really want to. With BSON, you can convert any data packet to JSON, which is pretty good. USDS is not far behind it:
std::string json; serverParser->getJSON(USDS_UTF8, &json); std::cout << "JSON:\n" << json << "\n"; The server not only received an arbitrary binary document, but was also able to convert it to JSON. The same operation could be performed on the “Client” side: create a DOM object and immediately convert it to JSON, which also strictly corresponds to the data scheme.
The USDS development plans include a USDS document editor with a full-fledged GUI. In the near future, the conversion between XML, JSON and USDS in any direction will be implemented in USDS Basic Parser.
Conclusion
Why did I publish the raw product (Pre-Alpha), which is strongly not recommended for use in projects? Your feedback is important to me:
- What is missing in the product?
- Is he needed at all?
- Is the documentation and source code understandable?
Sources:
Project Page: USDS 1.0
Download the library and sample source code here .
Library source code is available here .
Source: https://habr.com/ru/post/270469/
All Articles